Alexey Patrushev Analysis of Software Engineering Data with Self-Organizing Maps
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Prioritizing Pull Requests
Prioritizing pull requests Version of June 17, 2015 Erik van der Veen Prioritizing pull requests THESIS submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in COMPUTER SCIENCE by Erik van der Veen born in Voorburg, the Netherlands Software Engineering Research Group Q42 Department of Software Technology Waldorpstraat 17F Faculty EEMCS, Delft University of Technology 2521 CA Delft, the Netherlands The Hague, the Netherlands www.ewi.tudelft.nl www.q42.com c 2014 Erik van der Veen. Cover picture: Finding the pull request that needs the most attention. Prioritizing pull requests Author: Erik van der Veen Student id: 1509381 Email: [email protected] Abstract Previous work showed that in the pull-based development model integrators face challenges with regard to prioritizing work in the face of multiple concurrent pull requests. We identified the manual prioritization heuristics applied by integrators and ex- tracted features from these heuristics. The features are used to train a machine learning model, which is capable of predicting a pull request’s importance. The importance is then used to create a prioritized order of the pull requests. Our main contribution is the design and initial implementation of a prototype service, called PRioritizer, which automatically prioritizes pull requests. The service works like a priority inbox for pull requests, recommending the top pull requests the project owner should focus on. It keeps the pull request list up-to-date when pull requests are merged or closed. In addition, the service provides functionality that GitHub is currently lacking. We implemented pairwise pull request conflict detection and several new filter and sorting options e.g. -

Poli12-Bootstrappingsmalltalk-SCP
Bootstrapping Reflective Systems: The Case of Pharo G. Polito1,2,∗, S. Ducasse1, L. Fabresse2, N. Bouraqadi2, B. van Ryseghem1 Abstract Bootstrapping is a technique commonly known by its usage in language definition by the introduction of a compiler written in the same language it compiles. This process is important to understand and modify the definition of a given language using the same language, taking benefit of the abstractions and expression power it provides. A bootstrap, then, supports the evolution of a language. However, the infrastructure of reflective systems like Smalltalk includes, in addition to a compiler, an environment with several self-references. A reflective system bootstrap should consider all its infrastructural components. In this paper, we propose a definition of bootstrap for object-oriented reflective systems, we describe the architecture and components it should contain and we analyze the challenges it has to overcome. Finally, we present a reference bootstrap process for a reflective system and Hazelnut, its implementation for bootstrapping the Pharo Smalltalk-inspired system. Keywords: Object-Oriented Programming and Design, Bootstrap, Smalltalk, Software Evolution 1. Introduction Reflective systems are those that reason about and act upon themselves [21]. A causal connection exists between the program and its representation inside the program itself as a meta-program [16]. This reflective architecture introduces self-references: an object-oriented system is composed by objects, which are instances of classes, which are also objects, and so on. These self-references, also known as meta-circularities [6], allow the manipulation of several meta-levels on one infrastructure. Reflective systems traditionally modify their self-representation to evolve and define new abstractions. -

Proceedings.Pdf
Goals and scopes •The goals of the workshop is to create a forum around advances or experience in Smalltalk and to trigger discussions and exchanges of ideas. Participants are invited to submit research articles. We will not enforce any length restriction. However we expect papers of two kinds: –Short position papers describing emerging ideas. –Long research papers with deeper description of experiments and of research results. •We welcome contributions on all aspects, theoretical as well as practical, of Smalltalk related topics such as: –Aspect-oriented programming, –Design patterns, –Experience reports, –Frameworks, –Implementation, –new dialects or languages implemented in Smalltalk, –Interaction with other languages, –Meta-programming and Meta-modeling, –Tools Publication •Both submissions and final papers must be prepared using the ACM SIGPLAN 10 point format. Templates for Word and LaTeX are available at http://www.acm.org/sigs/sigplan/authorInformation.htm •Authors of the best accepted papers will also be invited to submit extended versions for publication in a special issue of Elsevier "Science of Computer Programming: Methods of Software Design: Techniques and Applications" •Please submit your paper through EasyChair on http://www.easychair.org/conferences/?conf=iwst2012 Program Chairs •Loïc Lagadec Lab-STICC, UBO, France •Alain Plantec, Lab-STICC, UBO, France Program Committee •Gabriela Arevalo, Universidad Nacional de Quilmes, Agentina •Alexandre Bergel University of Chile •Andrew P. Black Portland State University, US •Marcus -
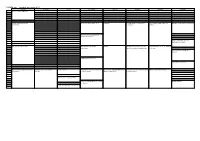
FOSDEM 2013 Schedule
FOSDEM 2013 - Saturday 2013-02-02 (1/9) Janson K.1.105 Ferrer Chavanne Lameere H.1301 H.1302 H.1308 10:30 Welcome to FOSDEM 2013 10:45 11:00 How we made the Jenkins QEMU USB status report 2012 Rockbuild The neat guide to Fedora RPM LinuxonAndroid and SlapOS on Wayland for Application Developers community Packaging Android 11:15 11:30 CRIU: Checkpoint and Restore (mostly) In Userspace 11:45 Ubuntu Online Accounts for application developers 12:00 The Devil is in the Details Vtrill: Rbridges for Virtual PTXdist Building RPM packages from Git Emdedded distro shootout: buildroot Networking repositories with git-buildpackage vs. Debian Better software through user 12:15 research 12:30 Bringing Xen to CentOS-6 Sketching interactions 12:45 13:00 The Open Observatory of Network Porting Fedora to 64-bit ARM Coding Goûter A brief tutorial on Xen's advanced Guacamayo -- Building Multimedia Package management and creation ARM v7 State of the Body ↴ Interference systems security features Appliance with Yocto ↴ in Gentoo Linux ↴ 13:15 Spoiling and Counter-spoiling 13:30 oVirt Live Storage Migration - Under Modern CMake ↴ the Hood ↴ ZONE: towards a better news feed ↴ 13:45 FOSDEM 2013 - Saturday 2013-02-02 (2/9) H.1309 H.2213 H.2214 AW1.120 AW1.121 AW1.125 AW1.126 Guillissen 10:30 10:45 11:00 Metaphor and BDD XMPP 101 Storytelling FLOSS Welcome and Introduction The room open() process Scripting Apache OpenOffice: Welcome to the Perl d… Introductory Nutshell Programs Inheritance versus Roles (Writer, Calc, Impress) 11:15 Signal/Collect: Processing Large -

