On Effectiveness of Compressed File Transfers To/From the Cloud: an Experimental Evaluation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Package 'Brotli'
Package ‘brotli’ May 13, 2018 Type Package Title A Compression Format Optimized for the Web Version 1.2 Description A lossless compressed data format that uses a combination of the LZ77 algorithm and Huffman coding. Brotli is similar in speed to deflate (gzip) but offers more dense compression. License MIT + file LICENSE URL https://tools.ietf.org/html/rfc7932 (spec) https://github.com/google/brotli#readme (upstream) http://github.com/jeroen/brotli#read (devel) BugReports http://github.com/jeroen/brotli/issues VignetteBuilder knitr, R.rsp Suggests spelling, knitr, R.rsp, microbenchmark, rmarkdown, ggplot2 RoxygenNote 6.0.1 Language en-US NeedsCompilation yes Author Jeroen Ooms [aut, cre] (<https://orcid.org/0000-0002-4035-0289>), Google, Inc [aut, cph] (Brotli C++ library) Maintainer Jeroen Ooms <[email protected]> Repository CRAN Date/Publication 2018-05-13 20:31:43 UTC R topics documented: brotli . .2 Index 4 1 2 brotli brotli Brotli Compression Description Brotli is a compression algorithm optimized for the web, in particular small text documents. Usage brotli_compress(buf, quality = 11, window = 22) brotli_decompress(buf) Arguments buf raw vector with data to compress/decompress quality value between 0 and 11 window log of window size Details Brotli decompression is at least as fast as for gzip while significantly improving the compression ratio. The price we pay is that compression is much slower than gzip. Brotli is therefore most effective for serving static content such as fonts and html pages. For binary (non-text) data, the compression ratio of Brotli usually does not beat bz2 or xz (lzma), however decompression for these algorithms is too slow for browsers in e.g. -
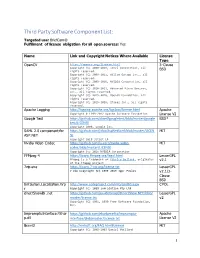
Third Party Software Component List: Targeted Use: Briefcam® Fulfillment of License Obligation for All Open Sources: Yes
Third Party Software Component List: Targeted use: BriefCam® Fulfillment of license obligation for all open sources: Yes Name Link and Copyright Notices Where Available License Type OpenCV https://opencv.org/license.html 3-Clause Copyright (C) 2000-2019, Intel Corporation, all BSD rights reserved. Copyright (C) 2009-2011, Willow Garage Inc., all rights reserved. Copyright (C) 2009-2016, NVIDIA Corporation, all rights reserved. Copyright (C) 2010-2013, Advanced Micro Devices, Inc., all rights reserved. Copyright (C) 2015-2016, OpenCV Foundation, all rights reserved. Copyright (C) 2015-2016, Itseez Inc., all rights reserved. Apache Logging http://logging.apache.org/log4cxx/license.html Apache Copyright © 1999-2012 Apache Software Foundation License V2 Google Test https://github.com/abseil/googletest/blob/master/google BSD* test/LICENSE Copyright 2008, Google Inc. SAML 2.0 component for https://github.com/jitbit/AspNetSaml/blob/master/LICEN MIT ASP.NET SE Copyright 2018 Jitbit LP Nvidia Video Codec https://github.com/lu-zero/nvidia-video- MIT codec/blob/master/LICENSE Copyright (c) 2016 NVIDIA Corporation FFMpeg 4 https://www.ffmpeg.org/legal.html LesserGPL FFmpeg is a trademark of Fabrice Bellard, originator v2.1 of the FFmpeg project 7zip.exe https://www.7-zip.org/license.txt LesserGPL 7-Zip Copyright (C) 1999-2019 Igor Pavlov v2.1/3- Clause BSD Infralution.Localization.Wp http://www.codeproject.com/info/cpol10.aspx CPOL f Copyright (C) 2018 Infralution Pty Ltd directShowlib .net https://github.com/pauldotknopf/DirectShow.NET/blob/ LesserGPL -

