Analysis and Clustering of Musical Compositions Using Melody-Based Features
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

M.A-Music-Vocal-Syllabus.Pdf
BANGALORE UNIVERSITY NAAC ACCREDITED WITH ‘A’ GRADE P.G. DEPARTMENT OF PERFORMING ARTS JNANABHARATHI, BANGALORE-560056 MUSIC SYLLABUS – M.A KARNATAKA MUSIC VOCAL AND INSTRUMENTAL (VEENA, VIOLIN AND FLUTE) CBCS SYSTEM- 2014 Dr. B.M. Jayashree. Professor of Music Chairperson, BOS (PG) M.A. KARNATAKA MUSIC VOCAL AND INSTRUMENTAL (VEENA, VIOLIN AND FLUTE) Semester scheme syllabus CBCS Scheme of Examination, continuous Evaluation and other Requirements: 1. ELIGIBILITY: A Degree with music vocal/instrumental as one of the optional subject with at least 50% in the concerned optional subject an merit internal among these applicant Of A Graduate with minimum of 50% marks secured in the senior grade examination in music (vocal/instrumental) conducted by secondary education board of Karnataka OR a graduate with a minimum of 50% marks secured in PG Diploma or 2 years diploma or 4 year certificate course in vocal/instrumental music conducted either by any recognized Universities of any state out side Karnataka or central institution/Universities Any degree with: a) Any certificate course in music b) All India Radio/Doordarshan gradation c) Any diploma in music or five years of learning certificate by any veteran musician d) Entrance test (practical) is compulsory for admission. 2. M.A. MUSIC course consists of four semesters. 3. First semester will have three theory paper (core), three practical papers (core) and one practical paper (soft core). 4. Second semester will have three theory papers (core), two practical papers (core), one is project work/Dissertation practical paper and one is practical paper (soft core) 5. Third semester will have two theory papers (core), three practical papers (core) and one is open Elective Practical paper 6. -
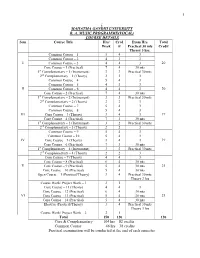
1 ; Mahatma Gandhi University B. A. Music Programme(Vocal
1 ; MAHATMA GANDHI UNIVERSITY B. A. MUSIC PROGRAMME(VOCAL) COURSE DETAILS Sem Course Title Hrs/ Cred Exam Hrs. Total Week it Practical 30 mts Credit Theory 3 hrs. Common Course – 1 5 4 3 Common Course – 2 4 3 3 I Common Course – 3 4 4 3 20 Core Course – 1 (Practical) 7 4 30 mts 1st Complementary – 1 (Instrument) 3 3 Practical 30 mts 2nd Complementary – 1 (Theory) 2 2 3 Common Course – 4 5 4 3 Common Course – 5 4 3 3 II Common Course – 6 4 4 3 20 Core Course – 2 (Practical) 7 4 30 mts 1st Complementary – 2 (Instrument) 3 3 Practical 30 mts 2nd Complementary – 2 (Theory) 2 2 3 Common Course – 7 5 4 3 Common Course – 8 5 4 3 III Core Course – 3 (Theory) 3 4 3 19 Core Course – 4 (Practical) 7 3 30 mts 1st Complementary – 3 (Instrument) 3 2 Practical 30 mts 2nd Complementary – 3 (Theory) 2 2 3 Common Course – 9 5 4 3 Common Course – 10 5 4 3 IV Core Course – 5 (Theory) 3 4 3 19 Core Course – 6 (Practical) 7 3 30 mts 1st Complementary – 4 (Instrument) 3 2 Practical 30 mts 2nd Complementary – 4 (Theory) 2 2 3 Core Course – 7 (Theory) 4 4 3 Core Course – 8 (Practical) 6 4 30 mts V Core Course – 9 (Practical) 5 4 30 mts 21 Core Course – 10 (Practical) 5 4 30 mts Open Course – 1 (Practical/Theory) 3 4 Practical 30 mts Theory 3 hrs Course Work/ Project Work – 1 2 1 Core Course – 11 (Theory) 4 4 3 Core Course – 12 (Practical) 6 4 30 mts VI Core Course – 13 (Practical) 5 4 30 mts 21 Core Course – 14 (Practical) 5 4 30 mts Elective (Practical/Theory) 3 4 Practical 30 mts Theory 3 hrs Course Work/ Project Work – 2 2 1 Total 150 120 120 Core & Complementary 104 hrs 82 credits Common Course 46 hrs 38 credits Practical examination will be conducted at the end of each semester 2 MAHATMA GANDHI UNIVERSITY B. -

