Intel Haswell Architecture/Microarchitecture, Operational Intensity
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 in the United States District Court
Case 6:20-cv-00779 Document 1 Filed 08/25/20 Page 1 of 33 IN THE UNITED STATES DISTRICT COURT WESTERN DISTRICT OF TEXAS AUSTIN DIVISION AURIGA INNOVATIONS, INC. C.A. No. 6:20-cv-779 Plaintiff, v. JURY TRIAL DEMANDED INTEL CORPORATION, HP INC., and HEWLETT PACKARD ENTERPRISE COMPANY, Defendants COMPLAINT Plaintiff Auriga Innovations, Inc. (“Auriga” or “Plaintiff”) files this complaint for patent infringeMent against Defendants Intel Corporation (“Intel”), HP Inc. (“HPI”), and Hewlett Packard Enterprise Company (“HPE”) (collectively, “Defendants”) under 35 U.S.C. § 217 et seq. as a result of Defendants’ unauthorized use of Auriga’s patents and alleges as follows: THE PARTIES 1. Auriga is a corporation organized and existing under the laws of the state of Delaware with its principal place of business at 1891 Robertson Road, Suite 100, Ottawa, ON K2H 5B7 Canada. 2. On information and belief, Intel is a Delaware corporation with a place of business at 2200 Mission College Boulevard, Santa Clara, California 95054. 3. On information and belief, since April 1989, Intel has been registered to do business in the State of Texas under Texas Taxpayer Number 19416727436 and has places of business at 1 Case 6:20-cv-00779 Document 1 Filed 08/25/20 Page 2 of 33 1300 S Mopac Expressway, Austin, Texas 78746; 6500 River Place Blvd, Bldg 7, Austin, Texas 78730; and 5113 Southwest Parkway, Austin, Texas 78735 (collectively, “Intel Austin Offices”). https://www.intel.com/content/www/us/en/location/usa.htMl. 4. On information and belief, HPI is a Delaware corporation with a principal place of business at 1501 Page Mill Road, Palo Alto, CA 94304. -

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

Single Board Computer
Single Board Computer SBC with the Intel® 8th generation Core™/Xeon® (formerly Coffee Lake H) SBC-C66 and 9th generation Core™ / Xeon® / Pentium® / Celeron® (formerly Coffee Lake Refresh) CPUs High-performing, flexible solution for intelligence at the edge HIGHLIGHTS CONNECTIVITY CPU 2x USB 3.1; 4x USB 2.0; NVMe SSD Slot; PCI-e x8 Intel® 8th gen. Core™ / Xeon® and 9th gen. Core™ / port (PCI-e x16 mechanical slot); VPU High Speed Xeon® / Pentium® / Celeron® CPUs Connector with 4xUSB3.1 + 2x PCI-ex4 GRAPHICS MEMORY Intel® UHD Graphics 630/P630 architecture, up to 128GB DDR4 memory on 4x SO-DIMM Slots supports up to 3 independent displays (ECC supported) Available in Industrial Temperature Range MAIN FIELDS OF APPLICATION Biomedical/ Gaming Industrial Industrial Surveillance Medical devices Automation and Internet of Control Things FEATURES ® ™ ® Intel 8th generation Core /Xeon (formerly Coffee Lake H) CPUs: Max Cores 6 • Intel® Core™ i7-8850H, Six Core @ 2.6GHz (4.3GHz Max 1 Core Turbo), 9MB Cache, 45W TDP (35W cTDP), with Max Thread 12 HyperThreading • Intel® Core™ i5-8400H, Quad Core @ 2.5GHz (4.2GHz Intel® QM370, HM370 or CM246 Platform Controller Hub Chipset Max 1 Core Turbo), 8MB Cache, 45W TDP (35W cTDP), (PCH) with HyperThreading • Intel® Core™ i3-8100H, Quad Core @ 3.0GHz, 6MB 2x DDR4-2666 or 4x DDR4-2444 ECC SODIMM Slots, up to 128GB total (only with 4 SODIMM modules). Cache, 45W TDP (35W cTDP) Memory ® ™ ® ® ECC DDR4 memory modules supported only with Xeon Core Information subject to change. Please visit www.seco.com to find the latest version of this datasheet Information subject to change. -