Why I Still Program in Smalltalk Outline Summary
Why I still program Outline in Smalltalk •Introduction, Background •What do Programmers Need? Musings on Software Development •Some History •What Is Smalltalk? Stephen Travis Pope • Language, Libraries, Tools, Methodology [email protected] Relationship to Other Languages, IDEs, etc. UCSB MAT Colloquium • January 14, 2012 •Why I Still Use Smalltalk http://HeavenEverywhere.com/WISPiST.pdf •A Call to Revolutionary Action 1 2 Summary (spoiler alert) NeXT ad from 1992 3 4 My Background What I Develop (& biases) Complex projects (music, AI, high-level tools) Training: EE, CS, Music • • Media-rich (A/V) •HW Development Projects • • Analog Synths, Eventide •DB-rich (large volumes, complex queries) • Vienna, Salzburg jobs •Wide-area distributed Programming • Cross-platform • Low-level, lots of tool-building, then LISP • • Visits to MIT and SAIL in 1976/77 •Performance-critical (compute-bound) • UNIX & C starting in 1976 •Back-end servers and front-end GUIs Graphics starting in 1979 • • C/C++, Python, MATLAB, SuperCollider, SQL • IRCAM, [email protected] 5 6 MODE, 1990-92 Context: 1983 Culture “Girls just want to have fun” “Puttin’ on the Ritz” 7 8 Context: 1983 Context Computing STP & CB in 1984 (photos by CR) 9 10 What do Programmers Need? What do Programmers Need? •Software Development Processes • Edit code • Compile, link •Software development tools! • Run, debug • Test • Document • Share, manage multi-programmer teams • Package, deliver • Maintain, upgrade 11 12 What do Programmers Need? Requirements Analysis •Great Overviews of the -

Squeakjs: a Modern and Practical Smalltalk
SqueakJS A Modern and Practical Smalltalk that Runs in Any Browser Bert Freudenberg Dan Ingalls Tim Felgentreff Communications Design Group Communications Design Group Hasso Plattner Institute Potsdam, Germany San Francisco, CA, USA University of Potsdam, Germany [email protected] [email protected] tim.felgentreff@hpi.uni-potsdam.de Tobias Pape Robert Hirschfeld Hasso Plattner Institute Hasso Plattner Institute University of Potsdam, Germany University of Potsdam, Germany [email protected] [email protected] Abstract We report our experience in implementing SqueakJS, a bit- compatible implementation of Squeak/Smalltalk written in pure JavaScript. SqueakJS runs entirely in the Web browser with a virtual file system that can be directed to a server or client-side storage. Our implementation is notable for simplicity and performance gained through adaptation to the host object memory and deployment lever- age gained through the Lively Web development environment. We present several novel techniques as well as performance measure- ments for the resulting virtual machine. Much of this experience is potentially relevant to preserving other dynamic language systems and making them available in a browser-based environment. Categories and Subject Descriptors D.3.4 [Software]: Program- ming Languages—Interpreters General Terms Languages, Virtual Machines, Performance Keywords Smalltalk, Squeak, Web browsers, JavaScript 1. Motivation Figure 1. SqueakJS running an Etoys image in a stand-alone Web The Squeak/Smalltalk development environment [8] and its deriva- page tives are the basis for a number of interesting applications in research and education. Educational applications such as Etoys [9] and early versions of Scratch [12], however, suffer from restrictions against browser-native, implementation of Squeak’s virtual machine (VM) installing native software in scholastic environments. -

