No Black Magic: Text Processing at the UNIX Command Line
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

At—At, Batch—Execute Commands at a Later Time
at—at, batch—execute commands at a later time at [–csm] [–f script] [–qqueue] time [date] [+ increment] at –l [ job...] at –r job... batch at and batch read commands from standard input to be executed at a later time. at allows you to specify when the commands should be executed, while jobs queued with batch will execute when system load level permits. Executes commands read from stdin or a file at some later time. Unless redirected, the output is mailed to the user. Example A.1 1 at 6:30am Dec 12 < program 2 at noon tomorrow < program 3 at 1945 pm August 9 < program 4 at now + 3 hours < program 5 at 8:30am Jan 4 < program 6 at -r 83883555320.a EXPLANATION 1. At 6:30 in the morning on December 12th, start the job. 2. At noon tomorrow start the job. 3. At 7:45 in the evening on August 9th, start the job. 4. In three hours start the job. 5. At 8:30 in the morning of January 4th, start the job. 6. Removes previously scheduled job 83883555320.a. awk—pattern scanning and processing language awk [ –fprogram–file ] [ –Fc ] [ prog ] [ parameters ] [ filename...] awk scans each input filename for lines that match any of a set of patterns specified in prog. Example A.2 1 awk '{print $1, $2}' file 2 awk '/John/{print $3, $4}' file 3 awk -F: '{print $3}' /etc/passwd 4 date | awk '{print $6}' EXPLANATION 1. Prints the first two fields of file where fields are separated by whitespace. 2. Prints fields 3 and 4 if the pattern John is found. -

1 A) Login to the System B) Use the Appropriate Command to Determine Your Login Shell C) Use the /Etc/Passwd File to Verify the Result of Step B
CSE ([email protected] II-Sem) EXP-3 1 a) Login to the system b) Use the appropriate command to determine your login shell c) Use the /etc/passwd file to verify the result of step b. d) Use the ‘who’ command and redirect the result to a file called myfile1. Use the more command to see the contents of myfile1. e) Use the date and who commands in sequence (in one line) such that the output of date will display on the screen and the output of who will be redirected to a file called myfile2. Use the more command to check the contents of myfile2. 2 a) Write a “sed” command that deletes the first character in each line in a file. b) Write a “sed” command that deletes the character before the last character in each line in a file. c) Write a “sed” command that swaps the first and second words in each line in a file. a. Log into the system When we return on the system one screen will appear. In this we have to type 100.0.0.9 then we enter into editor. It asks our details such as Login : krishnasai password: Then we get log into the commands. bphanikrishna.wordpress.com FOSS-LAB Page 1 of 10 CSE ([email protected] II-Sem) EXP-3 b. use the appropriate command to determine your login shell Syntax: $ echo $SHELL Output: $ echo $SHELL /bin/bash Description:- What is "the shell"? Shell is a program that takes your commands from the keyboard and gives them to the operating system to perform. -

DC Console Using DC Console Application Design Software
DC Console Using DC Console Application Design Software DC Console is easy-to-use, application design software developed specifically to work in conjunction with AML’s DC Suite. Create. Distribute. Collect. Every LDX10 handheld computer comes with DC Suite, which includes seven (7) pre-developed applications for common data collection tasks. Now LDX10 users can use DC Console to modify these applications, or create their own from scratch. AML 800.648.4452 Made in USA www.amltd.com Introduction This document briefly covers how to use DC Console and the features and settings. Be sure to read this document in its entirety before attempting to use AML’s DC Console with a DC Suite compatible device. What is the difference between an “App” and a “Suite”? “Apps” are single applications running on the device used to collect and store data. In most cases, multiple apps would be utilized to handle various operations. For example, the ‘Item_Quantity’ app is one of the most widely used apps and the most direct means to take a basic inventory count, it produces a data file showing what items are in stock, the relative quantities, and requires minimal input from the mobile worker(s). Other operations will require additional input, for example, if you also need to know the specific location for each item in inventory, the ‘Item_Lot_Quantity’ app would be a better fit. Apps can be used in a variety of ways and provide the LDX10 the flexibility to handle virtually any data collection operation. “Suite” files are simply collections of individual apps. Suite files allow you to easily manage and edit multiple apps from within a single ‘store-house’ file and provide an effortless means for device deployment. -

