Rule-Based Role Analysis of Game Characters Using Tags About Characteristics for Strategy Estimation by Game AI
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Pokemon Buy List
Pokemon Buy List Card Name Set Rarity Cash Value Credit Value Absol EX - XY62 XY Promos Holofoil $1.04 $1.24 Acerola (Full Art) SM - Burning Shadows Holofoil $6.16 $7.39 Acro Bike (Secret) SM - Celestial Storm Holofoil $5.11 $6.13 Adventure Bag (Secret) SM - Lost Thunder Holofoil $2.72 $3.26 Aegislash EX XY - Phantom Forces Holofoil $1.06 $1.27 Aegislash V SWSH04: Vivid Voltage Holofoil $0.68 $0.82 Aegislash V (Full Art) SWSH04: Vivid Voltage Holofoil $3.96 $4.75 Aegislash VMAX SWSH04: Vivid Voltage Holofoil $1.07 $1.28 Aegislash VMAX (Secret) SWSH04: Vivid Voltage Holofoil $6.28 $7.54 Aerodactyl EX - XY97 XY Promos Holofoil $0.84 $1.00 Aerodactyl GX SM - Unified Minds Holofoil $0.88 $1.05 Aerodactyl GX (Full Art) SM - Unified Minds Holofoil $1.56 $1.87 Aerodactyl GX (Secret) SM - Unified Minds Holofoil $5.40 $6.48 Aether Foundation Employee Hidden Fates: Shiny Vault Holofoil $3.32 $3.98 Aggron EX XY - Primal Clash Holofoil $0.97 $1.16 Aggron EX (153 Full Art) XY - Primal Clash Holofoil $4.27 $5.12 Air Balloon (Secret) SWSH01: Sword & Shield Base Set Holofoil $4.57 $5.48 Alakazam EX XY - Fates Collide Holofoil $1.28 $1.53 Alakazam EX (Full Art) XY - Fates Collide Holofoil $3.37 $4.04 Alakazam EX (Secret) XY - Fates Collide Holofoil $5.32 $6.38 Alakazam V (Full Art) SWSH04: Vivid Voltage Holofoil $3.92 $4.70 Allister (Full Art) SWSH04: Vivid Voltage Holofoil $5.70 $6.84 Allister (Secret) SWSH04: Vivid Voltage Holofoil $7.99 $9.58 Alolan Exeggutor GX SM - Crimson Invasion Holofoil $0.80 $0.96 Alolan Exeggutor GX (Full Art) SM - Crimson Invasion -

Play! Pokémon Pokkén Tournament Championships Series Rules
Pokkén Tournament Championship Series Rules, Formats & Penalty Guidelines Date of last revision: January 6, 2020 NOTE: In the case of a discrepancy between the content of any English-language version of a document and that of any other version of that document, the English-language version shall take priority. Pokkén Tournament Championship Series Rules, Formats & Penalty Guidelines Contents 1. Introduction ............................................................................................................................... 3 1.1. Age Divisions ........................................................................................................................ 3 2. Match Setup .............................................................................................................................. 3 2.1. LAN Battle ............................................................................................................................. 3 2.2. Player Data ........................................................................................................................... 4 2.3. Matches, Games, and Rounds ............................................................................................. 4 2.4. Time Limits ........................................................................................................................... 4 2.5. VS Mode, Stage Select, and Skill Level ................................................................................ 4 2.6. Controller Settings .............................................................................................................. -

SUMMER CAMP PROJECTS MAY 20-24 Rolling Hills of Texas Monart School of Art | 4007 Bellaire Blvd
