Market and Technology Watch Report Year1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Operational Perspective on a Hybrid and Heterogeneous Cray XC50 System
An Operational Perspective on a Hybrid and Heterogeneous Cray XC50 System Sadaf Alam, Nicola Bianchi, Nicholas Cardo, Matteo Chesi, Miguel Gila, Stefano Gorini, Mark Klein, Colin McMurtrie, Marco Passerini, Carmelo Ponti, Fabio Verzelloni CSCS – Swiss National Supercomputing Centre Lugano, Switzerland Email: {sadaf.alam, nicola.bianchi, nicholas.cardo, matteo.chesi, miguel.gila, stefano.gorini, mark.klein, colin.mcmurtrie, marco.passerini, carmelo.ponti, fabio.verzelloni}@cscs.ch Abstract—The Swiss National Supercomputing Centre added depth provides the necessary space for full-sized PCI- (CSCS) upgraded its flagship system called Piz Daint in Q4 e daughter cards to be used in the compute nodes. The use 2016 in order to support a wider range of services. The of a standard PCI-e interface was done to provide additional upgraded system is a heterogeneous Cray XC50 and XC40 system with Nvidia GPU accelerated (Pascal) devices as well as choice and allow the systems to evolve over time[1]. multi-core nodes with diverse memory configurations. Despite Figure 1 clearly shows the visible increase in length of the state-of-the-art hardware and the design complexity, the 37cm between an XC40 compute module (front) and an system was built in a matter of weeks and was returned to XC50 compute module (rear). fully operational service for CSCS user communities in less than two months, while at the same time providing significant improvements in energy efficiency. This paper focuses on the innovative features of the Piz Daint system that not only resulted in an adaptive, scalable and stable platform but also offers a very high level of operational robustness for a complex ecosystem. -

Interconnect Your Future Enabling the Best Datacenter Return on Investment
Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2016 Mellanox Accelerates The World’s Fastest Supercomputers . Accelerates the #1 Supercomputer . 39% of Overall TOP500 Systems (194 Systems) . InfiniBand Connects 65% of the TOP500 HPC Platforms . InfiniBand Connects 46% of the Total Petascale Systems . Connects All of 40G Ethernet Systems . Connects The First 100G Ethernet System on The List (Mellanox End-to-End) . Chosen for 65 End-User TOP500 HPC Projects in 2016, 3.6X Higher versus Omni-Path, 5X Higher versus Cray Aries InfiniBand is the Interconnect of Choice for HPC Infrastructures Enabling Machine Learning, High-Performance, Web 2.0, Cloud, Storage, Big Data Applications © 2016 Mellanox Technologies 2 Mellanox Connects the World’s Fastest Supercomputer National Supercomputing Center in Wuxi, China #1 on the TOP500 List . 93 Petaflop performance, 3X higher versus #2 on the TOP500 . 41K nodes, 10 million cores, 256 cores per CPU . Mellanox adapter and switch solutions * Source: “Report on the Sunway TaihuLight System”, Jack Dongarra (University of Tennessee) , June 20, 2016 (Tech Report UT-EECS-16-742) © 2016 Mellanox Technologies 3 Mellanox In the TOP500 . Connects the world fastest supercomputer, 93 Petaflops, 41 thousand nodes, and more than 10 million CPU cores . Fastest interconnect solution, 100Gb/s throughput, 200 million messages per second, 0.6usec end-to-end latency . Broadest adoption in HPC platforms , connects 65% of the HPC platforms, and 39% of the overall TOP500 systems . Preferred solution for Petascale systems, Connects 46% of the Petascale systems on the TOP500 list . Connects all the 40G Ethernet systems and the first 100G Ethernet system on the list (Mellanox end-to-end) . -

インテル® Parallel Studio XE 2020 リリースノート
インテル® Parallel Studio XE 2020 2019 年 12 月 5 日 内容 1 概要 ..................................................................................................................................................... 2 2 製品の内容 ........................................................................................................................................ 3 2.1 インテルが提供するデバッグ・ソリューションの追加情報 ..................................................... 5 2.2 Microsoft* Visual Studio* Shell の提供終了 ........................................................................ 5 2.3 インテル® Software Manager .................................................................................................... 5 2.4 サポートするバージョンとサポートしないバージョン ............................................................ 5 3 新機能 ................................................................................................................................................ 6 3.1 インテル® Xeon Phi™ 製品ファミリーのアップデート ......................................................... 12 4 動作環境 .......................................................................................................................................... 13 4.1 プロセッサーの要件 ...................................................................................................................... 13 4.2 ディスク空き容量の要件 .............................................................................................................. 13 4.3 オペレーティング・システムの要件 ............................................................................................. 13 -