Attacking X86 Processor Integrity from Software
V0LTpwn: Attacking x86 Processor Integrity from Software Zijo Kenjar and Tommaso Frassetto, Technische Universität Darmstadt; David Gens and Michael Franz, University of California, Irvine; Ahmad-Reza Sadeghi, Technische Universität Darmstadt https://www.usenix.org/conference/usenixsecurity20/presentation/kenjar This paper is included in the Proceedings of the 29th USENIX Security Symposium. August 12–14, 2020 978-1-939133-17-5 Open access to the Proceedings of the 29th USENIX Security Symposium is sponsored by USENIX. V0LTpwn: Attacking x86 Processor Integrity from Software Zijo Kenjar1, Tommaso Frassetto1, David Gens2, Michael Franz2, and Ahmad-Reza Sadeghi1 1Technical University of Darmstadt, Germany {zijo.kenjar,tommaso.frassetto,ahmad.sadeghi}@trust.tu-darmstadt.de 2University of California, Irvine {dgens,franz}@uci.edu Abstract complex, and far from flawless. In the recent past, we Fault-injection attacks have been proven in the past to have seen how seemingly minor implementation bugs at be a reliable way of bypassing hardware-based security the hardware level can have a severe impact on secu- measures, such as cryptographic hashes, privilege and rity [14]. Attacks such as Meltdown [36], Spectre [33], access permission enforcement, and trusted execution Foreshadow [58], and RIDL [62] demonstrate that at- environments. However, traditional fault-injection at- tackers can exploit these bugs from software to bypass tacks require physical presence, and hence, were often access permissions and extract secret data. considered out of scope in many real-world adversary Furthermore, we have seen that the adverse effects settings. of hardware vulnerabilities are not limited to confiden- In this paper we show this assumption may no longer tiality, but can also compromise integrity in principle: be justified on x86. -

Class-Action Lawsuit
Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 1 of 279 Steve D. Larson, OSB No. 863540 Email: [email protected] Jennifer S. Wagner, OSB No. 024470 Email: [email protected] STOLL STOLL BERNE LOKTING & SHLACHTER P.C. 209 SW Oak Street, Suite 500 Portland, Oregon 97204 Telephone: (503) 227-1600 Attorneys for Plaintiffs [Additional Counsel Listed on Signature Page.] UNITED STATES DISTRICT COURT DISTRICT OF OREGON PORTLAND DIVISION BLUE PEAK HOSTING, LLC, PAMELA Case No. GREEN, TITI RICAFORT, MARGARITE SIMPSON, and MICHAEL NELSON, on behalf of CLASS ACTION ALLEGATION themselves and all others similarly situated, COMPLAINT Plaintiffs, DEMAND FOR JURY TRIAL v. INTEL CORPORATION, a Delaware corporation, Defendant. CLASS ACTION ALLEGATION COMPLAINT Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 2 of 279 Plaintiffs Blue Peak Hosting, LLC, Pamela Green, Titi Ricafort, Margarite Sampson, and Michael Nelson, individually and on behalf of the members of the Class defined below, allege the following against Defendant Intel Corporation (“Intel” or “the Company”), based upon personal knowledge with respect to themselves and on information and belief derived from, among other things, the investigation of counsel and review of public documents as to all other matters. INTRODUCTION 1. Despite Intel’s intentional concealment of specific design choices that it long knew rendered its central processing units (“CPUs” or “processors”) unsecure, it was only in January 2018 that it was first revealed to the public that Intel’s CPUs have significant security vulnerabilities that gave unauthorized program instructions access to protected data. 2. A CPU is the “brain” in every computer and mobile device and processes all of the essential applications, including the handling of confidential information such as passwords and encryption keys. -

