Geometrical Quantum Mechanics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Path Integrals in Quantum Mechanics
Path Integrals in Quantum Mechanics Dennis V. Perepelitsa MIT Department of Physics 70 Amherst Ave. Cambridge, MA 02142 Abstract We present the path integral formulation of quantum mechanics and demon- strate its equivalence to the Schr¨odinger picture. We apply the method to the free particle and quantum harmonic oscillator, investigate the Euclidean path integral, and discuss other applications. 1 Introduction A fundamental question in quantum mechanics is how does the state of a particle evolve with time? That is, the determination the time-evolution ψ(t) of some initial | i state ψ(t ) . Quantum mechanics is fully predictive [3] in the sense that initial | 0 i conditions and knowledge of the potential occupied by the particle is enough to fully specify the state of the particle for all future times.1 In the early twentieth century, Erwin Schr¨odinger derived an equation specifies how the instantaneous change in the wavefunction d ψ(t) depends on the system dt | i inhabited by the state in the form of the Hamiltonian. In this formulation, the eigenstates of the Hamiltonian play an important role, since their time-evolution is easy to calculate (i.e. they are stationary). A well-established method of solution, after the entire eigenspectrum of Hˆ is known, is to decompose the initial state into this eigenbasis, apply time evolution to each and then reassemble the eigenstates. That is, 1In the analysis below, we consider only the position of a particle, and not any other quantum property such as spin. 2 D.V. Perepelitsa n=∞ ψ(t) = exp [ iE t/~] n ψ(t ) n (1) | i − n h | 0 i| i n=0 X This (Hamiltonian) formulation works in many cases. -

Key Concepts for Future QIS Learners Workshop Output Published Online May 13, 2020
Key Concepts for Future QIS Learners Workshop output published online May 13, 2020 Background and Overview On behalf of the Interagency Working Group on Workforce, Industry and Infrastructure, under the NSTC Subcommittee on Quantum Information Science (QIS), the National Science Foundation invited 25 researchers and educators to come together to deliberate on defining a core set of key concepts for future QIS learners that could provide a starting point for further curricular and educator development activities. The deliberative group included university and industry researchers, secondary school and college educators, and representatives from educational and professional organizations. The workshop participants focused on identifying concepts that could, with additional supporting resources, help prepare secondary school students to engage with QIS and provide possible pathways for broader public engagement. This workshop report identifies a set of nine Key Concepts. Each Concept is introduced with a concise overall statement, followed by a few important fundamentals. Connections to current and future technologies are included, providing relevance and context. The first Key Concept defines the field as a whole. Concepts 2-6 introduce ideas that are necessary for building an understanding of quantum information science and its applications. Concepts 7-9 provide short explanations of critical areas of study within QIS: quantum computing, quantum communication and quantum sensing. The Key Concepts are not intended to be an introductory guide to quantum information science, but rather provide a framework for future expansion and adaptation for students at different levels in computer science, mathematics, physics, and chemistry courses. As such, it is expected that educators and other community stakeholders may not yet have a working knowledge of content covered in the Key Concepts. -
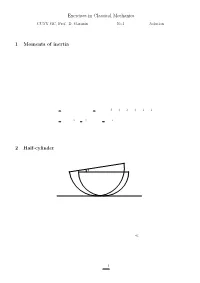
Exercises in Classical Mechanics 1 Moments of Inertia 2 Half-Cylinder
Exercises in Classical Mechanics CUNY GC, Prof. D. Garanin No.1 Solution ||||||||||||||||||||||||||||||||||||||||| 1 Moments of inertia (5 points) Calculate tensors of inertia with respect to the principal axes of the following bodies: a) Hollow sphere of mass M and radius R: b) Cone of the height h and radius of the base R; both with respect to the apex and to the center of mass. c) Body of a box shape with sides a; b; and c: Solution: a) By symmetry for the sphere I®¯ = I±®¯: (1) One can ¯nd I easily noticing that for the hollow sphere is 1 1 X ³ ´ I = (I + I + I ) = m y2 + z2 + z2 + x2 + x2 + y2 3 xx yy zz 3 i i i i i i i i 2 X 2 X 2 = m r2 = R2 m = MR2: (2) 3 i i 3 i 3 i i b) and c): Standard solutions 2 Half-cylinder ϕ (10 points) Consider a half-cylinder of mass M and radius R on a horizontal plane. a) Find the position of its center of mass (CM) and the moment of inertia with respect to CM. b) Write down the Lagrange function in terms of the angle ' (see Fig.) c) Find the frequency of cylinder's oscillations in the linear regime, ' ¿ 1. Solution: (a) First we ¯nd the distance a between the CM and the geometrical center of the cylinder. With σ being the density for the cross-sectional surface, so that ¼R2 M = σ ; (3) 2 1 one obtains Z Z 2 2σ R p σ R q a = dx x R2 ¡ x2 = dy R2 ¡ y M 0 M 0 ¯ 2 ³ ´3=2¯R σ 2 2 ¯ σ 2 3 4 = ¡ R ¡ y ¯ = R = R: (4) M 3 0 M 3 3¼ The moment of inertia of the half-cylinder with respect to the geometrical center is the same as that of the cylinder, 1 I0 = MR2: (5) 2 The moment of inertia with respect to the CM I can be found from the relation I0 = I + Ma2 (6) that yields " µ ¶ # " # 1 4 2 1 32 I = I0 ¡ Ma2 = MR2 ¡ = MR2 1 ¡ ' 0:3199MR2: (7) 2 3¼ 2 (3¼)2 (b) The Lagrange function L is given by L('; '_ ) = T ('; '_ ) ¡ U('): (8) The potential energy U of the half-cylinder is due to the elevation of its CM resulting from the deviation of ' from zero. -

