Thesis Project Report
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Libressl Presentatie2
Birth of LibreSSL and its current status Frank Timmers Consutant, Snow B.V. Background What is LibreSSL • A fork of OpenSSL 1.0.1g • Being worked on extensively by a number of OpenBSD developers What is OpenSSL • OpenSSL is an open source SSL/TLS crypto library • Currently the de facto standard for many servers and clients • Used for securing http, smtp, imap and many others Alternatives • Netscape Security Services (NSS) • BoringSSL • GnuTLS What is Heartbleed • Heartbleed was a bug leaking of private data (keys) from both client and server • At this moment known as “the worst bug ever” • Heartbeat code for DTLS over UDP • So why was this also included in the TCP code? • Not the reason to create a fork Why did this happen • Nobody looked • Or at least didn’t admit they looked Why did nobody look • The code is horrible • Those who did look, quickly looked away and hoped upstream could deal with it Why was the code so horrible • Buggy re-implementations of standard libc functions like random() and malloc() • Forces all platforms to use these buggy implementations • Nested #ifdef, #ifndefs (up to 17 layers deep) through out the code • Written in “OpenSSL C”, basically their own dialect • Everything on by default Why was it so horrible? crypto_malloc • Never frees memory (Tools like Valgrind, Coverity can’t spot bugs) • Used LIFO recycling (Use after free?) • Included debug malloc by default, logging private data • Included the ability to replace malloc/free at runtime #ifdef trees • #ifdef, #elif, #else trees up to 17 layers deep • Throughout the complete source • Some of which could never be reached • Hard to see what is or not compiled in 1. -

Not-Quite-So-Broken TLS Lessons in Re-Engineering a Security Protocol Specification and Implementation
Not-quite-so-broken TLS Lessons in re-engineering a security protocol specification and implementation David Kaloper Meršinjak Hannes Mehnert Peter Sewell Anil Madhavapeddy University of Cambridge, Computer Labs Usenix Security, Washington DC, 12 August 2015 INT SSL23_GET_CLIENT_HELLO(SSL *S) { CHAR BUF_SPACE[11]; /* REQUEST THIS MANY BYTES IN INITIAL READ. * WE CAN DETECT SSL 3.0/TLS 1.0 CLIENT HELLOS * ('TYPE == 3') CORRECTLY ONLY WHEN THE FOLLOWING * IS IN A SINGLE RECORD, WHICH IS NOT GUARANTEED BY * THE PROTOCOL SPECIFICATION: * BYTE CONTENT * 0 TYPE \ * 1/2 VERSION > RECORD HEADER * 3/4 LENGTH / * 5 MSG_TYPE \ * 6-8 LENGTH > CLIENT HELLO MESSAGE Common CVE sources in 2014 Class # Memory safety 15 State-machine errors 10 Certificate validation 5 ASN.1 parsing 3 (OpenSSL, GnuTLS, SecureTransport, Secure Channel, NSS, JSSE) Root causes Error-prone languages Lack of separation Ambiguous and untestable specification nqsb approach Choice of language and idioms Separation and modular structure A precise and testable specification of TLS Reuse between specification and implementation Choice of language and idioms OCaml: a memory-safe language with expressive static type system Well contained side-effects Explicit flows of data Value-based Explicit error handling We leverage it for abstraction and automated resource management. Formal approaches Either reason about a simplified model of the protocol; or reason about small parts of OpenSSL. In contrast, we are engineering a deployable implementation. nqsb-tls A TLS stack, developed from scratch, with dual goals: Executable specification Usable TLS implementation Structure nqsb-TLS ML module layout Core Is purely functional: VAL HANDLE_TLS : STATE -> BUFFER -> [ `OK OF STATE * BUFFER OPTION * BUFFER OPTION | `FAIL OF FAILURE ] Core OCaml helps to enforce state-machine invariants. -
![Arxiv:1911.09312V2 [Cs.CR] 12 Dec 2019](https://docslib.b-cdn.net/cover/5245/arxiv-1911-09312v2-cs-cr-12-dec-2019-485245.webp)
Arxiv:1911.09312V2 [Cs.CR] 12 Dec 2019
Revisiting and Evaluating Software Side-channel Vulnerabilities and Countermeasures in Cryptographic Applications Tianwei Zhang Jun Jiang Yinqian Zhang Nanyang Technological University Two Sigma Investments, LP The Ohio State University [email protected] [email protected] [email protected] Abstract—We systematize software side-channel attacks with three questions: (1) What are the common and distinct a focus on vulnerabilities and countermeasures in the cryp- features of various vulnerabilities? (2) What are common tographic implementations. Particularly, we survey past re- mitigation strategies? (3) What is the status quo of cryp- search literature to categorize vulnerable implementations, tographic applications regarding side-channel vulnerabili- and identify common strategies to eliminate them. We then ties? Past work only surveyed attack techniques and media evaluate popular libraries and applications, quantitatively [20–31], without offering unified summaries for software measuring and comparing the vulnerability severity, re- vulnerabilities and countermeasures that are more useful. sponse time and coverage. Based on these characterizations This paper provides a comprehensive characterization and evaluations, we offer some insights for side-channel of side-channel vulnerabilities and countermeasures, as researchers, cryptographic software developers and users. well as evaluations of cryptographic applications related We hope our study can inspire the side-channel research to side-channel attacks. We present this study in three di- community to discover new vulnerabilities, and more im- rections. (1) Systematization of literature: we characterize portantly, to fortify applications against them. the vulnerabilities from past work with regard to the im- plementations; for each vulnerability, we describe the root cause and the technique required to launch a successful 1. -

