Regular Expressions: Text Editing and Advanced Manipulation HORT 59000 Lecture 4 Instructor: Kranthi Varala Simple Manipulations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
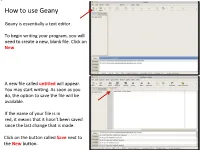
Geany Tutorial
How to use Geany Geany is essentially a text editor. To begin writing your program, you will need to create a new, blank file. Click on New. A new file called untitled will appear. You may start writing. As soon as you do, the option to save the file will be available. If the name of your file is in red, it means that it hasn’t been saved since the last change that is made. Click on the button called Save next to the New button. Save the file in a directory you had previously created before you launched Geany and name it main.cpp. All of the files you will write and submit to will be named specifically main.cpp. Once the .cpp has been specified, Geany will turn on its color coding feature for the C++ template. Next, we will set up our environment and then write a simple program that will print something to the screen Feel free to supply your own name in this small program Before we do anything with it, we will need to configure some options to make your life easier in this class The vertical line to the right marks the ! boundary of your code. You will need to respect this limit in that any line of code you write must not cross this line and therefore be properly, manually broken down to the next line. Your code will be printed out for The line is not where it should be, however, and grading, and if your code crosses the we will now correct it line, it will cause line-wrapping and some points will be deducted. -

Vim for Humans Release 1.0
Vim for humans Release 1.0 Vincent Jousse August 12, 2015 CONTENTS 1 Preamble 1 1.1 Disclaimer .................... ..................... 1 1.2 Paid book but free price .................... ..................... 1 1.3 Free license .................... ..................... 1 1.4 Thanks .................... ..................... 1 2 Introduction 3 2.1 For who? .................... ..................... 4 2.2 What you will be learning .................... .................... 4 2.3 What you will not be learning .................... .................. 4 2.4 The hardest part is to get started .................... ................. 5 3 Having a usable Vim 7 3.1 Essential preamble: the insert mode .................... ............... 8 3.2 Modes: the powerful Vim secrets .................... 10 3.3 The lifesaver default configuration .................... 12 3.4 And now, the color! .................... ..................... 13 3.5 Ourfirst plugin: thefile explorer .................... 17 3.6 Here we go .................... ..................... 19 4 The text editor you’ve always dreamed of 23 4.1 Learning how to move: the copy/paste use case ..................... 23 4.2 Forgetting the directional keys .................... 26 4.3 Doing without the Esc key .................... .................... 29 4.4 Combining keys and moves .................... ................... 29 4.5 Search / Move quickly .................... ..................... 30 4.6 Visual mode .................... ..................... 31 4.7 It’s your turn! .................... .................... -

Software Tools: a Building Block Approach
SOFTWARE TOOLS: A BUILDING BLOCK APPROACH NBS Special Publication 500-14 U.S. DEPARTMENT OF COMMERCE National Bureau of Standards ] NATIONAL BUREAU OF STANDARDS The National Bureau of Standards^ was established by an act of Congress March 3, 1901. The Bureau's overall goal is to strengthen and advance the Nation's science and technology and facilitate their effective application for public benefit. To this end, the Bureau conducts research and provides: (1) a basis for the Nation's physical measurement system, (2) scientific and technological services for industry and government, (3) a technical basis for equity in trade, and (4) technical services to pro- mote public safety. The Bureau consists of the Institute for Basic Standards, the Institute for Materials Research, the Institute for Applied Technology, the Institute for Computer Sciences and Technology, the Office for Information Programs, and the ! Office of Experimental Technology Incentives Program. THE INSTITUTE FOR BASIC STANDARDS provides the central basis within the United States of a complete and consist- ent system of physical measurement; coordinates that system with measurement systems of other nations; and furnishes essen- tial services leading to accurate and uniform physical measurements throughout the Nation's scientific community, industry, and commerce. The Institute consists of the Office of Measurement Services, and the following center and divisions: Applied Mathematics — Electricity — Mechanics — Heat — Optical Physics — Center for Radiation Research — Lab- oratory Astrophysics^ — Cryogenics^ — Electromagnetics^ — Time and Frequency*. THE INSTITUTE FOR MATERIALS RESEARCH conducts materials research leading to improved methods of measure- ment, standards, and data on the properties of well-characterized materials needed by industry, commerce, educational insti- tutions, and Government; provides advisory and research services to other Government agencies; and develops, produces, and distributes standard reference materials. -

