41St Research Students' Conference in Probability and Statistics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Westbournian Yearbook
The Westbournian Yearbook 2015–2016 Staff List Westbourne School 2015/16 Educating girls and boys for life GOVERNORS SENIOR SCHOOL Mr S Hinchliffe Chairman and local resident Art & Design Mr M Farn BA (Hons) PGCE Mr A Eaton Current parent and former pupil CDT Mr C Bell BA (Hons) PGCE Mr J Kenworthy Parent of current pupils Drama/Religion Mrs N Rigby BA (Hons) PGCE Mrs G Radley Parent of current pupils English Mrs L Wells BA (Hons) PGCE Mr T Strike Parent of current pupil English Miss C Smith BA (Hons) PGCE Mr I Wileman Former head teacher English/Media Mrs D Loane BA (Hons) PGCE Mr D Merifield Parent of current pupil Food Technology Mrs D Loasby BA (Hons) PGCE Ms C Lawton Partner at Jolliffe Cork French Mme V Hinchliffe Maîtrise (Rennes) Mrs S Kay Former parent French Mrs A Palmer BA (Hons) PGCE Mr S Goodhart Former head teacher Geography Mr I Davey BA (Hons) PGCE Geography/Games/ HEADMASTER Mr S Glover BSc (Hons) History Mr J B Hicks BEd (Hons) MEd History Mrs J Briddock BA (Hons) PGCE SENIOR MANAGEMENT TEAM ICT Mr P T Hinchliffe Learning Support Mrs N Day BA (Hons) PGCE, CPT3A, BPS Deputy Head of Senior School Mr P Birbeck MA (Cantab) PGCE Mr B Adebola BSc (Hons) PGCE Mrs L Cannell BA in Primary Education, Mathematics Mr P Birbeck MA (Cantab) PGCE Head of Junior School NPQH Mathematics Mr G Beckett Cert Ed Exams Officer/Staff Training Mrs J Briddock BA (Hons) PGCE Mathematics Mr P Bunton BA (Hons) PGCE Bursar/Registrar Mr C A Heald BA (Hons) Mathematics Mr C Allison MA BA Marketing Manager Mrs A Bywater PGCE Music Mrs M Pritchett BA -

The Elusive Glassblower Politics of the Lecture Theatre Behind the Scenes Insights the Chemistry of Brewing
The University of Sheffield’s Chemistry News Team Issue 2 : October 2014 THE ELUSIVE GLASSBLOWER POLITICS OF THE LECTURE THEATRE BEHIND THE SCENES INSIGHTS THE CHEMISTRY OF BREWING Resonance, October 2014 1 October 2014 Resonance is a biannual newsletter produced by chemistry students at the University NEWS FEATURES of Sheffield. It aims to provide insights into unheard stories from the Department and University, and to engage you with issues in the wider scientific world. LOCAL FOCUS INSIGHT Team members and contributing authors: Heather Carson, Michaela Fitzpatrick-Milton, Maya Singer Hobbs, Cate O’Brien, Friederike Dannheim, Gobika Chandrakumar Environmental success for The Department’s elusive chemistry technicians glassblower brought into Design: Editor-in-Cheif: Secretary: Kieran Chadwick Alex Stockham Jenna Spencer-Briggs light A graduate’s success in the Copy edited and reviewed by: House of Commons Cate, Jenna, Rike, Michaela, Dr Simon Jones & Prof. Mike Ward ACCOUNT Prof. Armes flying high A take on the undertones of Department bestowed with lecture theatre politics Athena SWAN Bronze A Note From the Editor INSIGHT Sterotype-challenging elcome, one and all, to this second issue of Resonance. Hello also video production by Dr Grant Hill reveals the Wto the Department’s newcomers; students from around the world, academics, support staff, and especially the first students from Nanjing. SciCommSoc chemical complexities The year is 2014, the location is Sheffield. What a beautiful place to be. behind our favourite tipple This edition is fresh off the press, bigger and bolder than before. In it we present news from far and near, and stories from within the Department. -

