Don't Skype & Type! Acoustic Eavesdropping in Voice-Over-IP
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Evaluation of Computer Input Devices for Use in Standard Office Applications While Moving in an Off-Road Vehicle
Evaluation of computer input devices for use in standard office applications while moving in an off-road vehicle by Thorsten Baldus A dissertation submitted to the graduate faculty in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY Major: Industrial Engineering Program of Study Committee: Patrick E. Patterson, Major Professor Samuel K. Adams Roger E. Baer John K. Jackman Mack C. Shelley Iowa State University Ames, Iowa 2006 UMI Number: 3229052 INFORMATION TO USERS The quality of this reproduction is dependent upon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleed-through, substandard margins, and improper alignment can adversely affect reproduction. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. UMI UMI Microform 3229052 Copyright 2006 by ProQuest Information and Learning Company. All rights reserved. This microform edition is protected against unauthorized copying under Title 17, United States Code. ProQuest Information and Learning Company 300 North Zeeb Road P.O. Box 1346 Ann Arbor, Ml 48106-1346 ii Graduate College Iowa State University This is to certify that the doctoral dissertation of Thorsten Baldus has met the dissertation requirements of Iowa State University Signature was redacted for privacy. Major Professor Signature was redacted for privacy. 'o/ -

Eye on the Message: Reducing Attention Demand for Touch-Based Text Entry
Avestia Publishing International Journal of Virtual Worlds and Human-Computer Interaction Volume 1, Year 2013 Journal ISSN: 2368-6103 DOI: 10.11159/vwhci.2013.001 Eye on the Message: Reducing Attention Demand for Touch-based Text Entry I. Scott MacKenzie, Steven J. Castellucci Dept. of Electrical Engineering and Computer Science York University Toronto, Ontario, Canada, M3J 1P3 [email protected]; [email protected] Abstract- A touch-based text entry method was developed with the device’s text entry method to enhance the user the goal of reducing the attention demand on the user. The experience. method, called H4touch, supports the entry of about 75 symbols In our observations of users interacting with touch- and commands using only four soft keys. Each key is about 20 based devices, it is evident that text is most commonly larger than the keys on a Qwerty soft keyboard on the same entered using a Qwerty soft keyboard, perhaps device. Symbols are entered as Huffman codes with most enhanced with swipe detection [26], word completion, letters requiring just two or three taps. The codes for the letters and common commands are learned after a few hours of next key prediction [9], or auto correction [23]. practice. At such time, the user can enter text while visually Because the keys are numerous and small, the user attending to the message, rather than the keyboard. Similar must attend to the keyboard to aim at and touch the eye-on-the-message interaction is not possible with a Qwerty desired key. Even highly practiced users must attend to soft keyboard, since there are many keys and they are small. -

Touch Typing at Home
Touch Typing at Home Physical & Medical Team There are lots of different touch typing tutors on the market. I have selected the following ones as they have been UK designed with children in mind, however this is by no means an exhaustive list! Free online software BBC dancemat is a free typing tutor for kids. http://www.bbc.co.uk/guides/z3c6tfr http://www.sense-lang.org/typing/tutor/keyboarding.php Doorway online http://www.doorwayonline.org.uk/ Software to purchase Nessy Fingers https://www.nessy.com/uk/product/nessy-fingers/ £30 single user license for a year. Current pricing due to Covid 19 is £24 plus VAT for a 2 month subscription to the typing tutor, reading and spelling and writing materials. Colourful typing tutor uses games and real words to practice touch typing. UK English. Not compatible with IPad/tablets English type https://englishtype.com/ Junior £29.95 for home license for everyone in your house. (Primary age) English Type Senior £29.95 for home license for everyone in your house (secondary age) Both are one-off purchases with no subscription needed. Not compatible with tablet/ IPads. Demo can be downloaded This software was developed by and Educational Psychologist in the UK and uses whole words rather than nonsense letter strings Touch type 2 http://www.inclusive.co.uk/touch-type-2-p2205 £39 single user license. A straightforward typing tutor with U.K. voice and clear layout. Not as visually appealing as some but suitable for all ages. Touch Type Read and Spell https://www.readandspell.com/home-course UK version. -