ROOT I/O Compression Improvements for HEP Analysis
EPJ Web of Conferences 245, 02017 (2020) https://doi.org/10.1051/epjconf/202024502017 CHEP 2019 ROOT I/O compression improvements for HEP analysis Oksana Shadura1;∗ Brian Paul Bockelman2;∗∗ Philippe Canal3;∗∗∗ Danilo Piparo4;∗∗∗∗ and Zhe Zhang1;y 1University of Nebraska-Lincoln, 1400 R St, Lincoln, NE 68588, United States 2Morgridge Institute for Research, 330 N Orchard St, Madison, WI 53715, United States 3Fermilab, Kirk Road and Pine St, Batavia, IL 60510, United States 4CERN, Meyrin 1211, Geneve, Switzerland Abstract. We overview recent changes in the ROOT I/O system, enhancing it by improving its performance and interaction with other data analysis ecosys- tems. Both the newly introduced compression algorithms, the much faster bulk I/O data path, and a few additional techniques have the potential to significantly improve experiment’s software performance. The need for efficient lossless data compression has grown significantly as the amount of HEP data collected, transmitted, and stored has dramatically in- creased over the last couple of years. While compression reduces storage space and, potentially, I/O bandwidth usage, it should not be applied blindly, because there are significant trade-offs between the increased CPU cost for reading and writing files and the reduces storage space. 1 Introduction In the past years, Large Hadron Collider (LHC) experiments are managing about an exabyte of storage for analysis purposes, approximately half of which is stored on tape storages for archival purposes, and half is used for traditional disk storage. Meanwhile for High Lumi- nosity Large Hadron Collider (HL-LHC) storage requirements per year are expected to be increased by a factor of 10 [1]. -
![Arxiv:2004.10531V1 [Cs.OH] 8 Apr 2020](https://docslib.b-cdn.net/cover/5419/arxiv-2004-10531v1-cs-oh-8-apr-2020-215419.webp)
Arxiv:2004.10531V1 [Cs.OH] 8 Apr 2020
ROOT I/O compression improvements for HEP analysis Oksana Shadura1;∗ Brian Paul Bockelman2;∗∗ Philippe Canal3;∗∗∗ Danilo Piparo4;∗∗∗∗ and Zhe Zhang1;y 1University of Nebraska-Lincoln, 1400 R St, Lincoln, NE 68588, United States 2Morgridge Institute for Research, 330 N Orchard St, Madison, WI 53715, United States 3Fermilab, Kirk Road and Pine St, Batavia, IL 60510, United States 4CERN, Meyrin 1211, Geneve, Switzerland Abstract. We overview recent changes in the ROOT I/O system, increasing per- formance and enhancing it and improving its interaction with other data analy- sis ecosystems. Both the newly introduced compression algorithms, the much faster bulk I/O data path, and a few additional techniques have the potential to significantly to improve experiment’s software performance. The need for efficient lossless data compression has grown significantly as the amount of HEP data collected, transmitted, and stored has dramatically in- creased during the LHC era. While compression reduces storage space and, potentially, I/O bandwidth usage, it should not be applied blindly: there are sig- nificant trade-offs between the increased CPU cost for reading and writing files and the reduce storage space. 1 Introduction In the past years LHC experiments are commissioned and now manages about an exabyte of storage for analysis purposes, approximately half of which is used for archival purposes, and half is used for traditional disk storage. Meanwhile for HL-LHC storage requirements per year are expected to be increased by factor 10 [1]. arXiv:2004.10531v1 [cs.OH] 8 Apr 2020 Looking at these predictions, we would like to state that storage will remain one of the major cost drivers and at the same time the bottlenecks for HEP computing. -

Metadefender Core V4.12.2
MetaDefender Core v4.12.2 © 2018 OPSWAT, Inc. All rights reserved. OPSWAT®, MetadefenderTM and the OPSWAT logo are trademarks of OPSWAT, Inc. All other trademarks, trade names, service marks, service names, and images mentioned and/or used herein belong to their respective owners. Table of Contents About This Guide 13 Key Features of Metadefender Core 14 1. Quick Start with Metadefender Core 15 1.1. Installation 15 Operating system invariant initial steps 15 Basic setup 16 1.1.1. Configuration wizard 16 1.2. License Activation 21 1.3. Scan Files with Metadefender Core 21 2. Installing or Upgrading Metadefender Core 22 2.1. Recommended System Requirements 22 System Requirements For Server 22 Browser Requirements for the Metadefender Core Management Console 24 2.2. Installing Metadefender 25 Installation 25 Installation notes 25 2.2.1. Installing Metadefender Core using command line 26 2.2.2. Installing Metadefender Core using the Install Wizard 27 2.3. Upgrading MetaDefender Core 27 Upgrading from MetaDefender Core 3.x 27 Upgrading from MetaDefender Core 4.x 28 2.4. Metadefender Core Licensing 28 2.4.1. Activating Metadefender Licenses 28 2.4.2. Checking Your Metadefender Core License 35 2.5. Performance and Load Estimation 36 What to know before reading the results: Some factors that affect performance 36 How test results are calculated 37 Test Reports 37 Performance Report - Multi-Scanning On Linux 37 Performance Report - Multi-Scanning On Windows 41 2.6. Special installation options 46 Use RAMDISK for the tempdirectory 46 3. Configuring Metadefender Core 50 3.1. Management Console 50 3.2. -