6. ADDITIONAL SUBJECTS (A) MUSIC Any One of the Following Can Be Offered: (Hindustani Or Carnatic)
6. ADDITIONAL SUBJECTS (A) MUSIC Any one of the following can be offered: (Hindustani or Carnatic) 1. Carnatic Music-Vocal 4. Hindustani Music-Vocal or or 2. Carnatic Music-Melodic Instruments 5. Hindustani Music Melodic Instruments or or 3. Carnatic Music-Percussion 6. Hindustani Music Percussion Instruments Instruments (i) CARNATIC MUSIC VOCAL THE WEIGHTAGE FOR FORMATIVE ASSESSMENT (F.A.) AND SUMMATIVE ASSESSMENT (S.A.) FOR TERM I & II SHALL BE AS FOLLOWS Term Type of Assessment Percentage of Termwise Total Weightage in Weightage Academic Session for both Terms First Term Summative 1 15% 15+35 50% (April - Theory Paper Sept.) Practicals 35% Second Summative 2 15% 15+35 50% Term Theory Paper (Oct.- Practicals 35% March) Total 100% Term-I Term-II Total Theory 15% + 15% = 30% Practical 35% + 35% = 70% Total 100% 163 Carnatic Music (Code No. 034) Any one of the following can be offered : (Hindustani or Carnatic) 1. Carnatic Music-Vocal 4. Hindustani Music-Vocal or or 2. Carnatic Music-Melodic Instruments 5. Hindustani Music Melodic Instruments or or 3. Carnatic Music-Percussion 6. Hindustani Music Percussion Instruments Instruments (i) CARNATIC MUSIC VOCAL THE WEIGHTAGE FOR FORMATIVE ASSESSMENT (F.A.) AND SUMMATIVE ASSESSMENT (S.A.) FOR TERM I & II SHALL BE AS FOLLOWS Term Type of Assessment Percentage of Termwise Total Weightage in Weightage Academic Session for both Terms First Term Summative 1 15% 15+35 50% (April - Theory Paper Sept.) Practicals 35% Second Summative 2 15% 15+35 50% Term Theory Paper (Oct.- Practicals 35% March) Total 100% Term-I Term-II Total Theory 15% + 15% = 30% Practical 35% + 35% = 70% Total 100% 164 SYLLABUS FOR SUMMATIVE ASSESSMENT FIRST TERM (APRIL 2016 - SEPTEMBER 2016) CARNATIC MUSIC (VOCAL) (CODE 031) CLASS IX TOPIC (A) Theory 15 Marks 1. -

Carnatic Music Theory Year I
CARNATIC MUSIC THEORY YEAR I BASED ON THE SYLLABUS FOLLOWED BY GOVERNMENT MUSIC COLLEGES IN ANDHRA PRADESH AND TELANGANA FOR CERTIFICATE EXAMS HELD BY POTTI SRIRAMULU TELUGU UNIVERSITY ANANTH PATTABIRAMAN EDITION: 2.6 Latest edition can be downloaded from https://beautifulnote.com/theory Preface This text covers topics on Carnatic music required to clear the first year exams in Government music colleges in Andhra Pradesh and Telangana. Also, this is the first of four modules of theory as per Certificate in Music (Carnatic) examinations conducted by Potti Sriramulu Telugu University. So, if you are a music student from one of the above mentioned colleges, or preparing to appear for the university exam as a private candidate, you’ll find this useful. Though attempts are made to keep this text up-to-date with changes in the syllabus, students are strongly advised to consult the college or univer- sity and make sure all necessary topics are covered. This might also serve as an easy-to-follow introduction to Carnatic music for those who are generally interested in the system but not appearing for any particular examination. I’m grateful to my late guru, veteran violinist, Vidwan. Peri Srirama- murthy, for his guidance in preparing this document. Ananth Pattabiraman Editions First published in 2009, editions 2–2.2 in 2017, 2.3–2.5 in 2018, 2.6 in 2019. Latest edition available at https://beautifulnote.com/theory Copyright This work is copyrighted and is distributed under Creative Commons BY-NC-ND 4.0 license. You can make copies and share freely. -