Typing Slowly but Screen-Free
Typing Slowly but Screen-Free: Exploring Navigation over Entirely Auditory Keyboards Reeti Mathur, Aishwarya Sheth, Parimal Vyas, and Davide Bolchini* Indiana University School of Informatics and Computing at IUPUI Indianapolis, USA *[email protected] Looping Flow Time Time Time Alphabetical Probabilistic Chunked [based on letter position] Figure 1. We investigate novel forms of entirely auditory keyboards that support text interaction without a reference screen. Time, rather than a fixed location in space, becomes the dimension in which to navigate symbols (right); a blind user experiments with an off-the-shelf armband to type in screenless mode (left). ABSTRACT CSS Concepts Accessible onscreen keyboards require people who are • Human-centered computing~Auditory feedback • blind to keep out their phone at all times to search for visual Human-centered computing~Accessibility affordances they cannot see. Is it possible to re-imagine text INTRODUCTION entry without a reference screen? To explore this question, On-screen keyboards support text entry on mobile devices we introduce screenless keyboards as aural flows by displaying a visual layout of letters but continue to pose (keyflows): rapid auditory streams of Text-To-Speech significant challenges for people who are Blind or Visually- (TTS) characters controllable by hand gestures. In a study, Impaired (BVI). Whereas a person who is blind may walk 20 screen-reader users experienced keyflows to perform with some form of travel aid in one hand (cane, a human initial text entry. Typing took inordinately longer than companion or guide dog), mobile displays force users to current screen-based keyboards, but most participants coordinate two hands to swipe or touch type on the screen. -

Issues and Techniques in Touch-Sensitive Tablet Input
SAN FRANCISCO JULY 22-26 Volume 19, Number 3, 1985 Issues and Techniques in Touch-Sensitive Tablet Input William Buxton Ralph Hill Peter Rowley Computer Systems Research Institute University of Toronto Toronto, Ontario Canada M5S 1A4 (416) 978-6320 1. Introduction Increasingly, research in human-computer interac- Abstract tion is focusing on problems of input [Foley, Wallace Touch-sensitive tablets and their use in human- &Chan 1984; Buxton 1983; Buxton £985]. Much of computer interaction are discussed, It is shown this attention is directed towards input technolo- that such devices have some important properties gies. The ubiquitous Sholes keyboard is being that differentiate them from other input devices replaced and/or complemented by alternative tech- (such as mice and joysticks). The analysis serves nologies. For example, a major focus of the market- two purposes: (1) it sheds light on touch tablets, ing strategy for two recent personal computers, the and (2) it demonstrates how other devices might be Apple Macintosh and Hewlett-Packard 150, has been approached. Three specific distinctions between on the input devices that they employ (the mouse touch tablets and one button mice are drawn. These and touch-screen, respectively). concern the signaling of events, multiple point sensing and the use of templates. These distinc- Now that the range of available devices is expand- tions are reinforced, and possible uses of touch ing, how does one select the best technology for a tablets are illustrated, in an example application. particular application? And once a technology is chosen, hove can it be used most effectively? These Potential enhancements to touch tablets and other questions are important, for as Buxton [ 1983] has input devices are discussed, as are some inherent argued, the ways in which the user physiccdty problems. -