Crypto Projects That Might Not Suck
Crypto Projects that Might not Suck Steve Weis PrivateCore ! http://bit.ly/CryptoMightNotSuck #CryptoMightNotSuck Today’s Talk ! • Goal was to learn about new projects and who is working on them. ! • Projects marked with ☢ are experimental or are relatively new. ! • Tried to cite project owners or main contributors; sorry for omissions. ! Methodology • Unscientific survey of projects from Twitter and mailing lists ! • Excluded closed source projects & crypto currencies ! • Stats: • 1300 pageviews on submission form • 110 total nominations • 89 unique nominations • 32 mentioned today The People’s Choice • Open Whisper Systems: https://whispersystems.org/ • Moxie Marlinspike (@moxie) & open source community • Acquired by Twitter 2011 ! • TextSecure: Encrypt your texts and chat messages for Android • OTP-like forward security & Axolotl key racheting by @trevp__ • https://github.com/whispersystems/textsecure/ • RedPhone: Secure calling app for Android • ZRTP for key agreement, SRTP for call encryption • https://github.com/whispersystems/redphone/ Honorable Mention • ☢ Networking and Crypto Library (NaCl): http://nacl.cr.yp.to/ • Easy to use, high speed XSalsa20, Poly1305, Curve25519, etc • No dynamic memory allocation or data-dependent branches • DJ Bernstein (@hashbreaker), Tanja Lange (@hyperelliptic), Peter Schwabe (@cryptojedi) ! • ☢ libsodium: https://github.com/jedisct1/libsodium • Portable, cross-compatible NaCL • OpenDNS & Frank Denis (@jedisct1) The Old Standbys • Gnu Privacy Guard (GPG): https://www.gnupg.org/ • OpenSSH: http://www.openssh.com/ -

Post-Quantum Authentication in Openssl with Hash-Based Signatures
Recalling Hash-Based Signatures Motivations for Cryptographic Library Integration Cryptographic Libraries OpenSSL & open-quantum-safe XMSS Certificate Signing in OpenSSL / open-quantum-safe Conclusions Post-Quantum Authentication in OpenSSL with Hash-Based Signatures Denis Butin, Julian Wälde, and Johannes Buchmann TU Darmstadt, Germany 1 / 26 I Quantum computers are not available yet, but deployment of new crypto takes time, so transition must start now I Well established post-quantum signature schemes: hash-based cryptography (XMSS and variants) I Our goal: make post-quantum signatures available in a popular security software library: OpenSSL Recalling Hash-Based Signatures Motivations for Cryptographic Library Integration Cryptographic Libraries OpenSSL & open-quantum-safe XMSS Certificate Signing in OpenSSL / open-quantum-safe Conclusions Overall Motivation I Networking requires authentication; authentication is realized by cryptographic signature schemes I Shor’s algorithm (1994): most public-key cryptography (RSA, DSA, ECDSA) breaks once large quantum computers exist I Post-quantum cryptography: public-key algorithms thought to be secure against quantum computer attacks 2 / 26 Recalling Hash-Based Signatures Motivations for Cryptographic Library Integration Cryptographic Libraries OpenSSL & open-quantum-safe XMSS Certificate Signing in OpenSSL / open-quantum-safe Conclusions Overall Motivation I Networking requires authentication; authentication is realized by cryptographic signature schemes I Shor’s algorithm (1994): most public-key -

