CUBE-Final Copy
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

On the Archimedean Or Semiregular Polyhedra
ON THE ARCHIMEDEAN OR SEMIREGULAR POLYHEDRA Mark B. Villarino Depto. de Matem´atica, Universidad de Costa Rica, 2060 San Jos´e, Costa Rica May 11, 2005 Abstract We prove that there are thirteen Archimedean/semiregular polyhedra by using Euler’s polyhedral formula. Contents 1 Introduction 2 1.1 RegularPolyhedra .............................. 2 1.2 Archimedean/semiregular polyhedra . ..... 2 2 Proof techniques 3 2.1 Euclid’s proof for regular polyhedra . ..... 3 2.2 Euler’s polyhedral formula for regular polyhedra . ......... 4 2.3 ProofsofArchimedes’theorem. .. 4 3 Three lemmas 5 3.1 Lemma1.................................... 5 3.2 Lemma2.................................... 6 3.3 Lemma3.................................... 7 4 Topological Proof of Archimedes’ theorem 8 arXiv:math/0505488v1 [math.GT] 24 May 2005 4.1 Case1: fivefacesmeetatavertex: r=5. .. 8 4.1.1 At least one face is a triangle: p1 =3................ 8 4.1.2 All faces have at least four sides: p1 > 4 .............. 9 4.2 Case2: fourfacesmeetatavertex: r=4 . .. 10 4.2.1 At least one face is a triangle: p1 =3................ 10 4.2.2 All faces have at least four sides: p1 > 4 .............. 11 4.3 Case3: threefacesmeetatavertes: r=3 . ... 11 4.3.1 At least one face is a triangle: p1 =3................ 11 4.3.2 All faces have at least four sides and one exactly four sides: p1 =4 6 p2 6 p3. 12 4.3.3 All faces have at least five sides and one exactly five sides: p1 =5 6 p2 6 p3 13 1 5 Summary of our results 13 6 Final remarks 14 1 Introduction 1.1 Regular Polyhedra A polyhedron may be intuitively conceived as a “solid figure” bounded by plane faces and straight line edges so arranged that every edge joins exactly two (no more, no less) vertices and is a common side of two faces. -

Graph Theory
1 Graph Theory “Begin at the beginning,” the King said, gravely, “and go on till you come to the end; then stop.” — Lewis Carroll, Alice in Wonderland The Pregolya River passes through a city once known as K¨onigsberg. In the 1700s seven bridges were situated across this river in a manner similar to what you see in Figure 1.1. The city’s residents enjoyed strolling on these bridges, but, as hard as they tried, no residentof the city was ever able to walk a route that crossed each of these bridges exactly once. The Swiss mathematician Leonhard Euler learned of this frustrating phenomenon, and in 1736 he wrote an article [98] about it. His work on the “K¨onigsberg Bridge Problem” is considered by many to be the beginning of the field of graph theory. FIGURE 1.1. The bridges in K¨onigsberg. J.M. Harris et al., Combinatorics and Graph Theory , DOI: 10.1007/978-0-387-79711-3 1, °c Springer Science+Business Media, LLC 2008 2 1. Graph Theory At first, the usefulness of Euler’s ideas and of “graph theory” itself was found only in solving puzzles and in analyzing games and other recreations. In the mid 1800s, however, people began to realize that graphs could be used to model many things that were of interest in society. For instance, the “Four Color Map Conjec- ture,” introduced by DeMorgan in 1852, was a famous problem that was seem- ingly unrelated to graph theory. The conjecture stated that four is the maximum number of colors required to color any map where bordering regions are colored differently. -

Archimedean Solids
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln MAT Exam Expository Papers Math in the Middle Institute Partnership 7-2008 Archimedean Solids Anna Anderson University of Nebraska-Lincoln Follow this and additional works at: https://digitalcommons.unl.edu/mathmidexppap Part of the Science and Mathematics Education Commons Anderson, Anna, "Archimedean Solids" (2008). MAT Exam Expository Papers. 4. https://digitalcommons.unl.edu/mathmidexppap/4 This Article is brought to you for free and open access by the Math in the Middle Institute Partnership at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in MAT Exam Expository Papers by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Archimedean Solids Anna Anderson In partial fulfillment of the requirements for the Master of Arts in Teaching with a Specialization in the Teaching of Middle Level Mathematics in the Department of Mathematics. Jim Lewis, Advisor July 2008 2 Archimedean Solids A polygon is a simple, closed, planar figure with sides formed by joining line segments, where each line segment intersects exactly two others. If all of the sides have the same length and all of the angles are congruent, the polygon is called regular. The sum of the angles of a regular polygon with n sides, where n is 3 or more, is 180° x (n – 2) degrees. If a regular polygon were connected with other regular polygons in three dimensional space, a polyhedron could be created. In geometry, a polyhedron is a three- dimensional solid which consists of a collection of polygons joined at their edges. The word polyhedron is derived from the Greek word poly (many) and the Indo-European term hedron (seat). -