Movement Strategies and Performance in Everyday Typing Anna Maria Feit Daryl Weir Antti Oulasvirta Aalto University, Helsinki, Finland
How We Type: Movement Strategies and Performance in Everyday Typing Anna Maria Feit Daryl Weir Antti Oulasvirta Aalto University, Helsinki, Finland Figure 1. Four users showing different typing behaviours involving different numbers of fingers and movement strategies. This paper reports typing rates, gaze and movement strategies for everyday typists, including both professionally trained and self-taught typists. We explain how untrained typists are able to type at very high rates, which were previously attributed only to the touch typing system that enforces the use of all 10 fingers. ABSTRACT Studies were carried out with trained typists (e.g., [2,4,6, This paper revisits the present understanding of typing, which 8, 23, 27, 29]) mostly operating typewriters. The participants originates mostly from studies of trained typists using the ten- were often professionally employed typists, skilled in typing finger touch typing system. Our goal is to characterise the with 10 fingers and able to consistently perform at rates of majority of present-day users who are untrained and employ over 80 words per minute (wpm) [8, 22, 24]. diverse, self-taught techniques. In a transcription task, we We are seeking to shed new light on the everyday typing tech- compare self-taught typists and those that took a touch typing niques, employed by a majority of users, that do not fall within course. We report several differences in performance, gaze the touch typing system. Touch typing originates from the deployment and movement strategies. The most surprising 1890s and is the technique taught in typing classes. Column- finding is that self-taught typists can achieve performance wise, each key is assigned to one finger. -

220 Layout with IBM* Compatibility FTSC Full Tr
5150 KEYBOARDS & KEYPADS 5150 CHERRY ELECTRICAL PRODUCTS 3600 Sunset Ave., Waukegan, IL 60087 708/360-3500 • FAX 708/360-3566 GSO-1600 & GSO-lS00 GSO-1600 GSO-lS00 mM Compatible Keyboard with Built-In Bar Code Compact, 101 Key, mM Compatible Keyboard with Reader. For PC, XT, AT,andPS/2-Systems. Separate Numeric Keypad. For PC, XT, AT and PS/2 Systems. • Input port for bar code stylus, laser scanning gun, or slot reader. • Fits into 19 inch rack (less than 16 inches wide). • Barcodes are automatically identified and differentiated • 101 keysforPC*. XT*, AT*, and PSI2* systems as well (all resolutions). as ffiM* terminals. • 103 keys (2 keys forprograrnroing mode) conforming to • Switch selection ofPC*, XT*, AT*, and PS/2 * modes. ASCU international key layout per DIN 66003/66303 . LED's indicate the mode selected . • Superior Cherry MX keyswitches with' ' Gold • Superior Cherry MX keyswitches with "Gold Crosspoint" contacts help eliminate input errors. Crosspoint" contacts help eliminate input errors. GSO-1307 DEC VT-220 Layout with • Includes housing and cable. IBM* Compatibility • Rugged construction. • " Deep Dish " for home keys FandJ with dimple on key • 105 keys using superior Cherry MX keyswitches with 5 for touch typing. "Gold Crosspoint" contacts to eliminate input errors. • Mane finished, 2-shot molded keycaps are wear resistant • High reliability: and easy to clean. Keycaps colors are: beige/grey (code MCBF = I x 10' operations. U9), white/grey (code L9) . MTBF = 80,000 hours. • Materials conform to UL 94. MCBF (each keymodule) 50 x 10" operations. > • Separate cu rsor pad. • Ergonomic, low profile design with "cylindrical style" • Full N -key rollover. -

Posture & Positioning
Keyboarding 101 Posture & Positioning Keyboarding 101 Learning Target: To learn proper keyboarding techniques to utilize when typing. Essential Questions: 1. Why is it important to use proper keyboarding techniques? 2. What proper keyboarding techniques should be utilized when typing on a computer keyboard? What is Keyboarding? • Keyboarding is the capability of entering text by using the correct fingers without looking at the keys (touch typing). • Touch typing involves using all ten of your fingers to type, using the correct finger for each key, and not looking at the keyboard. What is Keyboarding? • Having excellent keyboarding skills will help you to use the computer more efficiently and be more productive. • Keyboarding skills are skills for life. You will use these skills now and in the future for things like school work and in your career. There is no hiding from a computer today! Why Do We Care? As the day drags on, people tend to slouch. While slouching may feel like a comfortable way to relax and save energy, it can lead to back and neck pain. If you maintain good posture, you're likely to feel more alert throughout the day, because the muscles will have less strain placed on them, resulting in lower energy usage. Learning to have better posture is a practice that may take some time, but you'll look and feel better---and your body will be more relaxed. And MORE Why Do We Care… • The proper keyboarding posture minimizes static and dynamic muscle loads that may cause damage to your nerves, ligaments, muscles and tendons. -