A Novel Coding Architecture for Multi-Line Lidar Point Clouds
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination. IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS 1 A Novel Coding Architecture for Multi-Line LiDAR Point Clouds Based on Clustering and Convolutional LSTM Network Xuebin Sun , Sukai Wang , Graduate Student Member, IEEE, and Ming Liu , Senior Member, IEEE Abstract— Light detection and ranging (LiDAR) plays an preservation of historical relics, 3D sensing for smart city, indispensable role in autonomous driving technologies, such as well as autonomous driving. Especially for autonomous as localization, map building, navigation and object avoidance. driving systems, LiDAR sensors play an indispensable role However, due to the vast amount of data, transmission and storage could become an important bottleneck. In this article, in a large number of key techniques, such as simultaneous we propose a novel compression architecture for multi-line localization and mapping (SLAM) [1], path planning [2], LiDAR point cloud sequences based on clustering and convolu- obstacle avoidance [3], and navigation. A point cloud consists tional long short-term memory (LSTM) networks. LiDAR point of a set of individual 3D points, in accordance with one or clouds are structured, which provides an opportunity to convert more attributes (color, reflectance, surface normal, etc). For the 3D data to 2D array, represented as range images. Thus, we cast the 3D point clouds compression as a range image instance, the Velodyne HDL-64E LiDAR sensor generates a sequence compression problem. Inspired by the high efficiency point cloud of up to 2.2 billion points per second, with a video coding (HEVC) algorithm, we design a novel compression range of up to 120 m. -

Unfoldr Dstep
Asymmetric Numeral Systems Jeremy Gibbons WG2.11#19 Salem ANS 2 1. Coding Huffman coding (HC) • efficient; optimally effective for bit-sequence-per-symbol arithmetic coding (AC) • Shannon-optimal (fractional entropy); but computationally expensive asymmetric numeral systems (ANS) • efficiency of Huffman, effectiveness of arithmetic coding applications of streaming (another story) • ANS introduced by Jarek Duda (2006–2013). Now: Facebook (Zstandard), Apple (LZFSE), Google (Draco), Dropbox (DivANS). ANS 3 2. Intervals Pairs of rationals type Interval (Rational, Rational) = with operations unit (0, 1) = weight (l, r) x l (r l) x = + − ⇥ narrow i (p, q) (weight i p, weight i q) = scale (l, r) x (x l)/(r l) = − − widen i (p, q) (scale i p, scale i q) = so that narrow and unit form a monoid, and inverse relationships: weight i x i x unit 2 () 2 weight i x y scale i y x = () = narrow i j k widen i k j = () = ANS 4 3. Models Given counts :: [(Symbol, Integer)] get encodeSym :: Symbol Interval ! decodeSym :: Rational Symbol ! such that decodeSym x s x encodeSym s = () 2 1 1 1 1 Eg alphabet ‘a’, ‘b’, ‘c’ with counts 2, 3, 5 encoded as (0, /5), ( /5, /2), and ( /2, 1). { } ANS 5 4. Arithmetic coding encode1 :: [Symbol ] Rational ! encode1 pick foldl estep unit where = ◦ 1 estep :: Interval Symbol Interval 1 ! ! estep is narrow i (encodeSym s) 1 = decode1 :: Rational [Symbol ] ! decode1 unfoldr dstep where = 1 dstep :: Rational Maybe (Symbol, Rational) 1 ! dstep x let s decodeSym x in Just (s, scale (encodeSym s) x) 1 = = where pick :: Interval Rational satisfies pick i i. -