Graph Mining: Social Network Analysis and Information Diffusion
Graph Mining: Social network analysis and Information Diffusion Davide Mottin, Konstantina Lazaridou Hasso Plattner Institute Graph Mining course Winter Semester 2016 Lecture road Introduction to social networks Real word networks’ characteristics Information diffusion GRAPH MINING WS 2016 2 Paper presentations ▪ Link to form: https://goo.gl/ivRhKO ▪ Choose the date(s) you are available ▪ Choose three papers according to preference (there are three lists) ▪ Choose at least one paper for each course part ▪ Register to the mailing list: https://lists.hpi.uni-potsdam.de/listinfo/graphmining-ws1617 GRAPH MINING WS 2016 3 What is a social network? ▪Oxford dictionary A social network is a network of social interactions and personal relationships GRAPH MINING WS 2016 4 What is an online social network? ▪ Oxford dictionary An online social network (OSN) is a dedicated website or other application, which enables users to communicate with each other by posting information, comments, messages, images, etc. ▪ Computer science : A network that consists of a finite number of users (nodes) that interact with each other (edges) by sharing information (labels, signs, edge directions etc.) GRAPH MINING WS 2016 5 Definitions ▪Vertex/Node : a user of the social network (Twitter user, an author in a co-authorship network, an actor etc.) ▪Edge/Link/Tie : the connection between two vertices referring to their relationship or interaction (friend-of relationship, re-tweeting activity, etc.) Graph G=(V,E) symbols meaning V users E connections deg(u) node degree: -

1 Bipartite Matching and Vertex Covers
ORF 523 Lecture 6 Princeton University Instructor: A.A. Ahmadi Scribe: G. Hall Any typos should be emailed to a a [email protected]. In this lecture, we will cover an application of LP strong duality to combinatorial optimiza- tion: • Bipartite matching • Vertex covers • K¨onig'stheorem • Totally unimodular matrices and integral polytopes. 1 Bipartite matching and vertex covers Recall that a bipartite graph G = (V; E) is a graph whose vertices can be divided into two disjoint sets such that every edge connects one node in one set to a node in the other. Definition 1 (Matching, vertex cover). A matching is a disjoint subset of edges, i.e., a subset of edges that do not share a common vertex. A vertex cover is a subset of the nodes that together touch all the edges. (a) An example of a bipartite (b) An example of a matching (c) An example of a vertex graph (dotted lines) cover (grey nodes) Figure 1: Bipartite graphs, matchings, and vertex covers 1 Lemma 1. The cardinality of any matching is less than or equal to the cardinality of any vertex cover. This is easy to see: consider any matching. Any vertex cover must have nodes that at least touch the edges in the matching. Moreover, a single node can at most cover one edge in the matching because the edges are disjoint. As it will become clear shortly, this property can also be seen as an immediate consequence of weak duality in linear programming. Theorem 1 (K¨onig). If G is bipartite, the cardinality of the maximum matching is equal to the cardinality of the minimum vertex cover. -

An Enduring Error
Version June 5, 2008 Branko Grünbaum: An enduring error 1. Introduction. Mathematical truths are immutable, but mathematicians do make errors, especially when carrying out non-trivial enumerations. Some of the errors are "innocent" –– plain mis- takes that get corrected as soon as an independent enumeration is carried out. For example, Daublebsky [14] in 1895 found that there are precisely 228 types of configurations (123), that is, collections of 12 lines and 12 points, each incident with three of the others. In fact, as found by Gropp [19] in 1990, the correct number is 229. Another example is provided by the enumeration of the uniform tilings of the 3-dimensional space by Andreini [1] in 1905; he claimed that there are precisely 25 types. However, as shown [20] in 1994, the correct num- ber is 28. Andreini listed some tilings that should not have been included, and missed several others –– but again, these are simple errors easily corrected. Much more insidious are errors that arise by replacing enumeration of one kind of ob- ject by enumeration of some other objects –– only to disregard the logical and mathematical distinctions between the two enumerations. It is surprising how errors of this type escape detection for a long time, even though there is frequent mention of the results. One example is provided by the enumeration of 4-dimensional simple polytopes with 8 facets, by Brückner [7] in 1909. He replaces this enumeration by that of 3-dimensional "diagrams" that he inter- preted as Schlegel diagrams of convex 4-polytopes, and claimed that the enumeration of these objects is equivalent to that of the polytopes. -

