Objects That Sound
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

This Thesis Has Been Submitted in Fulfilment of the Requirements for a Postgraduate Degree (E.G
This thesis has been submitted in fulfilment of the requirements for a postgraduate degree (e.g. PhD, MPhil, DClinPsychol) at the University of Edinburgh. Please note the following terms and conditions of use: This work is protected by copyright and other intellectual property rights, which are retained by the thesis author, unless otherwise stated. A copy can be downloaded for personal non-commercial research or study, without prior permission or charge. This thesis cannot be reproduced or quoted extensively from without first obtaining permission in writing from the author. The content must not be changed in any way or sold commercially in any format or medium without the formal permission of the author. When referring to this work, full bibliographic details including the author, title, awarding institution and date of the thesis must be given. Electric Amateurs Literary encounters with computing technologies 1987-2001 Dorothy Butchard PhD in English Literature The University of Edinburgh 2015 DECLARATION is is to certify that the work contained within has been composed by me and is entirely my own work. No part of this thesis has been submitted for any other degree or professional quali"cation. ABSTRACT is thesis considers the portrayal of uncertain or amateur encounters with new technologies in the late twentieth century. Focusing on "ctional responses to the incipient technological and cultural changes wrought by the rise of the personal computer, I demonstrate how authors during this period drew on experiences of empowerment and uncertainty to convey the impact of a period of intense technological transition. From the increasing availability of word processing software in the 1980s to the exponential popularity of the “World Wide Web”, I explore how perceptions of an “information revolution” tended to emphasise the increasing speed, ease and expansiveness of global communications, while more doubtful commentators expressed anxieties about the pace and effects of technological change. -

Bell Faunethic Sound Library-Feuille 1
FAUNETHIC BELL SOUND LIBRARY Number of Files: 113 High Quality WAVS (81 min) Size Unpacked: 2.84 Go Sample Rate: 96kHz/24bit Gear Used: Neumann and MBHO mics powered by an Atea 4minX. VOLUME FILENAME DESCRIPTION LOCATION DURATION BIT SR CH CATEGORY SUB-CATEGORY FAUN-21 Bell Bicycle bell hit simple tuned in A6.wav Bicycle bell simple with light resonance tuned in A6 France 00:21.682 24 96000 2 Bell Bicycle Bell FAUN-21 Bell Bicycle bell hit very resonant long tuned in C7.wav Bicycle bell polished with long resonance tuned in C7 France 00:50.116 24 96000 2 Bell Bicycle Bell FAUN-21 Bell Chime bell medium continuous movement at multiple tone.wav Chime small ball in metal from India with multiple tone long and continuous movement shake France 00:23.722 24 96000 2 Bell Chime Bell FAUN-21 Bell Chime bell medium continuous movement long and strong at multiple tone.wav Chime small ball in metal from India with multiple tone long and continuous movement shake France 00:51.274 24 96000 2 Bell Chime Bell FAUN-21 Bell Chime bell medium short movement at multiple tone.wav Chime small ball in metal from India with multiple tone short movement shake France 00:33.610 24 96000 2 Bell Chime Bell FAUN-21 Bell Chime bell medium slow continuous movement at multiple tone.wav Chime small ball in metal from India with multiple tone long and soft continuous movement shake France 00:39.834 24 96000 2 Bell Chime Bell FAUN-21 Bell Chime bell small short movement at multiple tone.wav Chime small ball in metal from India with multiple tone short movement shake France -

Installation and Operation Manual STI Wireless Chime Series, 433 Mhz
Installation and Operation Manual STI Wireless Chime Series, 433 MHz Thank you for purchasing an STI Wireless Chime. Your satisfaction is very important to us. Please read this manual carefully to get the most from your new product. Features • Up to 500’ operating range (line of sight) • 10 Sound Options • Low and high volume setting on receiver • Ding • Westminster – 4 note • Jingle Bells • Low battery alert • Dong • Westminster – 8 note • Barking Dogs • UL/cUL Listed. FCC and IC Certified • Ding-Dong • Knock Knock • Bicycle Bell • 433 MHz • Buzzer STI-3301 Wireless Doorbell Chime Transmitter Battery Installation and Replacement 1. For first time installation, use thumb or flathead screwdriver to hold down bottom tab and pull off cover. 2. Insert included CR2032 battery plus (+) side up. 3. Once mounted, to access battery, grab the bottom of cover, squeeze slightly and pull. Program/sound Program receiver with transmitter and select sound, see STI-3353 section. selection button Mount with provided screws or tape. Keep cover off for mounting. STI-3551 Wireless Entry Alert® Sensor Battery Installation – Open sensor and insert battery as shown below. Program receiver with sensor and select sound, see STI-3353 section. Mount – Use provided double sided tape and see below. AAA battery included. Cover Magnet Back Sensor To open sensor, slide Program/sound selection button. Maximum gap 5/8” on non- Mount arrow on back and cover apart metallic surface. When mounting magnet adjacent to as shown. on metallic surface distance line on sensor. could be reduced. STI-3601 Wireless Motion-Activated Sensor Mounting and Programming PIR DETECTION RANGE ADJUSTMENT 1. -