Compresso: Efficient Compression of Segmentation Data for Connectomics
Compresso: Efficient Compression of Segmentation Data For Connectomics Brian Matejek, Daniel Haehn, Fritz Lekschas, Michael Mitzenmacher, Hanspeter Pfister Harvard University, Cambridge, MA 02138, USA bmatejek,haehn,lekschas,michaelm,[email protected] Abstract. Recent advances in segmentation methods for connectomics and biomedical imaging produce very large datasets with labels that assign object classes to image pixels. The resulting label volumes are bigger than the raw image data and need compression for efficient stor- age and transfer. General-purpose compression methods are less effective because the label data consists of large low-frequency regions with struc- tured boundaries unlike natural image data. We present Compresso, a new compression scheme for label data that outperforms existing ap- proaches by using a sliding window to exploit redundancy across border regions in 2D and 3D. We compare our method to existing compression schemes and provide a detailed evaluation on eleven biomedical and im- age segmentation datasets. Our method provides a factor of 600-2200x compression for label volumes, with running times suitable for practice. Keywords: compression, encoding, segmentation, connectomics 1 Introduction Connectomics|reconstructing the wiring diagram of a mammalian brain at nanometer resolution|results in datasets at the scale of petabytes [21,8]. Ma- chine learning methods find cell membranes and create cell body labelings for every neuron [18,12,14] (Fig. 1). These segmentations are stored as label volumes that are typically encoded in 32 bits or 64 bits per voxel to support labeling of millions of different nerve cells (neurons). Storing such data is expensive and transferring the data is slow. To cut costs and delays, we need compression methods to reduce data sizes. -

Redalyc.A Lossy Method for Compressing Raw CCD Images
Revista Mexicana de Astronomía y Astrofísica ISSN: 0185-1101 [email protected] Instituto de Astronomía México Watson, Alan M. A Lossy Method for Compressing Raw CCD Images Revista Mexicana de Astronomía y Astrofísica, vol. 38, núm. 2, octubre, 2002, pp. 233-249 Instituto de Astronomía Distrito Federal, México Available in: http://www.redalyc.org/articulo.oa?id=57138212 How to cite Complete issue Scientific Information System More information about this article Network of Scientific Journals from Latin America, the Caribbean, Spain and Portugal Journal's homepage in redalyc.org Non-profit academic project, developed under the open access initiative Revista Mexicana de Astronom´ıa y Astrof´ısica, 38, 233{249 (2002) A LOSSY METHOD FOR COMPRESSING RAW CCD IMAGES Alan M. Watson Instituto de Astronom´ıa Universidad Nacional Aut´onoma de M´exico, Campus Morelia, M´exico Received 2002 June 3; accepted 2002 August 7 RESUMEN Se presenta un m´etodo para comprimir las im´agenes en bruto de disposi- tivos como los CCD. El m´etodo es muy sencillo: cuantizaci´on con p´erdida y luego compresi´on sin p´erdida con herramientas de uso general como gzip o bzip2. Se convierten los archivos comprimidos a archivos de FITS descomprimi´endolos con gunzip o bunzip2, lo cual es una ventaja importante en la distribuci´on de datos com- primidos. El grado de cuantizaci´on se elige para eliminar los bits de bajo orden, los cuales sobre-muestrean el ruido, no proporcionan informaci´on, y son dif´ıciles o imposibles de comprimir. El m´etodo es con p´erdida, pero proporciona ciertas garant´ıas sobre la diferencia absoluta m´axima, la diferencia RMS y la diferencia promedio entre la imagen comprimida y la imagen original; tales garant´ıas implican que el m´etodo es adecuado para comprimir im´agenes en bruto. -

Data Latency and Compression
Data Latency and Compression Joseph M. Steim1, Edelvays N. Spassov2 1Quanterra Inc., 2Kinemetrics, Inc. Abstract DIscussion More Compression Because of interest in the capability of digital seismic data systems to provide low-latency data for “Early Compression and Latency related to Origin Queuing[5] Lossless Lempel-Ziv (LZ) compression methods (e.g. gzip, 7zip, and more recently “brotli” introduced by Warning” applications, we have examined the effect of data compression on the ability of systems to Plausible data compression methods reduce the volume (number of bits) required to represent each data Google for web-page compression) are often used for lossless compression of binary and text files. How deliver data with low latency, and on the efficiency of data storage and telemetry systems. Quanterra Q330 sample. Compression of data therefore always reduces the minimum required bandwidth (bits/sec) for does the best example of modern LZ methods compare with FDSN Level 1 and 2 for waveform data? systems are widely used in telemetered networks, and are considered in particular. transmission compared with transmission of uncompressed data. The volume required to transmit Segments of data representing up to one month of various levels of compressibility were compressed using compressed data is variable, depending on characteristics of the data. Higher levels of compression require Levels 1,2 and 3, and brotli using “quality” 1 and 6. The compression ratio (relative to the original 32 bits) Q330 data acquisition systems transmit data compressed in Steim2-format packets. Some studies have less minimum bandwidth and volume, and maximize the available unused (“free”) bandwidth for shows that in all cases the compression using L1,L2, or L3 is significantly greater than brotli. -