A Multigraph Approach to Social Network Analysis
1 Introduction Network data involving relational structure representing interactions between actors are commonly represented by graphs where the actors are referred to as vertices or nodes, and the relations are referred to as edges or ties connecting pairs of actors. Research on social networks is a well established branch of study and many issues concerning social network analysis can be found in Wasserman and Faust (1994), Carrington et al. (2005), Butts (2008), Frank (2009), Kolaczyk (2009), Scott and Carrington (2011), Snijders (2011), and Robins (2013). A common approach to social network analysis is to only consider binary relations, i.e. edges between pairs of vertices are either present or not. These simple graphs only consider one type of relation and exclude the possibility for self relations where a vertex is both the sender and receiver of an edge (also called edge loops or just shortly loops). In contrast, a complex graph is defined according to Wasserman and Faust (1994): If a graph contains loops and/or any pairs of nodes is adjacent via more than one line the graph is complex. [p. 146] In practice, simple graphs can be derived from complex graphs by collapsing the multiple edges into single ones and removing the loops. However, this approach discards information inherent in the original network. In order to use all available network information, we must allow for multiple relations and the possibility for loops. This leads us to the study of multigraphs which has not been treated as extensively as simple graphs in the literature. As an example, consider a network with vertices representing different branches of an organ- isation. -
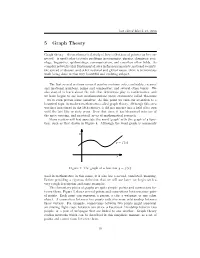
5 Graph Theory
last edited March 21, 2016 5 Graph Theory Graph theory – the mathematical study of how collections of points can be con- nected – is used today to study problems in economics, physics, chemistry, soci- ology, linguistics, epidemiology, communication, and countless other fields. As complex networks play fundamental roles in financial markets, national security, the spread of disease, and other national and global issues, there is tremendous work being done in this very beautiful and evolving subject. The first several sections covered number systems, sets, cardinality, rational and irrational numbers, prime and composites, and several other topics. We also started to learn about the role that definitions play in mathematics, and we have begun to see how mathematicians prove statements called theorems – we’ve even proven some ourselves. At this point we turn our attention to a beautiful topic in modern mathematics called graph theory. Although this area was first introduced in the 18th century, it did not mature into a field of its own until the last fifty or sixty years. Over that time, it has blossomed into one of the most exciting, and practical, areas of mathematical research. Many readers will first associate the word ‘graph’ with the graph of a func- tion, such as that drawn in Figure 4. Although the word graph is commonly Figure 4: The graph of a function y = f(x). used in mathematics in this sense, it is also has a second, unrelated, meaning. Before providing a rigorous definition that we will use later, we begin with a very rough description and some examples. -

Chapter 2 Figures and Shapes 2.1 Polyhedron in N-Dimension in Linear
Chapter 2 Figures and Shapes 2.1 Polyhedron in n-dimension In linear programming we know about the simplex method which is so named because the feasible region can be decomposed into simplexes. A zero-dimensional simplex is a point, an 1D simplex is a straight line segment, a 2D simplex is a triangle, a 3D simplex is a tetrahedron. In general, a n-dimensional simplex has n+1 vertices not all contained in a (n-1)- dimensional hyperplane. Therefore simplex is the simplest building block in the space it belongs. An n-dimensional polyhedron can be constructed from simplexes with only possible common face as their intersections. Such a definition is a bit vague and such a figure need not be connected. Connected polyhedron is the prototype of a closed manifold. We may use vertices, edges and faces (hyperplanes) to define a polyhedron. A polyhedron is convex if all convex linear combinations of the vertices Vi are inside itself, i.e. i Vi is contained inside for all i 0 and all _ i i 1. i If a polyhedron is not convex, then the smallest convex set which contains it is called the convex hull of the polyhedron. Separating hyperplane Theorem For any given point outside a convex set, there exists a hyperplane with this given point on one side of it and the entire convex set on the other. Proof: Because the given point will be outside one of the supporting hyperplanes of the convex set. 2.2 Platonic Solids Known to Plato (about 500 B.C.) and explained in the Elements (Book XIII) of Euclid (about 300 B.C.), these solids are governed by the rules that the faces are the regular polygons of a single species and the corners (vertices) are all alike. -