University Campus
0–9 F O 301: Student Skills and Development Centre E4 149 Faculty Offices Occupational Health Unit (HR) E2 104 > Arts and Humanities F3 195 Octagon Centre D4 118 > Engineering H3 170 ENGLISH LANGUAGE A Ophthalmology and Orthoptics C5 88 > Medicine, Dentistry and Health C5 92 University TEACHING CENTRE Academic Unit of Clinical Oncology B4 41 > Science E3 113 (see Central Sheffield Academic Unit of Medical Education C5 88 P map overleaf) > Social Sciences G3 197 Campus Accommodation and Commercial Services Finance Department E2 104 Pam Liversidge Building H2 174 (see Central Sheffield map) 10 Firth Court D3 105 Parking Services H2 190 Addison Building D3 113 Firth Hall D3 105 Perak Laboratories E3 110 Adult Dental Care C4 47 Florey Building D3 114 Philippa Cottam Communication Clinic C3 37 Aerospace Engineering H2 190 French F3 184 Philosophy G4 161 Alfred Denny Building E3 111 Physics and Astronomy E3 121 Allen Court F2 198 G Planning and Governance Services F4 156 Amy Johnson Building H3 173, 176 Gatehouse H2 201 Politics B3 31 Animal and Plant Sciences E3 111 Genomic Medicine C4 87 Polymer Centre E3 117 Antibody Resource Centre D3 108 Geography and Urban Planning D2 102 Portobello Centre H3 177 Archaeology until Summer 2017 H3 180 George Porter Building H2 190 Print and Design Solutions E3 151 Germanic Studies 184 Archaeology from Summer 2017 G4 163 F3 PropertywithUS E4 120 Glossop Road Student Accommodation D5 200 Architecture E2 104 Psychology (see Central Sheffield map) 205 Arthur Willis Environment Centre A3 28 Goodwin Sports Centre -

Sheffield City Council Sheffield Development Framework Proposals
n 8 q ALK Post Works n Adult Training n Garage qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqHall 12 8 26 37 39 8 212 2 1 92 Centre 282 q 168 El Sub Sta PH12 3 Tennis Court 408 BM 57.10m 21 q 45 PICKERING RD Works VALE ROAD 6 Tanks BM 72.69m WOOD FOLD 38 122 35 Car Park Gas Holder 2 n 295 n 33 1 Atlas Works n PARKWOOD ROAD Sheffield City Council DSIDE LANE Works 4 ALLIANCE STREET 9 162 POLKA 1a 219 Works WOO 184 to 170 10 SMERE W CARWOOD ROAD 68.6m SE q Tank COURT 86.3m FB PETRE STREET Works 9 1 30 q Playing Field n 31 Playground Works 1b Wentworth Lead Works n 18 LLE E n PENISTONE ROAD Garage 230 37 98 91.1m 71.0m q 200 Sheffield Development Framework TCB 2 EARLDOM ROAD FAIRFIELD ROAD 7 241 7 q Surgery 7 77.1m WB n LB n 2 55.5m 2 ELLAND CLO Works 120a Playing Field n 410 HOYLAND ROAD q 23 283 8 W RISING STREET 33 35 to 1 1 179 n q 145 23 Proposals Map 5 Playing Field Parkwood Chy 109 n M STREET 2 120 FB EARLDO ATLAS STREET 103 8 7 Industrial10 q FB HARLESTON STREET CLUB MILL ROAD 1 n 130 to 142 12 6 El Sub Sta 43.3m Gas Holder to 22 Estate Saxon Works NOTTINGHAM CLIFF BM Works 24 Playing Field 66.4m n q 28 3 Parkwood 209 n 8 25 74.7m 55.2m 40 March 2007 272 168 72.2m Industrial q 265 107 5.59m COUPE ROAD Shelter 8 227 107.3m E 228 83.8m 18 n 130a WALLACE ROAD Estate 174 Burngreave Garage Sheltern q n 50 Day Nursery 29 139 DOUGLAS ROAD 1 q WOODSIDE 4 EARLDOM DRIVE 101 Works 1 15 110 13 54.3m 144 Sheet 8 16 226 6 El 0 8 n Scrap n 17 Sub Sta 1 q 18 WB Yard 12 n 35 26 BM 43.65m PC 132 q 105 14 4 217 10 44 Works 13 8 CR 7 HILLFOOT ROAD WELLAND CLOSE 9 Posts -

