Functional Programming in Javascript
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CSCI 2041: Lazy Evaluation
CSCI 2041: Lazy Evaluation Chris Kauffman Last Updated: Wed Dec 5 12:32:32 CST 2018 1 Logistics Reading Lab13: Lazy/Streams I Module Lazy on lazy Covers basics of delayed evaluation computation I Module Stream on streams A5: Calculon Lambdas/Closures I Arithmetic language Briefly discuss these as they interpreter pertain Calculon I 2X credit for assignment I 5 Required Problems 100pts Goals I 5 Option Problems 50pts I Eager Evaluation I Milestone due Wed 12/5 I Lazy Evaluation I Final submit Tue 12/11 I Streams 2 Evaluation Strategies Eager Evaluation Lazy Evaluation I Most languages employ I An alternative is lazy eager evaluation evaluation I Execute instructions as I Execute instructions only as control reaches associated expression results are needed code (call by need) I Corresponds closely to I Higher-level idea with actual machine execution advantages and disadvantages I In pure computations, evaluation strategy doesn’t matter: will produce the same results I With side-effects, when code is run matter, particular for I/O which may see different printing orders 3 Exercise: Side-Effects and Evaluation Strategy Most common place to see differences between Eager/Lazy eval is when functions are called I Eager eval: eval argument expressions, call functions with results I Lazy eval: call function with un-evaluated expressions, eval as results are needed Consider the following expression let print_it expr = printf "Printing it\n"; printf "%d\n" expr; ;; print_it (begin printf "Evaluating\n"; 5; end);; Predict results and output for both Eager and Lazy Eval strategies 4 Answers: Side-Effects and Evaluation Strategy let print_it expr = printf "Printing it\n"; printf "%d\n" expr; ;; print_it (begin printf "Evaluating\n"; 5; end);; Evaluation > ocamlc eager_v_lazy.ml > ./a.out Eager Eval # ocaml’s default Evaluating Printing it 5 Lazy Eval Printing it Evaluating 5 5 OCaml and explicit lazy Computations I OCaml’s default model is eager evaluation BUT. -
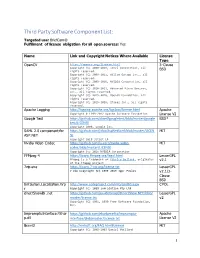
Third Party Software Component List: Targeted Use: Briefcam® Fulfillment of License Obligation for All Open Sources: Yes
Third Party Software Component List: Targeted use: BriefCam® Fulfillment of license obligation for all open sources: Yes Name Link and Copyright Notices Where Available License Type OpenCV https://opencv.org/license.html 3-Clause Copyright (C) 2000-2019, Intel Corporation, all BSD rights reserved. Copyright (C) 2009-2011, Willow Garage Inc., all rights reserved. Copyright (C) 2009-2016, NVIDIA Corporation, all rights reserved. Copyright (C) 2010-2013, Advanced Micro Devices, Inc., all rights reserved. Copyright (C) 2015-2016, OpenCV Foundation, all rights reserved. Copyright (C) 2015-2016, Itseez Inc., all rights reserved. Apache Logging http://logging.apache.org/log4cxx/license.html Apache Copyright © 1999-2012 Apache Software Foundation License V2 Google Test https://github.com/abseil/googletest/blob/master/google BSD* test/LICENSE Copyright 2008, Google Inc. SAML 2.0 component for https://github.com/jitbit/AspNetSaml/blob/master/LICEN MIT ASP.NET SE Copyright 2018 Jitbit LP Nvidia Video Codec https://github.com/lu-zero/nvidia-video- MIT codec/blob/master/LICENSE Copyright (c) 2016 NVIDIA Corporation FFMpeg 4 https://www.ffmpeg.org/legal.html LesserGPL FFmpeg is a trademark of Fabrice Bellard, originator v2.1 of the FFmpeg project 7zip.exe https://www.7-zip.org/license.txt LesserGPL 7-Zip Copyright (C) 1999-2019 Igor Pavlov v2.1/3- Clause BSD Infralution.Localization.Wp http://www.codeproject.com/info/cpol10.aspx CPOL f Copyright (C) 2018 Infralution Pty Ltd directShowlib .net https://github.com/pauldotknopf/DirectShow.NET/blob/ LesserGPL -

Functional Languages
Functional Programming Languages (FPL) 1. Definitions................................................................... 2 2. Applications ................................................................ 2 3. Examples..................................................................... 3 4. FPL Characteristics:.................................................... 3 5. Lambda calculus (LC)................................................. 4 6. Functions in FPLs ....................................................... 7 7. Modern functional languages...................................... 9 8. Scheme overview...................................................... 11 8.1. Get your own Scheme from MIT...................... 11 8.2. General overview.............................................. 11 8.3. Data Typing ...................................................... 12 8.4. Comments ......................................................... 12 8.5. Recursion Instead of Iteration........................... 13 8.6. Evaluation ......................................................... 14 8.7. Storing and using Scheme code ........................ 14 8.8. Variables ........................................................... 15 8.9. Data types.......................................................... 16 8.10. Arithmetic functions ......................................... 17 8.11. Selection functions............................................ 18 8.12. Iteration............................................................. 23 8.13. Defining functions ........................................... -

Akka Java Documentation Release 2.2.5
Akka Java Documentation Release 2.2.5 Typesafe Inc February 19, 2015 CONTENTS 1 Introduction 1 1.1 What is Akka?............................................1 1.2 Why Akka?..............................................3 1.3 Getting Started............................................3 1.4 The Obligatory Hello World.....................................7 1.5 Use-case and Deployment Scenarios.................................8 1.6 Examples of use-cases for Akka...................................9 2 General 10 2.1 Terminology, Concepts........................................ 10 2.2 Actor Systems............................................ 12 2.3 What is an Actor?.......................................... 14 2.4 Supervision and Monitoring..................................... 16 2.5 Actor References, Paths and Addresses............................... 19 2.6 Location Transparency........................................ 25 2.7 Akka and the Java Memory Model.................................. 26 2.8 Message Delivery Guarantees.................................... 28 2.9 Configuration............................................. 33 3 Actors 65 3.1 Actors................................................ 65 3.2 Typed Actors............................................. 84 3.3 Fault Tolerance............................................ 88 3.4 Dispatchers.............................................. 103 3.5 Mailboxes.............................................. 106 3.6 Routing................................................ 111 3.7 Building Finite State Machine -

The Machine That Builds Itself: How the Strengths of Lisp Family
Khomtchouk et al. OPINION NOTE The Machine that Builds Itself: How the Strengths of Lisp Family Languages Facilitate Building Complex and Flexible Bioinformatic Models Bohdan B. Khomtchouk1*, Edmund Weitz2 and Claes Wahlestedt1 *Correspondence: [email protected] Abstract 1Center for Therapeutic Innovation and Department of We address the need for expanding the presence of the Lisp family of Psychiatry and Behavioral programming languages in bioinformatics and computational biology research. Sciences, University of Miami Languages of this family, like Common Lisp, Scheme, or Clojure, facilitate the Miller School of Medicine, 1120 NW 14th ST, Miami, FL, USA creation of powerful and flexible software models that are required for complex 33136 and rapidly evolving domains like biology. We will point out several important key Full list of author information is features that distinguish languages of the Lisp family from other programming available at the end of the article languages and we will explain how these features can aid researchers in becoming more productive and creating better code. We will also show how these features make these languages ideal tools for artificial intelligence and machine learning applications. We will specifically stress the advantages of domain-specific languages (DSL): languages which are specialized to a particular area and thus not only facilitate easier research problem formulation, but also aid in the establishment of standards and best programming practices as applied to the specific research field at hand. DSLs are particularly easy to build in Common Lisp, the most comprehensive Lisp dialect, which is commonly referred to as the “programmable programming language.” We are convinced that Lisp grants programmers unprecedented power to build increasingly sophisticated artificial intelligence systems that may ultimately transform machine learning and AI research in bioinformatics and computational biology. -

Functional Programming Laboratory 1 Programming Paradigms
Intro 1 Functional Programming Laboratory C. Beeri 1 Programming Paradigms A programming paradigm is an approach to programming: what is a program, how are programs designed and written, and how are the goals of programs achieved by their execution. A paradigm is an idea in pure form; it is realized in a language by a set of constructs and by methodologies for using them. Languages sometimes combine several paradigms. The notion of paradigm provides a useful guide to understanding programming languages. The imperative paradigm underlies languages such as Pascal and C. The object-oriented paradigm is embodied in Smalltalk, C++ and Java. These are probably the paradigms known to the students taking this lab. We introduce functional programming by comparing it to them. 1.1 Imperative and object-oriented programming Imperative programming is based on a simple construct: A cell is a container of data, whose contents can be changed. A cell is an abstraction of a memory location. It can store data, such as integers or real numbers, or addresses of other cells. The abstraction hides the size bounds that apply to real memory, as well as the physical address space details. The variables of Pascal and C denote cells. The programming construct that allows to change the contents of a cell is assignment. In the imperative paradigm a program has, at each point of its execution, a state represented by a collection of cells and their contents. This state changes as the program executes; assignment statements change the contents of cells, other statements create and destroy cells. Yet others, such as conditional and loop statements allow the programmer to direct the control flow of the program. -

Functional and Imperative Object-Oriented Programming in Theory and Practice
Uppsala universitet Inst. för informatik och media Functional and Imperative Object-Oriented Programming in Theory and Practice A Study of Online Discussions in the Programming Community Per Jernlund & Martin Stenberg Kurs: Examensarbete Nivå: C Termin: VT-19 Datum: 14-06-2019 Abstract Functional programming (FP) has progressively become more prevalent and techniques from the FP paradigm has been implemented in many different Imperative object-oriented programming (OOP) languages. However, there is no indication that OOP is going out of style. Nevertheless the increased popularity in FP has sparked new discussions across the Internet between the FP and OOP communities regarding a multitude of related aspects. These discussions could provide insights into the questions and challenges faced by programmers today. This thesis investigates these online discussions in a small and contemporary scale in order to identify the most discussed aspect of FP and OOP. Once identified the statements and claims made by various discussion participants were selected and compared to literature relating to the aspects and the theory behind the paradigms in order to determine whether there was any discrepancies between practitioners and theory. It was done in order to investigate whether the practitioners had different ideas in the form of best practices that could influence theories. The most discussed aspect within FP and OOP was immutability and state relating primarily to the aspects of concurrency and performance. This thesis presents a selection of representative quotes that illustrate the different points of view held by groups in the community and then addresses those claims by investigating what is said in literature. -

** OPEN SOURCE LIBRARIES USED in Tv.Verizon.Com/Watch
** OPEN SOURCE LIBRARIES USED IN tv.verizon.com/watch ------------------------------------------------------------ 02/27/2019 tv.verizon.com/watch uses Node.js 6.4 on the server side and React.js on the client- side. Both are Javascript frameworks. Below are the licenses and a list of the JS libraries being used. ** NODE.JS 6.4 ------------------------------------------------------------ https://github.com/nodejs/node/blob/master/LICENSE Node.js is licensed for use as follows: """ Copyright Node.js contributors. All rights reserved. Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. """ This license applies to parts of Node.js originating from the https://github.com/joyent/node repository: """ Copyright Joyent, Inc. and other Node contributors. -

A Scalable Provenance Evaluation Strategy
Debugging Large-scale Datalog: A Scalable Provenance Evaluation Strategy DAVID ZHAO, University of Sydney 7 PAVLE SUBOTIĆ, Amazon BERNHARD SCHOLZ, University of Sydney Logic programming languages such as Datalog have become popular as Domain Specific Languages (DSLs) for solving large-scale, real-world problems, in particular, static program analysis and network analysis. The logic specifications that model analysis problems process millions of tuples of data and contain hundredsof highly recursive rules. As a result, they are notoriously difficult to debug. While the database community has proposed several data provenance techniques that address the Declarative Debugging Challenge for Databases, in the cases of analysis problems, these state-of-the-art techniques do not scale. In this article, we introduce a novel bottom-up Datalog evaluation strategy for debugging: Our provenance evaluation strategy relies on a new provenance lattice that includes proof annotations and a new fixed-point semantics for semi-naïve evaluation. A debugging query mechanism allows arbitrary provenance queries, constructing partial proof trees of tuples with minimal height. We integrate our technique into Soufflé, a Datalog engine that synthesizes C++ code, and achieve high performance by using specialized parallel data structures. Experiments are conducted with Doop/DaCapo, producing proof annotations for tens of millions of output tuples. We show that our method has a runtime overhead of 1.31× on average while being more flexible than existing state-of-the-art techniques. CCS Concepts: • Software and its engineering → Constraint and logic languages; Software testing and debugging; Additional Key Words and Phrases: Static analysis, datalog, provenance ACM Reference format: David Zhao, Pavle Subotić, and Bernhard Scholz. -

Implementing a Vau-Based Language with Multiple Evaluation Strategies
Implementing a Vau-based Language With Multiple Evaluation Strategies Logan Kearsley Brigham Young University Introduction Vau expressions can be simply defined as functions which do not evaluate their argument expressions when called, but instead provide access to a reification of the calling environment to explicitly evaluate arguments later, and are a form of statically-scoped fexpr (Shutt, 2010). Control over when and if arguments are evaluated allows vau expressions to be used to simulate any evaluation strategy. Additionally, the ability to choose not to evaluate certain arguments to inspect the syntactic structure of unevaluated arguments allows vau expressions to simulate macros at run-time and to replace many syntactic constructs that otherwise have to be built-in to a language implementation. In principle, this allows for significant simplification of the interpreter for vau expressions; compared to McCarthy's original LISP definition (McCarthy, 1960), vau's eval function removes all references to built-in functions or syntactic forms, and alters function calls to skip argument evaluation and add an implicit env parameter (in real implementations, the name of the environment parameter is customizable in a function definition, rather than being a keyword built-in to the language). McCarthy's Eval Function Vau Eval Function (transformed from the original M-expressions into more familiar s-expressions) (define (eval e a) (define (eval e a) (cond (cond ((atom e) (assoc e a)) ((atom e) (assoc e a)) ((atom (car e)) ((atom (car e)) (cond (eval (cons (assoc (car e) a) ((eq (car e) 'quote) (cadr e)) (cdr e)) ((eq (car e) 'atom) (atom (eval (cadr e) a))) a)) ((eq (car e) 'eq) (eq (eval (cadr e) a) ((eq (caar e) 'vau) (eval (caddr e) a))) (eval (caddar e) ((eq (car e) 'car) (car (eval (cadr e) a))) (cons (cons (cadar e) 'env) ((eq (car e) 'cdr) (cdr (eval (cadr e) a))) (append (pair (cadar e) (cdr e)) ((eq (car e) 'cons) (cons (eval (cadr e) a) a)))))) (eval (caddr e) a))) ((eq (car e) 'cond) (evcon. -

Comparative Studies of Programming Languages; Course Lecture Notes
Comparative Studies of Programming Languages, COMP6411 Lecture Notes, Revision 1.9 Joey Paquet Serguei A. Mokhov (Eds.) August 5, 2010 arXiv:1007.2123v6 [cs.PL] 4 Aug 2010 2 Preface Lecture notes for the Comparative Studies of Programming Languages course, COMP6411, taught at the Department of Computer Science and Software Engineering, Faculty of Engineering and Computer Science, Concordia University, Montreal, QC, Canada. These notes include a compiled book of primarily related articles from the Wikipedia, the Free Encyclopedia [24], as well as Comparative Programming Languages book [7] and other resources, including our own. The original notes were compiled by Dr. Paquet [14] 3 4 Contents 1 Brief History and Genealogy of Programming Languages 7 1.1 Introduction . 7 1.1.1 Subreferences . 7 1.2 History . 7 1.2.1 Pre-computer era . 7 1.2.2 Subreferences . 8 1.2.3 Early computer era . 8 1.2.4 Subreferences . 8 1.2.5 Modern/Structured programming languages . 9 1.3 References . 19 2 Programming Paradigms 21 2.1 Introduction . 21 2.2 History . 21 2.2.1 Low-level: binary, assembly . 21 2.2.2 Procedural programming . 22 2.2.3 Object-oriented programming . 23 2.2.4 Declarative programming . 27 3 Program Evaluation 33 3.1 Program analysis and translation phases . 33 3.1.1 Front end . 33 3.1.2 Back end . 34 3.2 Compilation vs. interpretation . 34 3.2.1 Compilation . 34 3.2.2 Interpretation . 36 3.2.3 Subreferences . 37 3.3 Type System . 38 3.3.1 Type checking . 38 3.4 Memory management . -

Npm Packages As Ingredients: a Recipe-Based Approach
npm Packages as Ingredients: a Recipe-based Approach Kyriakos C. Chatzidimitriou, Michail D. Papamichail, Themistoklis Diamantopoulos, Napoleon-Christos Oikonomou, and Andreas L. Symeonidis Electrical and Computer Engineering Dept., Aristotle University of Thessaloniki, Thessaloniki, Greece fkyrcha, mpapamic, thdiaman, [email protected], [email protected] Keywords: Dependency Networks, Software Reuse, JavaScript, npm, node. Abstract: The sharing and growth of open source software packages in the npm JavaScript (JS) ecosystem has been exponential, not only in numbers but also in terms of interconnectivity, to the extend that often the size of de- pendencies has become more than the size of the written code. This reuse-oriented paradigm, often attributed to the lack of a standard library in node and/or in the micropackaging culture of the ecosystem, yields interest- ing insights on the way developers build their packages. In this work we view the dependency network of the npm ecosystem from a “culinary” perspective. We assume that dependencies are the ingredients in a recipe, which corresponds to the produced software package. We employ network analysis and information retrieval techniques in order to capture the dependencies that tend to co-occur in the development of npm packages and identify the communities that have been evolved as the main drivers for npm’s exponential growth. 1 INTRODUCTION Given that dependencies and reusability have be- come very important in today’s software develop- The popularity of JS is constantly increasing, and ment process, npm registry has become a “must” along is increasing the popularity of frameworks for place for developers to share packages, defining code building server (e.g.