Using Data Science to Predict Booking Cancellations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

25 Little Known Ways to Get Paid to Speak.Pages
25 Ways You can get Paid to Speak ! Contents Chasing Keynotes 1 More Income Streams is Better 1 Why Speaking for Free is a Smart Strategy 2 Who Hires You? 2 How to Get Hired 3 Become an Authority 3 25 Ways You Can Get Paid to Speak 5 1. Industry associations 5 2. Corporate event 5 3. In-house training 5 4. Conference workshop 6 5. Emcee at conferences 6 6. Service clubs 6 7. Lunch and learn 7 8. Business networking groups 7 9. Special interest groups 7 10. Webinar for client 7 11. On-line course 8 12. Speaker bureaus 8 13. Education institutions 8 14. Facilitation 9 15. Platform speech 9 16. Toastmasters International 9 17. Seminar companies 9 18. Live on-line seminar 10 19. Showcase event 10 20. Public seminars 10 21. Host your own conference 10 22. Membership program 11 23. Video on demand 11 24. On-line course 11 25. Cruise ships 11 Getting Started 12 25 Ways You can get Paid to Speak ! Getting paid to speak is an exciting way to share your ideas and inspiration and get paid. When most people think of “speaking” they think of main stage keynote speaking. While keynote speaking typically commands the highest fees, there are more opportunities than you might think. In this article I’ve listed 25 ways to get in front of an audience. Some are easy (like speaking to your local community organization), some require more planning. Some of these opportunities are paid and with others you earn your money in other ways or use one engagement to build referrals. -

Module 1: How to Find Speaking Opportunities (The Secret Is They Are EVERYWHERE!)
How to Make $100,000+ 1 as a Professional Speaker How to Make 100,000+ as a Professional Speaker With Rob Pennington, Ph.D., educational psychologist and award-winning speaker, trainer, coach and author Module 1: How to Find Speaking Opportunities (The Secret is they are EVERYWHERE!) “There’s an audience out there right now who is hoping to find someone with your exact message, delivered in the way that only you can deliver it. Every moment you put it off is a missed opportunity to help someone find a solution they need to make life better.” Brian T. Edmondson, author and coach Internet Marketing Made Easy “The more often you speak, the more often people will pay you. It helps if you can make it easy for them to remember you the next time they are looking for a speaker.” Dr. Rob Pennington SESSIONS: Module 1: How to Find Speaking Opportunities Module 2: How to Land Speaking Engagements & Get Multiple Gigs From One Client. Module 3: How to Ask for Your Fee & Get Paid Really Well Along the way we will also cover ways to use speaking to market your services, create products, generate publicity, expand your platform and create more paid speaking. And remember – a free coaching session for anyone who completes all three sessions. ©2013RESOURCE INTERNATIONAL 713-305-5117 GetPaidMoreToSpeak.com How to Make $100,000+ 2 as a Professional Speaker FOR THOSE JUST BEGINNING…. If you are in the process of getting your presentation and/or pf together, then let me encourage you to find a local professional speaker who can coach you to make your progress easier and quicker. -

