Inserción De Datos De Sensores En Cadenas De Bloques Empleando Raspberry Pi Y Tecnologías Blockchain
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lightweight Django USING REST, WEBSOCKETS & BACKBONE
Lightweight Django USING REST, WEBSOCKETS & BACKBONE Julia Elman & Mark Lavin Lightweight Django LightweightDjango How can you take advantage of the Django framework to integrate complex “A great resource for client-side interactions and real-time features into your web applications? going beyond traditional Through a series of rapid application development projects, this hands-on book shows experienced Django developers how to include REST APIs, apps and learning how WebSockets, and client-side MVC frameworks such as Backbone.js into Django can power the new or existing projects. backend of single-page Learn how to make the most of Django’s decoupled design by choosing web applications.” the components you need to build the lightweight applications you want. —Aymeric Augustin Once you finish this book, you’ll know how to build single-page applications Django core developer, CTO, oscaro.com that respond to interactions in real time. If you’re familiar with Python and JavaScript, you’re good to go. “Such a good idea—I think this will lower the barrier ■ Learn a lightweight approach for starting a new Django project of entry for developers ■ Break reusable applications into smaller services that even more… the more communicate with one another I read, the more excited ■ Create a static, rapid prototyping site as a scaffold for websites and applications I am!” —Barbara Shaurette ■ Build a REST API with django-rest-framework Python Developer, Cox Media Group ■ Learn how to use Django with the Backbone.js MVC framework ■ Create a single-page web application on top of your REST API Lightweight ■ Integrate real-time features with WebSockets and the Tornado networking library ■ Use the book’s code-driven examples in your own projects Julia Elman, a frontend developer and tech education advocate, started learning Django in 2008 while working at World Online. -

Installation Guide
Oracle® Communications Session Monitor Installation Guide Release 4.3 F27697-02 July 2020 Oracle Communications Session Monitor Installation Guide, Release 4.3 F27697-02 Copyright © 2014, 2020, Oracle and/or its affiliates. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial computer software documentation" pursuant to the applicable Federal Acquisition -

Amazon Codeguru Profiler
Amazon CodeGuru Profiler User Guide Amazon CodeGuru Profiler User Guide Amazon CodeGuru Profiler: User Guide Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Amazon CodeGuru Profiler User Guide Table of Contents What is Amazon CodeGuru Profiler? ..................................................................................................... 1 What can I do with CodeGuru Profiler? ......................................................................................... 1 What languages are supported by CodeGuru Profiler? ..................................................................... 1 How do I get started with CodeGuru Profiler? ................................................................................ 1 Setting up ......................................................................................................................................... 3 Set up in the Lambda console ..................................................................................................... 3 Step 1: Sign up for AWS .................................................................................................... -

Bepasty Documentation Release 0.3.0
bepasty Documentation Release 0.3.0 The Bepasty Team (see AUTHORS file) Jul 02, 2019 Contents 1 Contents 3 1.1 bepasty..................................................3 1.2 Using bepasty’s web interface......................................4 1.3 Using bepasty with non-web clients...................................6 1.4 Quickstart................................................7 1.5 Installation tutorial with Debian, NGinx and gunicorn......................... 10 1.6 ChangeLog................................................ 12 1.7 The bepasty software Project....................................... 14 1.8 License.................................................. 14 1.9 Authors.................................................. 15 Index 17 i ii bepasty Documentation, Release 0.3.0 bepasty is like a pastebin for every kind of file (text, image, audio, video, documents, . ). You can upload multiple files at once, simply by drag and drop. Contents 1 bepasty Documentation, Release 0.3.0 2 Contents CHAPTER 1 Contents 1.1 bepasty bepasty is like a pastebin for all kinds of files (text, image, audio, video, documents, . , binary). The documentation is there: http://bepasty-server.readthedocs.org/en/latest/ 1.1.1 Features • Generic: – you can upload multiple files at once, simply by drag and drop – after upload, you get a unique link to a view of each file – on that view, we show actions you can do with the file, metadata of the file and, if possible, we also render the file contents – if you uploaded multiple files, you can create a pastebin with the list -

Zope Documentation Release 5.3
Zope Documentation Release 5.3 The Zope developer community Jul 31, 2021 Contents 1 What’s new in Zope 3 1.1 What’s new in Zope 5..........................................4 1.2 What’s new in Zope 4..........................................4 2 Installing Zope 11 2.1 Prerequisites............................................... 11 2.2 Installing Zope with zc.buildout .................................. 12 2.3 Installing Zope with pip ........................................ 13 2.4 Building the documentation with Sphinx ............................... 14 3 Configuring and Running Zope 15 3.1 Creating a Zope instance......................................... 16 3.2 Filesystem Permissions......................................... 17 3.3 Configuring Zope............................................. 17 3.4 Running Zope.............................................. 18 3.5 Running Zope (plone.recipe.zope2instance install)........................... 20 3.6 Logging In To Zope........................................... 21 3.7 Special access user accounts....................................... 22 3.8 Troubleshooting............................................. 22 3.9 Using alternative WSGI server software................................. 22 3.10 Debugging Zope applications under WSGI............................... 26 3.11 Zope configuration reference....................................... 27 4 Migrating between Zope versions 37 4.1 From Zope 2 to Zope 4 or 5....................................... 37 4.2 Migration from Zope 4 to Zope 5.0.................................. -

