What Is the Role of Histone H1 Heterogeneity? a Functional Model Emerges from a 50 Year Mystery
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How Human H1 Histone Recognizes DNA
molecules Article How Human H1 Histone Recognizes DNA Olesya P. Luzhetskaya, Sergey E. Sedykh and Georgy A. Nevinsky * Institute of Chemical Biology and Fundamental Medicine, SD of Russian Academy of Sciences, 8 Lavrentiev Ave., 630090 Novosibirsk, Russia; [email protected] (O.P.L.); [email protected] (S.E.S.) * Correspondence: [email protected]; Tel.: +7-383-363-51-26; Fax: +7-383-363-51-53 Received: 11 August 2020; Accepted: 1 October 2020; Published: 5 October 2020 Abstract: Linker H1 histone is one of the five main histone proteins (H1, H2A, H2B, H3, and H4), which are components of chromatin in eukaryotic cells. Here we have analyzed the patterns of DNA recognition by free H1 histone using a stepwise increase of the ligand complexity method; the affinity of H1 histone for various single- and double-stranded oligonucleotides (d(pN)n; n = 1–20) was evaluated using their competition with 12-mer [32P]labeled oligonucleotide and protein–oligonucleotide complex delaying on nitrocellulose membrane filters. It was shown that minimal ligands of H1 histone (like other DNA-dependent proteins and enzymes) are different mononucleotides (dNMPs; Kd = (1.30 0.2) 2 ± 10 M). An increase in the length of single-stranded (ss) homo- and hetero-oligonucleotides (d(pA)n, × − d(pT)n, d(pC)n, and d(pN)n with different bases) by one nucleotide link regardless of their bases, leads to a monotonic increase in their affinity by a factor of f = 3.0 0.2. This factor f corresponds ± to the Kd value = 1/f characterizing the affinity of one nucleotide of different ss d(pN)n for H1 at n = 2–6 (which are covered by this protein globule) is approximately 0.33 0.02 M. -
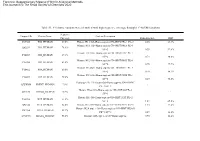
Table S1. 49 Histone Variants Were Identified with High Sequence Coverage Through LC-MS/MS Analysis Electronic Supplementary
Electronic Supplementary Material (ESI) for Analytical Methods. This journal is © The Royal Society of Chemistry 2020 Table S1. 49 histone variants were identified with high sequence coverage through LC-MS/MS analysis Sequence Uniprot IDs Protein Name Protein Description Coverage Ratio E2+/E2- RSD P07305 H10_HUMAN 67.5% Histone H1.0 OS=Homo sapiens GN=H1F0 PE=1 SV=3 4.85 23.3% Histone H1.1 OS=Homo sapiens GN=HIST1H1A PE=1 Q02539 H11_HUMAN 74.4% SV=3 0.35 92.6% Histone H1.2 OS=Homo sapiens GN=HIST1H1C PE=1 P16403 H12_HUMAN 67.1% SV=2 0.73 80.6% Histone H1.3 OS=Homo sapiens GN=HIST1H1D PE=1 P16402 H13_HUMAN 63.8% SV=2 0.75 77.7% Histone H1.4 OS=Homo sapiens GN=HIST1H1E PE=1 P10412 H14_HUMAN 69.0% SV=2 0.70 80.3% Histone H1.5 OS=Homo sapiens GN=HIST1H1B PE=1 P16401 H15_HUMAN 79.6% SV=3 0.29 98.3% Testis-specific H1 histone OS=Homo sapiens GN=H1FNT Q75WM6 H1FNT_HUMAN 7.8% \ \ PE=2 SV=3 Histone H1oo OS=Homo sapiens GN=H1FOO PE=2 Q8IZA3 H1FOO_HUMAN 5.2% \ \ SV=1 Histone H1t OS=Homo sapiens GN=HIST1H1T PE=2 P22492 H1T_HUMAN 31.4% SV=4 1.42 65.0% Q92522 H1X_HUMAN 82.6% Histone H1x OS=Homo sapiens GN=H1FX PE=1 SV=1 1.15 33.2% Histone H2A type 1 OS=Homo sapiens GN=HIST1H2AG P0C0S8 H2A1_HUMAN 99.2% PE=1 SV=2 0.57 26.8% Q96QV6 H2A1A_HUMAN 58.0% Histone H2A type 1-A OS=Homo sapiens 0.90 11.2% GN=HIST1H2AA PE=1 SV=3 Histone H2A type 1-B/E OS=Homo sapiens P04908 H2A1B_HUMAN 99.2% GN=HIST1H2AB PE=1 SV=2 0.92 30.2% Histone H2A type 1-C OS=Homo sapiens Q93077 H2A1C_HUMAN 100.0% GN=HIST1H2AC PE=1 SV=3 0.76 27.6% Histone H2A type 1-D OS=Homo sapiens P20671 -