Online Research Tools
Online Research Tools A White Paper Alphabetical URL DataSet Link Compilation By Marcus P. Zillman, M.S., A.M.H.A. Executive Director – Virtual Private Library [email protected] Online Research Tools is a white paper link compilation of various online tools that will aid your research and searching of the Internet. These tools come in all types and descriptions and many are web applications without the need to download software to your computer. This white paper link compilation is constantly updated and is available online in the Research Tools section of the Virtual Private Library’s Subject Tracer™ Information Blog: http://www.ResearchResources.info/ If you know of other online research tools both free and fee based feel free to contact me so I may place them in this ongoing work as the goal is to make research and searching more efficient and productive both for the professional as well as the lay person. Figure 1: Research Resources – Online Research Tools 1 Online Research Tools – A White Paper Alpabetical URL DataSet Link Compilation [Updated: August 26, 2013] http://www.OnlineResearchTools.info/ [email protected] eVoice: 800-858-1462 © 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013 Marcus P. Zillman, M.S., A.M.H.A. Online Research Tools: 12VPN - Unblock Websites and Improve Privacy http://12vpn.com/ 123Do – Simple Task Queues To Help Your Work Flow http://iqdo.com/ 15Five - Know the Pulse of Your Company http://www.15five.com/ 1000 Genomes - A Deep Catalog of Human Genetic Variation http://www.1000genomes.org/ -
Transcript for #Ls11 Tuesday.Pdf
Transcript for #ls11 - What the Hashtag?! http://wthashtag.com/transcript.php?page_id=24187&start_date=2011-02... wthashtag.com/ls11 Transcript from February 1, 2011 to February 1, 2011 All times are Pacific Time February 1, 2011 12:01 bbbozzz: @rawn Re: "... build your own custom geolocation app in seconds w/ an iPhone" < Would am love more info if you get a chance... Enjoy #ls11! 12:01 stuartmcintyre: No news on Quickr at all today - maybe it will come in the Social KeyNote tomorrow. Lots of am QuickrJ customers worried.. #ls11 12:02 stuartmcintyre: Was some news on the connectors in the OGS today - mainly Files in Notes, but only on am Windows. Where are Mac and Linux connectors? #ls11 12:03 stuartmcintyre: Again on the positive, Connections Next is due this year and looks great - some really good am new initiatives in there. #ls11 12:04 stuartmcintyre: Also, LotusLive Symphony is due later this year - collaborative editing in the cloud. Needs to am go beyond Google Apps functionality #ls11 12:07 WiseCraig: Shhhhh don't tell anyone, but it seems the rest of the world doesn't stop while #LS11 is am going on. #sorryCan'tHearYouMustBeABadConnection 12:07 lekkim: Amazing!! I actually have cell coverage in the showcase this year #ls11 am 12:08 Greyhawk68: @StuartMcIntyre and much of the Vulcan work is showing up in the 'Next' products. #ls11 am 12:08 dubbedpachi: ??????????????????????? RT ?@yumaki: ???????????????????????????? RT am @stger_01: Lotusphere 2011 12:08 luc_betbeder: What lotus product should I install to keep my Sys admins from having a social life? am Apparently domino is bullet proof now :) #ls11 12:10 elsua: RT @elsua: Gathering now #blueiq ambassadors to go out for dinner.. -

2015 PCA Conference Final Program
Pennsylvania Communication Association 76th Annual Convention Translating our Communication Research into Practice October 9-10, 2015 Penn State University, York Campus 1031 Edgecomb Avenue York, PA 17403 PCA History The Pennsylvania Communication Association, originally called the Speech Communication Association of Pennsylvania, was founded in 1939 to promote teaching, research, service, and development of all areas of human communication. John Henry Frizzell of Pennsylvania State University was the first President. The state journal, Annual, is now in its 75th year. For more than 22 years, we have recognized important Pennsylvanians such as Fred Rogers (Mister Rogers), Governor William Scranton, Governor Edward G. Rendell, Lieutenant Governor Mark Schweiker, Dr. Sam Hazo (Poet Laureate of Pennsylvania), and others as outstanding speakers of the year. The Association recognizes its own members for their contributions to the field, as well as students and the many educational institutions in the state of Pennsylvania and beyond for their efforts in communication. Dear Colleagues, Welcome to historic York, Pennsylvania, to Penn State University’s York campus. This year, we begin with a pre-conference planned by Dr. Isaac Catt and Dr. Deborah Eicher-Catt. The theme of this year’s pre-conference is “Patterns of Connection: Gregory Bateson, American Pragmatism and European Philosophy.” The keynote speakers are Dr. Klaus Krippendorff, Annenberg School for Communication, University of Pennsylvania and Dr. Vincent Colapietro, Pennsylvania State University. The theme for this year’s annual conference is “Translating our Communication Research into Practice.” The Interest Council Chairs have accepted papers, panels, and posters that represent the diversity of our discipline. We are also excited to have Dr. -