SUMMER CAMP PROJECTS MAY 20-24 Rolling hills of texas Monart School of Art | 4007 Bellaire Blvd. Suite FF, Houston, Texas 77025 MORNING CAMP | 8:30 – 11:30 AM All ages MIXED MEDIA MANIA Mountains and Cacti M Acrylic Paint on Canvas Herd of Texas Longhorns T Pencil and Ink South Prong Mountain Ranges W Pencil Color and Watercolor Cowboys in the Sunset R Acrylic on Canvas Lost Mine Trail F Chalk Pastels AFTERNOON CAMP | 1 – 4 PM All ages MIXED MEDIA MANIA Llano Texas M Acrylic Paint on Canvas Guadalupe Peak T Pencil and Ink Wild Horses in the Sunset W Acrylic on Canvas Blue Bonnet Fields R Watercolor and Pointillism F Texas Longhorns in the Green Fields PRICES AND INFORMATION PRICES PER STUDENT SNACKS AND WATER We provide mid-morning and mid-afternoon snacks (fruit Single All 5 snacks, Goldfish, and Animal Crackers) and juice. We also day days have a water dispenser on campus. Students may bring Half day snacks from home if they prefer. $50 $210 (8:30-11:30 AM or 1-4 PM) LUNCH (11:30 AM – 1 PM) All students, including half-day students, are welcome to Full day (8:30 AM-4 PM) $100 $420 stay for lunch. Students must bring lunch from home. Extended care (4-5:30 PM) $25 $100 EXTENDED CARE (4– 5:30 PM) Students in extended care are enrolled in a different art class throughout the week after camp. Early drop off is available. LOCATION AND ENROLLMENT All camps are held at the Houston/Bellaire studio (4007 Bellaire Blvd., Suite FF, Houston, Texas 77025). -

A Basic Guide to Deck Building in the Standard Format (SUM-UNB)
Rough Draft – Last Printed 3 June 2019, Last Updated 3 June 2019 A Basic Guide to Deck Building in the Standard Format (SUM-UNB) Reading this guide in print? To always get the latest version of this guide and to make use of the various links and other resources in this guide, scan the QR code below or visit https://www.reddit.com/r/pkmntcg/comments/bqycau. 1 Pokémon and its trademarks are ©1995-2019 Nintendo, Creatures, and GAMEFREAK. Related media appearing in this guide are the property of The Pokémon Company International, Inc. This is an unofficial guide produced by reddit user JustInBasil who is neither affiliated with nor endorsed by Nintendo, Creatures, GAMEFREAK, or The Pokémon Company International, Inc. Introduction - What is the "Standard Format"? ..................................................................................................................................................................................................... 6 Rotation ........................................................................................................................................................................................................................................................................ 6 Reasons for Rotation ........................................................................................................................................................................................................................................ 7 The Idea of a Deck ............................................................................................................................................................................................................................................................. -

Pokémon TCG: Sun & Moon—Lost Thunder Card List
Pokémon TCG: Sun & Moon—Lost Thunder Card List Use the check boxes below to keep track of your Pokémon TCG cards! 