Linux Fundamentals (GL120) U8583S This Is a Challenging Course That Focuses on the Fundamental Tools and Concepts of Linux and Unix
Course data sheet Linux Fundamentals (GL120) U8583S This is a challenging course that focuses on the fundamental tools and concepts of Linux and Unix. Students gain HPE course number U8583S proficiency using the command line. Beginners develop a Course length 5 days solid foundation in Unix, while advanced users discover Delivery mode ILT, vILT patterns and fill in gaps in their knowledge. The course View schedule, local material is designed to provide extensive hands-on View now pricing, and register experience. Topics include basic file manipulation; basic and View related courses View now advanced filesystem features; I/O redirection and pipes; text manipulation and regular expressions; managing jobs and processes; vi, the standard Unix editor; automating tasks with Why HPE Education Services? shell scripts; managing software; secure remote • IDC MarketScape leader 5 years running for IT education and training* administration; and more. • Recognized by IDC for leading with global coverage, unmatched technical Prerequisites Supported distributions expertise, and targeted education consulting services* Students should be comfortable with • Red Hat Enterprise Linux 7 • Key partnerships with industry leaders computers. No familiarity with Linux or other OpenStack®, VMware®, Linux®, Microsoft®, • SUSE Linux Enterprise 12 ITIL, PMI, CSA, and SUSE Unix operating systems is required. • Complete continuum of training delivery • Ubuntu 16.04 LTS options—self-paced eLearning, custom education consulting, traditional classroom, video on-demand -

Text Editing in UNIX: an Introduction to Vi and Editing
Text Editing in UNIX A short introduction to vi, pico, and gedit Copyright 20062009 Stewart Weiss About UNIX editors There are two types of text editors in UNIX: those that run in terminal windows, called text mode editors, and those that are graphical, with menus and mouse pointers. The latter require a windowing system, usually X Windows, to run. If you are remotely logged into UNIX, say through SSH, then you should use a text mode editor. It is possible to use a graphical editor, but it will be much slower to use. I will explain more about that later. 2 CSci 132 Practical UNIX with Perl Text mode editors The three text mode editors of choice in UNIX are vi, emacs, and pico (really nano, to be explained later.) vi is the original editor; it is very fast, easy to use, and available on virtually every UNIX system. The vi commands are the same as those of the sed filter as well as several other common UNIX tools. emacs is a very powerful editor, but it takes more effort to learn how to use it. pico is the easiest editor to learn, and the least powerful. pico was part of the Pine email client; nano is a clone of pico. 3 CSci 132 Practical UNIX with Perl What these slides contain These slides concentrate on vi because it is very fast and always available. Although the set of commands is very cryptic, by learning a small subset of the commands, you can edit text very quickly. What follows is an outline of the basic concepts that define vi. -

Basic Guide: Using VIM Introduction: VI and VIM Are In-Terminal Text Editors That Come Standard with Pretty Much Every UNIX Op
Basic Guide: Using VIM Introduction: VI and VIM are in-terminal text editors that come standard with pretty much every UNIX operating system. Our Astro computers have both. These editors are an alternative to using Emacs for editing and writing programs in python. VIM is essentially an extended version of VI, with more features, so for the remainder of this discussion I will be simply referring to VIM. (But if you ever do research and need to ssh onto another campus’s servers and they only have VI, 99% of what you know will still apply). There are advantages and disadvantages to using VIM, just like with any text editors. The main disadvantage of VIM is that it has a very steep learning curve, because it is operated via many keyboard shortcuts with somewhat obscure names like dd, dw, d}, p, u, :q!, etc. In addition, although VIM will do syntax highlighting for Python (ie, color code things based on what type of thing they are), it doesn’t have much intuitive support for writing long, extensive, and complex codes (though if you got comfortable enough you could conceivably do it). On the other hand, the advantage of VIM is once you learn how to use it, it is one of the most efficient ways of editing text. (Because of all the shortcuts, and efficient ways of opening and closing). It is perfectly reasonable to use a dedicated program like emacs, sublime, canopy, etc., for creating your code, and learning VIM as a way to edit your code on the fly as you try to run it. -