Black-Box Security Analysis of State Machine Implementations Joeri De Ruiter
Black-box security analysis of state machine implementations Joeri de Ruiter 18-03-2019 Agenda 1. Why are state machines interesting? 2. How do we know that the state machine is implemented correctly? 3. What can go wrong if the implementation is incorrect? What are state machines? • Almost every protocol includes some kind of state • State machine is a model of the different states and the transitions between them • When receiving a messages, given the current state: • Decide what action to perform • Which message to respond with • Which state to go the next Why are state machines interesting? • State machines play a very important role in security protocols • For example: • Is the user authenticated? • Did we agree on keys? And if so, which keys? • Are we encrypting our traffic? • Every implementation of a protocol has to include the corresponding state machine • Mistakes can lead to serious security issues! State machine example Confirm transaction Verify PIN 0000 Failed Init Failed Verify PIN 1234 OK Verified Confirm transaction OK State machines in specifications • Often specifications do not explicitly contain a state machine • Mainly explained in lots of prose • Focus usually on happy flow • What to do if protocol flow deviates from this? Client Server ClientHello --------> ServerHello Certificate* ServerKeyExchange* CertificateRequest* <-------- ServerHelloDone Certificate* ClientKeyExchange CertificateVerify* [ChangeCipherSpec] Finished --------> [ChangeCipherSpec] <-------- Finished Application Data <-------> Application Data -

You Really Shouldn't Roll Your Own Crypto: an Empirical Study of Vulnerabilities in Cryptographic Libraries
You Really Shouldn’t Roll Your Own Crypto: An Empirical Study of Vulnerabilities in Cryptographic Libraries Jenny Blessing Michael A. Specter Daniel J. Weitzner MIT MIT MIT Abstract A common aphorism in applied cryptography is that cryp- The security of the Internet rests on a small number of open- tographic code is inherently difficult to secure due to its com- source cryptographic libraries: a vulnerability in any one of plexity; that one should not “roll your own crypto.” In par- them threatens to compromise a significant percentage of web ticular, the maxim that complexity is the enemy of security traffic. Despite this potential for security impact, the character- is a common refrain within the security community. Since istics and causes of vulnerabilities in cryptographic software the phrase was first popularized in 1999 [52], it has been in- are not well understood. In this work, we conduct the first voked in general discussions about software security [32] and comprehensive analysis of cryptographic libraries and the vul- cited repeatedly as part of the encryption debate [26]. Conven- nerabilities affecting them. We collect data from the National tional wisdom holds that the greater the number of features Vulnerability Database, individual project repositories and in a system, the greater the risk that these features and their mailing lists, and other relevant sources for eight widely used interactions with other components contain vulnerabilities. cryptographic libraries. Unfortunately, the security community lacks empirical ev- Among our most interesting findings is that only 27.2% of idence supporting the “complexity is the enemy of security” vulnerabilities in cryptographic libraries are cryptographic argument with respect to cryptographic software. -