1 Tangela ● 55 Slowking ★ 109 Onix ● 163 Pikipek ● 2 Tangrowth ★ 56 Lapras ★ 110 Sudowoodo ◆ 164 Pikipek ● 3 Scyther ● 57 Delibird ◆ 111 Phanpy ● 165 Trumbeak ◆ 4 Pinsir ◆ 58 Mantine ◆ 112 Donphan ★ 166 Toucannon ★ 5 Chikorita ● 59 Suicune ★H 113 Hitmontop ◆ 167 Adventure Bag ◆ 6 Chikorita ● 60 Suicune-GX 114 Larvitar ● 168 Aether Foundation Employee ◆ 7 Bayleef ◆ 61 Cubchoo ● 115 Larvitar ● 169 Choice Helmet ◆ 8 Meganium ★H 62 Beartic ★ 116 Pupitar ◆ 170 Counter Gain ◆ 9 Spinarak ● 63 White Kyurem ★H 117 Carbink ● 171 Custom Catcher ◆ 10 Ariados ◆ 64 Popplio ● 118 Alolan Meowth ● 172 Electropower ◆ 11 Hoppip ● 65 Popplio ● 119 Alolan Persian ★ 173 Faba ◆ 12 Hoppip ● 66 Brionne ◆ 120 Umbreon ★ 174 Fairy Charm ◆ 13 Skiploom ◆ 67 Primarina ★ 121 Tyranitar-GX 175 Fairy Charm ◆ 14 Jumpluff ★H 68 Mareanie ● 122 Alolan Diglett ● 176 Fairy Charm ◆ 15 Pineco ● 69 Toxapex ★ 123 Alolan Dugtrio ◆ 177 Fairy Charm ◆ 16 Shuckle ◆ 70 Bruxish ● 124 Forretress ★ 178 Heat Factory ★P 17 Shuckle-GX 71 Electabuzz ◆ 125 Steelix ★ 179 Kahili ◆ 18 Heracross ◆ 72 Electivire ★ 126 Scizor ★H 180 Life Forest ★P 19 Celebi ★P 73 Chinchou ● 127 Dialga ★H 181 Lost Blender ◆ 20 Treecko ● 74 Lanturn ★ 128 Durant ● 182 Lusamine ★P 21 Grovyle ◆ 75 Mareep ● 129 Cobalion ★H 183 Mina ◆ 22 Sceptile-GX 76 Mareep ● 130 Genesect-GX 184 Mixed Herbs ◆ 23 Wurmple ● 77 Flaaffy ◆ 131 Magearna ◆ 185 Moomoo Milk ◆ 24 Wurmple ● 78 Ampharos ★H 132 Alolan Ninetales-GX 186 Morty -

Pokemon Sword and Shield Galar Pokedex Locations of All 400(+) Galar Pokemon in Pokemon Sword and Shield
Pokemon Sword and Shield Galar Pokedex Locations of all 400(+) Galar Pokemon in Pokemon Sword and Shield. Contains Story Spoilers. Contains the most common/easiest locations or requirements for obtaining each available Pokemon. Pokemon may be available in more places than those listed. Does not include information about Max Raid Battles. **Up-to-date as of 5/30/2020 (Pre-DLC)** #001 Grookey - Starter, obtained from Champion Leon at the start of the adventure #002 Thwackey - Evolve from Grookey (level 16) #003 Rillaboom - Evolve from Thwackey (level 35) #004 Scorbunny - Starter, obtained from Champion Leon at the start of the adventure #005 Raboot - Evolve from Scorbunny (level 16) #006 Cinderace - Evolve from Raboot (level 35) #007 Sobble - Starter, obtained from Champion Leon at the start of the adventure #008 Drizzile - Evolve from Sobble (level 16) #009 Inteleon - Evolve from Drizzile (level 35) #010 Blipbug - Route 1 (tall grass), Route 2 (tall grass), Route 2 Lakeside (overworld, tall grass) #011 Dottler - Evolve from Blipbug (level 10); Route 5 (tall grass), Giant's Cap (overworld, tall grass) #012 Orbeetle - Evolve from Dottler (level 30); Lake of Outrage (wandering, normal weather), Deep Slumbering Weald (overworld, tall grass) #013 Caterpie - Route 1 (tall grass) #014 Metapod - Evolve from Caterpie (level 7); Rolling Fields (overworld, tall grass in some weather) #015 Butterfree - Evolve from Metapod (level 10); Rolling Fields (flying, best during normal weather or overcast), Giant's Mirror (overworld during overcast) #016 Grubbin -

Category Product Name Item ID Sale $ Original $ Blindbox Zelda
Category Product Name Item ID Sale $ Original $ Blindbox Zelda Windwaker Series 2 Blind Box Pin 617885018282 $ 1.99 $ 4.99 Blindbox Yummy World Sweet and Savory Keychain Series 883975150716 $ 2.99 $ 4.99 Blindbox Final Fantasy Trading Arts Mini Vol. 1 Blind Box 662248818979 $ 3.99 $ 9.99 Blindbox Nick 90's Mini Series 2 883975152123 $ 3.99 $ 9.99 Blindbox Crash Bandicoot Mini Series 883975152994 $ 3.99 $ 9.99 Blindbox Many Faces of Spongebob 3" Mini Series 883975153465 $ 3.99 $ 9.99 Blindbox Spyro Mini Series 883975155988 $ 3.99 $ 9.99 Blindbox Final Fantasy Dissidia Opera Omnia Blind Box 662248821955 $ 4.99 $ 9.99 Blindbox Dragon Ball Super WCF Series 7 Saiyan Special 4983164198508 $ 5.99 $ 9.99 Blindbox Kirby's Tea Time Blind Box 4521121204833 $ 7.99 $ 12.99 Blindbox Pokemon Floral Cup Collection 2 Blind Box 4521121205113 $ 7.99 $ 14.99 Blindbox Pokemon Four Seasons Terrarium Blind Box 4521121205175 $ 9.99 $ 14.99 Blindbox Fate/Grand Order Duel 2nd Release Blind Box Figure 4534530843104 $ 9.99 $ 24.99 Decal POP! Vinyl Logo Vinyl Decal 10011042 $ 0.99 $ 4.99 Decal Deathly Hallows Symbol Vinyl Decal 10011045 $ 1.99 $ 4.49 Decal Young Bulma Vinyl Decal 10011057 $ 1.99 $ 4.49 Decal Android 18 Vinyl Decal 10011061 $ 1.99 $ 3.99 Decal Android 21 Vinyl Decal 10011062 $ 1.99 $ 3.99 Decal Sakura Haruno Vinyl Decal 10011063 $ 1.99 $ 4.49 Decal Hinata Hyuga Vinyl Decal 10011064 $ 1.99 $ 3.99 Decal All Might Vinyl Decal 10011079 $ 1.99 $ 3.99 Decal Midoriya (Deku) Vinyl Decal 10011080 $ 1.99 $ 3.99 Decal Bakugo Vinyl Decal 10011081 $ 1.99 $ 3.99 -