Nvidia Tesla P40 Gpu Accelerator
NVIDIA TESLA P40 GPU ACCELERATOR HIGH-PERFORMANCE VIRTUAL GRAPHICS AND COMPUTE NVIDIA redefined visual computing by giving designers, engineers, scientists, and graphic artists the power to take on the biggest visualization challenges with immersive, interactive, photorealistic environments. NVIDIA® Quadro® Virtual Data GPU 1 NVIDIA Pascal GPU Center Workstation (Quadro vDWS) takes advantage of NVIDIA® CUDA Cores 3,840 Tesla® GPUs to deliver virtual workstations from the data center. Memory Size 24 GB GDDR5 H.264 1080p30 streams 24 Architects, engineers, and designers are now liberated from Max vGPU instances 24 (1 GB Profile) their desks and can access applications and data anywhere. vGPU Profiles 1 GB, 2 GB, 3 GB, 4 GB, 6 GB, 8 GB, 12 GB, 24 GB ® ® The NVIDIA Tesla P40 GPU accelerator works with NVIDIA Form Factor PCIe 3.0 Dual Slot Quadro vDWS software and is the first system to combine an (rack servers) Power 250 W enterprise-grade visual computing platform for simulation, Thermal Passive HPC rendering, and design with virtual applications, desktops, and workstations. This gives organizations the freedom to virtualize both complex visualization and compute (CUDA and OpenCL) workloads. The NVIDIA® Tesla® P40 taps into the industry-leading NVIDIA Pascal™ architecture to deliver up to twice the professional graphics performance of the NVIDIA® Tesla® M60 (Refer to Performance Graph). With 24 GB of framebuffer and 24 NVENC encoder sessions, it supports 24 virtual desktops (1 GB profile) or 12 virtual workstations (2 GB profile), providing the best end-user scalability per GPU. This powerful GPU also supports eight different user profiles, so virtual GPU resources can be efficiently provisioned to meet the needs of the user. -

Introduction to High Performance Computing
Introduction to High Performance Computing Shaohao Chen Research Computing Services (RCS) Boston University Outline • What is HPC? Why computer cluster? • Basic structure of a computer cluster • Computer performance and the top 500 list • HPC for scientific research and parallel computing • National-wide HPC resources: XSEDE • BU SCC and RCS tutorials What is HPC? • High Performance Computing (HPC) refers to the practice of aggregating computing power in order to solve large problems in science, engineering, or business. • Purpose of HPC: accelerates computer programs, and thus accelerates work process. • Computer cluster: A set of connected computers that work together. They can be viewed as a single system. • Similar terminologies: supercomputing, parallel computing. • Parallel computing: many computations are carried out simultaneously, typically computed on a computer cluster. • Related terminologies: grid computing, cloud computing. Computing power of a single CPU chip • Moore‘s law is the observation that the computing power of CPU doubles approximately every two years. • Nowadays the multi-core technique is the key to keep up with Moore's law. Why computer cluster? • Drawbacks of increasing CPU clock frequency: --- Electric power consumption is proportional to the cubic of CPU clock frequency (ν3). --- Generates more heat. • A drawback of increasing the number of cores within one CPU chip: --- Difficult for heat dissipation. • Computer cluster: connect many computers with high- speed networks. • Currently computer cluster is the best solution to scale up computer power. • Consequently software/programs need to be designed in the manner of parallel computing. Basic structure of a computer cluster • Cluster – a collection of many computers/nodes. • Rack – a closet to hold a bunch of nodes. -