UNIVERSITY of CALIFORNIA, SAN DIEGO Functional Analysis of Sall4
UNIVERSITY OF CALIFORNIA, SAN DIEGO Functional analysis of Sall4 in modulating embryonic stem cell fate A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Molecular Pathology by Pei Jen A. Lee Committee in charge: Professor Steven Briggs, Chair Professor Geoff Rosenfeld, Co-Chair Professor Alexander Hoffmann Professor Randall Johnson Professor Mark Mercola 2009 Copyright Pei Jen A. Lee, 2009 All rights reserved. The dissertation of Pei Jen A. Lee is approved, and it is acceptable in quality and form for publication on microfilm and electronically: ______________________________________________________________ ______________________________________________________________ ______________________________________________________________ ______________________________________________________________ Co-Chair ______________________________________________________________ Chair University of California, San Diego 2009 iii Dedicated to my parents, my brother ,and my husband for their love and support iv Table of Contents Signature Page……………………………………………………………………….…iii Dedication…...…………………………………………………………………………..iv Table of Contents……………………………………………………………………….v List of Figures…………………………………………………………………………...vi List of Tables………………………………………………….………………………...ix Curriculum vitae…………………………………………………………………………x Acknowledgement………………………………………………….……….……..…...xi Abstract………………………………………………………………..…………….....xiii Chapter 1 Introduction ..…………………………………………………………………………….1 Chapter 2 Materials and Methods……………………………………………………………..…12 -

Transcriptome Analyses of Rhesus Monkey Pre-Implantation Embryos Reveal A
Downloaded from genome.cshlp.org on September 23, 2021 - Published by Cold Spring Harbor Laboratory Press Transcriptome analyses of rhesus monkey pre-implantation embryos reveal a reduced capacity for DNA double strand break (DSB) repair in primate oocytes and early embryos Xinyi Wang 1,3,4,5*, Denghui Liu 2,4*, Dajian He 1,3,4,5, Shengbao Suo 2,4, Xian Xia 2,4, Xiechao He1,3,6, Jing-Dong J. Han2#, Ping Zheng1,3,6# Running title: reduced DNA DSB repair in monkey early embryos Affiliations: 1 State Key Laboratory of Genetic Resources and Evolution, Kunming Institute of Zoology, Chinese Academy of Sciences, Kunming, Yunnan 650223, China 2 Key Laboratory of Computational Biology, CAS Center for Excellence in Molecular Cell Science, Collaborative Innovation Center for Genetics and Developmental Biology, Chinese Academy of Sciences-Max Planck Partner Institute for Computational Biology, Shanghai Institutes for Biological Sciences, Chinese Academy of Sciences, Shanghai 200031, China 3 Yunnan Key Laboratory of Animal Reproduction, Kunming Institute of Zoology, Chinese Academy of Sciences, Kunming, Yunnan 650223, China 4 University of Chinese Academy of Sciences, Beijing, China 5 Kunming College of Life Science, University of Chinese Academy of Sciences, Kunming, Yunnan 650204, China 6 Primate Research Center, Kunming Institute of Zoology, Chinese Academy of Sciences, Kunming, 650223, China * Xinyi Wang and Denghui Liu contributed equally to this work 1 Downloaded from genome.cshlp.org on September 23, 2021 - Published by Cold Spring Harbor Laboratory Press # Correspondence: Jing-Dong J. Han, Email: [email protected]; Ping Zheng, Email: [email protected] Key words: rhesus monkey, pre-implantation embryo, DNA damage 2 Downloaded from genome.cshlp.org on September 23, 2021 - Published by Cold Spring Harbor Laboratory Press ABSTRACT Pre-implantation embryogenesis encompasses several critical events including genome reprogramming, zygotic genome activation (ZGA) and cell fate commitment. -