The Ifplatform Package
The ifplatform package Original code by Johannes Große Package by Will Robertson http://github.com/wspr/ifplatform v0.4a∗ 2017/10/13 1 Main features and usage This package provides the three following conditionals to test which operating system is being used to run TEX: \ifwindows \iflinux \ifmacosx \ifcygwin If you only wish to detect \ifwindows, then it does not matter how you load this package. Note then that use of (Linux or Mac OS X or Cygwin) can then be detected with \ifwindows\else. If you also wish to determine the difference between which Unix-variant you are using (i.e., also detect \iflinux, \ifmacosx, and \ifcygwin) then shell escape must be enabled. This is achieved by using the -shell-escape command line option when executing LATEX. If shell escape is not enabled, \iflinux, \ifmacosx, and \ifcygwin will all return false. A warning will be printed in the console output to remind you in this case. ∗Thanks to Ken Brown, Joseph Wright, Zebb Prime, and others for testing this package. 1 2 Auxiliary features \ifshellescape is provided as a conditional to test whether shell escape is active or not. (Note: new versions of pdfTEX allow you to query shell escape with \ifnum\pdfshellescape>0 , and the pdftexcmds package provides the wrapper \pdf@shellescape which works with X TE EX, pdfTEX, and LuaTEX.) Also, the \platformname command is defined to expand to a macro that represents the operating system. Default definitions are (respectively): \windowsname ! ‘Windows’ \notwindowsname ! ‘*NIX’ (when shell escape is disabled) \linuxname ! ‘Linux’ \macosxname ! ‘Mac OS X’ \cygwinname ! ‘Cygwin’ \unknownplatform ! whatever is returned by uname E.g., if \ifwindows is true then \platformname expands to \windowsname, which expands to ‘Windows’. -
It's Complicated but It's Probably Already Booting Your Computer
FAQ SYSTEMD SYSTEMD It’s complicated but it’s probably already booting your computer. dynamically connect to your network, a runlevel of 1 for a single-user mode, GRAHAM MORRISON while syslogd pools all the system runlevel 3 for the same command messages together to create a log of prompt we described earlier, and Surely the ‘d’ in Systemd is everything important. Another daemon, runlevel 5 to launch a graphical a typo? though it lacks the ‘d’, is init – famous environment. Changing this for your No –it’s a form of Unix notation for being the first process that runs on next boot often involved editing the used to signify a daemon. your system. /etc/inittab file, and you’d soon get used to manually starting and stopping You mean like those little Isn’t init used to switch your own services simply by executing devils inhabiting Dante’s between the command-line the scripts you found. underworld? and the graphical desktop? There is a link in that Unix usage For many of us, yes. This was the You seem to be using the past of the term daemon supposedly main way of going from the tense for all this talk about the comes from Greek mythology, where desktop to a command line and back init daemon… daemons invisibly wove their magic again without trying to figure out which That’s because the and benign influence. The word is today processes to kill or start manually. aforementioned Systemd wants more commonly spelt ‘demon’, which Typing init 3 would typically close any to put init in the past. -

Getting to Grips with Unix and the Linux Family
Getting to grips with Unix and the Linux family David Chiappini, Giulio Pasqualetti, Tommaso Redaelli Torino, International Conference of Physics Students August 10, 2017 According to the booklet At this end of this session, you can expect: • To have an overview of the history of computer science • To understand the general functioning and similarities of Unix-like systems • To be able to distinguish the features of different Linux distributions • To be able to use basic Linux commands • To know how to build your own operating system • To hack the NSA • To produce the worst software bug EVER According to the booklet update At this end of this session, you can expect: • To have an overview of the history of computer science • To understand the general functioning and similarities of Unix-like systems • To be able to distinguish the features of different Linux distributions • To be able to use basic Linux commands • To know how to build your own operating system • To hack the NSA • To produce the worst software bug EVER A first data analysis with the shell, sed & awk an interactive workshop 1 at the beginning, there was UNIX... 2 ...then there was GNU 3 getting hands dirty common commands wait till you see piping 4 regular expressions 5 sed 6 awk 7 challenge time What's UNIX • Bell Labs was a really cool place to be in the 60s-70s • UNIX was a OS developed by Bell labs • they used C, which was also developed there • UNIX became the de facto standard on how to make an OS UNIX Philosophy • Write programs that do one thing and do it well. -

Unix Essentials (Pdf)
Unix Essentials Bingbing Yuan Next Hot Topics: Unix – Beyond Basics (Mon Oct 20th at 1pm) 1 Objectives • Unix Overview • Whitehead Resources • Unix Commands • BaRC Resources • LSF 2 Objectives: Hands-on • Parsing Human Body Index (HBI) array data Goal: Process a large data file to get important information such as genes of interest, sorting expression values, and subset the data for further investigation. 3 Advantages of Unix • Processing files with thousands, or millions, of lines How many reads are in my fastq file? Sort by gene name or expression values • Many programs run on Unix only Command-line tools • Automate repetitive tasks or commands Scripting • Other software, such as Excel, are not able to handle large files efficiently • Open Source 4 Scientific computing resources 5 Shared packages/programs https://tak.wi.mit.edu Request new packages/programs Installed packages/programs 6 Login • Requesting a tak account http://iona.wi.mit.edu/bio/software/unix/bioinfoaccount.php • Windows PuTTY or Cygwin Xming: setup X-windows for graphical display • Macs Access through Terminal 7 Connecting to tak for Windows Command Prompt user@tak ~$ 8 Log in to tak for Mac ssh –Y [email protected] 9 Unix Commands • General syntax Command Options or switches (zero or more) Arguments (zero or more) Example: uniq –c myFile.txt command options arguments Options can be combined ls –l –a or ls –la • Manual (man) page man uniq • One line description whatis ls 10 Unix Directory Structure root / home dev bin nfs lab . jdoe BaRC_Public solexa_public -