Quantum Mechanics
Quantum Mechanics Richard Fitzpatrick Professor of Physics The University of Texas at Austin Contents 1 Introduction 5 1.1 Intendedaudience................................ 5 1.2 MajorSources .................................. 5 1.3 AimofCourse .................................. 6 1.4 OutlineofCourse ................................ 6 2 Probability Theory 7 2.1 Introduction ................................... 7 2.2 WhatisProbability?.............................. 7 2.3 CombiningProbabilities. ... 7 2.4 Mean,Variance,andStandardDeviation . ..... 9 2.5 ContinuousProbabilityDistributions. ........ 11 3 Wave-Particle Duality 13 3.1 Introduction ................................... 13 3.2 Wavefunctions.................................. 13 3.3 PlaneWaves ................................... 14 3.4 RepresentationofWavesviaComplexFunctions . ....... 15 3.5 ClassicalLightWaves ............................. 18 3.6 PhotoelectricEffect ............................. 19 3.7 QuantumTheoryofLight. .. .. .. .. .. .. .. .. .. .. .. .. .. 21 3.8 ClassicalInterferenceofLightWaves . ...... 21 3.9 QuantumInterferenceofLight . 22 3.10 ClassicalParticles . .. .. .. .. .. .. .. .. .. .. .. .. .. .. 25 3.11 QuantumParticles............................... 25 3.12 WavePackets .................................. 26 2 QUANTUM MECHANICS 3.13 EvolutionofWavePackets . 29 3.14 Heisenberg’sUncertaintyPrinciple . ........ 32 3.15 Schr¨odinger’sEquation . 35 3.16 CollapseoftheWaveFunction . 36 4 Fundamentals of Quantum Mechanics 39 4.1 Introduction .................................. -

Zero-Point Energy and Interstellar Travel by Josh Williams
;;;;;;;;;;;;;;;;;;;;;; itself comes from the conversion of electromagnetic Zero-Point Energy and radiation energy into electrical energy, or more speciÞcally, the conversion of an extremely high Interstellar Travel frequency bandwidth of the electromagnetic spectrum (beyond Gamma rays) now known as the zero-point by Josh Williams spectrum. ÒEre many generations pass, our machinery will be driven by power obtainable at any point in the universeÉ it is a mere question of time when men will succeed in attaching their machinery to the very wheel work of nature.Ó ÐNikola Tesla, 1892 Some call it the ultimate free lunch. Others call it absolutely useless. But as our world civilization is quickly coming upon a terrifying energy crisis with As you can see, the wavelengths from this part of little hope at the moment, radical new ideas of usable the spectrum are incredibly small, literally atomic and energy will be coming to the forefront and zero-point sub-atomic in size. And since the wavelength is so energy is one that is currently on its way. small, it follows that the frequency is quite high. The importance of this is that the intensity of the energy So, what the hell is it? derived for zero-point energy has been reported to be Zero-point energy is a type of energy that equal to the cube (the third power) of the frequency. exists in molecules and atoms even at near absolute So obviously, since weÕre already talking about zero temperatures (-273¡C or 0 K) in a vacuum. some pretty high frequencies with this portion of At even fractions of a Kelvin above absolute zero, the electromagnetic spectrum, weÕre talking about helium still remains a liquid, and this is said to be some really high energy intensities. -