Sport & Physical Activity for Disabled People in Sheffield
Sport & Physical Activity for Disabled People in Sheffield www.withinreach.org.uk Sport & Physical Activity for Disabled People in Sheffield Contents Welcome 4 Activity Timetable 6 - 12 A-Z Clubs and Activities 13 - 80 A-Z Sports Facilities 81 - 96 Useful Contacts 97 - 103 Whilst every care has been taken to ensure that the information contained in this directory is accurate, WITHIN REACH and Sheffield City Council do not accept any responsibility for any error or omission that has occurred ACKNOWLEDGEMENTS: These photos were carried out by; Deborah Stone Photography, UK Coaching and Will Roberts, Vox Multimedia 2 3 Welcome Activity Timetable Welcome to the WITHIN REACH Sports Directory This directory aims to provide you with information on local sports clubs and leisure facilities that are available for disabled people in and around Sheffield. For example, you can find all club details, session times and dates, costs as well as affiliation details. The directory also provides information on sport and leisure facilities as well as useful contacts that can offer you help, assistance or advice. How to use the Directory This sports directory has been designed to be a useful and up to date guide of all the sports clubs, activities and facilities throughout Sheffield. It has been divided alphabetically by club or activity name to help you to find the activity for you. 4 5 Activity Timetable Activity Timetable Monday Sheffield City Boxing Club Leisure Swimming Sheffield Wheelchair Tennis 4.45 pm-6.00 pm 11-16yrs & 6.00 Various times Club D.A.W.S. -

Directory of Teaching Spaces
February Directory of Teaching 2020 Spaces If you need assistance with information regarding rooms and the equipment within them, you can use this document. NOTE; This document has links embedded within it. Wireless connectivity is available across campus. For information please visit: Click here to open a campus map. http://www.shef.ac.uk/it-services/wireless Click on a room code to open a user guide. Click on ‘INTERACTIVE DISPLAY MONITOR’ or IDB to open a user guide. To book a room visit: http://www.shef.ac.uk/it-services/roombookings Contents LOCATION: 9MS; 9 MAPPIN STREET .............................................................................................................................................................................................................. 3 LOCATION: 38MS; 38 MAPPIN STREET .......................................................................................................................................................................................................... 4 LOCATION: GR301; 301 GLOSSOP ROAD ........................................................................................................................................................................................................ 5 LOCATION: ADB; AFRED DENNY BUILDING ................................................................................................................................................................................................... 6 LOCATION: AT; ARTS TOWER ....................................................................................................................................................................................................................... -
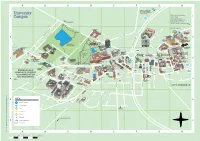
Download Our Campus Map with A-Z Index
0–9 F O 301: Student Skills and Development Centre E4 149 Faculty Offices Octagon Centre D4 118 > Arts and Humanities F3 195 Ophthalmology and Orthoptics C5 88 A > Engineering H3 210 ENGLISH LANGUAGE > Medicine, Dentistry and Health C5 92 TEACHING CENTRE P Academic Unit of Clinical Oncology B4 41 > Science E3 113 (see Central Sheffield Academic Unit of Medical Education C5 88 Pam Liversidge Building H2 174 map overleaf) > Social Sciences G3 197 University Accommodation and Commercial Services Perak Laboratories E3 110 St Vincent’s Accommodation Finance Department E2 104 (see Central Sheffield map) 10 Firth Court D3 105 Philippa Cottam Communication Clinic C3 37 3 Solly Street Addison Building D3 113 Firth Hall D3 105 Philosophy G4 161 Campus Adult Dental Care C4 47 University of Sheffield Florey Building D3 114 Physics and Astronomy E3 121 International College (USIC) Aerospace Engineering H3 170 French F3 184 Planning and Governance Services F4 156 Alfred Denny Building E3 111 Politics B3 31 NCP Solly Street car park Allen Court F2 198 (see City Centre map overleaf) G Polymer Centre E3 117 Amy Johnson Building H3 173 Gatehouse H2 201 Portobello Centre H3 177 Animal and Plant Sciences E3 111 Genomic Medicine C4 87 Print and Design Solutions E3 151 Antibody Resource Centre D3 108 Geography and Urban Planning D2 102 Psychology (see Central Sheffield map) 205 Archaeology G4 163 George Porter Building H2 190 Architecture E2 104 Germanic Studies F3 184 R Arthur Willis Environment Centre A3 28 Glossop Road Student Accommodation D5 200 Ranmoor Student -