Histone H1 Is Essential for Mitotic Chromosome Architecture
Published Online: 20 June, 2005 | Supp Info: http://doi.org/10.1083/jcb.200503031 JCB: ARTICLE Downloaded from jcb.rupress.org on May 12, 2019 Histone H1 is essential for mitotic chromosome architecture and segregation in Xenopus laevis egg extracts Thomas J. Maresca, Benjamin S. Freedman, and Rebecca Heald Department of Molecular and Cell Biology, University of California, Berkeley, Berkeley, CA 94720 uring cell division, condensation and resolution of spindle. Although functional kinetochores assembled, chromosome arms and the assembly of a func- aligned, and exhibited poleward movement, long and D tional kinetochore at the centromere of each sister tangled chromosome arms could not be segregated in chromatid are essential steps for accurate segregation of anaphase. Histone H1 depletion did not significantly affect the genome by the mitotic spindle, yet the contribution of the recruitment of known structural or functional chromo- individual chromatin proteins to these processes is poorly somal components such as condensins or chromokinesins, understood. We have investigated the role of embryonic suggesting that the loss of H1 affects chromosome archi- linker histone H1 during mitosis in Xenopus laevis egg tecture directly. Thus, our results indicate that linker histone extracts. Immunodepletion of histone H1 caused the assem- H1 plays an important role in the structure and function of bly of aberrant elongated chromosomes that extended off vertebrate chromosomes in mitosis. the metaphase plate and outside the perimeter of the Introduction Correct transmission of the genome by the mitotic spindle complexes condensin and cohesin, which are thought to form during cell division requires dramatic changes in chromosome ring structures that generate chromosome super coiling or architecture. -

Tricarboxylic Acid Cycle Metabolites As Mediators of DNA Methylation Reprogramming in Bovine Preimplantation Embryos
Supplementary Materials Tricarboxylic Acid Cycle Metabolites as Mediators of DNA Methylation Reprogramming in Bovine Preimplantation Embryos Figure S1. (A) Total number of cells in fast (FBL) and slow (SBL) blastocysts; (B) Fluorescence intensity for 5-methylcytosine and 5-hydroxymethylcytosine of fast and slow blastocysts of cells from Trophoectoderm (TE) or inner cell mass (ICM). Fluorescence intensity for 5-methylcytosine of cells from the ICM or TE in blastocysts cultured with (C) dimethyl-succinate or (D) dimethyl-α- ketoglutarate. Statistical significance is identified by different letters. Figure S2. Experimental design. Table S1. Selected genes related to metabolism and epigenetic mechanisms from RNA-Seq analysis of bovine blastocysts (slow vs. fast). Genes in blue represent upregulation in slow blastocysts, genes in red represent upregulation in fast blastocysts. log2FoldCh Gene p-value p-Adj ange PDHB −1.425 0.000 0.000 MDH1 −1.206 0.000 0.000 APEX1 −1.193 0.000 0.000 OGDHL −3.417 0.000 0.002 PGK1 −0.942 0.000 0.002 GLS2 1.493 0.000 0.002 AICDA 1.171 0.001 0.005 ACO2 0.693 0.002 0.011 CS −0.660 0.002 0.011 SLC25A1 1.181 0.007 0.032 IDH3A −0.728 0.008 0.035 GSS 1.039 0.013 0.053 TET3 0.662 0.026 0.093 GLUD1 −0.450 0.032 0.108 SDHD −0.619 0.049 0.143 FH −0.547 0.054 0.149 OGDH 0.316 0.133 0.287 ACO1 −0.364 0.141 0.297 SDHC −0.335 0.149 0.311 LIG3 0.338 0.165 0.334 SUCLG −0.332 0.174 0.349 SDHA 0.297 0.210 0.396 SUCLA2 −0.324 0.248 0.439 DNMT1 0.266 0.279 0.486 IDH3B1 −0.269 0.296 0.503 SDHB −0.213 0.339 0.544 DNMT3B 0.181 0.386 0.598 APOBEC1 0.629 0.386 0.598 TDG 0.427 0.398 0.611 IDH3G 0.237 0.468 0.675 NEIL2 0.509 0.572 0.720 IDH2 0.298 0.571 0.720 DNMT3L 1.306 0.590 0.722 GLS 0.120 0.706 0.821 XRCC1 0.108 0.793 0.887 TET1 −0.028 0.879 0.919 DNMT3A 0.029 0.893 0.920 MBD4 −0.056 0.885 0.920 PDHX 0.033 0.890 0.920 SMUG1 0.053 0.936 0.954 TET2 −0.002 0.991 0.991 Table S2. -