ESUG 2012 Report
CS18 and ESUG 20, Ghent, August 25th - 31st, 2012 1 CS18 and ESUG 20, Ghent, August 25th - 31st, 2012 This document contains my report of the ESUG conference in Ghent, August 27th - 31st, 2012 (and the Camp Smalltalk during the weekend before it). As there were parallel tracks, I could not attend all talks. Style ‘I’ or ‘my’ refers to Niall Ross; speakers (other than myself) are referred to by name or in the third person. A question asked in or after a talk is prefixed by ‘Q.’ (sometimes I name the questioner; often I was too busy noting their question). A question not beginning with ‘Q.’ is a rhetorical question asked by the speaker (or is just my way of summarising their meaning). Author’s Disclaimer and Acknowledgements These reports give my personal view. No view of any other person or organisation with which I am connected is expressed or implied. The talk descriptions were typed while I was trying to keep up with and understand what the speakers were saying, so may contain errors of fact or clarity. I apologise for any inaccuracies, and to any participants whose names or affiliations I failed to note down. If anyone spots errors or omissions, email me and corrections may be made. My thanks to the conference organisers and the speakers whose work gave me something to report. Venue Ghent is second only to Bruge (amongst Belgian cities that I know) for preserving the beautiful old centre of the renaissance town. The streets that border its canals are very pleasant, with fine architecture in abundance. -

Squeakjs: a Modern and Practical Smalltalk That Runs in Any Browser
Accepted for DLS SqueakJS A Modern and Practical Smalltalk That Runs in Any Browser Bert Freudenberg Dan Ingalls Tim Felgentreff Communications Design Group Communications Design Group Hasso Plattner Institute Potsdam, Germany San Francisco, CA, USA University of Potsdam, Germany [email protected] [email protected] tim.felgentreff@hpi.uni-potsdam.de Tobias Pape Robert Hirschfeld Hasso Plattner Institute Hasso Plattner Institute University of Potsdam, Germany University of Potsdam, Germany [email protected] [email protected] Abstract We report our experience in implementing SqueakJS, a bit- compatible implementation of Squeak/Smalltalk written in pure JavaScript. SqueakJS runs entirely in the Web browser with a virtual file system that can be directed to a server or client-side storage. Our implementation is notable for simplicity and performance gained through adaptation to the host object memory and deployment lever- age gained through the Lively Web development environment. We present several novel techniques as well as performance measure- ments for the resulting virtual machine. Much of this experience is potentially relevant to preserving other dynamic language systems and making them available in a browser-based environment. Categories and Subject Descriptors D.3.4 [Software]: Program- ming Languages—Interpreters General Terms Languages, Virtual Machines, Performance Keywords Smalltalk, Squeak, Web browsers, JavaScript 1. Motivation Figure 1. SqueakJS running an Etoys image in a stand-alone Web The Squeak/Smalltalk development environment [8] and its deriva- page tives are the basis for a number of interesting applications in research and education. Educational applications such as Etoys [9] and early versions of Scratch [12], however, suffer from restrictions against browser-native, implementation of Squeak’s virtual machine (VM) installing native software in scholastic environments. -

Efficient Layered Method Execution in Contextamber
Efficient Layered Method Execution in ContextAmber Matthias Springer Jens Lincke Robert Hirschfeld Hasso Plattner Institute Hasso Plattner Institute Hasso Plattner Institute University of Potsdam University of Potsdam University of Potsdam [email protected] [email protected] [email protected] ABSTRACT can be as small as 1% [3], whereas in context-oriented pro- We present ContextAmber, a framework for context-oriented gramming, the performance decrease of layer-aware method programming, in Amber Smalltalk, an implementation of dispatch is typically more than 75% [1]. the Smalltalk programming language that compiles to Java- Upon invocation of a layered method, a COP implemen- Script. ContextAmber is implemented using metaprogram- tation without any further optimizations has to perform the ming facilities and supports global, object-wise, and scoped following steps. layer activation. Current COP implementations come at the 1. Compute the receiver's layer composition (active layers). expense of significantly reduced execution performance due to multiple partial method invocations and layer composi- 2. Find and invoke the partial method corresponding to the tion computations every time a layered method is invoked. topmost layer having a partial method for the invoked ContextAmber can reduce this overhead by inlining partial base method. methods, caching layer compositions, and caching inlined 3. Find and invoke the next partial method when a proceed layered methods, resulting in a runtime overhead of about call is encountered. 5% in our vector graphics rendering benchmarks. In this paper, we present optimizations that speed up the Categories and Subject Descriptors execution of COP applications: our implementation, Con- textAmber, avoids unnecessary computations of layer com- D.1.5 [Programming Techniques]: Object-Oriented Pro- positions and reduces the number of method invocations by gramming; inlining partial methods. -