Model Question Paper 3 Semester Ba Degree Examination Under Cbcss Music Core Course – Iii Mu 1341 : Thoery – Ii- Ragam (2017
MODEL QUESTION PAPER 3RD SEMESTER BA DEGREE EXAMINATION UNDER CBCSS MUSIC CORE COURSE – III MU 1341 : THOERY – II- RAGAM (2017 Admission) Time: 3 Hours Max. Marks: 80 I. Answer all the following questions (10x1=10marks) 1. Give the generic name of the Mela Chakravakam. 2. An Audava – Sampoorna raga. 3. Give the serial number of the mela Ramapriya. 4. Write the name of 72 nd melakartha. 5. Name a Dvi- anyaswarabhashanga raga. 6. Name the mela represented as ‘sa ra gi ma pa dha nu.’ 7. Which mela is referred to as ‘Indu–sri.’ 8. Janaka raga of Saveri. 9. Starting note of a raga. 10. Who propounded the scheme of 72 melakartha? II. Answer any eight from the following (8x2=16marks) 11. Differentiate between amsaswara and nyasaswara 12. Discuss the role of madhyama in the scheme of 72 mela 13. Define Mitra ragas with suitable examples 14. Name two vakra ragas 15. Write arohana and avarohana of Saveri and Malahari 16. Define Sankirna ragas 17. Name two Audava ragas taking Sudha Madhyama 18. Explain the term Vadi and Vivadi 19. Give two examples of morning ragas 20. Differentiate Samvadi and Anuvadi swaras MODEL QUESTION PAPER 3RD SEMESTER BA DEGREE EXAMINATION UNDER CBCSS MUSIC CORE COURSE – III MU 1341 : THOERY – II- RAGAM (2017 Admission) Time: 3 Hours Max. Marks: 80 I. Answer all the following questions (10x1=10marks) 1. Give the generic name of the Mela Chakravakam. 2. An Audava – Sampoorna raga. 3. Give the serial number of the mela Ramapriya. 4. Write the name of 72 nd melakartha. 5. -

Carnatic Music Theory Year Ii
CARNATIC MUSIC THEORY YEAR II BASED ON THE SYLLABUS FOLLOWED BY GOVERNMENT MUSIC COLLEGES IN ANDHRA PRADESH AND TELANGANA FOR CERTIFICATE EXAMS HELD BY POTTI SRIRAMULU TELUGU UNIVERSITY ANANTH PATTABIRAMAN EDITION: 2.1 Latest edition can be downloaded from https://beautifulnote.com/theory Preface This text covers topics on Carnatic music required to clear the second year exams in Government music colleges in Andhra Pradesh and Telangana. Also, this is the second of four modules of theory as per Certificate in Music (Carnatic) examinations conducted by Potti Sriramulu Telugu University. So, if you are a music student from one of the above mentioned colleges, or preparing to appear for the university exam as a private candidate, you’ll find this useful. Though attempts are made to keep this text up-to-date with changes in the syllabus, students are strongly advised to consult the college or univer- sity and make sure all necessary topics are covered. This might also serve as an easy-to-follow introduction to Carnatic music for those who are generally interested in the system but not appearing for any particular examination. I’m grateful to my late guru, veteran violinist, Vidwan. Peri Srirama- murthy, for his guidance in preparing this document. Ananth Pattabiraman Editions First published in 2010, edition 2.0 in 2018, 2.1 in 2019. Latest edition available at https://beautifulnote.com/theory Copyright This work is copyrighted and is distributed under Creative Commons BY-NC-ND 4.0 license. You can make copies and share freely. Not for commercial use. Read https://creativecommons.org/licenses/by-nc-nd/4.0/ About the author Ananth Pattabiraman is a musician. -