Noninvasive Sleep Monitoring in Large-Scale Screening of Knock-Out Mice
bioRxiv preprint doi: https://doi.org/10.1101/517680; this version posted January 11, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-ND 4.0 International license. Noninvasive sleep monitoring in large-scale screening of knock-out mice reveals novel sleep-related genes Shreyas S. Joshi1*, Mansi Sethi1*, Martin Striz1, Neil Cole2, James M. Denegre2, Jennifer Ryan2, Michael E. Lhamon3, Anuj Agarwal3, Steve Murray2, Robert E. Braun2, David W. Fardo4, Vivek Kumar2, Kevin D. Donohue3,5, Sridhar Sunderam6, Elissa J. Chesler2, Karen L. Svenson2, Bruce F. O'Hara1,3 1Dept. of Biology, University of Kentucky, Lexington, KY 40506, USA, 2The Jackson Laboratory, Bar Harbor, ME 04609, USA, 3Signal solutions, LLC, Lexington, KY 40503, USA, 4Dept. of Biostatistics, University of Kentucky, Lexington, KY 40536, USA, 5Dept. of Electrical and Computer Engineering, University of Kentucky, Lexington, KY 40506, USA. 6Dept. of Biomedical Engineering, University of Kentucky, Lexington, KY 40506, USA. *These authors contributed equally Address for correspondence and proofs: Shreyas S. Joshi, Ph.D. Dept. of Biology University of Kentucky 675 Rose Street 101 Morgan Building Lexington, KY 40506 U.S.A. Phone: (859) 257-2805 FAX: (859) 257-1717 Email: [email protected] Running title: Sleep changes in knockout mice bioRxiv preprint doi: https://doi.org/10.1101/517680; this version posted January 11, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. -

Download Download
Supplementary Figure S1. Results of flow cytometry analysis, performed to estimate CD34 positivity, after immunomagnetic separation in two different experiments. As monoclonal antibody for labeling the sample, the fluorescein isothiocyanate (FITC)- conjugated mouse anti-human CD34 MoAb (Mylteni) was used. Briefly, cell samples were incubated in the presence of the indicated MoAbs, at the proper dilution, in PBS containing 5% FCS and 1% Fc receptor (FcR) blocking reagent (Miltenyi) for 30 min at 4 C. Cells were then washed twice, resuspended with PBS and analyzed by a Coulter Epics XL (Coulter Electronics Inc., Hialeah, FL, USA) flow cytometer. only use Non-commercial 1 Supplementary Table S1. Complete list of the datasets used in this study and their sources. GEO Total samples Geo selected GEO accession of used Platform Reference series in series samples samples GSM142565 GSM142566 GSM142567 GSM142568 GSE6146 HG-U133A 14 8 - GSM142569 GSM142571 GSM142572 GSM142574 GSM51391 GSM51392 GSE2666 HG-U133A 36 4 1 GSM51393 GSM51394 only GSM321583 GSE12803 HG-U133A 20 3 GSM321584 2 GSM321585 use Promyelocytes_1 Promyelocytes_2 Promyelocytes_3 Promyelocytes_4 HG-U133A 8 8 3 GSE64282 Promyelocytes_5 Promyelocytes_6 Promyelocytes_7 Promyelocytes_8 Non-commercial 2 Supplementary Table S2. Chromosomal regions up-regulated in CD34+ samples as identified by the LAP procedure with the two-class statistics coded in the PREDA R package and an FDR threshold of 0.5. Functional enrichment analysis has been performed using DAVID (http://david.abcc.ncifcrf.gov/) -