Football SPORTS PARK DAY ICE HOCKEY FINAL
Sheffield Varsity merchandise is available in the Students’ Union Official University of or online from sheffieldstore.com TWO UNIVERSITIES, ONE CITY Official Varsity and Team Hallam merchandise is available from your Students’ Union, The HUBS or, you can buy online hallamstudentsunion.org/varsity at Team Uni of Team Uni of Team Uni of Points Points Points Hallam Sheffield Hallam Sheffield Hallam Sheffield Event Venue Date Time Available Event Venue Date Time Available Event Venue Date Time Available Points Points Points Points Points Points Snow sports varsity Val Thorens 18 Dec – 4 1 3 Rugby Union Men’s 1 SHU Sports Park 20 Mar 18:00 1 Table Tennis Men’s 1 EIS Sheffield 25 Mar 18:30 1 Cycling – Dual Slalom Park Wood Springs 13 Mar 14:00 * Rugby Union Women’s 1 SHU Sports Park 20 Mar 13:00 1 Hockey Women’s 2 Abbeydale Sports Club 26 Mar 12:00 1 Equestrian Parklands Equestrian Centre 15 Mar 10:00 1 Rugby Union Men’s 2 SHU Sports Park 20 Mar 16:00 1 Hockey Men’s 2 Abbeydale Sports Club 26 Mar 14:00 1 Sailing Winscar Reservoir 16 Mar 12:00 1 Rugby Union Men’s 3 SHU Sports Park 20 Mar 13:00 0 Hockey Women’s 1 Abbeydale Sports Club 26 Mar 16:00 1 Cycling – Cross Country Lady Cannings 17 Mar 11:00 * Hockey Men’s 1 Abbeydale Sports Club 26 Mar 18:00 1 Trampolining Goodwin Sports Centre 17 Mar 16:00 1 21st March 21st March 10:00- Tennis Men’s 1 Hallamshire Tennis & Squash Club 26 Mar 1 BOXING ICE HOCKEY 2’S 16:00 19th March 10:00- @ Octagon Centre @ iceSheffield Tennis Men’s 2 Hallamshire Tennis & Squash Club 26 Mar 1 Football Tickets £6 from -

The University of Sheffield Index
Index The University of Sheffield Map Number Grid Reference Faculty offices Parking Services G1 190 > Arts and Humanities F3 184 Perak Laboratories D2 110 > Engineering H2 170 Philippa Cottam Communication Clinic B4 51 > Medicine, Dentistry and Health B5 88 Philosophy F3 161 > Science E2 117 Physics and Astronomy E3 121 > Social Science G3 197 Planning and Governance Services F4 174 Finance Department E4 139 Politics A2 31 95 Firth Court D3 105 Polymer Centre (Research) E2 117 Academic Secretary’s Office F4 174 Firth Hall D3 105 Portering Services D4 149 University parking Bus stop Academic Unit of Clinical Oncology A4 41 Florey Building D3 114 Portobello Centre H3 177 Academic Unit of Medical Education D5 141 French F3 184 Postgraduate Student Enquiries D3 120 (permit only) and service number Accommodation and Commercial Services 10 Print and Design Solutions D2 151 Addison Building D3 113 Probability and Statistics E3 121 Admissions Section C4 66 Genomic Medicine B5 87 propertywithUS D3 119 Adult Dental Care B4 47 Geography D2 102 Psychology B3 34 Aerospace Engineering H2 170 George Porter Building G1 190 Procurement and Supplies E4 139 Alfred Denny Building D3 111 Germanic Studies F3 184 Pure Mathematics E3 121 Alumni Relations E4 147 Goodwin Sports Centre A2 30 Supertram stop Banks with Amy Johnson Building H3 173 Graduate Research Centre Animal and Plant Sciences D3 111 > North Campus H1 193 Recruitment Support C4 72 and name cash dispensers Antibody Resource Centre D2 108 Graduate Research Office E4 147 Regent Court G3 166 Applied Mathematics -