Performance from Aligning Smalltalk & Javascript Classes
Performance from Aligning Smalltalk & Javascript Classes Dave Mason Ryerson University 350 Victoria Street Toronto, ON, Canada M5B 2K7 [email protected] ProtoObject ABSTRACT ProtoObject class methods Amber is a wonderful Smalltalk programming environment methods that runs on top of Javascript, including a browser-based fields IDE and compiler, as well as command-line support. The Object only challenge is that execution performance can be 1{2 or- Object class an Object methods ders of magnitude slower than native Javascript code. Amber- methods Direct is a series of modest changes to the compiler and some fields infrastructure classes and methods that bring most gener- Behavior ated programs to within a factor of two of native Javascript. Behavior class methods methods fields The challenge we faced was maintaining a seamless integra- tion into existing Javascript classes while maximizing fidelity Class Class class to Smalltalk execution semantics. methods methods fields 1. INTRODUCTION Metaclass Metaclass class Amber[9] Smalltalk is a programming environment created methods methods to support programming on the web (or on servers using fields NodeJS). It provides a Smalltalk IDE, and supports pro- gramming in Smalltalk, while automatically compiling the UndefinedObject UndefinedObject Smalltalk code to Javascript to utilize the native Javascript nil methods class engine provided by most modern browsers. fields methods In development mode, Amber creates a context within each UserCls a UserCls UserCls class methods function to facilitate traditional Smalltalk error reporting. fields methods This context-creation can be turned off for production mode fields to minimize the overhead. superclass Amber is also specifically designed to interoperate with nor- class mal Javascript as seamlessly as possible. -

CS11 and ESUG 14, Prague, September 4Th - 8Th, 2006 1 CS11 and ESUG 14, Prague, September 4Th - 8Th, 2006
CS11 and ESUG 14, Prague, September 4th - 8th, 2006 1 CS11 and ESUG 14, Prague, September 4th - 8th, 2006 Arriving in Prague on an early flight (5 am get-up :-/), I got on the airport shuttle bus, only to discover that the currency of the Czech Republic is crowns, not euros. I approve their individuality and independence on this issue (which may not last much longer, I fear). And since a courteous fellow passenger offered me a fair rate to exchange a euro for my fare crowns, I was not tempted to moderate my admiration by any considerations of mere convenience for foreigners like myself. The hotel had large labels saying accommodation, restaurant and other facilities but none giving its name. Fortunately, the heaviness of my luggage persuaded me to try it anyway since it was in the right place, otherwise I might have walked far before turning around. Style In the text below, ‘I’ or ‘my’ refers to Niall Ross; speakers are referred to by name or in the third person. A question asked in or after a talk is prefaced by ‘Q.’ (I identify the questioner when I could see who they were). A question not prefaced by ‘Q.’ is a rhetorical question asked by the speaker (or is just my way of summarising their meaning). Author’s Disclaimer and Acknowledgements This report was written by Niall Ross of eXtremeMetaProgrammers Ltd. (nfr AT bigwig DOT net). It gives my personal view. No view of any other person or organisation with which I am connected is expressed or implied. -

Poli13b-Bootstrappingasmalltal
Bootstrapping Reflective Systems: The Case of Pharo Guillermo Polito, Stéphane Ducasse, Luc Fabresse, Noury Bouraqadi, Benjamin van Ryseghem To cite this version: Guillermo Polito, Stéphane Ducasse, Luc Fabresse, Noury Bouraqadi, Benjamin van Ryseghem. Boot- strapping Reflective Systems: The Case of Pharo. Science of Computer Programming, Elsevier, 2014, 96, pp.18. 10.1016/j.scico.2013.10.008. hal-00903724 HAL Id: hal-00903724 https://hal.inria.fr/hal-00903724 Submitted on 12 Nov 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Bootstrapping Reflective Systems: The Case of Pharo Accepted to Science of Computer Programming - Journal - Elsevier G. Polito1,2,∗, S. Ducasse1, L. Fabresse2, N. Bouraqadi2, B. van Ryseghem1 Abstract Bootstrapping is a technique commonly known by its usage in language definition by the introduction of a compiler written in the same language it compiles. This process is important to understand and modify the definition of a given language using the same language, taking benefit of the abstractions and expression power it provides. A bootstrap, then, supports the evolution of a language. However, the infrastructure of reflective systems like Smalltalk includes, in addition to a compiler, an environment with several self-references.