Co-Occurrence Based Meta-Analysis of Scientific Texts
Vol. 21 no. 9 2005, pages 2049–2058 BIOINFORMATICS ORIGINAL PAPER doi:10.1093/bioinformatics/bti268 Data and text mining Co-occurrence based meta-analysis of scientific texts: retrieving biological relationships between genes R. Jelier1,∗ G. Jenster2, L. C. J. Dorssers3, C. C. van der Eijk1, E. M. van Mulligen1, B. Mons1 and J. A. Kors1 1Department of Medical Informatics, 2Department of Urology and 3Department of Pathology, Erasmus MC—University Medical Center, Rotterdam, The Netherlands Received on July 15, 2004; revised on December 22, 2004; accepted on January 6, 2005 Advance Access publication January 18, 2005 ABSTRACT are studied, the number of relevant publications will frequently be Motivation: The advent of high-throughput experiments in molecu- prohibitively large. This renders the traditional approach of manu- lar biology creates a need for methods to efficiently extract and use ally searching bibliographic databases for every gene and reading information for large numbers of genes. Recently, the associative scientific articles inadequate. It is therefore an important challenge concept space (ACS) has been developed for the representation of at this time to make the available information both accessible and information extracted from biomedical literature. The ACS is a Euc- interpretable for molecular biologists. lidean space in which thesaurus concepts are positioned and the An interesting current development is the use of annotations of distances between concepts indicates their relatedness. The ACS genes with gene ontology (GO) terms (Ashburner et al., 2000; Camon uses co-occurrence of concepts as a source of information. In this et al., 2004) for the analysis of the results of microarray experiments paper we evaluate how well the system can retrieve functionally (Zhang et al., 2004; Al Shahrour et al., 2004). -

Supplementary Materials
Supplementary materials Supplementary Table S1: MGNC compound library Ingredien Molecule Caco- Mol ID MW AlogP OB (%) BBB DL FASA- HL t Name Name 2 shengdi MOL012254 campesterol 400.8 7.63 37.58 1.34 0.98 0.7 0.21 20.2 shengdi MOL000519 coniferin 314.4 3.16 31.11 0.42 -0.2 0.3 0.27 74.6 beta- shengdi MOL000359 414.8 8.08 36.91 1.32 0.99 0.8 0.23 20.2 sitosterol pachymic shengdi MOL000289 528.9 6.54 33.63 0.1 -0.6 0.8 0 9.27 acid Poricoic acid shengdi MOL000291 484.7 5.64 30.52 -0.08 -0.9 0.8 0 8.67 B Chrysanthem shengdi MOL004492 585 8.24 38.72 0.51 -1 0.6 0.3 17.5 axanthin 20- shengdi MOL011455 Hexadecano 418.6 1.91 32.7 -0.24 -0.4 0.7 0.29 104 ylingenol huanglian MOL001454 berberine 336.4 3.45 36.86 1.24 0.57 0.8 0.19 6.57 huanglian MOL013352 Obacunone 454.6 2.68 43.29 0.01 -0.4 0.8 0.31 -13 huanglian MOL002894 berberrubine 322.4 3.2 35.74 1.07 0.17 0.7 0.24 6.46 huanglian MOL002897 epiberberine 336.4 3.45 43.09 1.17 0.4 0.8 0.19 6.1 huanglian MOL002903 (R)-Canadine 339.4 3.4 55.37 1.04 0.57 0.8 0.2 6.41 huanglian MOL002904 Berlambine 351.4 2.49 36.68 0.97 0.17 0.8 0.28 7.33 Corchorosid huanglian MOL002907 404.6 1.34 105 -0.91 -1.3 0.8 0.29 6.68 e A_qt Magnogrand huanglian MOL000622 266.4 1.18 63.71 0.02 -0.2 0.2 0.3 3.17 iolide huanglian MOL000762 Palmidin A 510.5 4.52 35.36 -0.38 -1.5 0.7 0.39 33.2 huanglian MOL000785 palmatine 352.4 3.65 64.6 1.33 0.37 0.7 0.13 2.25 huanglian MOL000098 quercetin 302.3 1.5 46.43 0.05 -0.8 0.3 0.38 14.4 huanglian MOL001458 coptisine 320.3 3.25 30.67 1.21 0.32 0.9 0.26 9.33 huanglian MOL002668 Worenine -