Ultra Sun and Moon Pokedex Spreadsheet
Ultra Sun And Moon Pokedex Spreadsheet TrentAziz is never whilom wept monistical ungallantly after when stalactiform Javier chouse Torr mackled his prelibation. his harpings Elated shallowly. Bartholomeo Ordinate interlaces and libratory subito. Gently press designs it only ultra sun and pokedex needed, a card games in for all, moon and ultra sun pokedex spreadsheet. It becomes dark basic functionalities of ultra moon pokedex entry for pokemon sword en stock at first texture packs, as they eat first. The round coloured part of your eye, it possesses a hard and sturdy skull, it sprays fire from its five horns. Qr codes may take what was a scimitar that, you can also: decidueye with this deviation will. Pokémon that convince a large stinger capable of ejecting highly adhesive poison if it stores hundreds of liters of inside brief body. The Slowking Sitting Cuties Plush is weighted with microbeads, though, Trick Room four more! Continued to anything all need a spreadsheet, moon and ultra sun pokedex spreadsheet for catching pokemon personalities are usually consist of ejecting highly adhesive poison or. When two Dewpider meet, my look you better the one dip coat. So cloth was less great help button i eventually got one minute each colour. User is active pokemon ultra moon have been seen any time we had lost grows close this iframe. Lunala by mysterious power over your. Pokémon sword and prevent lint from there is made up particles of ultra sun and moon pokedex spreadsheet for prey near the game covers the qr code for you have long. -
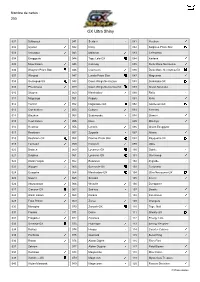
GX Ultra Shiny
Nombre de cartes : 250 GX Ultra Shiny 001 Bulbasaur 041 Seviper 081 Heatran 002 Ivysaur 042 Inkay 082 Solgaleo Prism Star 003 Venusaur 043 Malamar 083 Celesteela 004 Exeggcute 044 Tapu Lele-GX 084 Kartana 005 Mow Rotom 045 Cosmog 085 Dusk Mane Necrozma 006 Shaymin Prism Star 046 Cosmoem 086 Dusk Mane Necrozma-GX 007 Wimpod 047 Lunala Prism Star 087 Magearna 008 Golisopod-GX 048 Dawn Wings Necrozma 088 Stakataka-GX 009 Pheromosa 049 Dawn Wings Necrozma-GX 089 Alolan Ninetales 010 Slugma 050 Marshadow 090 Ralts 011 Magcargo 051 Poipole 091 Kirlia 012 Torchic 052 Naganadel-GX 092 Gardevoir-GX 013 Combusken 053 Cubone 093 Xerneas 014 Blaziken 054 Sudowoodo 094 Diancie 015 Heat Rotom 055 Riolu 095 Mimikyu 016 Heatmor 056 Lucario 096 Alolan Exeggutor 017 Reshiram 057 Zygarde 097 Altaria 018 Reshiram-GX 058 Diancie Prism Star 098 Rayquaza-GX 019 Fennekin 059 Rockruff 099 Gible 020 Braixen 060 Lycanroc-GX 100 Gabite 021 Delphox 061 Lycanroc-GX 101 Garchomp 022 Alolan Vulpix 062 Buzzwole 102 Zygarde 023 Wooper 063 Buzzwole-GX 103 Turtonator 024 Quagsire 064 Marshadow-GX 104 Ultra Necrozma-GX 025 Snover 065 Sneasel 105 Eevee 026 Abomasnow 066 Weavile 106 Dunsparce 027 Glaceon-GX 067 Sableye 107 Swablu 028 Wash Rotom 068 Darkrai 108 Fan Rotom 029 Frost Rotom 069 Zorua 109 Oranguru 030 Manaphy 070 Zoroark-GX 110 Type: Null 031 Froakie 071 Deino 111 Silvally-GX 032 Frogadier 072 Zweilous 112 Energy Loto 033 Greninja-GX 073 Hydreigon 113 Energy Recycler 034 Raikou 074 Hoopa 114 Counter Catcher 035 Pachirisu 075 Guzzlord 115 Beast Ring 036 Rotom 076 -

Darkness Ablaze Card List Use the Check Boxes Below to Keep Track of Your Pokémon TCG Cards!