923,920,400/100,412,4913,680,682,.691, 516, 515; 248/917,921,918,922,919, Primarye.E.E." Examine-Jeffery A
III USOO5212473A United States Patent (19) 11 Patent Number: 5,212,473 Louis (45) Date of Patent: May 18, 1993 (54) MEMBRANE KEYBOARD AND METHOD 4,933,522 6/1990 Celander ............................. 200/513 OF USNG SAME 5,119,078 6/1992 Grant .................................. 340/71 75 Inventor: William M. Louis, Encinitas, Calif. OTHER PUBLICATIONS 73 Assignee: Typeright Keyboard Corp., IBM Technical Disclosure Bulletin, "Key Matrix Using Encinitas, Calif. a Fluid Medium' by Cook et al. vol. 13, No. 3, dated Aug. 1970, p. 744. (21) Appl. No.: 658,541 IBM Technical Disclosure Bulletin, "Briefcase-Porta 22 Filed: Feb. 21, 1991 ble Text-written with 100-key Full-Size Keyboard' by 51) Int. Cl............................................... Goog 3/oz Pechanek et al. vol. 27, No. 4A, dated Sep. 1984, pp. 52 U.S. C. ...................................... 340/711; 341/22, 2002-200 ... if 58 Field341/27, of Search 200/513, ....................... 200/516, 340/711,700, 200/517,361/380 407, puter"IBM.Techniel by IBM Corp.,Pisclosure vol. 32,Bullein, No. 10B,Solding dated Mar.in 341/21, 22, 27, 24; 200/512.5 A, 513,511,517, 1990, pp. 266-267. 520,521,923,920,400/100,412,4913,680,682,.691, 516, 515; 248/917,921,918,922,919, PrimaryE.E.E." Examine-Jeffery A. Bri 693; 364/709.06, 710.01, 189, 708; 361/380; Attorney, Agent, or Firm-Bernard L. Kleinke; Jerry R. 235/1 D Potts; William Patrict Waters (56) References Cited 57 ABSTRACT U.S. PATENT DOCUMENTS A membrane keyboard producing audible and tactile 2,527,016 10/1950 Loung ................................ -

A Flick-Based Japanese Tablet Keyboard Using Direct Kanji Input
A Flick-based Japanese Tablet Keyboard using Direct Kanji Input Yuya Nakamura1 and Hiroshi Hosobe2 1Graduate School of Computer and Information Sciences, Hosei University, Tokyo, Japan 2Faculty of Computer and Information Sciences, Hosei University, Tokyo, Japan Keywords: Text Entry Touch Screen, Touch Typing, Software Keyboard. Abstract: Tablets, as well as smartphones and personal computers, are popular as Internet clients. A split keyboard is a software keyboard suitable for tablets with large screens. However, unlike other methods, the split keyboard has space in the center of the screen, which makes the part of the screen for displaying suggestions small and inconvenient. This paper proposes a Japanese input software keyboard that enables direct kanji input on a split flick keyboard. Once the user has mastered this keyboard, it allows the user to efficiently input Japanese text while holding a tablet with both hands. The paper presents an implementation of the keyboard on Android and reports the result of an experiment on its performance compared with existing methods. In addition, since direct kanji input generally takes time for users to learn, one of the authors by himself has conducted a long- term experiment to confirm the possibility of its mastery. For 12 months, both the input speed and the error rate have gradually improved. 1 INTRODUCTION makes the part of the screen for displaying conversion suggestions small and inconvenient. Japanese text is composed of Chinese-originated In Japan, there are about as many users of “flick” “kanji” characters and Japanese “kana” characters keyboards as QWERTY keyboard users. Flick is a (Tamaoka, 2014). While a kanji character typi- gesture operation especially used for character input cally has a meaning, a kana character does not; in- on touch-screen devices such as tablets and smart- stead, a kana character is associated with a speech phones. -