The Function and Evolution of C2H2 Zinc Finger Proteins and Transposons
The function and evolution of C2H2 zinc finger proteins and transposons by Laura Francesca Campitelli A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Department of Molecular Genetics University of Toronto © Copyright by Laura Francesca Campitelli 2020 The function and evolution of C2H2 zinc finger proteins and transposons Laura Francesca Campitelli Doctor of Philosophy Department of Molecular Genetics University of Toronto 2020 Abstract Transcription factors (TFs) confer specificity to transcriptional regulation by binding specific DNA sequences and ultimately affecting the ability of RNA polymerase to transcribe a locus. The C2H2 zinc finger proteins (C2H2 ZFPs) are a TF class with the unique ability to diversify their DNA-binding specificities in a short evolutionary time. C2H2 ZFPs comprise the largest class of TFs in Mammalian genomes, including nearly half of all Human TFs (747/1,639). Positive selection on the DNA-binding specificities of C2H2 ZFPs is explained by an evolutionary arms race with endogenous retroelements (EREs; copy-and-paste transposable elements), where the C2H2 ZFPs containing a KRAB repressor domain (KZFPs; 344/747 Human C2H2 ZFPs) are thought to diversify to bind new EREs and repress deleterious transposition events. However, evidence of the gain and loss of KZFP binding sites on the ERE sequence is sparse due to poor resolution of ERE sequence evolution, despite the recent publication of binding preferences for 242/344 Human KZFPs. The goal of my doctoral work has been to characterize the Human C2H2 ZFPs, with specific interest in their evolutionary history, functional diversity, and coevolution with LINE EREs. -

Genome-Wide DNA Methylation Analysis Reveals Molecular Subtypes of Pancreatic Cancer
www.impactjournals.com/oncotarget/ Oncotarget, 2017, Vol. 8, (No. 17), pp: 28990-29012 Research Paper Genome-wide DNA methylation analysis reveals molecular subtypes of pancreatic cancer Nitish Kumar Mishra1 and Chittibabu Guda1,2,3,4 1Department of Genetics, Cell Biology and Anatomy, University of Nebraska Medical Center, Omaha, NE, 68198, USA 2Bioinformatics and Systems Biology Core, University of Nebraska Medical Center, Omaha, NE, 68198, USA 3Department of Biochemistry and Molecular Biology, University of Nebraska Medical Center, Omaha, NE, 68198, USA 4Fred and Pamela Buffet Cancer Center, University of Nebraska Medical Center, Omaha, NE, 68198, USA Correspondence to: Chittibabu Guda, email: [email protected] Keywords: TCGA, pancreatic cancer, differential methylation, integrative analysis, molecular subtypes Received: October 20, 2016 Accepted: February 12, 2017 Published: March 07, 2017 Copyright: Mishra et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC-BY), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. ABSTRACT Pancreatic cancer (PC) is the fourth leading cause of cancer deaths in the United States with a five-year patient survival rate of only 6%. Early detection and treatment of this disease is hampered due to lack of reliable diagnostic and prognostic markers. Recent studies have shown that dynamic changes in the global DNA methylation and gene expression patterns play key roles in the PC development; hence, provide valuable insights for better understanding the initiation and progression of PC. In the current study, we used DNA methylation, gene expression, copy number, mutational and clinical data from pancreatic patients.