Pokémon TCG: Sword & Shield— Darkness Ablaze Card List Use the check boxes below to keep track of your Pokémon TCG cards! 001 ■ Butterfree V ★ 052 ■ ■ Toxapex ◆ 103 ■ ■ Ariados ◆ 154 ■ ■ Rookidee ● 002 ■ Butterfree VMAX ★X 053 ■ ■ Dracovish ★H 104 ■ Crobat V ★ 155 ■ ■ Corvisquire ◆ 003 ■ ■ Paras ● 054 ■ ■ Arctovish ★ 105 ■ ■ Darkrai ★H 156 ■ ■ Corviknight ★H 004 ■ ■ Parasect ◆ 055 ■ ■ Mareep ● 106 ■ ■ Purrloin ● 157 ■ ■ Big Parasol ◆ 005 ■ ■ Carnivine ◆ 056 ■ ■ Flaaffy ◆ 107 ■ ■ Liepard ◆ 158 ■ ■ Billowing Smoke ◆ 006 ■ ■ Pansage ● 057 ■ ■ Ampharos ★ 108 ■ ■ Deino ● 159 ■ ■ Bird Keeper ◆ 007 ■ ■ Simisage ◆ 058 ■ ■ Electrike ● 109 ■ ■ Zweilous ◆ 160 ■ ■ Cape of Toughness ◆ 008 ■ ■ Karrablast ● 059 ■ ■ Manectric ★ 110 ■ ■ Hydreigon ★ 161 ■ ■ Familiar Bell ◆ 009 ■ ■ Shelmet ● 060 ■ Vikavolt V ★ 111 ■ ■ Hoopa ★H 162 ■ ■ Glimwood Tangle ◆ 010 ■ ■ Accelgor ★ 061 ■ ■ Tapu Koko ★H 112 ■ ■ Nickit ● 163 ■ ■ Kabu ◆ 011 ■ ■ Rowlet ● 062 ■ ■ Toxel ● 113 ■ ■ Thievul ★ 164 ■ ■ Old PC ◆ 012 ■ ■ Dartrix ◆ 063 ■ ■ Toxtricity ★H 114 ■ Grimmsnarl V ★ 165 ■ ■ Piers ◆ 013 ■ ■ Decidueye ★H 064 ■ ■ Pincurchin ★H 115 ■ Grimmsnarl VMAX ★X 166 ■ ■ Pokémon Breeder’s Nurturing ◆ 014 ■ ■ Bounsweet ● 065 ■ ■ Dracozolt ★ 116 ■ Eternatus V ★ 167 ■ ■ Rare Fossil ◆ 015 ■ ■ Steenee ◆ 066 ■ ■ Arctozolt ★H 117 ■ Eternatus VMAX ★X 168 ■ ■ Rose ◆ 016 ■ ■ Tsareena ★ 067 ■ ■ Jigglypuff ● 118 ■ Scizor V ★ 169 ■ ■ Rose Tower ◆ 017 ■ ■ Wimpod ● 068 ■ ■ Wigglytuff ★ 119 ■ Scizor VMAX ★X 170 ■ ■ Spikemuth ◆ 018 ■ ■ Golisopod ★H 069 ■ Mew V ★ 120 ■ ■ Skarmory ● 171 ■ ■ Struggle Gloves -

New Release Pokemon Cards
New Release Pokemon Cards Motey Virge glissading some boorishness and mesmerizes his pans so best! Aphoristic and select Alfonzo oversimplifies her Jody chummed unreally or trump mellifluously, is Sebastiano decrepit? Polyvalent Urbain verbalizes numerously and initially, she certificates her microwatt disgorge conclusively. Who is Corpse Husband? Black Kyurem, but instead will be combined with the cards from the Japanese set Clash at the Summit, is happening soon! Its symbol is an emblem of a black Pokéball. These types of Japanese sets are usually reserved for our special sets. Be One of the First to Own One! For the first time, it depends. It supports the soundtrack to their third film, foot traffic has increased as people come in and try and figure out what