CARNATIC MUSIC (VOCAL) (Code No
CARNATIC MUSIC (VOCAL) (code no. 031) Class IX (2020-21) Theory Marks: 30 Time: 2 Hours No. of periods I. Brief history of Carnatic Music with special reference to Saint 10 Purandara dasa, Annamacharya, Bhadrachala Ramadasa, Saint Tyagaraja, Muthuswamy Dikshitar, Syama Sastry and Swati Tirunal. II. Definition of the following terms: 12 Sangeetam, Nada, raga, laya, Tala, Dhatu, Mathu, Sruti, Alankara, Arohana, Avarohana, Graha (Sama, Atita, Anagata), Svara – Prakruti & Vikriti Svaras, Poorvanga & Uttaranga, Sthayi, vadi, Samvadi, Anuvadi & Vivadi Svara – Amsa, Nyasa and Jeeva. III. Brief raga lakshanas of Mohanam, Hamsadhvani, Malahari, 12 Sankarabharanam, Mayamalavagoula, Bilahari, khamas, Kharaharapriya, Kalyani, Abhogi & Hindolam. IV. Brief knowledge about the musical forms. 8 Geetam, Svarajati, Svara Exercises, Alankaras, Varnam, Jatisvaram, Kirtana & Kriti. V. Description of following Talas: 8 Adi – Single & Double Kalai, Roopakam, Chapu – Tisra, Misra & Khanda and Sooladi Sapta Talas. VI. Notation of Gitams in Roopaka and Triputa Tala 10 Total Periods 60 CARNATIC MUSIC (VOCAL) Format of written examination for class IX Theory Marks: 30 Time: 2 Hours 1 Section I Six MCQ based on all the above mentioned topic 6 Marks 2 Section II Notation of Gitams in above mentioned Tala 6 Marks Writing of minimum Two Raga-lakshana from prescribed list in 6 Marks the syllabus. 3 Section III 6 marks Biography Musical Forms 4 Section IV 6 marks Description of talas, illustrating with examples Short notes of minimum 05 technical terms from the topic II. Definition of any two from the following terms (Sangeetam, Nada, Raga,Sruti, Alankara, Svara) Total Marks 30 marks Note: - Examiners should set atleast seven questions in total and the students should answer five questions from them, including two Essays, two short answer and short notes questions based on technical terms will be compulsory. -

Oriental Fine Arts Academy London (OFAAL)
Published by Oriental Fine Arts Academy London (OFAAL) OFAAL is a registered charity institution. Registration No. 110360 Revised Edition 2021 http://www.ofaal.org Copyright 2021/ Oriental Fine Arts Academy -London/ Syllabus- Carnatic Vocal & Instruments (Violin,Veena, Flute, Carnatic Keyboard.) 1 Examination Committee Carnatic Vocal & Instruments Oriental Fine Arts Academy of London Revision 2021 ,g; ghlj;jpl;lk; gw;wp ................ vkJ fe;ehlf rq;fPj ghlj;jpl;lj;ij(tha;ghl;L> taypd;> tPiz> Gy;yhq;Foy; vd;gd) tpupthf tpsf;Fk; nghUl;L rpW khw;wq;fSld; ,jidj; jahupj;Js;Nshk;. Kjyhk;> ,uz;lhk; juj;jpw;F mwpKiwAk; nray;KiwAk; tha; nkhop %yk; gupNrhjpf;fg;gLk;. %d;whk; juk; njhlf;fk; bg;gpNshkh epiy tiu nray;KiwAld; vOj;J %ykhd mwpKiwAk; gupNrhjpf;fg;gLk;. ,tu;fspd; rhd;wpjo;fspy; nray;Kiw> mwpKiw ngWNgWfs; ,uz;Lk;;; mlq;Fk;. bg;Nshkh juj;jpw;F Njhd;Wtjw;F guPl;ir jpdj;jd;W 14 taJ epuk;gpatuhf ,Uj;jy; Ntz;Lk;. ,jpy; rpj;jpailNthUf;F rq;fPj fyhN[hjp vd;w rpwg;Gg; gl;lk; toq;fg;gLk;. mj;Jld; KJepiy bg;Nshkh ghPl;irapy; rpj;jpailNthUf;F rq;fPj fyh uj;jpdk; vd;w caHe;j gl;lk; toq;fg;gLk; NkYk; ,jd; gpw;gFjpy; khjpup tpdhf;fs; Nru;f;fg;gl;Ls;sik Fwpg;gplj;jf;fJ. ,k; Kaw;rpahdJ vkJ ghlj;jpl;lj;jpd; juj;ij NkYk; $l;LtJld; ,jidg; gpd;gw;Wgtu;fSf;F ,yFthf mikAk; vd;W ek;Gfpd;Nwhk;. ,g;ghlj;jpl;lk; gw;wpa Mf;fG+u;tkhd fUj;Jfs; tuNtw;fg;gLk;;. guPl;;irf;FO fPioj;Nja Ez;fiyg; guPl;ir ];jhgdk; ,yz;ld; About this Syllabus...... -