ECOGEO Workshop 2: Introduction to Env 'Omics
ECOGEO Workshop 2: Introduction to Env ‘Omics Unix and Bioinformatics Ben Tully (USC); Ken Youens-Clark (UA) Unix Commands pwd rm grep tail install ls ‘>’ sed cut cd cat nano top mkdir ‘<’ history screen touch ‘|’ $PATH ssh cp sort less df mv uniq head rsync/scp Unix Command Line 1. Open Terminal window Unix Command Line 2. Open Chrome and navigate to Unix tutorial at Protocols.io 3. Group: ECOGEO 4. Protocol: ECOGEO Workshop 2: Unix Module ! This will allow you to copy, paste Unix scripts into terminal window ! ECOGEO Protocols.io for making copy, paste easier Unix Command Line $ ls ls - lists items in the current directory Many commands have additional options that can be set by a ‘-’ $ ls -a Unix Command Line $ ls -a lists all files/directories, including hidden files ‘.’ $ ls -l lists the long format File Permissions | # Link | User | Group | Size | Last modified $ ls -lt lists the long format, but ordered by date last modified Unix Command Line Unix Command Line $ cd ecogeo/ cd - change directory List the contents of the current directory Move into the directory called unix List contents $ pwd pwd - present working directory Unix Command Line /home/c-debi/ecogeo/unix When were we in the directory home? Or c-debi? Or ecogeo? $ cd / Navigates to root directory List contents of root directory This where everything is stored in the computer All the commands we are running live in /bin Unix Command Line / root bin sys home mnt usr c-debi BioinfPrograms cdebi Desktop Downloads ecogeo unix assembly annotation etc Typical Unix Layout Unix Command Line Change directory to home Change directory to c-debi Change directory to ecogeo Change directory to unix List contents Change directory to data Change directory to root Unix Command Line Change directory to unix/data in one step $ cd /home/c-debi/ecogeo/unix/data Tab can be used to auto complete names $ cd . -

Introduction to Unix
Introduction to Unix Rob Funk <[email protected]> University Technology Services Workstation Support http://wks.uts.ohio-state.edu/ University Technology Services Course Objectives • basic background in Unix structure • knowledge of getting started • directory navigation and control • file maintenance and display commands • shells • Unix features • text processing University Technology Services Course Objectives Useful commands • working with files • system resources • printing • vi editor University Technology Services In the Introduction to UNIX document 3 • shell programming • Unix command summary tables • short Unix bibliography (also see web site) We will not, however, be covering these topics in the lecture. Numbers on slides indicate page number in book. University Technology Services History of Unix 7–8 1960s multics project (MIT, GE, AT&T) 1970s AT&T Bell Labs 1970s/80s UC Berkeley 1980s DOS imitated many Unix ideas Commercial Unix fragmentation GNU Project 1990s Linux now Unix is widespread and available from many sources, both free and commercial University Technology Services Unix Systems 7–8 SunOS/Solaris Sun Microsystems Digital Unix (Tru64) Digital/Compaq HP-UX Hewlett Packard Irix SGI UNICOS Cray NetBSD, FreeBSD UC Berkeley / the Net Linux Linus Torvalds / the Net University Technology Services Unix Philosophy • Multiuser / Multitasking • Toolbox approach • Flexibility / Freedom • Conciseness • Everything is a file • File system has places, processes have life • Designed by programmers for programmers University Technology Services -