Parquet Data Format Performance
Parquet data format performance Jim Pivarski Princeton University { DIANA-HEP February 21, 2018 1 / 22 What is Parquet? 1974 HBOOK tabular rowwise FORTRAN first ntuples in HEP 1983 ZEBRA hierarchical rowwise FORTRAN event records in HEP 1989 PAW CWN tabular columnar FORTRAN faster ntuples in HEP 1995 ROOT hierarchical columnar C++ object persistence in HEP 2001 ProtoBuf hierarchical rowwise many Google's RPC protocol 2002 MonetDB tabular columnar database “first” columnar database 2005 C-Store tabular columnar database also early, became HP's Vertica 2007 Thrift hierarchical rowwise many Facebook's RPC protocol 2009 Avro hierarchical rowwise many Hadoop's object permanance and interchange format 2010 Dremel hierarchical columnar C++, Java Google's nested-object database (closed source), became BigQuery 2013 Parquet hierarchical columnar many open source object persistence, based on Google's Dremel paper 2016 Arrow hierarchical columnar many shared-memory object exchange 2 / 22 What is Parquet? 1974 HBOOK tabular rowwise FORTRAN first ntuples in HEP 1983 ZEBRA hierarchical rowwise FORTRAN event records in HEP 1989 PAW CWN tabular columnar FORTRAN faster ntuples in HEP 1995 ROOT hierarchical columnar C++ object persistence in HEP 2001 ProtoBuf hierarchical rowwise many Google's RPC protocol 2002 MonetDB tabular columnar database “first” columnar database 2005 C-Store tabular columnar database also early, became HP's Vertica 2007 Thrift hierarchical rowwise many Facebook's RPC protocol 2009 Avro hierarchical rowwise many Hadoop's object permanance and interchange format 2010 Dremel hierarchical columnar C++, Java Google's nested-object database (closed source), became BigQuery 2013 Parquet hierarchical columnar many open source object persistence, based on Google's Dremel paper 2016 Arrow hierarchical columnar many shared-memory object exchange 2 / 22 Developed independently to do the same thing Google Dremel authors claimed to be unaware of any precedents, so this is an example of convergent evolution. -

The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on Iot Nodes in Smart Cities
sensors Article The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on IoT Nodes in Smart Cities Ammar Nasif *, Zulaiha Ali Othman and Nor Samsiah Sani Center for Artificial Intelligence Technology (CAIT), Faculty of Information Science & Technology, University Kebangsaan Malaysia, Bangi 43600, Malaysia; [email protected] (Z.A.O.); [email protected] (N.S.S.) * Correspondence: [email protected] Abstract: Networking is crucial for smart city projects nowadays, as it offers an environment where people and things are connected. This paper presents a chronology of factors on the development of smart cities, including IoT technologies as network infrastructure. Increasing IoT nodes leads to increasing data flow, which is a potential source of failure for IoT networks. The biggest challenge of IoT networks is that the IoT may have insufficient memory to handle all transaction data within the IoT network. We aim in this paper to propose a potential compression method for reducing IoT network data traffic. Therefore, we investigate various lossless compression algorithms, such as entropy or dictionary-based algorithms, and general compression methods to determine which algorithm or method adheres to the IoT specifications. Furthermore, this study conducts compression experiments using entropy (Huffman, Adaptive Huffman) and Dictionary (LZ77, LZ78) as well as five different types of datasets of the IoT data traffic. Though the above algorithms can alleviate the IoT data traffic, adaptive Huffman gave the best compression algorithm. Therefore, in this paper, Citation: Nasif, A.; Othman, Z.A.; we aim to propose a conceptual compression method for IoT data traffic by improving an adaptive Sani, N.S.