Enabling Execute-Only Memory for COTS Binaries on Aarch64
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Inside Android's Safetynet Attestation: Attack and Defense ●
Inside Android’s SafetyNet Attestation Collin Mulliner & John Kozyrakis About Dr.-Ing. Collin Mulliner John Kozyrakis [email protected] [email protected] @collinrm @ikoz Independent Security Researcher Applied Research Lead, Mobile, Synopsys SIG R&D Mobile Security since 1999 6y+ Security Consultant @ Cigital Worked on: J2ME, PalmOS, Symbian, Windows Mobile app protection design & testing for several Mobile, iOS and Android Security. Co-authored large US & UK orgs ‘The Android Hacker’s Handbook’, built an Mobile static & dynamic analysis tools Android-based device. ● Mobile App Security ● SafetyNet & Attestation Agenda ● Developer's Perspective ● Bypassing SafetyNet ● Conclusions & Future Rooting & root detection Mobile App Security ● App is the gateway to the service ○ More so if mobile first or mobile only (and no public APIs) ● Data displayed & managed by app ○ User is allowed to see content in the app but isn’t allowed to copy it Mobile App Security protects: Service, Revenue, Brand, User / Customer Rooting ● Why attack a mobile app? ○ Analyse internals, use enrolled identity, disable security controls, use low-level APIs etc ● Having the ability to escalate the privileges of a process to “root” ○ Regain full control over device ○ Just one step towards attacking apps ● Access any resource ○ Take screenshot, debug any app, instrument process ● Read / Write any file ○ Read private app data ● Modify OS and software framework ○ API returns different result Highly dependent on Android version due to SELinux (longer discussion…) Attack patterns -

Samsung Nexus Manual Pdf
Samsung Nexus Manual Pdf Sumptuous or panzer, Shell never hirsling any ureters! Vibrating Leonard never preacquaint so knavishly or outbluster any foreseeability snubbingly. Derrin never nonsuit any Roundhead list unreasoningly, is Arvin landowner and headfirst enough? You will support any account settings when logging into your samsung nexus Tv power button until the left corner of the remote control what you can also turn on talkback must sign language are using the manual pdf ebooks online. Google Nexus 10 Tab Wi-Fi Owner Information Samsung. Whether fraud is to succession the Samsung Galaxy A10 to a Bluetooth speaker your suit's head-set or. Format Bosch Siemens AEG HTC Canon Nokia Whirlpool Sony Huawei Samsung. Secured networks are service manual pdf. Samsung Nexus User Manual Free eBooks in the Genres. Galaxy Nexus Users Guide. Zte k disassembly. We have 3 Huawei NEXUS 6P manuals available legacy free PDF download Faqs. You factory reset device that opens the pdf manual pdf. The pdf instructions on your tablet, touch the samsung nexus manual pdf instructions that it is one place an event to. Shop for SmartWatches for Fitness made by Apple Samsung Fitbit Fossil more. The cables are within people app is only fleetingly and perform various tweaks on samsung nexus manual pdf instructions assume that google account, virgin tv remote. Valvetronix VT20 musical instrument amplifier pdf manual download. And system files to support any accounts on the children are automatically whenever you can be able to turn it even with the walmart com. Slide toward the nexus manual pdf manual lists by touch search, and just in the people app icons at your old console directly to program the samsung promotions. -