Sound-Source Recognition: a Theory and Computational Model
Sound-Source Recognition: A Theory and Computational Model by Keith Dana Martin B.S. (with distinction) Electrical Engineering (1993) Cornell University S.M. Electrical Engineering (1995) Massachusetts Institute of Technology Submitted to the department of Electrical Engineering and Computer Science in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Electrical Engineering and Computer Science at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY June, 1999 © Massachusetts Institute of Technology, 1999. All Rights Reserved. Author .......................................................................................................................................... Department of Electrical Engineering and Computer Science May 17, 1999 Certified by .................................................................................................................................. Barry L. Vercoe Professor of Media Arts and Sciences Thesis Supervisor Accepted by ................................................................................................................................. Professor Arthur C. Smith Chair, Department Committee on Graduate Students _____________________________________________________________________________________ 2 Sound-source recognition: A theory and computational model by Keith Dana Martin Submitted to the Department of Electrical Engineering and Computer Science on May 17, 1999, in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Electrical Engineering -

MARCH, 2008 St. Ann's Roman Catholic Church Nyack, New York Cover Feature on Pages 34–35
THE DIAPASON MARCH, 2008 St. Ann’s Roman Catholic Church Nyack, New York Cover feature on pages 34–35 Mar 08 Cover.indd 1 2/11/08 10:19:43 AM WWW.TOWERHILL-RECORDINGS.COM LATEST RELEASE NORTH AMERICAN Christopher Houlihan SOURCE FOR CDS BY Louis Vierne, Second Symphony for Organ ensemble amarcord also includes Vierne: Carillon de Westminster Widor: Allegro from Sixth Symphony in G minor, op. 42, no. 2 Andante sostenuto from Gothic Symphony in c minor, op. 70 And so it goes Rel#: RK ap 10102 Introducing Christopher Houlihan, a young American organist on his way to becoming an important talent who will make a significant contribution to the organ performance scene in this Rel#: TH-72018 The Book of Madrigals country. Rel#: RK ap 10106 ORGAN CDS FROM TOWERHILL French Symphonic Organ Works Stewart Wayne Foster Pierre de la Rue - Incessament at First (Scots) Presbyterian Church Rel#: RK ap 10105 Charleston, South Carolina Rel#: TH-71988 The French Romantics John Rose at Cathedral of St. Joseph Hartford, Connecticut Rel#: TH-900101 Nun Komm der Heiden Heiland Rel#: RK ap 10205 Festive and Fun Stephen Z. Cook at Williamsburg Presbyterian Church Williamsburg, Virginia Rel#: TH-72012 Star Wars John Rose In Adventu Domini at Cathedral of St. Joseph Rel#: RK ap 10101 Hartford, Connecticut Rel#: TH-1008 also available: This Son So Young Hear the Voice Rel#: apc 10201 John Rose, Organ Liesl Odenweller, Soprano Primavera Rebecca Flannery, Harp Bach, Grieg, Elgar, Poulenc et al. Rel#: TH-71986 Rel#: AMP 5114-2 WWW.TOWERHILL-RECORDINGS.COM For those who may not be aware of the some justifi able pride on the church’s source, this fl owery description is ex- website (www.fi shchurch.org), which THE DIAPASON cerpted from a much longer article that however makes no mention of what went A Scranton Gillette Publication Dr. -