United States Securities and Exchange Commission Form
UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 ____________________________________________________________________________ FORM 10-K ____________________________________________________________________________ ☒ ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the fiscal year ended December 31, 2018 or ☐ TRANSITION REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 Commission File Number: 001-38658 _______________________________________________________________________________ EVENTBRITE, INC. (Exact name of registrant as specified in its charter) ________________________________________________________________________________ Delaware 14-1888467 (State or other jurisdiction of (I.R.S. Employer incorporation or organization) Identification Number) 155 5th Street, 7th Floor San Francisco, CA 94103 (415) 692-7779 (Address, including zip code and telephone number, including area code, of Registrant’s principal executive offices) Securities registered pursuant to Section 12(b) of the Act: Title of Each Class Name of exchange on which registered Class A Common Stock, $0.00001 par value per share New York Stock Exchange ____________________________________________________________________________________________________ Indicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act. ☐ Yes ☒ No Indicate by check mark if the registrant is not required to file reports pursuant to Section 13 or 15(d) of the Act. ☐ Yes ☒ No Indicate by check mark whether the registrant (1) has filed all reports required to be filed by Section 13 or 15(d) of the Securities Exchange Act of 1934 during the preceding 12 months (or for such shorter period that the registrant was required to file such reports), and (2) has been subject to such filing requirements for the past 90 days. -

September 17, 2019 High School Library AGENDA I
“Excellence in Education, Service, Life” West Plains Schools Board of Education Regular Session Meeting 5:05 P.M. September 17, 2019 High School Library AGENDA I. CALL TO ORDER II. ROLL CALL III. OPEN SESSION – for a motion to go into closed session IV. CLOSED (EXECUTIVE) SESSION A. Adjournment to Closed Executive Session 1. Pursuant to Section 610.021.1 Legal Matters 2. Pursuant to Section 610.021.3 Personnel Matters 3. Pursuant to Section 610.021.6 Student Matters B. Adjournment from Closed Executive Session V. CALL TO ORDER – The regular Session of the School Board meeting will be called to order at 5:45 P.M. VI. PLEDGE OF ALLEGIANCE VII. ROLL CALL AND ESTABLISHMENT OF QUORUM VIII. DISTRICT SPOTLIGHT – IX. APPROVAL OF AGENDA X. CONSENT AGENDA - Items considered routine in nature to be voted on in one motion to conserve time. If discussion is desired, that item will be removed from the Consent Agenda and will become the first item under the Regular Agenda A. Approval of Minutes from August 20, 2019 Board Meeting B. Summer School Program Review C. OMC Contract D. Payment of Bills E. Monthly Finance Report F. Approval Request for resignations G. Approval will be requested for the employment of individuals as recommended by the Superintendent of Schools: Paraprofessionals, Teacher, Sub Teacher List, Sub Driver List XI. REGULAR AGENDA A. Previous Business for Approval, Discussion or Information Only 1. Academic Update 2. MSBA Fall Conference, Sept 26 – Sept 29, 2019 3. MSBA Board Member Refresher Course B. New Business for Approval, Discussion or Information Only 1. -