Applying the Roofline Performance Model to the Intel Xeon Phi Knights Landing Processor
Applying the Roofline Performance Model to the Intel Xeon Phi Knights Landing Processor Douglas Doerfler, Jack Deslippe, Samuel Williams, Leonid Oliker, Brandon Cook, Thorsten Kurth, Mathieu Lobet, Tareq Malas, Jean-Luc Vay, and Henri Vincenti Lawrence Berkeley National Laboratory {dwdoerf, jrdeslippe, swwilliams, loliker, bgcook, tkurth, mlobet, tmalas, jlvay, hvincenti}@lbl.gov Abstract The Roofline Performance Model is a visually intuitive method used to bound the sustained peak floating-point performance of any given arithmetic kernel on any given processor architecture. In the Roofline, performance is nominally measured in floating-point operations per second as a function of arithmetic intensity (operations per byte of data). In this study we determine the Roofline for the Intel Knights Landing (KNL) processor, determining the sustained peak memory bandwidth and floating-point performance for all levels of the memory hierarchy, in all the different KNL cluster modes. We then determine arithmetic intensity and performance for a suite of application kernels being targeted for the KNL based supercomputer Cori, and make comparisons to current Intel Xeon processors. Cori is the National Energy Research Scientific Computing Center’s (NERSC) next generation supercomputer. Scheduled for deployment mid-2016, it will be one of the earliest and largest KNL deployments in the world. 1 Introduction Moving an application to a new architecture is a challenge, not only in porting of the code, but in tuning and extracting maximum performance. This is especially true with the introduction of the latest manycore and GPU-accelerated architec- tures, as they expose much finer levels of parallelism that can be a challenge for applications to exploit in their current form. -

This Is Your Presentation Title
Introduction to GPU/Parallel Computing Ioannis E. Venetis University of Patras 1 Introduction to GPU/Parallel Computing www.prace-ri.eu Introduction to High Performance Systems 2 Introduction to GPU/Parallel Computing www.prace-ri.eu Wait, what? Aren’t we here to talk about GPUs? And how to program them with CUDA? Yes, but we need to understand their place and their purpose in modern High Performance Systems This will make it clear when it is beneficial to use them 3 Introduction to GPU/Parallel Computing www.prace-ri.eu Top 500 (June 2017) CPU Accel. Rmax Rpeak Power Rank Site System Cores Cores (TFlop/s) (TFlop/s) (kW) National Sunway TaihuLight - Sunway MPP, Supercomputing Center Sunway SW26010 260C 1.45GHz, 1 10.649.600 - 93.014,6 125.435,9 15.371 in Wuxi Sunway China NRCPC National Super Tianhe-2 (MilkyWay-2) - TH-IVB-FEP Computer Center in Cluster, Intel Xeon E5-2692 12C 2 Guangzhou 2.200GHz, TH Express-2, Intel Xeon 3.120.000 2.736.000 33.862,7 54.902,4 17.808 China Phi 31S1P NUDT Swiss National Piz Daint - Cray XC50, Xeon E5- Supercomputing Centre 2690v3 12C 2.6GHz, Aries interconnect 3 361.760 297.920 19.590,0 25.326,3 2.272 (CSCS) , NVIDIA Tesla P100 Cray Inc. DOE/SC/Oak Ridge Titan - Cray XK7 , Opteron 6274 16C National Laboratory 2.200GHz, Cray Gemini interconnect, 4 560.640 261.632 17.590,0 27.112,5 8.209 United States NVIDIA K20x Cray Inc. DOE/NNSA/LLNL Sequoia - BlueGene/Q, Power BQC 5 United States 16C 1.60 GHz, Custom 1.572.864 - 17.173,2 20.132,7 7.890 4 Introduction to GPU/ParallelIBM Computing www.prace-ri.eu How do -

NVIDIA Ampere GA102 GPU Architecture Whitepaper
NVIDIA AMPERE GA102 GPU ARCHITECTURE Second-Generation RTX Updated with NVIDIA RTX A6000 and NVIDIA A40 Information V2.0 Table of Contents Introduction 5 GA102 Key Features 7 2x FP32 Processing 7 Second-Generation RT Core 7 Third-Generation Tensor Cores 8 GDDR6X and GDDR6 Memory 8 Third-Generation NVLink® 8 PCIe Gen 4 9 Ampere GPU Architecture In-Depth 10 GPC, TPC, and SM High-Level Architecture 10 ROP Optimizations 11 GA10x SM Architecture 11 2x FP32 Throughput 12 Larger and Faster Unified Shared Memory and L1 Data Cache 13 Performance Per Watt 16 Second-Generation Ray Tracing Engine in GA10x GPUs 17 Ampere Architecture RTX Processors in Action 19 GA10x GPU Hardware Acceleration for Ray-Traced Motion Blur 20 Third-Generation Tensor Cores in GA10x GPUs 24 Comparison of Turing vs GA10x GPU Tensor Cores 24 NVIDIA Ampere Architecture Tensor Cores Support New DL Data Types 26 Fine-Grained Structured Sparsity 26 NVIDIA DLSS 8K 28 GDDR6X Memory 30 RTX IO 32 Introducing NVIDIA RTX IO 33 How NVIDIA RTX IO Works 34 Display and Video Engine 38 DisplayPort 1.4a with DSC 1.2a 38 HDMI 2.1 with DSC 1.2a 38 Fifth Generation NVDEC - Hardware-Accelerated Video Decoding 39 AV1 Hardware Decode 40 Seventh Generation NVENC - Hardware-Accelerated Video Encoding 40 NVIDIA Ampere GA102 GPU Architecture ii Conclusion 42 Appendix A - Additional GeForce GA10x GPU Specifications 44 GeForce RTX 3090 44 GeForce RTX 3070 46 Appendix B - New Memory Error Detection and Replay (EDR) Technology 49 Appendix C - RTX A6000 GPU Perf ormance 50 List of Figures Figure 1. -