Not-Quite-So-Broken TLS: Lessons in Re-Engineering a Security Protocol Specification and Implementation
Not-Quite-So-Broken TLS: Lessons in Re-Engineering a Security Protocol Specification and Implementation David Kaloper-Meršinjak, Hannes Mehnert, Anil Madhavapeddy, and Peter Sewell, University of Cambridge https://www.usenix.org/conference/usenixsecurity15/technical-sessions/presentation/kaloper-mersinjak This paper is included in the Proceedings of the 24th USENIX Security Symposium August 12–14, 2015 • Washington, D.C. ISBN 978-1-939133-11-3 Open access to the Proceedings of the 24th USENIX Security Symposium is sponsored by USENIX Not-quite-so-broken TLS: lessons in re-engineering a security protocol specification and implementation David Kaloper-Mersinjakˇ †, Hannes Mehnert†, Anil Madhavapeddy and Peter Sewell University of Cambridge Computer Laboratory [email protected] † These authors contributed equally to this work Abstract sensitive services, they are not providing the security we need. Transport Layer Security (TLS) is the most widely Transport Layer Security (TLS) implementations have a deployed security protocol on the Internet, used for au- history of security flaws. The immediate causes of these thentication and confidentiality, but a long history of ex- are often programming errors, e.g. in memory manage- ploits shows that its implementations have failed to guar- ment, but the root causes are more fundamental: the chal- antee either property. Analysis of these exploits typically lenges of interpreting the ambiguous prose specification, focusses on their immediate causes, e.g. errors in mem- the complexities inherent in large APIs and code bases, ory management or control flow, but we believe their root inherently unsafe programming choices, and the impos- causes are more fundamental: sibility of directly testing conformance between imple- mentations and the specification. -

A Technical Comparison of Ipsec and SSL
A Technical Comparison of IPSec and SSL y Ab delNasir Alshamsi Takamichi Saito Tokyo University of Technology Abstract p osed but the most famous secure and widely de ployed are IPSec IP Security and SSL Secure So cket Layer IPSec IP Security and SSL SecureSocket Layer In this pap er we will provide a technical comparison have been the most robust and most potential tools of IPSec and SSL the similarities and the dierences available for securing communications over the Inter of the cryptographic prop erties The results of per net Both IPSec and SSL have advantages and short formance are based on comparing FreeSWAN as comings Yet no paper has been found comparing the IPSec and Stunnel as SSL two protocols in terms of characteristic and functional ity Our objective is to present an analysis of security and performancepr operties for IPSec and SSL IPSec IPSec is an IP layer proto col that enables the Intro duction sending and receiving of cryptographically protected packets of any kind TCPUDPICMPetc without any provides two kinds of crypto mo dication IPSec Securing data over the network is hard and compli graphic services Based on necessity IPSec can provide cated issue while the threat of data mo dication and condentiality and authenticity or it can provide data interruption is rising The goal of network security authenticity only is to provide condentiality integrity and authenticity Condentiality is keeping the data secret from the ESP Encapsulated SecurityPayload unintended listeners on the network Integrity is en suring -
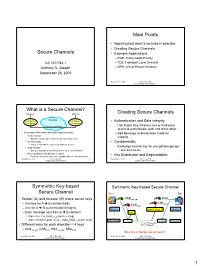
Secure Channels Secure Channels • Example Applications – PGP: Pretty Good Privacy CS 161/194-1 – TLS: Transport Layer Security Anthony D
Main Points • Applying last week’s lectures in practice • Creating Secure Channels Secure Channels • Example Applications – PGP: Pretty Good Privacy CS 161/194-1 – TLS: Transport Layer Security Anthony D. Joseph – VPN: Virtual Private Network September 26, 2005 September 26, 2005 CS161 Fall 2005 2 Joseph/Tygar/Vazirani/Wagner What is a Secure Channel? Plaintext Plaintext Creating Secure Channels Encryption / Internet Encryption / • Authentication and Data Integrity Decryption Decryption Ciphertext and MAC – Use Public Key Infrastructure or third-party server to authenticate each end to the other • A stream with these security requirements: – Add Message Authentication Code for – Authentication integrity • Ensures sender and receiver are who they claim to be – Confidentiality • Confidentiality • Ensures that data is read only by authorized users – Data integrity – Exchange session key for encrypt/decrypt ops • Ensures that data is not changed from source to destination • Bulk data transfer – Non-repudiation (not discussed today) • Ensures that sender can’t deny message and rcvr can’t deny msg • Key Distribution and Segmentation September 26, 2005 CS161 Fall 2005 3 September 26, 2005 CS161 Fall 2005 4 Joseph/Tygar/Vazirani/Wagner Joseph/Tygar/Vazirani/Wagner Symmetric Key-based Symmetric Key-based Secure Channel Secure Channel Alice Bob • Sender (A) and receiver (B) share secret keys KABencrypt KABencrypt – One key for A è B confidentiality KABauth KABauth – One for A è B authentication/integrity Message MAC Compare? Message – Each message -