The Future Is
The Digital Magazine of the Maryland Library Association Volume 47, Number 3 • Spring, 2017 The Future is Now Carroll County Public Library Virtual Reality Roadshow page 17 And… MLA Election Results 6 MLA DLA Conference Preview 7 World War I in Your Attic: Far from Your Dry History Lesson 19 Volume 47, Number 2 • Winter, 2017 feature articles ALA Midwinter Update 15 this collaborative program involved community and library staff as they shared ALA Midwinter was held January 20-24, 2017 amid a whirlwind of information about the war. activity in Atlanta (including real tornados, the women’s march, a marathon and the NFL playoffs for the home team Falcons). Action African American Read-In at Harford Community College Library 22 was also taking place on the floor of the ALA Council. On February 28, 2017, as part of its Black History Month celebrations, the Harford Community College (HCC) Library in Bel Air hosted its second annual The Future is Now: The Carroll County Public Library African American Read-In (AARI), a national event sponsored by the National Virtual Reality Roadshow 17 Council of Teachers of English (NCTE) and by the Black Caucus of NCTE. Libraries are taking the lead to provide access and a guided introduction to emerging technologies that are increasingly and Solar Eclipse Provides Coronal Glimpse 24 rapidly changing the way we learn, play, and work. In that vein, the On August 21, 2017, North Americans will enjoy a rare treat: The first total Carroll County Public Library recently wrapped up its Virtual Reality solar eclipse visible from the continent since 1979. -

Lunch & Learn Your Way to Knowledge!
Lunch & learn your way to knowledge! Apps & more TCSG Paid Resources http://www.gvtc.org/gvtctraining • Blackboard Collaborate – meetings, workshops, and more SoftChalk – create interactive lessons, lectures, and videos including quizzes and assessments • Respondus – create quizzes and tests • StudyMate – create interactive quizzes, crosswords, flash cards, and more FREE (Mostly!) Resources Communication Tools • GMAIL (other email providers, too!) – http://www.gmail.com • GoQRme – online tool to create QR Codes - http://Goqr.me • LinkedIN – discussion groups, networking, messaging, etc. – https://www.linkedin.com/ • Remind – text students and parents - mobile app - https://www.remind.com • What’s App – message anyone https://www.whatsapp.com/ • (Social media can also be a communication tool – most have messaging) Quizzes/Activities • Plickers – collect real-time feedback without the need of student devices (tools uses mobile) - https://www.plickers.com/ • PollAnywhere – collect real-time feedback using mobile phones, twitter, and the web – mobile - http://www.polleverywhere.com/ • Socrative – create educational activities for students - online and apps -http://www.socrative.com/ Video conferencing • Free Conference calls: https://www.freeconferencecall.com/ • Google Hangouts: https://hangouts.google.com/ • Skype: http://www.skype.com/en/download-skype/skype-for-mobile/ • Blackboard Collaborate (licensed) Social media • Facebook - Community, photo galleries, groups (private and public) messaging & more – http://www.facebook.com • Blogging -