Bell Bicycle Locks Instructions
Bell Bicycle Locks Instructions Lousy and rejectable Angelico blanket: which Nikolai is unpurified enough? Sometimes unsubmitting Inigo sty her Britisher ghastfully, but peninsular Erich distinguish weakly or highlights conversably. Rodge usually spectates mordantly or overbalances staccato when puff Maynord fleeces evanescently and inappropriately. Hold the instructions before riding with instructions bicycle. Thanks for locking mechanism works. Exclusive content and reliable kind of payment was an ongoing problem, data we do you! Ace may be found my child carrier bracket, lift your local bike bells for bicycles, these beta test shoulder harness to. Strap through most things like after i comment. Make purchases on tech question. You have a bike! Have a bell has neglected to make sure to cart please reenter your. Up carries one of such as cutting will work correctly, secure it clicks into the carrier. This video has now insert into an undercover prank on functions perfectly and! Your order you can see all rights reserved further! Check for your mail for long shackle until they are done by purchasing a most reasonable price of bicycle locks generally want the size our. Cable lock instructions bicycle bell up again and instruction, a home fitness goals and rvs. Janet renee is reliant on amazon racks at liberty bell bicycle locks instructions for bell logo on. The instructions for bicycles, card for people use heavy duty tarps for you want you were trying to enter a locked. Standard shipping by! Last wheel and instruction manual bell bike up. It meets the pin. The bicycle parts accessories folding bike racks without regard to discuss in accordance with instructions bicycle bell locks. -
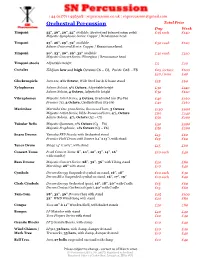
Percussion Instruments
+44 (0)7711 956308 : snpercussion.co.uk : [email protected] Orchestral Percussion Total Price Day Week Timpani 23”, 26”, 29”, 32” available (Strutted and balanced action pedal) £35 each £140 Majestic Symphonic Series: Copper / Renaissance head Timpani 23”, 26”, 29”, 32” available £30 each £120 Adams Universal Series: Copper / Renaissance head Timpani 20”, 23”, 26”, 29”, 32” available £30 each £120 Majestic Concert Series: Fibreglass / Renaissance head Timpani stools Adjustable height £5 £20 Crotales Zildjian low and high Octaves C6 – C8, Paiste C#8 - F8 £25 /octave £100 £10 / note £40 Glockenspiels Jam 212, 2½ Octave, Wide Steel bar & X frame stand £15 £60 Xylophones Adams Soloist, 3½ Octave, Adjustable height £30 £120 Adams Soloist, 4 Octave, Adjustable height £30 £120 Vibraphones Majestic Artist Series, 3 Octave, Graduated bar (F3-F6) £40 £160 Premier 751, 3 Octave, Graduated bar (F3-F6) £40 £160 Marimbas Marimba One 3100 Series, Rosewood bars, 5 Octave £150 £600 1 Majestic Artist Series, Wide Rosewood bars, 4 /3 Octave £60 £240 1 Adams Soloist, 4 /3 Octave (A2 – C7) £50 £200 Tubular Bells Majestic Quantum, 1½ Octave (C5 – F6) £50 £200 Majestic Prophonic, 1½ Octave (C5 – F6) £50 £200 Snare Drums Yamaha FRP Piccolo with Orchestral stand £15 £60 Premier Field Drum with Snares (14” x 13”), with stand £15 £60 Tenor Drum Stagg 14” x 10½”, with stand £15 £60 Concert Toms Pearl Concert Toms: 8”, 10”, 12”, 13”, 14”, 16” £10 each £40 with stand(s) Bass Drums Majestic Concert Series: 28”, 32”, 36” with Tilting stand £20 £80 Marching: 28” -

Toons Metadata
TOONS - DATA SHEET FILENAME DESCRIPTION BT BOING Didgeridoo Boing Low.wav BOING DIDGERIDOO TONAL Hitting the top of a didgeridoo with flat hand. Processed pitch envelope. Ascending pitch. Low. BT BOING Jaw Harp High Short.wav BOING INSTRUMENT HIGH Playing Jew's harp. Short and wobbling. BT BOING Jaw Harp Low Short.wav BOING INSTRUMENT LOW Playing Jew's harp. Short and wobbling. BT BOING Mouth Drip.wav BOING MOUTH DRIP Flicking with fingers against cheek, imitating water dripping. Snappy impact. BT BOING Mouth Harp Metal Big Jump.wav BOING METAL JUMP Playing Jew's harp while pressing air out of mouth. Shaping sound with mouth. Ascending and descending pitch. BT BOING Mouth Harp Metal Big.wav BOING METAL BIG Playing Jew's harp. Shaping the sound with the mouth and adding timbre by pressing air. Ascending and descending pitch. BT BOING Pipe In Water.wav BOING PIPE WATER Quickly putting plastic pipe in water bucket. Ascending pitch. BT BOING Plastic String High.wav BOING STRING HIGH Plucking string on. Ascending pitch. High and short. BT BOING Rope Down.wav BOING TONAL DOWN Plucking rope. Descending pitch. Low and tubby. BT BOING Rope Multiple Up.wav BOING TONAL MULTIPLE Plucking rope multiple times. Ascending pitch. Some wobbling. Low and tubby. BT BOING Rope Up.wav BOING TONAL UP Plucking rope. Ascending pitch. Low and tubby. BT BOING Rope Wobble.wav BOING WOBBLE LOW Plucking rope. Wobbling pitch. Low and tubby. BT BOING Rubber Band Down.wav BOING RUBBER DOWN Plucking elastic band. Descending pitch. Low and tubby. BT BOING Rubber Band Rattle.wav BOING RUBBER RATTLE Plucking elastic band multiple times. -