A First Course to Openfoam
Basic Shell Scripting Slides from Wei Feinstein HPC User Services LSU HPC & LON [email protected] September 2018 Outline • Introduction to Linux Shell • Shell Scripting Basics • Variables/Special Characters • Arithmetic Operations • Arrays • Beyond Basic Shell Scripting – Flow Control – Functions • Advanced Text Processing Commands (grep, sed, awk) Basic Shell Scripting 2 Linux System Architecture Basic Shell Scripting 3 Linux Shell What is a Shell ▪ An application running on top of the kernel and provides a command line interface to the system ▪ Process user’s commands, gather input from user and execute programs ▪ Types of shell with varied features o sh o csh o ksh o bash o tcsh Basic Shell Scripting 4 Shell Comparison Software sh csh ksh bash tcsh Programming language y y y y y Shell variables y y y y y Command alias n y y y y Command history n y y y y Filename autocompletion n y* y* y y Command line editing n n y* y y Job control n y y y y *: not by default http://www.cis.rit.edu/class/simg211/unixintro/Shell.html Basic Shell Scripting 5 What can you do with a shell? ▪ Check the current shell ▪ echo $SHELL ▪ List available shells on the system ▪ cat /etc/shells ▪ Change to another shell ▪ csh ▪ Date ▪ date ▪ wget: get online files ▪ wget https://ftp.gnu.org/gnu/gcc/gcc-7.1.0/gcc-7.1.0.tar.gz ▪ Compile and run applications ▪ gcc hello.c –o hello ▪ ./hello ▪ What we need to learn today? o Automation of an entire script of commands! o Use the shell script to run jobs – Write job scripts Basic Shell Scripting 6 Shell Scripting ▪ Script: a program written for a software environment to automate execution of tasks ▪ A series of shell commands put together in a file ▪ When the script is executed, those commands will be executed one line at a time automatically ▪ Shell script is interpreted, not compiled. -
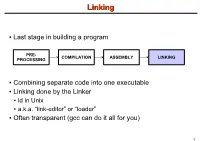
Linking + Libraries
LinkingLinking ● Last stage in building a program PRE- COMPILATION ASSEMBLY LINKING PROCESSING ● Combining separate code into one executable ● Linking done by the Linker ● ld in Unix ● a.k.a. “link-editor” or “loader” ● Often transparent (gcc can do it all for you) 1 LinkingLinking involves...involves... ● Combining several object modules (the .o files corresponding to .c files) into one file ● Resolving external references to variables and functions ● Producing an executable file (if no errors) file1.c file1.o file2.c gcc file2.o Linker Executable fileN.c fileN.o Header files External references 2 LinkingLinking withwith ExternalExternal ReferencesReferences file1.c file2.c int count; #include <stdio.h> void display(void); Compiler extern int count; int main(void) void display(void) { file1.o file2.o { count = 10; with placeholders printf(“%d”,count); display(); } return 0; Linker } ● file1.o has placeholder for display() ● file2.o has placeholder for count ● object modules are relocatable ● addresses are relative offsets from top of file 3 LibrariesLibraries ● Definition: ● a file containing functions that can be referenced externally by a C program ● Purpose: ● easy access to functions used repeatedly ● promote code modularity and re-use ● reduce source and executable file size 4 LibrariesLibraries ● Static (Archive) ● libname.a on Unix; name.lib on DOS/Windows ● Only modules with referenced code linked when compiling ● unlike .o files ● Linker copies function from library into executable file ● Update to library requires recompiling program 5 LibrariesLibraries ● Dynamic (Shared Object or Dynamic Link Library) ● libname.so on Unix; name.dll on DOS/Windows ● Referenced code not copied into executable ● Loaded in memory at run time ● Smaller executable size ● Can update library without recompiling program ● Drawback: slightly slower program startup 6 LibrariesLibraries ● Linking a static library libpepsi.a /* crave source file */ … gcc .. -

Bash Crash Course + Bc + Sed + Awk∗
Bash Crash course + bc + sed + awk∗ Andrey Lukyanenko, CSE, Aalto University Fall, 2011 There are many Unix shell programs: bash, sh, csh, tcsh, ksh, etc. The comparison of those can be found on-line 1. We will primary focus on the capabilities of bash v.4 shell2. 1. Each bash script can be considered as a text file which starts with #!/bin/bash. It informs the editor or interpretor which tries to open the file, what to do with the file and how should it be treated. The special character set in the beginning #! is a magic number; check man magic and /usr/share/file/magic on existing magic numbers if interested. 2. Each script (assume you created “scriptname.sh file) can be invoked by command <dir>/scriptname.sh in console, where <dir> is absolute or relative path to the script directory, e.g., ./scriptname.sh for current directory. If it has #! as the first line it will be invoked by this command, otherwise it can be called by command bash <dir>/scriptname.sh. Notice: to call script as ./scriptname.sh it has to be executable, i.e., call command chmod 555 scriptname.sh before- hand. 3. Variable in bash can be treated as integers or strings, depending on their value. There are set of operations and rules available for them. For example: #!/bin/bash var1=123 # Assigns value 123 to var1 echo var1 # Prints ’var1’ to output echo $var1 # Prints ’123’ to output var2 =321 # Error (var2: command not found) var2= 321 # Error (321: command not found) var2=321 # Correct var3=$var2 # Assigns value 321 from var2 to var3 echo $var3 # Prints ’321’ to output