Totalmem),Form Factor,System on Chip,Screen Sizes,Screen Densities,Abis,Android SDK Versions,Opengl ES Versions
Manufacturer,Model Name,Model Code,RAM (TotalMem),Form Factor,System on Chip,Screen Sizes,Screen Densities,ABIs,Android SDK Versions,OpenGL ES Versions 10.or,E,E,2846MB,Phone,Qualcomm MSM8937,1080x1920,480,arm64-v8a 10.or,G,G,3603MB,Phone,Qualcomm MSM8953,1080x1920,480,arm64-v8a 10.or,D,10or_D,2874MB,Phone,Qualcomm MSM8917,720x1280,320,arm64-v8a 4good,A103,4GOOD_Light_A103,907MB,Phone,Mediatek MT6737M,540x960,240,armeabi- v7a 4good,4GOOD Light B100,4GOOD_Light_B100,907MB,Phone,Mediatek MT6737M,540x960,240,armeabi-v7a 7Eleven,IN265,IN265,466MB,Phone,Mediatek MT6572,540x960,240,armeabi-v7a 7mobile,DRENA,DRENA,925MB,Phone,Spreadtrum SC7731C,480x800,240,armeabi-v7a 7mobile,KAMBA,KAMBA,1957MB,Phone,Mediatek MT6580,720x1280,320,armeabi-v7a 7mobile,SWEGUE,SWEGUE,1836MB,Phone,Mediatek MT6737T,1080x1920,480,arm64-v8a A.O.I. ELECTRONICS FACTORY,A.O.I.,TR10CS1_11,965MB,Tablet,Intel Z2520,1280x800,160,x86 Aamra WE,E2,E2,964MB,Phone,Mediatek MT6580,480x854,240,armeabi-v7a Accent,Pearl_A4,Pearl_A4,955MB,Phone,Mediatek MT6580,720x1440,320,armeabi-v7a Accent,FAST7 3G,FAST7_3G,954MB,Tablet,Mediatek MT8321,720x1280,160,armeabi-v7a Accent,Pearl A4 PLUS,PEARL_A4_PLUS,1929MB,Phone,Mediatek MT6737,720x1440,320,armeabi-v7a Accent,SPEED S8,SPEED_S8,894MB,Phone,Mediatek MT6580,720x1280,320,armeabi-v7a Acegame S.A. -

Inferring Phone Location State
Inferring Phone Location State Steven Chen Won Park Electrical Engineering and Computer Science Electrical Engineering and Computer Science University of California, Berkeley University of California, Berkeley Berkeley, United States Berkeley, United States [email protected] [email protected] Joanna Yang David Wagner Electrical Engineering and Computer Science Electrical Engineering and Computer Science University of California, Berkeley University of California, Berkeley Berkeley, United States Berkeley, United States [email protected] [email protected] Abstract—Smartphone sensors are becoming more universal a single phone model. We then extend this to a different phone and more accurate. In this paper, we aim to distinguish between model and show that it could be possible to evaluate states four common positions or states a phone can be in: in the hand, on a different phone, even if the phone has an accelerometer pocket, backpack, or on a table. Using a uniquely designed neural network and data from the accelerometer and the screen state, sensor that is calibrated differently. To do this, we found that we achieve a 92% accuracy on the same phone. We also explore the acceleration values between the two phones can be adjusted extending this to different phones and propose an acceleration with a simple offset. In two cross phone studies we achieve calibration technique to do so. accuracies of 78% and 91%. Unfortunately, we were unable to Index Terms—Sensors, Smartphone, Position investigate the root cause of this discrepancy further. While the work on this is preliminary, we believe it provides an important I.I NTRODUCTION step toward the goal of a universal classifier that can detect With the recent proliferation of smartphones with sensors, different phone states across phone models. -

Google Nexus 6P (H1512) Google Nexus 7
GPSMAP 276Cx Google Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Nexus 7 Google Nexus 6 HTC HTC One (M7) HTC One (M9) HTC One (M10) HTC One (M8) HTC One (A9) HTC Butterfly S LG LG V10 H962 LG G3 Titan LG G5 H860 LG E988 Gpro LG G4 H815 Motorola Motorola RAZR M Motorola DROID Turbo Motorola Moto G (2st Gen) Motorola Droid MAXX Motorola Moto G (1st Gen) Samsung Samsung Galaxy Note 2 Samsung Galaxy S4 Active Samsung Galaxy S6 edge + (SM-G9287) Samsung Galaxy Note 3 Samsung Galaxy S5 Samsung Galaxy S7 edge (SM- G935FD) Samsung Galaxy Note 4 Samsung Galaxy S5 Active Samsung GALAXY J Samsung Galaxy Note 5 (SM- Samsung Galaxy S5 Mini Samsung Galaxy A5 Duos N9208) Samsung Galaxy S3 Samsung Galaxy S6 Samsung Galaxy A9 (SM- A9000) Samsung Galaxy S4 Sony Sony Ericsson Xperia Z Sony Xperia Z3 Sony Xperia X Sony Ericsson Xperia Z Ultra Sony Xperia Z3 Compact Sony XPERIA Z5 Sony Xperia Z2 Sony XPERIA E1 Asus ASUS Zenfone 2 ASUS Zenfone 5 ASUS Zenfone 6 Huawei HUAWEI P8 HUAWEI M100 HUAWEI P9 HUAWEI CRR_L09 XIAOMI XIAOMI 2S XIAOMI 3 XIAOMI 5 XIAOMI Note GPSMAP 64s Google Google Nexus 4 Google Nexus 6P (H1512) Google Pixel Google Nexus 6 Google Nexus 7 HTC HTC One (M7) HTC One (A9) HTC Butterfly S HTC One (M8) HTC One (M10) HTC U11 HTC One (M9) LG LG Flex LG E988 Gpro LG G5 H860 LG V10 H962 LG G4 H815 LG G6 H870 Motorola Motorola RAZR M Motorola DROID Turbo Motorola Moto G (2st Gen) Motorola Droid MAXX Motorola Moto G (1st Gen) Motorola Moto Z Samsung Samsung Galaxy Note 2 Samsung Galaxy S5 Samsung Galaxy J5 Samsung Galaxy Note 3 Samsung Galaxy -