Welcome to Sheffield Make the Most of Your
Your Open Day Guide Welcome Make the most to Sheffield of your day You have made a great choice in coming to visit us. The Open Day is as flexible as you want it to be; you choose Come and talk to us what to do and in which order, the only activities that are No matter what time you arrive, the Central Exhibition fixed are the subject talks. Use this guide to plan your day is a great place to head first – meet staff and students with us. from across the University and ask any questions you You don't need to sign in on the day – just head straight to your first session might have. when you arrive. Explore our campus From the Self-Guided Campus Tour to our Information Hubs around campus, the best way to find out about us is to see the University for yourself. Find out about your subject Whether you are set on one course or considering a few options, our subject exhibitions are perfect to get more detailed information – just don’t forget to attend your pre-booked subject talk. Take a tour Tours take place throughout the day to our student accommodation, the libraries, Sport Sheffield and the Students' Union. Get a feel for our city Sheffield is a city like no other with independent shops, a great food scene and plenty of cultural events. There is always something to see in Sheffield. 2 3 Central Exhibition Talks This is the best place to start no matter what time you These 20-minute presentations run throughout the arrive at the University. -

June 2019 ...You Are an Agent of Change
April – June 2019 ...You are an agent of change. A better world is possible. By taking the time to share, listen and understand each other, we can change the things that matter to each of us, together. Difference doesn’t have to mean division and success doesn’t rely on the failure of others. Welcome to the Festival of Debate 2019. Coordinated by Opus, the festival is a Within our reach we have the ideas and the means to tackle non-partisan city-wide programme of events that asks us to explore the most important social, economic, environmental and political issues of the day. the problems we all face. Many possible solutions already exist, but we need to act together. We need to learn how to CONTENTS make change. We need to be ambitious, loving and clever. We need to talk. 4. STRANDS 6. FESTIVAL HIGHLIGHTS What you think and do matters. Now more 10. APRIL EVENTS than ever, we need to carry hope in our fists 12. OUR DEMOCRACY HUB DAY and remember that nothing about us, without 14. APRIL EVENTS 15. MAY EVENTS us, is for us. 18. OUR PLANET HUB DAY 20. MAY EVENTS 32. LIVING TOGETHER HUB DAY 34. PROGRAMME AT A GLANCE 37. VENUES & ACCESS 40. PARTNERS & FUNDERS www.weareopus.org www.festivalofdebate.com 43. BECOME A ‘FRIEND OF OPUS’ STRANDS WHO WE ARE Contemplating who we are, what we do and what defines us. Strand sponsored by Abbeydale Brewery OUR DEMOCRACY Questioning where power lies, the systems that exist and the status quo. Strand sponsored by The Sheffield College OUR PLANET From climate crisis to alternative food production, discovering the natural world, the forces at work and our impact on them. -

Postgraduate Taught Students
Postgraduate taught students 1 A WORLD TOP 100 Welcome UNIVERSITY QS World to Sheffield University Rankings 2020 You’ve made a great choice in coming to visit us. The Open day will be an excellent opportunity to find out more about our University, the subjects you are interested in studying and the city of Sheffield. Use this guide to help plan your day with us. Top 50 most international universities in the world – Times Higher Education World University Rankings 2019 6 Nobel Prize winners A Member of the Russell Group – One of the 24 leading UK universities for research and teaching. Make the most of your day Take a tour Tours take place throughout the day at our student accommodation, libraries and the Students' Union. See page 6 for more information. Tell us you are here The first thing to do when you arrive is to register at the Find out about your subject Octagon Centre, anytime from 9:30am. You can attend up to two subject talks on the day, giving you the opportunity to explore your options and interests. Come and talk to us The central exhibition is a great place to start – you Explore our campus can meet staff and students from faculties and support services and ask any questions you might have. From the self-guided campus tour to meeting our ambassadors, the best way to find out about us is to see the University for yourself. Attend our talk series Get a feel for our city We have a number of talks to give you more information Sheffield is a city like no other with independent about our University.