The Sunway Taihulight Supercomputer: System and Applications
SCIENCE CHINA Information Sciences . RESEARCH PAPER . July 2016, Vol. 59 072001:1–072001:16 doi: 10.1007/s11432-016-5588-7 The Sunway TaihuLight supercomputer: system and applications Haohuan FU1,3 , Junfeng LIAO1,2,3 , Jinzhe YANG2, Lanning WANG4 , Zhenya SONG6 , Xiaomeng HUANG1,3 , Chao YANG5, Wei XUE1,2,3 , Fangfang LIU5 , Fangli QIAO6 , Wei ZHAO6 , Xunqiang YIN6 , Chaofeng HOU7 , Chenglong ZHANG7, Wei GE7 , Jian ZHANG8, Yangang WANG8, Chunbo ZHOU8 & Guangwen YANG1,2,3* 1Ministry of Education Key Laboratory for Earth System Modeling, and Center for Earth System Science, Tsinghua University, Beijing 100084, China; 2Department of Computer Science and Technology, Tsinghua University, Beijing 100084, China; 3National Supercomputing Center in Wuxi, Wuxi 214072, China; 4College of Global Change and Earth System Science, Beijing Normal University, Beijing 100875, China; 5Institute of Software, Chinese Academy of Sciences, Beijing 100190, China; 6First Institute of Oceanography, State Oceanic Administration, Qingdao 266061, China; 7Institute of Process Engineering, Chinese Academy of Sciences, Beijing 100190, China; 8Computer Network Information Center, Chinese Academy of Sciences, Beijing 100190, China Received May 27, 2016; accepted June 11, 2016; published online June 21, 2016 Abstract The Sunway TaihuLight supercomputer is the world’s first system with a peak performance greater than 100 PFlops. In this paper, we provide a detailed introduction to the TaihuLight system. In contrast with other existing heterogeneous supercomputers, which include both CPU processors and PCIe-connected many-core accelerators (NVIDIA GPU or Intel Xeon Phi), the computing power of TaihuLight is provided by a homegrown many-core SW26010 CPU that includes both the management processing elements (MPEs) and computing processing elements (CPEs) in one chip. -
TECHNICAL GUIDELINES for APPLICANTS to PRACE 17Th CALL
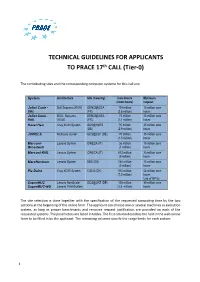
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 17th CALL (T ier-0) The contributing sites and the corresponding computer systems for this call are: System Architecture Site (Country) Core Hours Minimum (node hours) request Joliot Curie - Bull Sequana X1000 GENCI@CEA 134 million 15 million core SKL (FR) (2.8 million) hours Joliot Curie - BULL Sequana GENCI@CEA 72 million 15 million core KNL X1000 (FR) (1,1 million) hours Hazel Hen Cray XC40 System GCS@HLRS 70 million 35 million core (DE) (2.9 million) hours JUWELS Multicore cluster GCS@JSC (DE) 70 million 35 million core (1.5 million) hours Marconi- Lenovo System CINECA (IT) 36 million 15 million core Broadwell (1 million) hours Marconi-KNL Lenovo System CINECA (IT) 612 million 30 million core (9 million) hours MareNostrum Lenovo System BSC (ES) 240 million 15 million core (5 million) hours Piz Daint Cray XC50 System CSCS (CH) 510 million 68 million core (7.5 million) hours Use of GPUs SuperMUC Lenovo NextScale/ GCS@LRZ (DE) 105 million 35 million core SuperMUC-NG Lenovo ThinkSystem (3.8 million) hours The site selection is done together with the specification of the requested computing time by the two sections at the beginning of the online form. The applicant can choose one or several machines as execution system, as long as proper benchmarks and resource request justification are provided on each of the requested systems. The parameters are listed in tables. The first column describes the field in the web online form to be filled in by the applicant. The remaining columns specify the range limits for each system. -