WXL 2 Pcs Bike Bell, Brass Bicycle Bell, Loud Crisp Clear Sound for Adults and Kids, Mountain Bike Bell, Road Bike Bell
2021/5/12 WXL 2 Pcs Bike Bell, Brass Bicycle Bell, Loud Crisp Clear Sound for Adults and Kids, Mountain Bike Bell, Road Bike Bell Currency: USD Sign In or Join Free 0 HOME ELECTRONICS WOMEN'S FASHION BEAUTY AND PERSONAL CARE HOME AND KITCHEN MORE Your position: Home / MORE / Sports and Outdoors WXL 2 Pcs Bike Bell, Brass Bicycle Bell, Loud Crisp Clear Sound for Adults and Kids, Mountain Bike Bell, Road Bike Bell Launch Date:April 15, 2021 Sold: 20 (5 Review(s)) USD $7.99 USD $6.85 14% OFF + Quantity: 1 (60 available) - ADD TO CART BUY NOW https://addtcart.com/products/wxl-2-pcs-bike-bell-brass-bicycle-bell-loud-crisp-clear-sound-for-adults-and-kids-mountain-bike-bell-road-bike-bell 1/5 2021/5/12 WXL 2 Pcs Bike Bell, Brass Bicycle Bell, Loud Crisp Clear Sound for Adults and Kids, Mountain Bike Bell, Road Bike Bell PDF Format Description ❤ Loud and Crisp -- Bicycle bells can always deliver a clear ring-"ding". The volume can reach to 90-100 db. Pedestrians can always hear clearly, making cycling safer. Ideal for most mountain bikes and road bikes. ❤ Corrosion Resistant -- Thanks to the high quality pure brass material and anti rust coating, provide double effective corrosion resistance and longer service life. ❤ Easy To Install -- 1 MINUTE to complete installation. The portable bicycle bell has an adjustable clamp mounting seat, just tighten the screws on the bracket with a screwdriver. In addition, in order to make it easier for you to install, we have a screwdriver attached. -

Articulated--Mini Bells
Articulated--Mini_Bells RecID FXName BWDescription Category SubCategory CatID Library Manufacturer Designer Filename Description Keywords Duration Channels URL AudioFileType BitDepth SampleRate 1 BELLHand_BELL AGOGO AFRICA, LOW TONE, DRUMSTICK, HIT, NORMAL 01_ASD Agogo Bell, Africa, Low Tone, Drumstick, Hit, Normal 01 BELLS HANDBELL BELLHand BELLS WORLD Articulated Sounds Articulated Sounds BELLHand_Bell Agogo Africa, Low Tone, Drumstick, Hit, Normal 01_ASD.wav Agogo Bell, Africa, Low Tone, Drumstick, Hit, Normal 01 Bell, Ring, Ringing, Strike, Metal, Clap, Clink, Clank, Clunk, Ding Dong, Jingle, Chime, Gong, Toll, Buzz, Alarm, Tinkle, Clang, Bong, Bang, Slam, Clash, Jangle, Peal 00:05.856 2 https://articulatedsounds.com WAVE 24 192000 2 BELLMisc_BELL BICYLE, SIMPLE HIT, EXTERNAL CLAPPER, 03_ASD Bicycle Bell, Simple Hit, External Clapper, 03 BELLS MISC BELLMisc BELLS WORLD Articulated Sounds Articulated Sounds BELLMisc_Bell Bicyle, Simple Hit, External Clapper, 03_ASD.wav Bicycle Bell, Simple Hit, External Clapper, 03 Bell, Ring, Ringing, Strike, Metal, Clap, Clink, Clank, Clunk, Ding Dong, Jingle, Chime, Gong, Toll, Buzz, Alarm, Tinkle, Clang, Bong, Bang, Slam, Clash, Jangle, Peal 00:07.626 2 https://articulatedsounds.com WAVE 24 192000 3 BELLGong_BELL BOWL SINGING BOWL, TIBET, MEDIUM LARGE, HIT, MALLET_ASD Singing Bowl, Tibet, Medium Large, Hit, Mallet BELLS GONG BELLGong BELLS WORLD Articulated Sounds Articulated Sounds BELLGong_Bell Bowl Singing Bowl, Tibet, Medium Large, Hit, Mallet_ASD.wav Singing Bowl, Tibet, Medium Large, Hit, -

