ADVANCED TOPICS in ALGEBRAIC GEOMETRY Outline of Talk: My Goal
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Using Elimination to Describe Maxwell Curves Lucas P
Louisiana State University LSU Digital Commons LSU Master's Theses Graduate School 2006 Using elimination to describe Maxwell curves Lucas P. Beverlin Louisiana State University and Agricultural and Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_theses Part of the Applied Mathematics Commons Recommended Citation Beverlin, Lucas P., "Using elimination to describe Maxwell curves" (2006). LSU Master's Theses. 2879. https://digitalcommons.lsu.edu/gradschool_theses/2879 This Thesis is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Master's Theses by an authorized graduate school editor of LSU Digital Commons. For more information, please contact [email protected]. USING ELIMINATION TO DESCRIBE MAXWELL CURVES A Thesis Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial ful¯llment of the requirements for the degree of Master of Science in The Department of Mathematics by Lucas Paul Beverlin B.S., Rose-Hulman Institute of Technology, 2002 August 2006 Acknowledgments This dissertation would not be possible without several contributions. I would like to thank my thesis advisor Dr. James Madden for his many suggestions and his patience. I would also like to thank my other committee members Dr. Robert Perlis and Dr. Stephen Shipman for their help. I would like to thank my committee in the Experimental Statistics department for their understanding while I completed this project. And ¯nally I would like to thank my family for giving me the chance to achieve a higher education. -
Geometry Course Outline
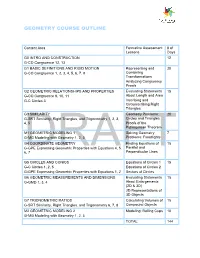
GEOMETRY COURSE OUTLINE Content Area Formative Assessment # of Lessons Days G0 INTRO AND CONSTRUCTION 12 G-CO Congruence 12, 13 G1 BASIC DEFINITIONS AND RIGID MOTION Representing and 20 G-CO Congruence 1, 2, 3, 4, 5, 6, 7, 8 Combining Transformations Analyzing Congruency Proofs G2 GEOMETRIC RELATIONSHIPS AND PROPERTIES Evaluating Statements 15 G-CO Congruence 9, 10, 11 About Length and Area G-C Circles 3 Inscribing and Circumscribing Right Triangles G3 SIMILARITY Geometry Problems: 20 G-SRT Similarity, Right Triangles, and Trigonometry 1, 2, 3, Circles and Triangles 4, 5 Proofs of the Pythagorean Theorem M1 GEOMETRIC MODELING 1 Solving Geometry 7 G-MG Modeling with Geometry 1, 2, 3 Problems: Floodlights G4 COORDINATE GEOMETRY Finding Equations of 15 G-GPE Expressing Geometric Properties with Equations 4, 5, Parallel and 6, 7 Perpendicular Lines G5 CIRCLES AND CONICS Equations of Circles 1 15 G-C Circles 1, 2, 5 Equations of Circles 2 G-GPE Expressing Geometric Properties with Equations 1, 2 Sectors of Circles G6 GEOMETRIC MEASUREMENTS AND DIMENSIONS Evaluating Statements 15 G-GMD 1, 3, 4 About Enlargements (2D & 3D) 2D Representations of 3D Objects G7 TRIONOMETRIC RATIOS Calculating Volumes of 15 G-SRT Similarity, Right Triangles, and Trigonometry 6, 7, 8 Compound Objects M2 GEOMETRIC MODELING 2 Modeling: Rolling Cups 10 G-MG Modeling with Geometry 1, 2, 3 TOTAL: 144 HIGH SCHOOL OVERVIEW Algebra 1 Geometry Algebra 2 A0 Introduction G0 Introduction and A0 Introduction Construction A1 Modeling With Functions G1 Basic Definitions and Rigid -
Dimension Guide
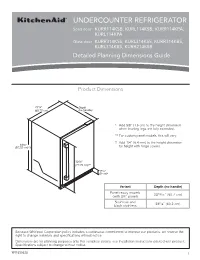
UNDERCOUNTER REFRIGERATOR Solid door KURR114KSB, KURL114KSB, KURR114KPA, KURL114KPA Glass door KURR314KSS, KURL314KSS, KURR314KBS, KURL314KBS, KURR214KSB Detailed Planning Dimensions Guide Product Dimensions 237/8” Depth (60.72 cm) (no handle) * Add 5/8” (1.6 cm) to the height dimension when leveling legs are fully extended. ** For custom panel models, this will vary. † Add 1/4” (6.4 mm) to the height dimension 343/8” (87.32 cm)*† for height with hinge covers. 