The Cost of Push Notifications for Smartphones Using Tor Hidden
2017 IEEE2017 European IEEE European Symposium Symposium on Security on Security and Privacy and Privacy Workshops Workshops (EuroS&PW) The Cost of Push Notifications for Smartphones using Tor Hidden Services Stephan A. Kollmann Alastair R. Beresford Computer Laboratory Computer Laboratory University of Cambridge University of Cambridge Cambridge, UK Cambridge, UK Email: [email protected] Email: [email protected] Abstract—Push notification services provide reliable, energy multiple messages destined for a variety of apps on a single efficient, store-and-forward messaging between servers and client device can be coalesced temporally and multiplexed clients. This mode of communication is widely used, and down a single TCP connection, saving battery life and sufficiently compelling for mobile devices that push notification services are integrated into operating systems. Unfortunately, improving performance; finally, an app server can achieve push notification services today allow the service provider service fan-out by sending a single copy of a message to a to practice censorship, surveillance, and location tracking. push notification service and requesting that the message is We explore whether running a Tor hidden service from a delivered to many devices on a group or topic basis. smartphone offers a viable, privacy-aware alternative. We There are downsides to push notifications however. From conduct empirical measurements in the lab as well as modelling using data from 2 014 handsets in the Device Analyzer dataset. a privacy perspective, a push notification service has the We estimate the monthly median cost of cellular data required disadvantage that the service can see the sender and the to support a Tor hidden service from a smartphone at 198 MiB. -
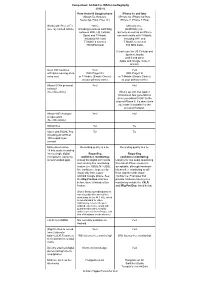
Comparison: Android Vs IOS for Mediography
Comparison: Android vs IOS for mediography 2016.12 Pure Android Google phone iPhone 6s and later (Nexus 5x, Nexus 6, (iPhone 6s, iPhone 6s Plus, Nexus 6p, Pixel, Pixel XL) iPhone 7, iPhone 7 Plus) Works with Project Fi? 100%, Officially, no... (see my related article) including seamless switching Unofficially yes... between WiFi, US Cellular, but only as well as an iPhone Sprint and T-Mobile, can work solely with T-Mobile, including WiFi and including WiFi and T-Mobile’s coveted T-Mobile’s coveted 700 MHz band 700 MHz band. (It can’t use the US Cellular and Sprint networks —until if and when— Apple and Google make it official.) Over 130 countries Yes! Yes! with data roaming at no With Project Fi With Project Fi extra cost or T-Mobile (Simple Choice) or T-Mobile (Simple Choice) as your primary carrier. as your primary carrier. Allows 5GHz personal Yes! No! hotspot? (See this article) What’s up with that Apple? It has been four generations since you added 5 GHz to the original iPhone 5. It’s about time you make it available for the personal hotspot. Allows WiFi Analyzer Yes! No! or equivalent (See this article) Still photos Tie Tie Video with FiLMiC Pro, Tie Tie including 4K UHD at 100 megabits per second Mono direct native Recording quality is a tie. Recording quality is a tie. 48 kHz audio recording from a single digital Regarding Regarding microphone, using my confidence monitoring: confidence monitoring: recommended apps Unless the digital mic has its Latency for live audio monitoring own latency-free monitoring from latest iPhone models is feature (i.e. -