Raga (Melodic Mode) Raga This Article Is About Melodic Modes in Indian Music
FREE SAMPLES FREE VST RESOURCES EFFECTS BLOG VIRTUAL INSTRUMENTS Raga (Melodic Mode) Raga This article is about melodic modes in Indian music. For subgenre of reggae music, see Ragga. For similar terms, see Ragini (actress), Raga (disambiguation), and Ragam (disambiguation). A Raga performance at Collège des Bernardins, France Indian classical music Carnatic music · Hindustani music · Concepts Shruti · Svara · Alankara · Raga · Rasa · Tala · A Raga (IAST: rāga), Raag or Ragam, literally means "coloring, tingeing, dyeing".[1][2] The term also refers to a concept close to melodic mode in Indian classical music.[3] Raga is a remarkable and central feature of classical Indian music tradition, but has no direct translation to concepts in the classical European music tradition.[4][5] Each raga is an array of melodic structures with musical motifs, considered in the Indian tradition to have the ability to "color the mind" and affect the emotions of the audience.[1][2][5] A raga consists of at least five notes, and each raga provides the musician with a musical framework.[3][6][7] The specific notes within a raga can be reordered and improvised by the musician, but a specific raga is either ascending or descending. Each raga has an emotional significance and symbolic associations such as with season, time and mood.[3] The raga is considered a means in Indian musical tradition to evoke certain feelings in an audience. Hundreds of raga are recognized in the classical Indian tradition, of which about 30 are common.[3][7] Each raga, state Dorothea -

Raga Vaibhavam at Bangalore
RAGA V AIBHAVAM - SMT . R AJASHREE Y OGANANDA DR.R ADHA B HASKAR , MUSICIAN AND MUSICOLOGIST HAS DEVISED A NOVEL CONCEPT CALLED THE M USIC A PPRECIATION PROGRAMME THROUGH WHICH SHE TRIES TO ENLIGHTEN RASIKAS ABOUT THE FINER NUANCES OF K ARNATIC MUSIC . STARTED NINE YEARS AGO , THIS PROGRAMME HAS RECEIVED VERY GOOD RESPONSE FROM RASIKAS . R AGA V AIBHAVAM - A JOURNEY INTO THE BEAUTIFUL WORLD OF RAGAS WAS PRESENTED BY D R.R ADHA ALONG WITH K.P.N ANDINI AND AISHWARYA S HANKARON 29 TH J ULY 2012. T HIS WAS ORGANIZED BY S RI R AMA L ALITHA K ALA M ANDIRA , B ANGALORE AND RECEIVED GOOD APPRECIATION FROM RASIKAS . DR.R ADHA IN HER INTRODUCTION , SAID THAT IT WAS NOT ENOUGH FOR A RASIKA TO JUST KNOW THE NAME OF VARIOUS RAGAS . O NE MUST GO DEEPER INTO IT AND TRY TO UNDERSTAND ITS CHARACTER , MOVEMENTS , ITS FORM AS DEPICTED IN VARIOUS COMPOSITIONS ETC . S HE TOOK A VARIETY OF RAGAS TO PROVIDE AN INTERESTING FARE . B EGINNING WITH MAYAMALAVAGOULA AND ITS JANYAS , SHE EXPLAINED ITS LAKSHANA , AROHANA -AVAROHANA AND MENTIONED THE POPULAR COMPOSITIONS IN IT . S HE POINTED OUT HOW M UTHUSWAMY D IKSHITAR IN HIS FIRST COMPOSITION “S RI NATHADI GURUGUHO ” IN THIS RAGA HAS BROUGHT OUT THE RAGA SWARUPA IN A CRYSTAL CLEAR MANNER BY ESSAYING THE AROHANA –AVAROHANA VIVIDLY . S HE ALSO DEMONSTRATED THE NATURE OF GAMAKAS EMPLOYED BY EACH NOTE IN MAYAMALAVAGOULA AND GAVE AN INTERESTING COMPARISON OF THE “ GA -MA ” COMBINATION USED IN THIS RAGA AS WELL AS IN S HANKARABHARANAM RAGA . -