Plaintext-Recovery Attacks Against Datagram TLS
Plaintext-Recovery Attacks Against Datagram TLS Nadhem J. AlFardan and Kenneth G. Paterson∗ Information Security Group Royal Holloway, University of London, Egham, Surrey TW20 0EX, UK fNadhem.Alfardan.2009, [email protected] Abstract GnuTLS2. Both of these provide source toolkits that imple- ment TLS and DTLS as well as being general purpose cryp- The Datagram Transport Layer Security (DTLS) proto- tographic libraries that software developers can use. The col provides confidentiality and integrity of data exchanged first release of OpenSSL to implement DTLS was 0.9.8. between a client and a server. We describe an efficient and Since its release, DTLS has become a mainstream proto- full plaintext recovery attack against the OpenSSL imple- col in OpenSSL. There are also a number of commercial mentation of DTLS, and a partial plaintext recovery attack products that have taken advantage of DTLS. For example, against the GnuTLS implementation of DTLS. The attack DTLS is used to secure Virtual Private Networks (VPNs)3;4 against the OpenSSL implementation is a variant of Vaude- and wireless traffic5. Platforms such as Microsoft Windows, nay’s padding oracle attack and exploits small timing differ- Microsoft .NET and Linux can also make use of DTLS6. ences arising during the cryptographic processing of DTLS In addition, the number of RFC documents that are be- packets. It would have been prevented if the OpenSSL im- ing published on DTLS is increasing. Recent examples in- plementation had been in accordance with the DTLS RFC. clude RFC 5415 [1], RFC 5953 [8] and RFC 6012 [13]. A In contrast, the GnuTLS implementation does follow the new version of DTLS is currently under development in the DTLS RFC closely, but is still vulnerable to attack. -

Heartbleed Debugged – Openssl & CVE-2014-0160
Heartbleed Debugged – OpenSSL & CVE-2014-0160 Heartbleed Debugged – OpenSSL & CVE-2014-0160 René ’Lynx’ Pfeiffer DeepSec GmbH ihttps://deepsec.net/, [email protected] FH Eisenstadt Heartbleed Debugged – OpenSSL & CVE-2014-0160 Vorstellung Studium der Physik PGP Benutzer seit 1992 (aus denselben Gründen wie heute) selbstständig seit 1999 in der Informationstechnologie seit 2001 Lehrtätigkeit bei Firmen und dem Technikum Wien seit 2008 in der Geschäftsführung der DeepSec Konferenz seit 2010 in der Geschäftsführung der Crowes Agency OG Heartbleed Debugged – OpenSSL & CVE-2014-0160 Motivation – Ist OpenSSL wichtig? OpenSSL ist wichtige Sicherheitskomponente weit verbreitet in Applikationen & Embedded Devices OpenSSL implementiert nicht nur SSL/TLS full-strength general purpose cryptography library X.509 für PKI ::: Fehler in OpenSSL betreffen daher viele Anwendungen One Bug to rule them all, One Bug to find them; One Bug to bring them all and in the darkness bind them. Heartbleed Debugged – OpenSSL & CVE-2014-0160 OpenSSL Fakten Geschichte von OpenSSL offizieller Start am 23. Dezember 1998 (Version 0.9.1) Motivation: Werkzeug für Kryptographie, Fokus Internet mod_ssl v1 stammt von April 1998 (auf Basis Apache-SSL) OpenSSL Entwicklungsteam 11 Developer (zwei angestellt) schreiben, modifizieren, testen 500.000+ Zeilen Code Heartbleed Debugged – OpenSSL & CVE-2014-0160 OpenSSL Fakten OpenSSL Fähigkeiten Verschlüsselungsalgorithmen AES, Blowfish, Camellia, SEED, CAST-128, DES, IDEA, RC2, RC4, RC5, Triple DES, GOST 28147-89 Hash-Algorithmen MD5,