Relativistic Quantum Mechanics 1
Relativistic Quantum Mechanics 1 The aim of this chapter is to introduce a relativistic formalism which can be used to describe particles and their interactions. The emphasis 1.1 SpecialRelativity 1 is given to those elements of the formalism which can be carried on 1.2 One-particle states 7 to Relativistic Quantum Fields (RQF), which underpins the theoretical 1.3 The Klein–Gordon equation 9 framework of high energy particle physics. We begin with a brief summary of special relativity, concentrating on 1.4 The Diracequation 14 4-vectors and spinors. One-particle states and their Lorentz transforma- 1.5 Gaugesymmetry 30 tions follow, leading to the Klein–Gordon and the Dirac equations for Chaptersummary 36 probability amplitudes; i.e. Relativistic Quantum Mechanics (RQM). Readers who want to get to RQM quickly, without studying its foun- dation in special relativity can skip the first sections and start reading from the section 1.3. Intrinsic problems of RQM are discussed and a region of applicability of RQM is defined. Free particle wave functions are constructed and particle interactions are described using their probability currents. A gauge symmetry is introduced to derive a particle interaction with a classical gauge field. 1.1 Special Relativity Einstein’s special relativity is a necessary and fundamental part of any Albert Einstein 1879 - 1955 formalism of particle physics. We begin with its brief summary. For a full account, refer to specialized books, for example (1) or (2). The- ory oriented students with good mathematical background might want to consult books on groups and their representations, for example (3), followed by introductory books on RQM/RQF, for example (4). -

Newtonian Mechanics Is Most Straightforward in Its Formulation and Is Based on Newton’S Second Law
CLASSICAL MECHANICS D. A. Garanin September 30, 2015 1 Introduction Mechanics is part of physics studying motion of material bodies or conditions of their equilibrium. The latter is the subject of statics that is important in engineering. General properties of motion of bodies regardless of the source of motion (in particular, the role of constraints) belong to kinematics. Finally, motion caused by forces or interactions is the subject of dynamics, the biggest and most important part of mechanics. Concerning systems studied, mechanics can be divided into mechanics of material points, mechanics of rigid bodies, mechanics of elastic bodies, and mechanics of fluids: hydro- and aerodynamics. At the core of each of these areas of mechanics is the equation of motion, Newton's second law. Mechanics of material points is described by ordinary differential equations (ODE). One can distinguish between mechanics of one or few bodies and mechanics of many-body systems. Mechanics of rigid bodies is also described by ordinary differential equations, including positions and velocities of their centers and the angles defining their orientation. Mechanics of elastic bodies and fluids (that is, mechanics of continuum) is more compli- cated and described by partial differential equation. In many cases mechanics of continuum is coupled to thermodynamics, especially in aerodynamics. The subject of this course are systems described by ODE, including particles and rigid bodies. There are two limitations on classical mechanics. First, speeds of the objects should be much smaller than the speed of light, v c, otherwise it becomes relativistic mechanics. Second, the bodies should have a sufficiently large mass and/or kinetic energy. -

Rotation: Moment of Inertia and Torque
Rotation: Moment of Inertia and Torque Every time we push a door open or tighten a bolt using a wrench, we apply a force that results in a rotational motion about a fixed axis. Through experience we learn that where the force is applied and how the force is applied is just as important as how much force is applied when we want to make something rotate. This tutorial discusses the dynamics of an object rotating about a fixed axis and introduces the concepts of torque and moment of inertia. These concepts allows us to get a better understanding of why pushing a door towards its hinges is not very a very effective way to make it open, why using a longer wrench makes it easier to loosen a tight bolt, etc. This module begins by looking at the kinetic energy of rotation and by defining a quantity known as the moment of inertia which is the rotational analog of mass. Then it proceeds to discuss the quantity called torque which is the rotational analog of force and is the physical quantity that is required to changed an object's state of rotational motion. Moment of Inertia Kinetic Energy of Rotation Consider a rigid object rotating about a fixed axis at a certain angular velocity. Since every particle in the object is moving, every particle has kinetic energy. To find the total kinetic energy related to the rotation of the body, the sum of the kinetic energy of every particle due to the rotational motion is taken. The total kinetic energy can be expressed as .. -

Statics Syllabus
AME-201 Statics Spring 2011 Instructor Charles Radovich [email protected] Lecture T Th 2:00 pm – 3:20 PM, VKC 152 Office Hours Tue. 3:30 – 5 pm, Wed. 4:30 – 5:30 pm, also by appointment – RRB 202 Textbook Beer, F. and E. Johnston. Vector Mechanics for Engineers: Statics, 9th Edition. McGraw-Hill, Boston, 2009. ISBN-10: 007727556X; ISBN-13: 978-0077275563. Course Description AME-201 STATICS Units: 3 Prerequisite: MATH-125 Recommended preparation: AME-101, PHYS-151 Analysis of forces acting on particles and rigid bodies in static equilibrium; equivalent systems of forces; friction; centroids and moments of inertia; introduction to energy methods. (from the USC Course Catalogue) The subject of Statics deals with forces acting on rigid bodies at rest covering coplanar and non- coplanar forces, concurrent and non-concurrent forces, friction forces, centroid and moments of inertia. Much time will be spent finding resultant forces for a variety of force systems, as well as analyzing forces acting on bodies to find the reacting forces supporting those bodies. Students will develop critical thinking skills necessary to formulate appropriate approaches to problem solutions. Course Objectives Throughout the semester students will develop an understanding of, and demonstrate their proficiency in the following concepts and principles pertaining to vector mechanics, statics. 1. Components of a force and the resultant force for a systems of forces 2. Moment caused by a force acting on a rigid body 3. Principle of transmissibility and the line of action 4. Moment due to several concurrent forces 5. Force and moment reactions at the supports and connections of a rigid body 6. -