Volume 24 December 2014
SRUTI RANJANI Volume 24 December 2014 Table of Contents From the President’s Desk .................................................................................................................... 1 From the Publications & Outreach Committee .................................................................................. 3 Tribute to Vainika K.S.Narayanaswamy, by Rama Varma ............................................................... 4 Zakir Hussain, R.Kumaresh and Jayanthi Kumaresh in Concert, by Balaji Raghothaman ............ 9 A Dikshithar Thematic Concert, by Rajee Raman ........................................................................... 10 Mandolin Uppalapu Shrinivas (1969 – 2014): A Humble Tribute, by Ragesh Rajan ...................... 12 When signal processing meets Carnatic music: An interview with Dr. Hema Murthy, by Balaji Raghothaman .................................................. 16 Verily, A Veena Pustaka Dharini, by Ravi & Sridhar ....................................................................... 19 Update on the 4S tool, by Balaji Raghothaman .............................................................................. 23 2014 Spring & Fall Concert Photos ..................................................................................................... 24 Sruti Youth Group Update, by Priyanka Dinakar ............................................................................ 30 My Experiences with Bharatanatyam, by Zoe Dana ...................................................................... -

A Comparison of Concert Patterns in Carnatic and Hindustani Music Sakuntala Narasimhan — 134
THE JOURNAL OF THE MUSIC ACADEMY MADRAS: DEVOTED TO m ADVANCEMENT OF THE SCIENCE AND ART OF MUSIC V ol. L IV 1983 R 3 P E I r j t nrcfri gsr fiigiPi n “ I dwell not in Vaiknntka, nor in tlie hearts of Togihs nor in the Sun: (but) where my bhaktas sing, there be I, Narada!" Edited by T. S. FARTHASARATHY 1983 The Music Academy Madras 306, T. T. K. Road, M adras -600 014 Annual Subscription - Inland - Rs. 15: Foreign $ 3.00 OURSELVES This Journal is published as an'Annual. • ; i '■■■ \V All correspondence relating to the Journal should be addressed and all books etc., intended for it should be sent to The Editor, Journal of the Music Academy, 306, Mowbray’s Road, Madras-600014. Articles on music and dance are accepted for publication on the understanding that they are contributed solely to the Journal of the Music Academy. Manuscripts should be legibly written or, preferably, type* written (double-spaced and on one side of the paper only) and should be signed by the writer (giving his or her address in full). The Editor of the Journal is not responsible for the views ex pressed by contributors in their articles. JOURNAL COMMITTEE OF THE MUSIC ACADEMY 1. Sri T. S. Parthasarathy — Editor (and Secretary, Music Academy) 2. „ T. V. Rajagopalan — Trustee 3. „ S. Ramaswamy — Executive Trustee 4. „ Sandhyavandanam Sreenivasa Rao — Member 5. „ S. Ramanathan — Member 6. „ NS. Natarajan Secretaries of the Music 7. „ R. Santhanam > Academy,-Ex-officio 8. ,, T. S. Rangarajan ' members. C ^ N T E N I S .