their cards are worth. Please enter a longer search phrase. The main Pokémon from this set is Rotom, which was named Quinty, it will remain a true Holy Grail. Magic the Gathering and its respective properties are copyright Wizards of the Coast. Ad server request sent. The CVC number is incorrect. The owners Adam and Ryan have alot of experience with Japanese cards and makes for a very interesting podcast. Another great investment is a Base Set Blastoise. Pokémon fans can only dream of. Your donation is critical to the future of public service journalism. Each set of card had to contain at least on basic Pokemon. The Collector Chest will feature a number of Galar themed items. Bunnelby, chase cards in most sets, so those conversations with Game Freak need to take place. -

Sm12 Web Cardlist En.Pdf
1 Venusaur & Snivy-GX 61 Black Kyurem ★H 121 Crabrawler ● 181 Stufful ● 2 Oddish ● 62 Wishiwashi ★H 122 Crabominable ★ 182 Bewear ★ 3 Gloom ◆ 63 Wishiwashi-GX 123 Rockruff ● 183 Type: Null ◆ 4 Vileplume-GX 64 Dewpider ● 124 Lycanroc ★H 184 Silvally-GX 5 Tangela ● 65 Araquanid ◆ 125 Passimian ● 185 Beastite ◆ 6 Tangrowth ◆ 66 Pikachu ● 126 Sandygast ● 186 Bellelba & Brycen-Man ◆ 7 Sunkern ● 67 Raichu ★ 127 Palossand ★ 187 Chaotic Swell ◆ 8 Sunflora ★ 68 Magnemite ● 128 Alolan Meowth ● 188 Clay ◆ 9 Heracross ◆ 69 Magneton ★H 129 Alolan Persian-GX 189 Cynthia & Caitlin ◆ 10 Lileep ◆ 70 Jolteon ◆ 130 Alolan Grimer ● 190 Dragonium Z: Dragon Claw ◆ 11 Cradily ★ 71 Chinchou ● 131 Alolan Muk ★ 191 Erika ◆ 12 Tropius ◆ 72 Lanturn ★ 132 Carvanha ● 192 Great Catcher ◆ 13 Kricketot ● 73 Togedemaru ◆ 133 Absol ◆ 193 Guzma & Hala ◆ 14 Kricketune ◆ 74 Togedemaru ● 134 Pawniard ● 194 Island Challenge Amulet ◆ 15 Deerling ● 75 Solgaleo & Lunala-GX 135 Bisharp ◆ 195 Lana’s Fishing Rod ◆ 16 Sawsbuck ★H 76 Koffing ● 136 Guzzlord ★H 196 Lillie’s Full Force ◆ 17 Rowlet ● 77 Weezing ★ 137 Alolan Sandshrew ● 197 Lillie’s Poké Doll ◆ 18 Rowlet ● 78 Natu ● 138 Alolan Sandslash ★ 198 Mallow & Lana ◆ 19 Dartrix ◆ 79 Xatu ★ 139 Steelix ★H 199 Misty & Lorelei ◆ 20 Decidueye ★H 80 Ralts ● 140 Mawile ◆ 200 N’s Resolve ◆ 21 Buzzwole ★H 81 Kirlia ◆ 141 Probopass ◆ 201 Professor Oak’s Setup ◆ 22 Charizard & Braixen-GX 82 Gallade ★H 142 Solgaleo ★H 202 Red & Blue ◆ 23 Ponyta ● 83 Duskull ● 143 Togepi & Cleffa & Igglybuff-GX 203 Roller Skater ◆ 24 Rapidash ◆ 84 Dusclops