Using the Linux Virtual Machine
Using the Linux Virtual Machine Update: On my computer I had problems with screen resolution and the VM didn't resize with the window and take the full width when in fullscreen mode. This was fixed with installation of an additional package. In a console window (see below how to pen that), I gave this command: sudo aptget install virtualboxguestdkms This asks for the password. That is "genomics". After restarting the VM, the screen resize works fine. Some programs are found in the menu at the bottomleft corner. Many programs are commandline only and not in the menu. To use the command line, start the console by clicking the icon in the bottom panel. Execute the following commands to create a new directory in your home folder "~/" for today’s exercises: mkdir ~/session_1 cd ~/session_1 Open the file browser to see what you did. The Shared Folders is under /media. On the file browser you can change to directory view using the pull down menu on the topleft corner: Click then "media" and "sf_evogeno". Using RStudio Click this link: https://drive.google.com/open?id=0B3Cf0QL4k1PTkZ5QVdEQ1psRUU and select to open the file in RStudio. Save the file in the folder "session_1" that you created above. The script requires two R libraries that are not installed. Install them by typing the following commands in the R console window: install.packages("ggplot2") install.packages("reshape") Now you are ready to run the script e.g. by clicking the "Source" button in the topright corner of the file editor window. -

A Brief Introduction to Unix-2019-AMS
A Brief Introduction to Linux/Unix – AMS 2019 Pete Pokrandt UW-Madison AOS Systems Administrator [email protected] Twitter @PTH1 Brief Intro to Linux/Unix o Brief History of Unix o Basics of a Unix session o The Unix File System o Working with Files and Directories o Your Environment o Common Commands Brief Intro to Unix (contd) o Compilers, Email, Text processing o Image Processing o The vi editor History of Unix o Created in 1969 by Kenneth Thompson and Dennis Ritchie at AT&T o Revised in-house until first public release 1977 o 1977 – UC-Berkeley – Berkeley Software Distribution (BSD) o 1983 – Sun Workstations produced a Unix Workstation o AT&T unix -> System V History of Unix o Today – two main variants, but blended o System V (Sun Solaris, SGI, Dec OSF1, AIX, linux) o BSD (Old SunOS, linux, Mac OSX/MacOS) History of Unix o It’s been around for a long time o It was written by computer programmers for computer programmers o Case sensitive, mostly lowercase abbreviations Basics of a Unix Login Session o The Shell – the command line interface, where you enter commands, etc n Some common shells Bourne Shell (sh) C Shell (csh) TC Shell (tcsh) Korn Shell (ksh) Bourne Again Shell (bash) [OSX terminal] Basics of a Unix Login Session o Features provided by the shell n Create an environment that meets your needs n Write shell scripts (batch files) n Define command aliases n Manipulate command history n Automatically complete the command line (tab) n Edit the command line (arrow keys in tcsh) Basics of a Unix Login Session o Logging in to a unix -

The Kate Handbook
The Kate Handbook Anders Lund Seth Rothberg Dominik Haumann T.C. Hollingsworth The Kate Handbook 2 Contents 1 Introduction 10 2 The Fundamentals 11 2.1 Starting Kate . 11 2.1.1 From the Menu . 11 2.1.2 From the Command Line . 11 2.1.2.1 Command Line Options . 12 2.1.3 Drag and Drop . 13 2.2 Working with Kate . 13 2.2.1 Quick Start . 13 2.2.2 Shortcuts . 13 2.3 Working With the KateMDI . 14 2.3.1 Overview . 14 2.3.1.1 The Main Window . 14 2.3.2 The Editor area . 14 2.4 Using Sessions . 15 2.5 Getting Help . 15 2.5.1 With Kate . 15 2.5.2 With Your Text Files . 16 2.5.3 Articles on Kate . 16 3 Working with the Kate Editor 17 4 Working with Plugins 18 4.1 Kate Application Plugins . 18 4.2 External Tools . 19 4.2.1 Configuring External Tools . 19 4.2.2 Variable Expansion . 20 4.2.3 List of Default Tools . 22 4.3 Backtrace Browser Plugin . 25 4.3.1 Using the Backtrace Browser Plugin . 25 4.3.2 Configuration . 26 4.4 Build Plugin . 26 The Kate Handbook 4.4.1 Introduction . 26 4.4.2 Using the Build Plugin . 26 4.4.2.1 Target Settings tab . 27 4.4.2.2 Output tab . 28 4.4.3 Menu Structure . 28 4.4.4 Thanks and Acknowledgments . 28 4.5 Close Except/Like Plugin . 28 4.5.1 Introduction . 28 4.5.2 Using the Close Except/Like Plugin . -