Quantum Information Science: Emerging No More
Quantum Information Science: Emerging No More Carlton M. Caves Center for Quantum Information and Control, University of New Mexico, Albuquerque, New Mexico 87131-0001, USA Final: 2013 January 30 Quantum information science (QIS) is a new field of enquiry, nascent in the 1980s, founded firmly in the 1990s, exploding in the 2010s, now established as a discipline for the 21st Century. Born in obscurity, then known as the foundations of quantum mechanics, the field began in the 60s and 70s with studies of Bell inequalities. These showed that the predictions of quantum mechanics cannot be squared with the belief, called local realism, that physical systems have realistic properties whose pre-existing values are revealed by measurements. The predictions of quantum mechanics for separate systems, correlated in the quantum way that we now call entanglement, are at odds with any version of local realism. Experiments in the early 80s demonstrated convincingly that the world comes down on the side of quantum mechanics. With local realism tossed out the window, it was natural to dream that quantum correlations could be used for faster-than-light communication, but this speculation was quickly shot down, and the shooting established the principle that quantum states cannot be copied. A group consisting of quantum opticians, electrical engineers, and mathematical physicists spent the 60s and 70s studying quantum measurements, getting serious about what can be measured and how well, going well beyond the description of observables that was (and often still is) taught in quantum-mechanics courses. This was not an empty exercise: communications engineers needed a more general description of quantum measurements to describe communications channels and to assess their performance. -

Mechanics Lecture 3 Static Forces, Resultants, Equilibrium of a Particle Dr Philip Jackson
C.1 EE1.el3 (EEE1023): Electronics III Mechanics lecture 3 Static forces, resultants, equilibrium of a particle Dr Philip Jackson http://www.ee.surrey.ac.uk/Teaching/Courses/ee1.el3/ C.2 Mechanics • Mechanics is the study of the relationship between the motion of bodies and the forces applied to them It describes, measures and relates forces with motion • Statics: study of forces, resultant forces, bodies in equilibrium, no acceleration • Kinematics: study of motion, position and time • Dynamics: study of forces and motion C.3 Forces and equilibrium Forces magnitude and direction components of a force Equilibrium static or dynamic forces in balance Preparation What are the fundamental forces? List them What is a component of force? Give one example What is equilibrium? Draw a diagram with 3-4 forces C.4 Four fundamental forces All forces can be described by four fundamental forces: 1. Gravity: long range, v. weak 2. Electromagnetic: responsible for many electrical, magnetic and EM wave phenomena 3. Weak nuclear: short range, radioactive decay 4. Strong nuclear: short range C.5 Statics – what is a force? • A force is a directed action of one body on another • The action “tends to move” the body and depends on the magnitude, direction and point of application of the force • A force is represented by a vector: C.6 Properties of forces: opposition • Forces occur in equal and opposite pairs (Newton’s 3rd law), each having the same line of action and acting on different bodies • In mechanics, we consider two types of forces: – contact forces -

On the Logic Resolution of the Wave Particle Duality Paradox in Quantum Mechanics (Extended Abstract) M.A
On the logic resolution of the wave particle duality paradox in quantum mechanics (Extended abstract) M.A. Nait Abdallah To cite this version: M.A. Nait Abdallah. On the logic resolution of the wave particle duality paradox in quantum me- chanics (Extended abstract). 2016. hal-01303223 HAL Id: hal-01303223 https://hal.archives-ouvertes.fr/hal-01303223 Preprint submitted on 18 Apr 2016 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. On the logic resolution of the wave particle duality paradox in quantum mechanics (Extended abstract) M.A. Nait Abdallah UWO, London, Canada and INRIA, Paris, France Abstract. In this paper, we consider three landmark experiments of quantum physics and discuss the related wave particle duality paradox. We present a formalization, in terms of formal logic, of single photon self- interference. We show that the wave particle duality paradox appears, from the logic point of view, in the form of two distinct fallacies: the hard information fallacy and the exhaustive disjunction fallacy. We show that each fallacy points out some fundamental aspect of quantum physical systems and we present a logic solution to the paradox.