305/8” (77.75 cm)** 39/16” (9 cm)* Variant Depth (no handle) Panel ready models 2313/16” (60.7 cm) (with 3/4” panel) Stainless and 235/8” (60.2 cm) black stainless Because Whirlpool Corporation policy includes a continuous commitment to improve our products, we reserve the right to change materials and specifications without notice. Dimensions are for planning purposes only. For complete details, see Installation Instructions packed with product. Specifications subject to change without notice. W11530525 1 Panel ready models Stainless and black Dimension Description (with 3/4” panel) stainless models A Width of door 233/4” (60.3 cm) 233/4” (60.3 cm) B Width of the grille 2313/16” (60.5 cm) 2313/16” (60.5 cm) C Height to top of handle ** 311/8” (78.85 cm) Width from side of refrigerator to 1 D handle – door open 90° ** 2 /3” (5.95 cm) E Depth without door 2111/16” (55.1 cm) 2111/16” (55.1 cm) F Depth with door 2313/16” (60.7 cm) 235/8” (60.2 cm) 7 G Depth with handle ** 26 /16” (67.15 cm) H Depth with door open 90° 4715/16” (121.8 cm) 4715/16” (121.8 cm) **For custom panel models, this will vary. -

Spectral Dimensions and Dimension Spectra of Quantum Spacetimes
PHYSICAL REVIEW D 102, 086003 (2020) Spectral dimensions and dimension spectra of quantum spacetimes † Michał Eckstein 1,2,* and Tomasz Trześniewski 3,2, 1Institute of Theoretical Physics and Astrophysics, National Quantum Information Centre, Faculty of Mathematics, Physics and Informatics, University of Gdańsk, ulica Wita Stwosza 57, 80-308 Gdańsk, Poland 2Copernicus Center for Interdisciplinary Studies, ulica Szczepańska 1/5, 31-011 Kraków, Poland 3Institute of Theoretical Physics, Jagiellonian University, ulica S. Łojasiewicza 11, 30-348 Kraków, Poland (Received 11 June 2020; accepted 3 September 2020; published 5 October 2020) Different approaches to quantum gravity generally predict that the dimension of spacetime at the fundamental level is not 4. The principal tool to measure how the dimension changes between the IR and UV scales of the theory is the spectral dimension. On the other hand, the noncommutative-geometric perspective suggests that quantum spacetimes ought to be characterized by a discrete complex set—the dimension spectrum. We show that these two notions complement each other and the dimension spectrum is very useful in unraveling the UV behavior of the spectral dimension. We perform an extended analysis highlighting the trouble spots and illustrate the general results with two concrete examples: the quantum sphere and the κ-Minkowski spacetime, for a few different Laplacians. In particular, we find that the spectral dimensions of the former exhibit log-periodic oscillations, the amplitude of which decays rapidly as the deformation parameter tends to the classical value. In contrast, no such oscillations occur for either of the three considered Laplacians on the κ-Minkowski spacetime. DOI: 10.1103/PhysRevD.102.086003 I. -

Effective Noether Irreducibility Forms and Applications*
Appears in Journal of Computer and System Sciences, 50/2 pp. 274{295 (1995). Effective Noether Irreducibility Forms and Applications* Erich Kaltofen Department of Computer Science, Rensselaer Polytechnic Institute Troy, New York 12180-3590; Inter-Net: [email protected] Abstract. Using recent absolute irreducibility testing algorithms, we derive new irreducibility forms. These are integer polynomials in variables which are the generic coefficients of a multivariate polynomial of a given degree. A (multivariate) polynomial over a specific field is said to be absolutely irreducible if it is irreducible over the algebraic closure of its coefficient field. A specific polynomial of a certain degree is absolutely irreducible, if and only if all the corresponding irreducibility forms vanish when evaluated at the coefficients of the specific polynomial. Our forms have much smaller degrees and coefficients than the forms derived originally by Emmy Noether. We can also apply our estimates to derive more effective versions of irreducibility theorems by Ostrowski and Deuring, and of the Hilbert irreducibility theorem. We