Oracle Communications Operations Monitor Licensing Information User Manual Licensing Information
Oracle® Communications Operations Monitor Licensing Information User Manual Release 4.4.0 E99936-01 December 2020 Copyright © 2000, 2020, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are “commercial computer software” pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. -

Polyglot Programming in Applications Used for Genetic Data Analysis
Hindawi Publishing Corporation BioMed Research International Volume 2014, Article ID 253013, 7 pages http://dx.doi.org/10.1155/2014/253013 Research Article Polyglot Programming in Applications Used for Genetic Data Analysis Robert M. Nowak InstituteofElectronicSystems,WarsawUniversityofTechnology,Nowowiejska15/19,00-665Warsaw,Poland Correspondence should be addressed to Robert M. Nowak; [email protected] Received 30 May 2014; Revised 22 July 2014; Accepted 31 July 2014; Published 14 August 2014 Academic Editor: Brian Oliver Copyright © 2014 Robert M. Nowak. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Applications used for the analysis of genetic data process large volumes of data with complex algorithms. High performance, flexibility, and a user interface with a web browser are required by these solutions, which can be achieved by using multiple programming languages. In this study, I developed a freely available framework for building software to analyze genetic data, which uses C++, Python, JavaScript, and several libraries. This system was used to build a number of genetic data processing applications and it reduced the time and costs of development. 1. Background facilitate an understanding of the biological meanings of the sequence, that is, its function and/or its structure. The number of computer programs for the analysis of Thelargenumberofpossiblecandidatesolutionsdur- geneticdataisincreasingsignificantly,butitstillneedstobe ing the analysis of genetic data means that the employed improved greatly because of the importance of result analysis algorithms must be selected carefully [2]. Exhaustive search with appropriate methods and the exponential growth in the algorithms must be supported by heuristics based on biologi- volume of genetic data. -

An Analysis of Python's Topics, Trends, and Technologies Through Mining Stack Overflow Discussions
1 An Analysis of Python’s Topics, Trends, and Technologies Through Mining Stack Overflow Discussions Hamed Tahmooresi, Abbas Heydarnoori, and Alireza Aghamohammadi F Abstract—Python is a popular, widely used, and general-purpose pro- (LDA) [3] to categorize discussions in specific areas such gramming language. In spite of its ever-growing community, researchers as web programming [4], mobile application development [5], have not performed much analysis on Python’s topics, trends, and tech- security [6], and blockchain [7]. However, none of them has nologies which provides insights for developers about Python commu- focused on Python. In this study, we shed light on the nity trends and main issues. In this article, we examine the main topics Python’s main areas of discussion through mining 2 461 876 related to this language being discussed by developers on one of the most popular Q&A websites, Stack Overflow, as well as temporal trends posts, from August 2008 to January 2019, using LDA based through mining 2 461 876 posts. To be more useful for the software topic modeling . We also analyze the temporal trends of engineers, we study what Python provides as the alternative to popular the extracted topics to find out how the developers’ interest technologies offered by common programming languages like Java. is changing over the time. After explaining the topics and Our results indicate that discussions about Python standard features, trends of Python, we investigate the technologies offered web programming, and scientific programming 1 are the most popular by Python, which are not properly revealed by the topic areas in the Python community. -