Broadwell Skylake Next Gen* NEW Intel NEW Intel NEW Intel Microarchitecture Microarchitecture Microarchitecture
15 лет доступности IOTG is extending the product availability for IOTG roadmap products from a minimum of 7 years to a minimum of 15 years when both processor and chipset are on 22nm and newer process technologies. - Xeon Scalable (w/ chipsets) - E3-12xx/15xx v5 and later (w/ chipsets) - 6th gen Core and later (w/ chipsets) - Bay Trail (E3800) and later products (Braswell, N3xxx) - Atom C2xxx (Rangeley) and later - Не включает в себя Xeon-D (7 лет) и E5-26xx v4 (7 лет) 2 IOTG Product Availability Life-Cycle 15 year product availability will start with the following products: Product Discontinuance • Intel® Xeon® Processor Scalable Family codenamed Skylake-SP and later with associated chipsets Notification (PDN)† • Intel® Xeon® E3-12xx/15xx v5 series (Skylake) and later with associated chipsets • 6th Gen Intel® Core™ processor family (Skylake) and later (includes Intel® Pentium® and Celeron® processors) with PDNs will typically be issued no later associated chipsets than 13.5 years after component • Intel Pentium processor N3700 (Braswell) and later and Intel Celeron processors N3xxx (Braswell) and J1900/N2xxx family introduction date. PDNs are (Bay Trail) and later published at https://qdms.intel.com/ • Intel® Atom® processor C2xxx (Rangeley) and E3800 family (Bay Trail) and late Last 7 year product availability Time Last Last Order Ship Last 15 year product availability Time Last Last Order Ship L-1 L L+1 L+2 L+3 L+4 L+5 L+6 L+7 L+8 L+9 L+10 L+11 L+12 L+13 L+14 L+15 Years Introduction of component family † Intel may support this extended manufacturing using reasonably Last Time Order/Ship Periods Component family introduction dates are feasible means deemed by Intel to be appropriate. -

SIMD Vectorization
How to Write Fast Numerical Code Spring 2015 Lecture: SIMD extensions, SSE, compiler vectorization Instructor: Markus Püschel TA: Gagandeep Singh, Daniele Spampinato, Alen Stojanov Planning Currently: work on project (submit update 2.4.) No class on Sechseläuten (13.4.) Exam 15.4. First one-on-one meetings: late April 2 © Markus Püschel How to write fast numerical code Computer Science Spring 2015 Flynn’s Taxonomy Single instruction Multiple instruction Single data SISD MISD Uniprocessor Multiple data SIMD MIMD Vector computer Multiprocessors Short vector extensions VLIW 3 SIMD Extensions and SSE Overview: SSE family SSE intrinsics Compiler vectorization This lecture and material was created together with Franz Franchetti (ECE, Carnegie Mellon) 4 © Markus Püschel How to write fast numerical code Computer Science Spring 2015 SIMD Vector Extensions + x 4-way What is it? . Extension of the ISA . Data types and instructions for the parallel computation on short (length 2, 4, 8, …) vectors of integers or floats . Names: MMX, SSE, SSE2, … Why do they exist? . Useful: Many applications have the necessary fine-grain parallelism Then: speedup by a factor close to vector length . Doable: Relative easy to design; chip designers have enough transistors to play with 5 © Markus Püschel MMX: Computer Science Multimedia extension SSE: Intel x86 Processors Streaming SIMD extension x86-16 8086 AVX: Advanced vector extensions 286 x86-32 386 register 486 width Pentium MMX Pentium MMX 64 bit (only int) SSE Pentium III time SSE2 Pentium 4 SSE3 Pentium -