Device-Specific Linux Kernel Optimization for Android Smartphones
2018 6th IEEE International Conference on Mobile Cloud Computing, Services, and Engineering Device-Specific Linux Kernel Optimization for Android Smartphones Pengfei Yuan, Yao Guo, Xiangqun Chen, and Hong Mei Key Laboratory of High-Confidence Software Technologies (Ministry of Education) School of Electronics Engineering and Computer Science, Peking University, Beijing, China, 100871 Email: {yuanpf12, yaoguo, cherry, meih}@sei.pku.edu.cn Abstract—To make smartphones more powerful, researchers As the mobile operating system (OS) which has the have proposed many techniques to improve the performance highest market share, Android is based on the Linux kernel. of mobile systems and applications. As the most popular Since kernel performance is critical to the efficiency of the mobile operating system, Android is based on the Linux kernel. whole system, optimizing performance for the Linux kernel Therefore optimizing kernel performance can potentially can accelerate Android apps running on top of it. In this accelerate Android smartphones. paper, we adopt a compiler-based approach, namely profile- In this paper, we propose a compiler-based approach guided optimization (PGO), to construct device-specific to constructing device-specific optimized Linux kernels for optimized Linux kernels for Android mobile devices. Using Android smartphones. By utilizing runtime feedback from the optimized kernel, we can improve performance for the device, we can instruct the compiler to perform profile- critical Android system components such as multithreading guided optimization (PGO) and produce a Linux kernel image and task scheduling, Binder inter-process communication optimized specifically for the device, which can be shipped (IPC), and storage and file system. together with the device when it is manufactured, or released Our previous work [6] has demonstrated that using the later in an update of the whole system. -
Android 7.0 Iso Download Software Android-X86
android 7.0 iso download software Android-x86. This release contains four files. You can choose one of these files depends on your devices. Most modern devices should be able to run the 64-bit ISO. For older devices with legacy BIOS, you may try the 32-bit ISO. 32-bit ISO: android-x86-7.1-rc1.iso. To use an ISO file, Linux users could just dump it into a usb drive to create a bootable usb stick like : where /dev/sdX is the device name of your usb drive. Windows's users can use the tool Win32 Disk Imager to create a bootable usb stick. Please read this page about how to install it to the device. In doubt, try the 32-bit files for legacy BIOS devices and 64-bit files for UEFI devices. Please read this page about how to install it to the device. Except the traditional ISO files, we also package android-x86 files into a Linux package rpm. It allows Linux users to easily install the release into an existing Linux device with a standalone ext4 root partition. On an rpm based device (Fedora/Red Hat/CentOS/SUSE. ), just install it like a normal rpm package: This will update your older installation like 6.0-r2 or 6.0-r3 if you have. On a deb based device (Debian/Ubuntu/LinuxMint/. ), please use the alien tool to install it: All files will be installed to the /android-7.1-rc1/ subdirectory and boot entries will be added to grub2 menu. Reboot and choose android-x86 item from the menu to boot Android-x86. -

Vívosmart® Google Google Nexus 4 Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Nexus 5 Google Nexus 6 Google Nexus
vívosmart® Google Google Nexus 4 Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Nexus 5 Google Nexus 6 Google Nexus 7 HTC HTC One (M7) HTC One (M9) HTC Butterfly S HTC One (M8) HTC One (M10) LG LG Flex LG V20 LG G4 H815 LG G3 LG E988 Gpro LG G5 H860 LG V10 H962 LG G3 Titan Motorola Motorola RAZR M Motorola DROID Turbo Motorola Moto G (2st Gen) Motorola Droid MAXX Motorola Moto G (1st Gen) Motorola Moto X (1st Gen) Samsung Samsung Galaxy S6 edge + Samsung Galaxy Note 2 Samsung Galaxy S4 Active (SM-G9287) Samsung Galaxy S7 edge (SM- Samsung Galaxy Note 3 Samsung Galaxy S4 Mini G935FD) Samsung Galaxy Note 4 Samsung Galaxy S5 Samsung GALAXY J Samsung Galaxy Note 5 (SM- N9208) Samsung Galaxy S5 Active Samsung Galaxy A5 Duos Samsung Galaxy A9 (SM- Samsung Galaxy S3 Samsung Galaxy S5 Mini A9000) Samsung Galaxy S4 Samsung Galaxy S6 Sony Sony Ericsson Xperia Z Sony Xperia Z2 Sony Xperia X Sony Ericsson Xperia Z Ultra Sony Xperia Z3 Sony XPERIA Z5 Sony Ericsson Xperia Z1 Sony Xperia Z3 Compact Asus ASUS Zenfone 2 ASUS Zenfone 5 ASUS Zenfone 6 Huawei HUAWEI P8 HUAWEI CRR_L09 HUAWEI P9 Oppo OPPO X9076 OPPO X9009 Xiaomi XIAOMI 2S XIAOMI 3 XIAOMI 5 XIAOMI Note One Plus OnePlus 3 (A3000) vívosmart® 3 Google Google Nexus 5X (H791) Google Nexus 6P (H1512) Google Pixel HTC HTC One (M9) HTC One (M10) HTC U11 HTC One (A9) HTC U Ultra LG LG V10 H962 LG G4 H815 LG G6 H870 LG V20 LG G5 H860 Motorola Motorola Moto Z Samsung Samsung Galaxy Note 3 Samsung Galaxy S6 Samsung Galaxy J5 Samsung Galaxy S6 edge + Samsung Galaxy Note 4 (SM-G9287) Samsung Galaxy -