Keyboard Proficiency: an Essential Skill in a Technological Age. Number 2. INSTITUTION City Technology Colleges Trust Ltd., London (England)
DOCUMENT RESUME ED 348 557 CE 061 804 AUTHOI: Gillmon, Eve TITLE Keyboard Proficiency: An Essential Skill in a Technological Age. Number 2. INSTITUTION City Technology Colleges Trust Ltd., London (England). REPORT NO ISBN-1-873862-01-7 PUB DATE Sep 91 NOTE 39p. AVAILABLE FROMCity Technology Colleges Trust, Ltd., 15 Young Street, London W8 5EH, England, United Kingdom (7.50 British pounds). PUB TYPE Reports - Descriptive (141) EDRS PRICE MF01/PCO2 Plus Postage. DESCRIPTORS Business Education; Computer Oriented Programs; Foreign Countries; Information Systems; Job Skills; Junior High Schools; *Keyboarding (Data Entry); *Technological Advancement; *Typewriting; Word Processing IDENTIFIERS England ABSTRACT A structured keyboard skills training scheme for students in England should be included within school curricula. Negative attitudes toward keyboard training prevail in schools although employers value keyboard application skills. There are several reasons why keyboard proficiency, which facilitates the efficient input and retrieval of text and data, is needed in today's technologically advanced society: imputing and extracting text and data is a fundamental part of information technology; there is a need for efficient text input skills; and these skills enable the highest standards of text presentation available. Structured training in the skill is required because touch-typing is a complex psychomotor skill; systematic teaching in schools prevents picking up bad habits. In devising a strategy to provide training in schools, several points should be considered: (1) keyboard skills should be developed and monitored so they are shared through curriculum areas;(2) teaching staff should acquire keyboard training; (3) positive images of keyboard use enhance student motivation; (4) proficiency should be developed in all students; and (5) only basic equipment is needed. -
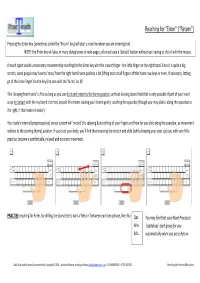
Reaching for “Enter” (“Return”)
Reaching for “Enter” (“Return”) Pressing the Enter key (sometimes called the ‘Return’ key) will start a new line when you are entering text. NOTE: the Enter key will also, in many dialog boxes or web-pages, often activate a ‘default’ button without you having to click it with the mouse. A touch typist avoids unnecessary movement by reaching for the Enter key with the closest finger - the little finger on the right hand. Since it is quite a big stretch, some people may have to ‘stray’ from the right hand home position a bit (lifting most or all fingers off the home row keys or even, if necessary, letting go of the index finger’s home key (the one with the ‘bump’ on it)! This ‘straying from home’ is fine as long as you can do it and return to the home position, without looking down! And that is only possible if part of your hand stays in contact with the keyboard: for most people this means leaving your thumb gently touching the spacebar (though you may slide it along the spacebar to the right, if that makes it easier). Your body’s internal (proprioceptive) sensor system will ‘record’ the splaying & stretching of your fingers and how far you slide along the spacebar, as movement relative to the starting (home) position . If you trust your body, you’ll find that reversing the stretch and slide (whilst keeping your eyes up) can, with very little practice, become a comfortable, relaxed and accurate movement. PRACTISE reaching for Enter, by drilling the story letters with a ‘Return’ between each key phrase, like this: Qaz You may find that your Word Processor Wsx ‘capitalises’ each group for you Edc… automatically when you press Return StarTouch and all materials protected by Copyright © 2011 - Jonathan Stevens, trading as Parang [email protected] – 020 8288 8255 – 07765 257 671 Reaching for Peripheral Keys.docx Reaching for “Shift” Pressing and holding one of the Shift keys, while you type another key, will give you either the Upper Case (of a letter key) or the uppermost of the two symbols shown on most symbol/number keys.