Intel® Core™ I7-8700K Processor (12M Cache, up to 4.70 Ghz) Code Name Coffee Lake Vertical Segment Desktop Processor Numb
ARK | Compare Intel® Products Intel® Core™ i7-8700K Processor (12M Cache, up to 4.70 GHz) Code Name Coffee Lake Essentials Vertical Segment Desktop Processor Number i7-8700K Status Launched Launch Date Q4'17 Lithography 14 nm Performance # of Cores 6 # of Threads 12 Processor Base Frequency 3.70 GHz Max Turbo Frequency 4.70 GHz Cache 12 MB Bus Speed 8 GT/s DMI3 TDP 95 W Supplemental Information Embedded Options Available No Conflict Free Yes Memory Specifications Max Memory Size (dependent on memory type) 64 GB Memory Types DDR4-2666 Max # of Memory Channels 2 ECC Memory Supported ‡ No Graphics Specifications Processor Graphics ‡ Intel® UHD Graphics 630 Graphics Base Frequency 350 MHz Graphics Max Dynamic Frequency 1.20 GHz Graphics Video Max Memory 64 GB Execution Units 24 4K Support Yes, at 60Hz Max Resoluon (HDMI 1.4)‡ 4096x2304@24Hz Max Resoluon (DP)‡ 4096x2304@60Hz Max Resoluon (eDP - Integrated Flat Panel)‡ 4096x2304@60Hz DirectX* Support 12 OpenGL* Support 4.5 Intel® Quick Sync Video Yes Intel® InTru™ 3D Technology Yes Intel® Clear Video HD Technology Yes Intel® Clear Video Technology Yes # of Displays Supported ‡ 3 Device ID 0x3E92 Expansion Options Scalability 1S Only PCI Express Revision 3.0 PCI Express Configuraons ‡ Up to 1x16 or 2x8 or 1x8+2x4 Max # of PCI Express Lanes 16 Package Specifications Sockets Supported FCLGA1151 Max CPU Configuration 1 Thermal Solution Specification PCG 2015C (130W) T<sub>JUNCTION</sub> 100°C Package Size 37.5mm x 37.5mm Low Halogen Options Available See MDDS Advanced Technologies Intel® Optane™ -

The Intel X86 Microarchitectures Map Version 2.0
The Intel x86 Microarchitectures Map Version 2.0 P6 (1995, 0.50 to 0.35 μm) 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P5 (1993, 0.80 to 0.35 μm) NetBurst (2000 , 180 to 130 nm) Skylake (2015, 14 nm) Alternative Names: i686 Series: Alternative Names: iAPX 386, 386, i386 Alternative Names: Pentium, 80586, 586, i586 Alternative Names: Pentium 4, Pentium IV, P4 Alternative Names: SKL (Desktop and Mobile), SKX (Server) Series: Pentium Pro (used in desktops and servers) • 16-bit data bus: 8086 (iAPX Series: Series: Series: Series: • Variant: Klamath (1997, 0.35 μm) 86) • Desktop/Server: i386DX Desktop/Server: P5, P54C • Desktop: Willamette (180 nm) • Desktop: Desktop 6th Generation Core i5 (Skylake-S and Skylake-H) • Alternative Names: Pentium II, PII • 8-bit data bus: 8088 (iAPX • Desktop lower-performance: i386SX Desktop/Server higher-performance: P54CQS, P54CS • Desktop higher-performance: Northwood Pentium 4 (130 nm), Northwood B Pentium 4 HT (130 nm), • Desktop higher-performance: Desktop 6th Generation Core i7 (Skylake-S and Skylake-H), Desktop 7th Generation Core i7 X (Skylake-X), • Series: Klamath (used in desktops) 88) • Mobile: i386SL, 80376, i386EX, Mobile: P54C, P54LM Northwood C Pentium 4 HT (130 nm), Gallatin (Pentium 4 Extreme Edition 130 nm) Desktop 7th Generation Core i9 X (Skylake-X), Desktop 9th Generation Core i7 X (Skylake-X), Desktop 9th Generation Core i9 X (Skylake-X) • Variant: Deschutes (1998, 0.25 to 0.18 μm) i386CXSA, i386SXSA, i386CXSB Compatibility: Pentium OverDrive • Desktop lower-performance: Willamette-128 -