It's a Multi-Core World
It’s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group Moore’s Law is not to blame. Intel process technology capabilities High Volume Manufacturing 2004 2006 2008 2010 2012 2014 2016 2018 Feature Size 90nm 65nm 45nm 32nm 22nm 16nm 11nm 8nm Integration Capacity (Billions of 2 4 8 16 32 64 128 256 Transistors) Transistor for Influenza Virus 90nm Process Source: CDC 50nm Source: Intel At end of day, we keep using all those new transistors. That Power and Clock Inflection Point in 2004… didn’t get better. Fun fact: At 100+ Watts and <1V, currents are beginning to exceed 100A at the point of load! Source: Kogge and Shalf, IEEE CISE Courtesy Horst Simon, LBNL Not a new problem, just a new scale… CPU Power W) Cray-2 with cooling tower in foreground, circa 1985 And how to get more performance from more transistors with the same power. RULE OF THUMB A 15% Frequency Power Performance Reduction Reduction Reduction Reduction In Voltage 15% 45% 10% Yields SINGLE CORE DUAL CORE Area = 1 Area = 2 Voltage = 1 Voltage = 0.85 Freq = 1 Freq = 0.85 Power = 1 Power = 1 Perf = 1 Perf = ~1.8 Single Socket Parallelism Processor Year Vector Bits SP FLOPs / core / Cores FLOPs/cycle cycle Pentium III 1999 SSE 128 3 1 3 Pentium IV 2001 SSE2 128 4 1 4 Core 2006 SSE3 128 8 2 16 Nehalem 2008 SSE4 128 8 10 80 Sandybridge 2011 AVX 256 16 12 192 Haswell 2013 AVX2 256 32 18 576 KNC 2012 AVX512 512 32 64 2048 KNL 2016 AVX512 512 64 72 4608 Skylake 2017 AVX512 512 96 28 2688 Putting It All Together Prototypical Application: Serial Weather Model CPU MEMORY First Parallel Weather Modeling Algorithm: Richardson in 1917 Courtesy John Burkhardt, Virginia Tech Weather Model: Shared Memory (OpenMP) Core Fortran: !$omp parallel do Core do i = 1, n Core a(i) = b(i) + c(i) enddoCore C/C++: MEMORY #pragma omp parallel for Four meteorologists in the samefor(i=1; room sharingi<=n; i++) the map. -

PACKET 22 BOOKSTORE, TEXTBOOK CHAPTER Reading Graphics
A.11 GRAPHICS CARDS, Historical Perspective (edited by J Wunderlich PhD in 2020) Graphics Pipeline Evolution 3D graphics pipeline hardware evolved from the large expensive systems of the early 1980s to small workstations and then to PC accelerators in the 1990s, to $X,000 graphics cards of the 2020’s During this period, three major transitions occurred: 1. Performance-leading graphics subsystems PRICE changed from $50,000 in 1980’s down to $200 in 1990’s, then up to $X,0000 in 2020’s. 2. PERFORMANCE increased from 50 million PIXELS PER SECOND in 1980’s to 1 billion pixels per second in 1990’’s and from 100,000 VERTICES PER SECOND to 10 million vertices per second in the 1990’s. In the 2020’s performance is measured more in FRAMES PER SECOND (FPS) 3. Hardware RENDERING evolved from WIREFRAME to FILLED POLYGONS, to FULL- SCENE TEXTURE MAPPING Fixed-Function Graphics Pipelines Throughout the early evolution, graphics hardware was configurable, but not programmable by the application developer. With each generation, incremental improvements were offered. But developers were growing more sophisticated and asking for more new features than could be reasonably offered as built-in fixed functions. The NVIDIA GeForce 3, described by Lindholm, et al. [2001], took the first step toward true general shader programmability. It exposed to the application developer what had been the private internal instruction set of the floating-point vertex engine. This coincided with the release of Microsoft’s DirectX 8 and OpenGL’s vertex shader extensions. Later GPUs, at the time of DirectX 9, extended general programmability and floating point capability to the pixel fragment stage, and made texture available at the vertex stage.