also give an effective estimate on the diameter of the neighborhood of an absolutely irreducible polynomial with respect to the coefficient space in which absolute irreducibility is preserved. Furthermore, we can apply the effective estimates to derive several factorization results in parallel computational complexity theory: we show how to compute arbitrary high precision approximations of the complex factors of a multivariate integral polynomial, and how to count the number of absolutely irreducible factors of a multivariate polynomial with coefficients in a rational function field, both in the complexity class . The factorization results also extend to the case where the coefficient field is a function field. -

Zero-Dimensional Symmetry
Snapshots of modern mathematics № 3/2015 from Oberwolfach Zero-dimensional symmetry George Willis This snapshot is about zero-dimensional symmetry. Thanks to recent discoveries we now understand such symmetry better than previously imagined possible. While still far from complete, a picture of zero-dimen- sional symmetry is beginning to emerge. 1 An introduction to symmetry: spinning globes and infinite wallpapers Let’s begin with an example. Think of a sphere, for example a globe’s surface. Every point on it is specified by two parameters, longitude and latitude. This makes the sphere a two-dimensional surface. You can rotate the globe along an axis through the center; the object you obtain after the rotation still looks like the original globe (although now maybe New York is where the Mount Everest used to be), meaning that the sphere has rotational symmetry. Each rotation is prescribed by the latitude and longitude where the axis cuts the southern hemisphere, and by an angle through which it rotates the sphere. 1 These three parameters specify all rotations of the sphere, which thus has three-dimensional rotational symmetry. In general, a symmetry may be viewed as being a transformation (such as a rotation) that leaves an object looking unchanged. When one transformation is followed by a second, the result is a third transformation that is called the product of the other two. The collection of symmetries and their product 1 Note that we include the rotation through the angle 0, that is, the case where the globe actually does not rotate at all. 1 operation forms an algebraic structure called a group 2 . -
Creating a Revolve
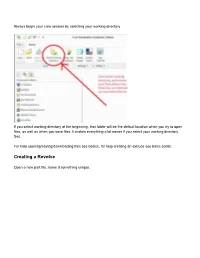
Always begin your creo session by selecting your working directory If you select working directory at the beginning, that folder will be the default location when you try to open files, as well as when you save files. It makes everything a lot easier if you select your working directory first. For help opening/saving/downloading files see basics, for help creating an extrude see basic solids. Creating a Revolve Open a new part file, name it something unique. Choose a plane to sketch on Go to sketch view (if you don’t know where that is see Basic Solids) Move your cursor so the centerline snaps to the horizontal line as shown above You may now begin your sketch I have just sketched a random shape Sketch Tips: ● Your shape MUST be closed ● If you didn’t put a centerline in, you will get radial instead of diameter dimensions (in general this is bad) ● Remember this is being revolved so you are only sketching the profile on one side of the center line. If you need to put in diameter dimensions: Click normal, click the line or point you want the dimension for, click the centerline, and click the same line/point that you clicked the first time AGAIN, and then middle mouse button where you want the dimension to be placed. After your sketch is done, click the checkmark to get out of sketch, then click the checkmark again to complete the revolve The part in the sketch will look like this: . -

Etienne Bézout on Elimination Theory Erwan Penchevre