Lenovo Yoga S730-13IWL DS
S730 WE MADE IT THIN. AND THEN, A LITTLE THINNER. Polished in premium aluminum and sleeker than ever, the Lenovo™ Yoga™ S730 is our thinnest Yoga notebook yet. At 11.9 mm, you could lose it in a stack of magazines—and we didn’t sacrifice a thing. Featuring the latest Intel® processing, FHD clarity and the immersive sound of the Dolby Atmos® Speaker System, the Yoga S730 offers a new standard for thin and stylish design. WHY YOU SHOULD BUY THE LENOVO YOGA S730 Ultra-thin, ultra-sleek Clear and bright The Yoga S730 is our Enjoy FHD clarity on a 13.3" thinnest Yoga notebook wide-angle display, edged yet, measuring a miniscule with razor-thin 3.62 mm left & 11.9 mm thin. Featuring a right bezels1. The Yoga S730 simplified chassis crafted will make the absolute most from sand-blasted premium of your entertainment—we aluminum, the Yoga S730 didn’t waste a millimeter. offers sophisticated style designed to last. 10 hours of battery Power and speed Keep moving for up to 10 hours, The latest generation of with the Yoga S730’s powerful Intel® Core™ i7 processing battery. And if you need an represents an enormous extra boost, an hour plugged-in increase in performance from will provide up to 80% previous generations, offering battery life2. up to a 40% improvement with 8th Generation Intel® Core™ i7. Whether you’re streaming content, running multiple programs or editing videos, the Yoga S730 is designed to multitask with ease3. 1 Not including rubber bumper. 2 Power-off mode; requires 65W power supply. -
Code Name Coffee Lake Essentials Vertical Segment Desktop Processor Number I5-8500T Status Launched Launch Date Q2'18 Lithog
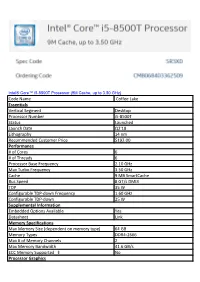
Intel® Core™ i5-8500T Processor (9M Cache, up to 3.50 GHz) Code Name Coffee Lake Essentials Vertical Segment Desktop Processor Number i5-8500T Status Launched Launch Date Q2'18 Lithography 14 nm Recommended Customer Price $192.00 Performance # of Cores 6 # of Threads 6 Processor Base Frequency 2.10 GHz Max Turbo Frequency 3.50 GHz Cache 9 MB SmartCache Bus Speed 8 GT/s DMI3 TDP 35 W Configurable TDP-down Frequency 1.60 GHz Configurable TDP-down 25 W Supplemental Information Embedded Options Available Yes Datasheet Link Memory Specifications Max Memory Size (dependent on memory type) 64 GB Memory Types DDR4-2666 Max # of Memory Channels 2 Max Memory Bandwidth 41.6 GB/s ECC Memory Supported ‡ No Processor Graphics Processor Graphics <sup><small>‡</small></sup> Intel® UHD Graphics 630 Graphics Base Frequency 350 MHz Graphics Max Dynamic Frequency 1.10 GHz Graphics Video Max Memory 64 GB 4K Support Yes, at 60Hz Max Resolution (HDMI 1.4)‡ 4096x2304@24Hz Max Resolution (DP)‡ 4096x2304@60Hz Max Resolution (eDP - Integrated Flat Panel)‡ 4096x2304@60Hz DirectX* Support 12 OpenGL* Support 4.5 Intel® Quick Sync Video Yes Intel® InTru™ 3D Technology Yes Intel® Clear Video HD Technology Yes Intel® Clear Video Technology Yes # of Displays Supported ‡ 3 Device ID 0x3E92 Expansion Options Scalability 1S Only PCI Express Revision 3 PCI Express Configurations ‡ Up to 1x16, 2x8, 1x8+2x4 Max # of PCI Express Lanes 16 Package Specifications Sockets Supported FCLGA1151 Max CPU Configuration 1 Thermal Solution Specification PCG 2015A (35W) T<sub>JUNCTION</sub> -

Comet Lake Platform Intel® Turbo Boost Max Technology 3.0
Technical Advisory WW14, April 2020 Document Number: 621487 Intel Confidential Legal Disclaimer You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com. Intel technologies may require enabled hardware, specific software, or services activation. Check with your system manufacturer or retailer. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest Intel product specifications and roadmaps Copies of documents which have an order number and are referenced in this document may be obtained by calling 1-800-548-4725 or visit www.intel.com/design/literature.htm.