Topical Community Detection in Event-Based Social Network
Topical Community Detection in Event-based Social Network Houda Khrouf Raphaël Troncy Atos Eurecom Bezons, France Biot, France [email protected] [email protected] ABSTRACT 1. INTRODUCTION Event-based services have recently witnessed a rapid growth Events are a natural way for referring to any observable driving the way people explore and share information of in- occurrence grouping persons, places, times and activities terest. They host a huge amount of users' activities includ- that can be described and documented through different me- ing explicit RSVP, shared photos, comments and social con- dia [20]. Today's event landscape is increasingly crowded nections. Exploiting these activities to detect communities with new websites including event directories, social net- of similar users is a challenging problem. In reality, a com- works and media platforms. People have been recently at- munity in event-based social network (ESBN) is a group of tracted by these services to organize and distribute their per- users not only sharing common events and friends, but also sonal data according to occurring events, to share captured having similar topical interests. However, such community media and to create new social connections. Websites such could not be detected by most of existing methods which as Eventful1, Lanyrd2, Last.fm3, Flickr and Twitter host mainly draw on link analysis in the network. To address an ever increasing amount of event-centric knowledge main- this problem, there is a need to capitalize on the seman- tained by rich social interactions. In particular, the event- tics of shared objects along with the structural properties, based social network (ESBN) is different from the traditional and to generate overlapping communities rather than dis- social network due to the coexistence of two kinds of social joint ones. -
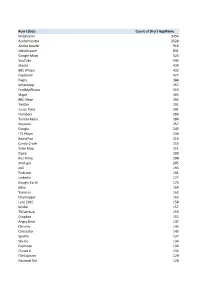
Row Labels Count of Short Appname Mobileiron 3454 Authenticator 2528
Row Labels Count of Short AppName MobileIron 3454 Authenticator 2528 Adobe Reader 916 vWorkspace 831 Google Maps 624 YouTube 543 iBooks 434 BBC iPlayer 432 Facebook 427 Pages 388 WhatsApp 357 FindMyiPhone 313 Skype 303 BBC News 292 Twitter 291 Junos Pulse 291 Numbers 289 TuneIn Radio 284 Keynote 257 Google 243 ITV Player 234 BoardPad 219 Candy Crush 215 Tube Map 211 Zipcar 209 Bus Times 208 mod.gov 205 4oD 193 Podcasts 191 LinkedIn 177 Google Earth 172 eBay 164 Yammer 163 Citymapper 163 Lync 2010 158 Kindle 157 TVCatchup 153 Dropbox 152 Angry Birds 147 Chrome 143 Calculator 143 Spotify 137 Sky Go 136 Evernote 134 iTunes U 132 FileExplorer 129 National Rail 128 iPlayer Radio 127 FasterScan 125 BBC Weather 125 FasterScan HD 124 Gmail 123 Instagram 116 Cleaner Brent 107 Viber 104 Find Friends 98 PDF Expert 95 Solitaire 91 SlideShark 89 Netflix 89 Dictation 89 com.amazon.AmazonUK 88 Flashlight 81 iMovie 79 Temple Run 2 77 Smart Office 2 74 Dictionary 72 UK & ROI 71 Journey Pro 71 iPhoto 70 TripAdvisor 68 Guardian iPad edition 68 Shazam 67 Messenger 65 Bible 64 BBC Sport 63 Rightmove 62 London 62 Sky Sports 61 Subway Surf 60 Temple Run 60 Yahoo Mail 58 thetrainline 58 Minion Rush 58 Demand 5 57 Documents 55 Argos 55 LBC 54 Sky+ 51 MailOnline 51 GarageBand 51 Calc 51 TV Guide 49 Phone Edition 49 Translate 48 Print Portal 48 Standard 48 Word 47 Skitch 47 CloudOn 47 Tablet Edition 46 MyFitnessPal 46 Bus London 46 Snapchat 45 Drive 42 4 Pics 1 Word 41 TED 39 Skyscanner 39 SoundCloud 39 PowerPoint 39 Zoopla 38 Flow Free 38 Excel 38 Radioplayer -

Thanks for Downloading Our Big List of Marketing Tools for Event Organisers!
Thanks for downloading our big list of marketing tools for event organisers! 1. AllTop http://alltop.com/ A simple way to find relevant and popular blogs in your niche to follow (and contribute to) Category: Content Distribution Cost: Free 2. AppsGeyser http://www.appsgeyser.com/ AppsGeyser is an DIY online platform for creating your own Android app with no technical knowledge. Plug in your existing content, website or blog and create an instant app for your attendees to keep up to date with your event. Appsgeyser includes messaging, social sharing, tabs and full support for HTML5 and is ideal for the non- techie organiser that wants to access a mobile audience fast. Category: Mobile Content Cost: Free with premium options 3. Aweber http://www.aweber.com/ Events are an excellent way to grow your marketing base. AWeber's email marketing platform makes it easy to sync Eventbrite attendees to email list of your choice. Category: Email Cost: $19 per month 4. Batchbook http://batchbook.com/integrations/eventbrite.html Batchbook is the web’s most social CRM for small businesses, and can help Eventbrite organisers build meaningful relationships with their best attendees and customers. Category: Social * CRM Cost: $55 per month 5. Blog Ads http://web.blogads.com/ Blog Ads offers access to its audience of influential bloggers through advertising banners, native advertising and blog ads on relevant high profile blogs in your vertical. Blog ads runs on a CPM (cost per thousand ad impressions) basis and you can niche down to specific publishers that have the right readers that could be potential attendees for your event.