Etienne Bézout on elimination theory Erwan Penchevre To cite this version: Erwan Penchevre. Etienne Bézout on elimination theory. 2017. hal-01654205 HAL Id: hal-01654205 https://hal.archives-ouvertes.fr/hal-01654205 Preprint submitted on 3 Dec 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Etienne Bézout on elimination theory ∗ Erwan Penchèvre Bézout’s name is attached to his famous theorem. Bézout’s Theorem states that the degree of the eliminand of a system a n algebraic equations in n unknowns, when each of the equations is generic of its degree, is the product of the degrees of the equations. The eliminand is, in the terms of XIXth century algebra1, an equation of smallest degree resulting from the elimination of (n − 1) unknowns. Bézout demonstrates his theorem in 1779 in a treatise entitled Théorie générale des équations algébriques. In this text, he does not only demonstrate the theorem for n > 2 for generic equations, but he also builds a classification of equations that allows a better bound on the degree of the eliminand when the equations are not generic. This part of his work is difficult: it appears incomplete and has been seldom studied. -

Simple Proof of the Main Theorem of Elimination Theory in Algebraic Geometry
SIMPLE PROOF OF THE MAIN THEOREM OF ELIMINATION THEORY IN ALGEBRAIC GEOMETRY Autor(en): Cartier, P. / Tate, J. Objekttyp: Article Zeitschrift: L'Enseignement Mathématique Band (Jahr): 24 (1978) Heft 1-2: L'ENSEIGNEMENT MATHÉMATIQUE PDF erstellt am: 10.10.2021 Persistenter Link: http://doi.org/10.5169/seals-49707 Nutzungsbedingungen Die ETH-Bibliothek ist Anbieterin der digitalisierten Zeitschriften. Sie besitzt keine Urheberrechte an den Inhalten der Zeitschriften. Die Rechte liegen in der Regel bei den Herausgebern. Die auf der Plattform e-periodica veröffentlichten Dokumente stehen für nicht-kommerzielle Zwecke in Lehre und Forschung sowie für die private Nutzung frei zur Verfügung. Einzelne Dateien oder Ausdrucke aus diesem Angebot können zusammen mit diesen Nutzungsbedingungen und den korrekten Herkunftsbezeichnungen weitergegeben werden. Das Veröffentlichen von Bildern in Print- und Online-Publikationen ist nur mit vorheriger Genehmigung der Rechteinhaber erlaubt. Die systematische Speicherung von Teilen des elektronischen Angebots auf anderen Servern bedarf ebenfalls des schriftlichen Einverständnisses der Rechteinhaber. Haftungsausschluss Alle Angaben erfolgen ohne Gewähr für Vollständigkeit oder Richtigkeit. Es wird keine Haftung übernommen für Schäden durch die Verwendung von Informationen aus diesem Online-Angebot oder durch das Fehlen von Informationen. Dies gilt auch für Inhalte Dritter, die über dieses Angebot zugänglich sind. Ein Dienst der ETH-Bibliothek ETH Zürich, Rämistrasse 101, 8092 Zürich, Schweiz, www.library.ethz.ch http://www.e-periodica.ch A SIMPLE PROOF OF THE MAIN THEOREM OF ELIMINATION THEORY IN ALGEBRAIC GEOMETRY by P. Cartier and J. Tate Summary The purpose of this note is to provide a simple proof (which we believe to be new) for the weak zero theorem in the case of homogeneous polynomials. -

Why Observable Space Is Three Dimensional
Adv. Studies Theor. Phys., Vol. 8, 2014, no. 17, 689 – 700 HIKARI Ltd, www.m-hikari.com http://dx.doi.org/10.12988/astp.2014.4675 Why Observable Space Is Solely Three Dimensional Mario Rabinowitz Armor Research, 715 Lakemead Way Redwood City, CA 94062-3922, USA Copyright © 2014 Mario Rabinowitz. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Quantum (and classical) binding energy considerations in n-dimensional space indicate that atoms (and planets) can only exist in three-dimensional space. This is why observable space is solely 3-dimensional. Both a novel Virial theorem analysis, and detailed classical and quantum energy calculations for 3-space circular and elliptical orbits indicate that they have no orbital binding energy in greater than 3-space. The same energy equation also excludes the possibility of atom-like bodies in strictly 1 and 2-dimensions. A prediction is made that