A Note on Light Geometric Graphs
A note on light geometric graphs Eyal Ackerman∗ Jacob Foxy Rom Pinchasiz March 19, 2012 Abstract Let G be a geometric graph on n vertices in general position in the plane. We say that G is k-light if no edge e of G has the property that each of the two open half-planes bounded by the line through e contains more than k edges of G. We extend the previous result in [1] and withp a shorter argument show that every k-light geometric graph on n vertices has at most O(n k) edges. This bound is best possible. Keywords: Geometric graphs, k-near bipartite. 1 Introduction Let G be an n-vertex geometric graph. That is, G is a graph drawn in the plane such that its vertices are distinct points and its edges are straight-line segments connecting corresponding vertices. It is usually assumed, as we will assume in this paper, that the set of vertices of G is in general position in the sense that no three of them lie on a line. A typical question in geometric graph theory asks for the maximum number of edges that a geometric graph on n vertices can have assuming a forbidden configuration in that graph. This is a popular area of study extending classical extremal graph theory, utilizing diverse tools from both geometry and combinatorics. For example, an old result of Hopf and Pannwitz [3] and independently Sutherland [7] states that any geometric graph on n vertices with no pair of disjoint edges has at most n edges. -

6.1 Directed Acyclic Graphs 6.2 Trees
6.1 Directed Acyclic Graphs Directed acyclic graphs, or DAGs are acyclic directed graphs where vertices can be ordered in such at way that no vertex has an edge that points to a vertex earlier in the order. This also implies that we can permute the adjacency matrix in a way that it has only zeros on and below the diagonal. This is a strictly upper triangular matrix. Arranging vertices in such a way is referred to in computer science as topological sorting. Likewise, consider if we performed a strongly connected components (SCC) decomposition, contracted each SCC into a single vertex, and then topologically sorted the graph. If we order vertices within each SCC based on that SCC's order in the contracted graph, the resulting adjacency matrix will have the SCCs in \blocks" along the diagonal. This could be considered a block triangular matrix. 6.2 Trees A graph with no cycle is acyclic.A forest is an acyclic graph. A tree is a connected undirected acyclic graph. If the underlying graph of a DAG is a tree, then the graph is a polytree.A leaf is a vertex of degree one. Every tree with at least two vertices has at least two leaves. A spanning subgraph of G is a subgraph that contains all vertices. A spanning tree is a spanning subgraph that is a tree. All graphs contain at least one spanning tree. Necessary properties of a tree T : 1. T is (minimally) connected 2. T is (maximally) acyclic 3. T has n − 1 edges 4. T has a single u; v-path 8u; v 2 V (T ) 5. -

Line Graphs Math 381 — Spring 2011 Since Edges Are So Important to a Graph, Sometimes We Want to Know How Much of the Graph Is
Line Graphs Math 381 | Spring 2011 Since edges are so important to a graph, sometimes we want to know how much of the graph is determined by its edges. There are a couple of ways to make this a precise question. The one we'll talk about is this: You know the edge set; you don't know the vertices of the edges; but you do know which edges are adjacent (that means they have a common vertex in G). That is, you know adjacency of edges of G. In other words, you have a graph whose vertices are the edges and whose edges tell you which edges (of the original graph G) are adjacent. This graph is the line graph, L(G). Formal definition: L(G) is the graph such that V (L(G)) := E(G) and in which e; f 2 E(G) are adjacent (as vertices of L(G)) if and only if they are adjacent edges in G. The name comes from the fact that "line" is another name for "edge"; the line graph is the graph of relations between edges. Note that the vertices of G do not appear in L(G). Exercise LG.1. What is the line graph of K4? What is L(K4)? What is L(K4)? Is either one of them a graph we've seen before? Here is the solution. K K L K 4 4 with ( 4) v v 1 1 e e 14 13 e e 14 e 12 12 e v v v v 13 4 2 4 2 e e 24 e 24 e e 23 23 34 e 34 v v 3 3 L( K ) L( K ) redrawn Complement 4 4 L K of ( 4) e e e e e 14 e 14 12 14 12 12 e e e 13 13 13 e e e 24 24 24 e 23 e e e e e 34 34 23 34 23 Notice that the complement of L(K4) is very simple: it's a 1-factor of K6.