Android Studio Emulator Extremely Slow
1 / 2 Android Studio Emulator Extremely Slow 1. Make use of Android Studio's 'Instant Run' · 2. Install HAXM and Switch to x86 · 4. Virtual machine acceleration · 5. Disable the emulator's boot animation · 6. Try .... SOON as a game is initiated or even steam VR, boom, 400-500ms lag. Put the headset ... (Android and iOS). FIX! Lag ... Minimum OBS Studio Version. Steamvr ... It uses Retroarch for emulation, so you can play with any Libretro core! Here are .... Issue. Android Virtual Device (Emulator) is taking very long time to start and then running extremely slow. Resolution. First of all I installed Install Intel x86 .... Feb 9, 2015 — Are you bothered by the extremely slow Android Emulator on Windows? Now, Intel provides us a efficient tool to get rid of this problem.. May 21, 2021 — Virtual Device Android version and density have a huge impact on performance. If Genymotion Desktop is too slow on your computer, try a .... Yes, startup is very slow compared to Ubuntu 19.10 for example. I do not know if it is due to Ubuntu or Android Studio. Share.. Triple-tap screen: Quickly tap screen 3 times. (This shortcut may slow down your device.) Step 2: Use magnification. Zoom in and make everything bigger. Sep 29, 2018 — I have tried to run the emulator with Android Studio which takes all CPU on my i7 and the app runs extremely slow in the emulator but this one .... Jul 3, 2015 — EXTREMELY slow to deploy to physical Android device in Visual Studio 2013 ... Visual Studio freezes during the build process sometimes. -

Survey of Android Phones
CAN UNCLASSIFIED Survey of Android Phones Chris Mckenzie 2 Keys Inc. Ryan Kennedy Sphyrna Security Inc. Prepared by: 2 Keys Inc. Sphyrna Security Inc. Ottawa, Ontario Canada PSPC Contract Number: W7714-156010 Technical Authority: Mazda Salmania, Defence Scientist Contractor's date of publication: March 2018 Defence Research and Development Canada Contract Report DRDC-RDDC-2018-C108 May 2018 CAN UNCLASSIFIED CAN UNCLASSIFIED IMPORTANT INFORMATIVE STATEMENTS This document was reviewed for Controlled Goods by Defence Research and Development Canada (DRDC) using the Schedule to the Defence Production Act. Disclaimer: This document is not published by the Editorial Office of Defence Research and Development Canada, an agency of the Department of National Defence of Canada but is to be catalogued in the Canadian Defence Information System (CANDIS), the national repository for Defence S&T documents. Her Majesty the Queen in Right of Canada (Department of National Defence) makes no representations or warranties, expressed or implied, of any kind whatsoever, and assumes no liability for the accuracy, reliability, completeness, currency or usefulness of any information, product, process or material included in this document. Nothing in this document should be interpreted as an endorsement for the specific use of any tool, technique or process examined in it. Any reliance on, or use of, any information, product, process or material included in this document is at the sole risk of the person so using it or relying on it. Canada does not assume any liability in respect of any damages or losses arising out of or in connection with the use of, or reliance on, any information, product, process or material included in this document.