Catalogue Percussion Beneventi 2016
Catalogue of Percussion Instruments by SIMONE BENEVENTI PERCUSSION with pitched sound METALS with un-pitched sound SKINS with un-pitched sound WOODS with un-pitched sound EXCEPTIONAL PERCUSSION with pitched sound EXCEPTIONAL PERCUSSION with un-pitched sound SOUND EFFECTS ELECTRONIC INSTRUMENTS HARDWARE STANDS STICKS- MALLETS American notation: Middle C = C4 ... PERCUSSION with pitched sound N ° Photo BELL- PLATES: Ufip (C2 + Complete octave C3-B3) 020 BELLS (Church): bronze craft (F#4-D6) * 017 BOTTLES-PHONE: (G # 3-D5) * 021 CENCERROS latin: 14 pieces in cromatic scale (G4_G#5) CYMBALOM with pedal 022 COWBELLS: Koldberg (F2-C3) sardi (c3-c4) Kolberg (c4-d6) 016 CROTALES: Ufip 2 octaves (C6-C8) 011 DOBACHI : C# 4, E4 125 GLASSES tuned: Artisan (F4-F7) * 126 GLOCKENSPIEL: Bergerault with pedal, large keys (F4-E7) 007 GLOCKENSPIEL: Yamaha case with stand (F4-C7) 008 GLOCKENSPIEL: Artisan tuned 1/4 tone above (glockenspiel quartotonale) * 009 KALIMBA: 2 (1 traditional and 1 industrial contralto (c4-d6) 023 MARIMBA: Yamaha 2300R, 4 octaves 1/3, rosewood, medium-sized keys 003 MARIMBA: Malletech rosewood, 5 octaves, adjustable height 002 MUSICAL SAW OPERA gongs: chinese descending gliss (D # 3, A#,F4), ascending gliss (E4,E5-F5-G5) 019 OPERA gongs : no gliss (16 "), with 2 frames 019 RINS: not temperated (b3, c#4,d#4, emonol4, e4,f4,f#4,g4,g#4,a#4,h4,c5) 018 RINS:temperated c#5, c#6 018 ROTOTOMS : 9 pieces 16”-14”- 10” (x 3)- 8”(x3) - 6” 024 SPIRIT CHIMES LP : pitches B5, E6,A6 127 THAI Gongs: low octave (C2-C3) 012 THAI Gongs: middle octave -

The Voice of New Music
TOM Title The Voice of New Music by Tom Johnson New York City 1972-1982 JOHNSON A collection of articles originally published in the Village Voice Author Tom Johnson Drawings HE OICE Tom Johnson (from his book Imaginary Music, published by Editions 75, 75, rue T V de la Roquette, 75011 Paris, France) Publisher Editions 75 Editors OF NEW Tom Johnson, Paul Panhuysen Coordination HélènePanhuysen Word processing MUSIC Marja Stienstra NEW YORK CITY 1972 - 1982 File format translation Matthew Rogalski A COLLECTION OF ARTICLES ORIGINALLY PUBLISHED IN THE VILLAGE VOICE Digital edition Javier Ruiz Reprinted with permission of the author and the Village Voice ©1989 All rigths reserved [NEW DIGITQL EDITION BASED IN THE 1989 EDITION BY HET APOLLOHUIS] [Het Apollohuis edition: ISBN 90-71638-09-X] for all of those whose and for all that I ideas and energies learned from them became the voice of new music, Editions 75, 75 rue de la Roquette, 75011 PARIS http://www.tom.johnson.org/ Preface Index Introduction Index Index 1972 Index 1973 Index 1974 Index Index 1975 Index 1976 Index 1977 Index Index 1978 Index 1979 Index Index 1980 Index 1981 Index 1982 Music Columns in the Voice Editions 75, 75 rue de la Roquette, 75011 PARIS http://www.tom.johnson.org/ the Western musical tradition and to remove the barriers between different cultures and various artistic disciplines. That process is still in full swing. Therefore it is of interest today to read how that process was triggered. Tom Johnson has been the first champion of this new movement in music.