ENCM 335 Fall 2018: Command-Line C Programming on Macos
page 1 of 4 ENCM 335 Fall 2018: Command-line C programming on macOS Steve Norman Department of Electrical & Computer Engineering University of Calgary September 2018 Introduction This document is intended to help students who would like to do ENCM 335 C pro- gramming on an Apple Mac laptop or desktop computer. A note about software versions The information in this document was prepared using the latest versions of macOS Sierra version 10.12.6 and Xcode 9.2, the latest version of Xcode available for that version of macOS. Things should work for you if you have other but fairly recent versions of macOS and Xcode. If you have versions that are several years old, though you may experience difficulties that I'm not able to help with. Essential Software There are several key applications needed to do command-line C programming on a Mac. Web browser I assume you all know how to use a web browser to find course documents, so I won't say anything more about web browsers here. Finder Finder is the tool built in to macOS for browsing folders and files. It really helps if you're fluent with its features. Terminal You'll need Terminal to enter commands and look at output of commands. To start it up, look in Utilities, which is a folder within the Applications folder. It probably makes sense to drag the icon for Terminal to the macOS Dock, so that you can launch it quickly. macOS Terminal runs the same bash shell that runs in Cygwin Terminal, so commands like cd, ls, mkdir, and so on, are all available on your Mac. -

Set up Mail Server Documentation 1.0
Set Up Mail Server Documentation 1.0 Nosy 2014 01 23 Contents 1 1 1.1......................................................1 1.2......................................................2 2 11 3 13 3.1...................................................... 13 3.2...................................................... 13 3.3...................................................... 13 4 15 5 17 5.1...................................................... 17 5.2...................................................... 17 5.3...................................................... 17 5.4...................................................... 18 6 19 6.1...................................................... 19 6.2...................................................... 28 6.3...................................................... 32 6.4 Webmail................................................. 36 6.5...................................................... 37 6.6...................................................... 38 7 39 7.1...................................................... 39 7.2 SQL.................................................... 41 8 43 8.1...................................................... 43 8.2 strategy.................................................. 43 8.3...................................................... 44 8.4...................................................... 45 8.5...................................................... 45 8.6 Telnet................................................... 46 8.7 Can postfix receive?.......................................... -

Session: Introduction Topic: Editors Daniel Chang
COP 3344 Introduction to UNIX Lecture Session: Introduction Topic: Editors Daniel Chang Copyright August 2006, Daniel Chang COP 3344 Introduction to UNIX Using "pico" • The command "pico" will start the "pico" text editor with an empty buffer • Specifying a file name will have "pico" open that file (or start a new file) • Incidentally, "nano" is a GNU clone of "pico" pico pico <filename> Commands • Arrow keys are used to navigate around document • Similar to "pine" e-mail program, available commands are displayed at the bottom of the "pico" window • The caret symbol (^) indicates you must press and hold the control key first, then press the key for the command. Marking and Cut & Paste • You cannot use your mouse in "pico" (actually, the mouse works to cut and paste because of the SSHClient program, but you must learn how to work without it) • ^^ (ctrl-shift-^) begins marking text at the current cursor position • Use the arrow keys to mark text • ^k cuts text (kills), ^u then brings the text back at the current cursor position Saving • ^o writes "Out" the buffered text to a file • A prompt appears at the bottom of the screen allowing you to specify a file name • ^x exits "pico" Copyright August 2006, Daniel Chang COP 3344 Introduction to UNIX "pico" Commands (arrows) Move cursor (bksp) Move cursor left one space, deleting character ^a Move to beginning of line ^b Move back one character (same as left arrow) ^e Move to end of line ^f Move forward one character (same as right arrow) ^n Move to next line (same as down arrow) ^p Move to previous