in the search for deviations from r2 of the gravitational force at sub-millimeter distances such a deviation must occur at < ~ 1010m (or < ~1012 m considering muoniom), since atoms would disintegrate if the curled up dimensions of string theory were larger than this. Callender asserts that the often-repeated claim in previous work that stable orbits are possible in only three dimensions is not even remotely established. The binding energy analysis herein avoids the pitfalls that Callender points out, as it circumvents stability issues. An uncanny quantum surprise is present in very high dimensions. -

Triangle Identities Via Elimination Theory
Triangle Identities via Elimination Theory Dam Van Nhi and Luu Ba Thang Abstract The aim of this paper is to present some new identities via resultants and elimination theory, by presenting the sidelengths, the lengths of the altitudes and the exradii of a triangle as roots of cubic polynomials. 1 Introduction Finding identities between elements of a triangle represents a classical topic in elementary geometry. In Recent Advances in Geometric Inequalities [3], Mitrinovic et al presents the sidelengths, the lengths of the altitudes and the various radii as roots of cubic polynomials, and collects many interesting equalities and inequalities between these quantities. As far as we know, almost of them are built using only elementary algebra and geometry. In this paper, we use transformations of rational functions and resultants to build similar nice equalities and inequalities might be difficult to prove with different methods. 2 Main results To fix notations, suppose we are given a triangle ∆ABC with sidelengh a; b; c. Denote the radius of the circumcircle by R, the radius of incircle by r, the area of ∆ABC by S, the semiperimeter as p, the radii of the excircles as r1; r2; r3, and the altitudes from sides a; b and c, respectively, as ha; hb and hc. We have the results from [3, Chapter 1]. Theorem 1. [3] Using the above notations, (i) a; b; c are the roots of the cubic polynomial x3 − 2px2 + (p2 + r2 + 4Rr)x − 4Rrp: (1) (ii) ha; hb; hc are the roots of the cubic polynomial S2 + 4Rr3 + r4 2S2 2S2 x3 − x2 + x − : (2) 2Rr2 Rr R (iii) r1; r2; r3 are the roots of the cubic polynomial x3 − (4R + r)x2 + p2x − p2r: (3) Next, we present how to use transformations of rational functions to build new geometric equalities ax + b and inequalities. -

Dimension Theory: Road to the Forth Dimension and Beyond
Dimension Theory: Road to the Fourth Dimension and Beyond 0-dimension “Behold yon miserable creature. That Point is a Being like ourselves, but confined to the non-dimensional Gulf. He is himself his own World, his own Universe; of any other than himself he can form no conception; he knows not Length, nor Breadth, nor Height, for he has had no experience of them; he has no cognizance even of the number Two; nor has he a thought of Plurality, for he is himself his One and All, being really Nothing. Yet mark his perfect self-contentment, and hence learn this lesson, that to be self-contented is to be vile and ignorant, and that to aspire is better than to be blindly and impotently happy.” ― Edwin A. Abbott, Flatland: A Romance of Many Dimensions 0-dimension Space of zero dimensions: A space that has no length, breadth or thickness (no length, height or width). There are zero degrees of freedom. The only “thing” is a point. = ∅ 0-dimension 1-dimension Space of one dimension: A space that has length but no breadth or thickness A straight or curved line. Drag a multitude of zero dimensional points in new (perpendicular) direction Make a “line” of points 1-dimension One degree of freedom: Can only move right/left (forwards/backwards) { }, any point on the number line can be described by one number 1-dimension How to visualize living in 1-dimension Stuck on an endless one-lane one-way road Inhabitants: points and line segments (intervals) Live forever between your front and back neighbor.