The Pyramid Web Application Development Framework Version 1.4.9
The Pyramid Web Application Development Framework Version 1.4.9 Chris McDonough Contents Front Matteri Copyright, Trademarks, and Attributions iii Typographical Conventionsv Author Introduction vii I Narrative Documentation1 1 Pyramid Introduction3 2 Installing Pyramid 23 3 Application Configuration 31 4 Creating Your First Pyramid Application 35 5 Creating a Pyramid Project 41 6 Startup 65 7 Request Processing 69 8 URL Dispatch 75 9 Views 99 10 Renderers 111 11 Templates 127 12 View Configuration 141 13 Static Assets 159 14 Request and Response Objects 169 15 Sessions 177 16 Using Events 185 17 Environment Variables and .ini File Settings 189 18 Logging 201 19 PasteDeploy Configuration Files 209 20 Command-Line Pyramid 213 21 Internationalization and Localization 231 22 Virtual Hosting 249 23 Unit, Integration, and Functional Testing 253 24 Resources 261 25 Much Ado About Traversal 273 26 Traversal 281 27 Security 293 28 Combining Traversal and URL Dispatch 305 29 Invoking a Subrequest 315 30 Using Hooks 321 31 Pyramid Configuration Introspection 347 32 Extending An Existing Pyramid Application 361 33 Advanced Configuration 367 34 Extending Pyramid Configuration 375 35 Thread Locals 383 36 Using the Zope Component Architecture in Pyramid 387 II Tutorials 393 37 ZODB + Traversal Wiki Tutorial 395 38 SQLAlchemy + URL Dispatch Wiki Tutorial 445 39 Converting a repoze.bfg Application to Pyramid 505 40 Running a Pyramid Application under mod_wsgi 509 III API Reference 513 41 pyramid.authorization 515 42 pyramid.authentication 517 43 pyramid.config -
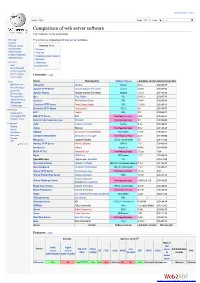
Comparison of Web Server Software from Wikipedia, the Free Encyclopedia
Create account Log in Article Talk Read Edit ViewM ohrisetory Search Comparison of web server software From Wikipedia, the free encyclopedia Main page This article is a comparison of web server software. Contents Featured content Contents [hide] Current events 1 Overview Random article 2 Features Donate to Wikipedia 3 Operating system support Wikimedia Shop 4 See also Interaction 5 References Help 6 External links About Wikipedia Community portal Recent changes Overview [edit] Contact page Tools Server Developed by Software license Last stable version Latest release date What links here AOLserver NaviSoft Mozilla 4.5.2 2012-09-19 Related changes Apache HTTP Server Apache Software Foundation Apache 2.4.10 2014-07-21 Upload file Special pages Apache Tomcat Apache Software Foundation Apache 7.0.53 2014-03-30 Permanent link Boa Paul Phillips GPL 0.94.13 2002-07-30 Page information Caudium The Caudium Group GPL 1.4.18 2012-02-24 Wikidata item Cite this page Cherokee HTTP Server Álvaro López Ortega GPL 1.2.103 2013-04-21 Hiawatha HTTP Server Hugo Leisink GPLv2 9.6 2014-06-01 Print/export Create a book HFS Rejetto GPL 2.2f 2009-02-17 Download as PDF IBM HTTP Server IBM Non-free proprietary 8.5.5 2013-06-14 Printable version Internet Information Services Microsoft Non-free proprietary 8.5 2013-09-09 Languages Jetty Eclipse Foundation Apache 9.1.4 2014-04-01 Čeština Jexus Bing Liu Non-free proprietary 5.5.2 2014-04-27 Galego Nederlands lighttpd Jan Kneschke (Incremental) BSD variant 1.4.35 2014-03-12 Português LiteSpeed Web Server LiteSpeed Technologies Non-free proprietary 4.2.3 2013-05-22 Русский Mongoose Cesanta Software GPLv2 / commercial 5.5 2014-10-28 中文 Edit links Monkey HTTP Server Monkey Software LGPLv2 1.5.1 2014-06-10 NaviServer Various Mozilla 1.1 4.99.6 2014-06-29 NCSA HTTPd Robert McCool Non-free proprietary 1.5.2a 1996 Nginx NGINX, Inc. -

Release 19.9.0 Benoit Chesneau
Gunicorn Documentation Release 19.9.0 Benoit Chesneau Jul 03, 2018 Contents 1 Features 3 2 Contents 5 2.1 Installation................................................5 2.2 Running Gunicorn............................................7 2.3 Configuration Overview.........................................9 2.4 Settings.................................................. 10 2.5 Instrumentation.............................................. 28 2.6 Deploying Gunicorn........................................... 29 2.7 Signal Handling............................................. 35 2.8 Custom Application........................................... 37 2.9 Design.................................................. 38 2.10 FAQ.................................................... 41 2.11 Community................................................ 43 2.12 Changelog................................................ 44 i ii Gunicorn Documentation, Release 19.9.0 Website http://gunicorn.org Source code https://github.com/benoitc/gunicorn Issue tracker https://github.com/benoitc/gunicorn/issues IRC #gunicorn on Freenode Usage questions https://github.com/benoitc/gunicorn/issues Gunicorn ‘Green Unicorn’ is a Python WSGI HTTP Server for UNIX. It’s a pre-fork worker model ported from Ruby’s Unicorn project. The Gunicorn server is broadly compatible with various web frameworks, simply implemented, light on server resources, and fairly speedy. Contents 1 Gunicorn Documentation, Release 19.9.0 2 Contents CHAPTER 1 Features • Natively supports WSGI, Django, and Paster • Automatic -

Oracle Communications Policy Management Licensing Information User Manual Release 12.5 Copyright © 2011, 2019, Oracle And/Or Its Affiliates
Oracle® Communications Policy Management Licensing Information User Manual Release 12.5.1 F16918-02 October 2019 Oracle Communications Policy Management Licensing Information User Manual Release 12.5 Copyright © 2011, 2019, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are “commercial computer software” pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs.