Game Theory Model and Empirical Evidence
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Determinants of Efficient Behavior in Coordination Games
The Determinants of Efficient Behavior in Coordination Games Pedro Dal B´o Guillaume R. Fr´echette Jeongbin Kim* Brown University & NBER New York University Caltech May 20, 2020 Abstract We study the determinants of efficient behavior in stag hunt games (2x2 symmetric coordination games with Pareto ranked equilibria) using both data from eight previous experiments on stag hunt games and data from a new experiment which allows for a more systematic variation of parameters. In line with the previous experimental literature, we find that subjects do not necessarily play the efficient action (stag). While the rate of stag is greater when stag is risk dominant, we find that the equilibrium selection criterion of risk dominance is neither a necessary nor sufficient condition for a majority of subjects to choose the efficient action. We do find that an increase in the size of the basin of attraction of stag results in an increase in efficient behavior. We show that the results are robust to controlling for risk preferences. JEL codes: C9, D7. Keywords: Coordination games, strategic uncertainty, equilibrium selection. *We thank all the authors who made available the data that we use from previous articles, Hui Wen Ng for her assistance running experiments and Anna Aizer for useful comments. 1 1 Introduction The study of coordination games has a long history as many situations of interest present a coordination component: for example, the choice of technologies that require a threshold number of users to be sustainable, currency attacks, bank runs, asset price bubbles, cooper- ation in repeated games, etc. In such examples, agents may face strategic uncertainty; that is, they may be uncertain about how the other agents will respond to the multiplicity of equilibria, even when they have complete information about the environment. -

Lecture 4 Rationalizability & Nash Equilibrium Road
Lecture 4 Rationalizability & Nash Equilibrium 14.12 Game Theory Muhamet Yildiz Road Map 1. Strategies – completed 2. Quiz 3. Dominance 4. Dominant-strategy equilibrium 5. Rationalizability 6. Nash Equilibrium 1 Strategy A strategy of a player is a complete contingent-plan, determining which action he will take at each information set he is to move (including the information sets that will not be reached according to this strategy). Matching pennies with perfect information 2’s Strategies: HH = Head if 1 plays Head, 1 Head if 1 plays Tail; HT = Head if 1 plays Head, Head Tail Tail if 1 plays Tail; 2 TH = Tail if 1 plays Head, 2 Head if 1 plays Tail; head tail head tail TT = Tail if 1 plays Head, Tail if 1 plays Tail. (-1,1) (1,-1) (1,-1) (-1,1) 2 Matching pennies with perfect information 2 1 HH HT TH TT Head Tail Matching pennies with Imperfect information 1 2 1 Head Tail Head Tail 2 Head (-1,1) (1,-1) head tail head tail Tail (1,-1) (-1,1) (-1,1) (1,-1) (1,-1) (-1,1) 3 A game with nature Left (5, 0) 1 Head 1/2 Right (2, 2) Nature (3, 3) 1/2 Left Tail 2 Right (0, -5) Mixed Strategy Definition: A mixed strategy of a player is a probability distribution over the set of his strategies. Pure strategies: Si = {si1,si2,…,sik} σ → A mixed strategy: i: S [0,1] s.t. σ σ σ i(si1) + i(si2) + … + i(sik) = 1. If the other players play s-i =(s1,…, si-1,si+1,…,sn), then σ the expected utility of playing i is σ σ σ i(si1)ui(si1,s-i) + i(si2)ui(si2,s-i) + … + i(sik)ui(sik,s-i). -

Lecture Notes
GRADUATE GAME THEORY LECTURE NOTES BY OMER TAMUZ California Institute of Technology 2018 Acknowledgments These lecture notes are partially adapted from Osborne and Rubinstein [29], Maschler, Solan and Zamir [23], lecture notes by Federico Echenique, and slides by Daron Acemoglu and Asu Ozdaglar. I am indebted to Seo Young (Silvia) Kim and Zhuofang Li for their help in finding and correcting many errors. Any comments or suggestions are welcome. 2 Contents 1 Extensive form games with perfect information 7 1.1 Tic-Tac-Toe ........................................ 7 1.2 The Sweet Fifteen Game ................................ 7 1.3 Chess ............................................ 7 1.4 Definition of extensive form games with perfect information ........... 10 1.5 The ultimatum game .................................. 10 1.6 Equilibria ......................................... 11 1.7 The centipede game ................................... 11 1.8 Subgames and subgame perfect equilibria ...................... 13 1.9 The dollar auction .................................... 14 1.10 Backward induction, Kuhn’s Theorem and a proof of Zermelo’s Theorem ... 15 2 Strategic form games 17 2.1 Definition ......................................... 17 2.2 Nash equilibria ...................................... 17 2.3 Classical examples .................................... 17 2.4 Dominated strategies .................................. 22 2.5 Repeated elimination of dominated strategies ................... 22 2.6 Dominant strategies .................................. -

Tough Talk, Cheap Talk, and Babbling: Government Unity, Hawkishness
Tough Talk, Cheap Talk, and Babbling: Government Unity, Hawkishness and Military Challenges By Matthew Blake Fehrs Department of Political Science Duke University Date:_____________________ Approved: ___________________________ Joseph Grieco, Supervisor __________________________ Alexander Downes __________________________ Peter Feaver __________________________ Chris Gelpi __________________________ Erik Wibbels Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Political Science in the Graduate School of Duke University 2008 ABSTRACT Tough Talk, Cheap Talk, and Babbling: Government Unity, Hawkishness and Military Challenges By Matthew Blake Fehrs Department of Political Science Duke University Date:_____________________ Approved: ___________________________ Joseph Grieco, Supervisor __________________________ Alexander Downes __________________________ Peter Feaver __________________________ Chris Gelpi __________________________ Erik Wibbels An abstract of a dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Political Science in the Graduate School of Duke University 2008 Copyrighted by Matthew Blake Fehrs 2008 Abstract A number of puzzles exist regarding the role of domestic politics in the likelihood of international conflict. In particular, the sources of incomplete information remain under-theorized and the microfoundations deficient. This study will examine the role that the unity of the government and the views of the government towards the use of force play in the targeting of states. The theory presented argues that divided dovish governments are particularly likely to suffer from military challenges. In particular, divided governments have difficulty signaling their intentions, taking decisive action, and may appear weak. The theory will be tested on a new dataset created by the author that examines the theory in the context of international territorial disputes. -

Forward Guidance: Communication, Commitment, Or Both?
Forward Guidance: Communication, Commitment, or Both? Marco Bassetto July 25, 2019 WP 2019-05 https://doi.org/10.21033/wp-2019-05 *Working papers are not edited, and all opinions and errors are the responsibility of the author(s). The views expressed do not necessarily reflect the views of the Federal Reserve Bank of Chicago or the Federal Federal Reserve Bank of Chicago Reserve Federal Reserve System. Forward Guidance: Communication, Commitment, or Both?∗ Marco Bassettoy July 25, 2019 Abstract A policy of forward guidance has been suggested either as a form of commitment (\Odyssean") or as a way of conveying information to the public (\Delphic"). I an- alyze the strategic interaction between households and the central bank as a game in which the central bank can send messages to the public independently of its actions. In the absence of private information, the set of equilibrium payoffs is independent of the announcements of the central bank: forward guidance as a pure commitment mechanism is a redundant policy instrument. When private information is present, central bank communication can instead have social value. Forward guidance emerges as a natural communication strategy when the private information in the hands of the central bank concerns its own preferences or beliefs: while forward guidance per se is not a substitute for the central bank's commitment or credibility, it is an instrument that allows policymakers to leverage their credibility to convey valuable information about their future policy plans. It is in this context that \Odyssean forward guidance" can be understood. ∗I thank Gadi Barlevy, Jeffrey Campbell, Martin Cripps, Mariacristina De Nardi, Fernando Duarte, Marco Del Negro, Charles L. -

Mill's Conversion: the Herschel Connection
volume 18, no. 23 Introduction november 2018 John Stuart Mill’s A System of Logic, Ratiocinative and Inductive, being a connected view of the principles of evidence, and the methods of scientific investigation was the most popular and influential treatment of sci- entific method throughout the second half of the 19th century. As is well-known, there was a radical change in the view of probability en- dorsed between the first and second editions. There are three differ- Mill’s Conversion: ent conceptions of probability interacting throughout the history of probability: (1) Chance, or Propensity — for example, the bias of a bi- The Herschel Connection ased coin. (2) Judgmental Degree of Belief — for example, the de- gree of belief one should have that the bias is between .6 and .7 after 100 trials that produce 81 heads. (3) Long-Run Relative Frequency — for example, propor- tion of heads in a very large, or even infinite, number of flips of a given coin. It has been a matter of controversy, and continues to be to this day, which conceptions are basic. Strong advocates of one kind of prob- ability may deny that the others are important, or even that they make Brian Skyrms sense at all. University of California, Irvine, and Stanford University In the first edition of 1843, Mill espouses a frequency view of prob- ability that aligns well with his general material view of logic: Conclusions respecting the probability of a fact rest, not upon a different, but upon the very same basis, as conclu- sions respecting its certainly; namely, not our ignorance, © 2018 Brian Skyrms but our knowledge: knowledge obtained by experience, This work is licensed under a Creative Commons of the proportion between the cases in which the fact oc- Attribution-NonCommercial-NoDerivatives 3.0 License. -

1 SAYING and MEANING, CHEAP TALK and CREDIBILITY Robert
SAYING AND MEANING, CHEAP TALK AND CREDIBILITY Robert Stalnaker In May 2003, the U.S. Treasury Secretary, John Snow, in response to a question, made some remarks that caused the dollar to drop precipitously in value. The Wall Street Journal sharply criticized him for "playing with fire," and characterized his remarks as "dumping on his own currency", "bashing the dollar," and "talking the dollar down". What he in fact said was this: "When the dollar is at a lower level it helps exports, and I think exports are getting stronger as a result." This was an uncontroversial factual claim that everyone, whatever his or her views about what US government currency policy is or should be, would agree with. Why did it have such an impact? "What he has done," Alan Blinder said, "is stated one of those obvious truths that the secretary of the Treasury isn't supposed to say. When the secretary of the Treasury says something like that, it gets imbued with deep meaning whether he wants it to or not." Some thought the secretary knew what he was doing, and intended his remarks to have the effect that they had. ("I think he chose his words carefully," said one currency strategist.) Others thought that he was "straying from the script," and "isn't yet fluent in the delicate language of dollar policy." The Secretary, and other officials, followed up his initial remarks by reiterating that the government's policy was to support a strong dollar, but some still saw his initial remark as a signal that "the Bush administration secretly welcomes the dollar's decline."1 The explicit policy statements apparently lacked credibility. -

Evolution and the Social Contract
Evolution and the Social Contract BRIAN SKYRMS The Tanner Lectures on Human Values Delivered at Te University of Michigan November 2, 2007 Peterson_TL28_pp i-250.indd 47 11/4/09 9:26 AM Brian Skyrms is Distinguished Professor of Logic and Philosophy of Science and of Economics at the University of California, Irvine, and Pro- fessor of Philosophy and Religion at Stanford University. He graduated from Lehigh University with degrees in Economics and Philosophy and received his Ph.D. in Philosophy from the University of Pittsburgh. He is a Fellow of the American Academy of Arts and Sciences, the National Academy of Sciences, and the American Association for the Advancement of Science. His publications include Te Dynamics of Rational Delibera- tion (1990), Evolution of the Social Contract (1996), and Te Stag Hunt and the Evolution of Social Structure (2004). Peterson_TL28_pp i-250.indd 48 11/4/09 9:26 AM DEWEY AND DARWIN Almost one hundred years ago John Dewey wrote an essay titled “Te In- fuence of Darwin on Philosophy.” At that time, he believed that it was really too early to tell what the infuence of Darwin would be: “Te exact bearings upon philosophy of the new logical outlook are, of course, as yet, uncertain and inchoate.” But he was sure that it would not be in provid- ing new answers to traditional philosophical questions. Rather, it would raise new questions and open up new lines of thought. Toward the old questions of philosophy, Dewey took a radical stance: “Old questions are solved by disappearing . while new questions . -
Lecture 19: Costly Signaling Vs. Cheap Talk – 15.025 Game Theory
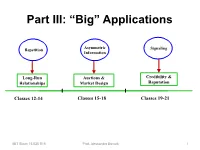
Part III: “Big” Applications Asymmetric Repetition Signaling Information Long-Run Auctions & Credibility & Relationships Market Design Reputation Classes 12-14 Classes 15-18 Classes 19-21 MIT Sloan 15.025 S15 Prof. Alessandro Bonatti 1 Signaling Games How to Make Communication Credible Chapter 1 (Today): Costly Signaling MIT Sloan 15.025 S15 Prof. Alessandro Bonatti 2 Signaling Examples • Entry deterrence: – Incumbent tries to signal its resolve to fight to deter entrants How can strong informed players distinguish themselves? • Credence Goods: – Used car warranties Can weak players signal-jam? Two of your class projects • Social interactions already using this… – Fashion (pitching a lemon, Estonia) MIT Sloan 15.025 S15 Prof. Alessandro Bonatti 3 The beer & quiche model • A monopolist can be either a tough incumbent or a wimp (not tough). • Incumbent earns 4 if the entrant stays out. • Incumbent earns 2 if the entrant enters. • Entrant earns 2 if it enters against wimp. • Entrant earns -1 if it enters against tough. • Entrant gets 0 if it stays out. MIT Sloan 15.025 S15 Prof. Alessandro Bonatti 4 Beer & Quiche • Prior to the entrant’s decision to enter or stay out, the incumbent gets to choose its “breakfast.” • The incumbent can have beer or quiche for breakfast. • Breakfasts are consumed in public. • Eating quiche “costs” 0. • Drinking beer costs differently according to type: – a beer breakfast costs a tough incumbent 1… – but costs a wimp incumbent 3. MIT Sloan 15.025 S15 Prof. Alessandro Bonatti 5 What’s Beer? Toughness Beer Excess Capacity High Output Low Costs Low Prices Beat up Rivals & Deep Pockets Previous Entrants MIT Sloan 15.025 S15 Prof. -

Cheap Talk and Authoritative Figures in Empirical Experiments ∗
Cheap Talk and Authoritative Figures in Empirical Experiments ∗ Alfred Pang December 9, 2005 Abstract Cheap talk refers to non-binding, costless, non-veriable communications that agents may participate in, before or during a game. It is dicult to observe collusion through cheap talk in empirical experiements. One rea- son for this is our cultural programming that causes us to obey authority gures. 1 Introduction Cheap talk is a term used by game theorists used to describe the communications that take place between agents before the start of a game. The purpose of cheap talk depends on the game being played. For example, if cheap talk is allowed before the start of Battle of the Sexes game, it is used for assisting in the coordination between the agents onto one of the Nash equilibria as shown by Cooper et al [4]. Although cheap talk generally leads to better results in games of coordination as shown by Farrell [2] and Farrell and Rabin [1], this is not always the case. It is known that cheap talk before a singleton Prisoner's Dilemma does not contribute to the cooperation result, if the agents do not have externalities in the result (that is, the agents do not have any utility for a preference to coordinate). Let us examine the attributes of cheap talk: 1. Non-binding - There is no direct penalty for declaring or promising actions and not following through. 2. Costless - There is no cost to the communications. However, it is not completely unlimited. The agents (in real-life and in theory) often have limitations in the communications language and the duration of the cheap talk that limits the possible communications exchanges. -

Ten Great Ideas About Chance a Review by Mark Huber
BOOK REVIEW Ten Great Ideas about Chance A Review by Mark Huber Ten Great Ideas About Chance Having had Diaconis as my professor and postdoctoral By Persi Diaconis and Brian Skyrms advisor some two decades ago, I found the cadences and style of much of the text familiar. Throughout, the book Most people are familiar with the is written in an engaging and readable way. History and basic rules and formulas of prob- philosophy are woven together throughout the chapters, ability. For instance, the chance which, as the title implies, are organized thematically rather that event A occurs plus the chance than chronologically. that A does not occur must add to The story begins with the first great idea: Chance can be 1. But the question of why these measured. The word probability itself derives from the Latin rules exist and what exactly prob- probabilis, used by Cicero to denote that “...which for the abilities are, well, that is a question most part usually comes to pass” (De inventione, I.29.46, Princeton University Press, 2018 Press, Princeton University ISBN: 9780691174167 272 pages, Hardcover, often left unaddressed in prob- [2]). Even today, modern courtrooms in the United States ability courses ranging from the shy away from assigning numerical values to probabilities, elementary to graduate level. preferring statements such as “preponderance of the evi- Persi Diaconis and Brian Skyrms have taken up these dence” or “beyond a reasonable doubt.” Those dealing with questions in Ten Great Ideas About Chance, a whirlwind chance and the unknown are reluctant to assign an actual tour through the history and philosophy of probability. -

Introduction to Game Theory Lecture 1: Strategic Game and Nash Equilibrium
Game Theory and Rational Choice Strategic-form Games Nash Equilibrium Examples (Non-)Strict Nash Equilibrium . Introduction to Game Theory Lecture 1: Strategic Game and Nash Equilibrium . Haifeng Huang University of California, Merced Shanghai, Summer 2011 . • Rational choice: the action chosen by a decision maker is better or at least as good as every other available action, according to her preferences and given her constraints (e.g., resources, information, etc.). • Preferences (偏好) are rational if they satisfy . Completeness (完备性): between any x and y in a set, x ≻ y (x is preferred to y), y ≻ x, or x ∼ y (indifferent) . Transitivity(传递性): x ≽ y and y ≽ z )x ≽ z (≽ means ≻ or ∼) ) Say apple ≻ banana, and banana ≻ orange, then apple ≻ orange Game Theory and Rational Choice Strategic-form Games Nash Equilibrium Examples (Non-)Strict Nash Equilibrium Rational Choice and Preference Relations • Game theory studies rational players’ behavior when they engage in strategic interactions. • Preferences (偏好) are rational if they satisfy . Completeness (完备性): between any x and y in a set, x ≻ y (x is preferred to y), y ≻ x, or x ∼ y (indifferent) . Transitivity(传递性): x ≽ y and y ≽ z )x ≽ z (≽ means ≻ or ∼) ) Say apple ≻ banana, and banana ≻ orange, then apple ≻ orange Game Theory and Rational Choice Strategic-form Games Nash Equilibrium Examples (Non-)Strict Nash Equilibrium Rational Choice and Preference Relations • Game theory studies rational players’ behavior when they engage in strategic interactions. • Rational choice: the action chosen by a decision maker is better or at least as good as every other available action, according to her preferences and given her constraints (e.g., resources, information, etc.).