“Housekeeping”
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Daniel D. Garcia
DANIEL D. GARCIA [email protected] http://www.cs.berkeley.edu/~ddgarcia/ 777 Soda Hall #1776 UC Berkeley Berkeley, CA 94720-1776 (510) 517-4041 ______________________________________________________ EDUCATION MASSACHUSETTS INSTITUTE OF TECHNOLOGY Cambridge, MA B.S. in Computer Science, 1990 B.S. in Electrical Engineering, 1990 UNIVERSITY OF CALIFORNIA, BERKELEY Berkeley, CA M.S. in Computer Science, 1995 Ph.D. in Computer Science, 2000. Area: computer graphics and scientific visualization. Brian Barsky, advisor. TEACHING AWARDS • Outstanding Graduate Student Instructor in Computer Science (1992) • Electrical Engineering and Computer Science Outstanding Graduate Student Instructor (1997) • Computer Science Division Diane S. McEntyre Award for Excellence in Teaching (2002) • Computer Science Division IT Faculty Award for Excellence in Undergraduate Teaching (2005) • UC Berkeley “Everyday Hero” Award (2005) • Highest “teaching effectiveness” rating for any EECS lower division instructor, ever (6.7, since tied) (2006) • CS10: The Beauty and Joy of Computing chosen as 1 of 5 national pilots for AP CS: Principles course (2010) • CS10: The Beauty and Joy of Computing chosen as a University of California Online Course Pilot (2011) • Association of Computing Machinery (ACM) Distinguished Educator (2012) • Top 5 Professors to Take Classes with at UC Berkeley, The Black Sheep Online (2013) • CS10 becomes first introductory computing class at UC Berkeley with > 50% women (2013,2014) • Ten Most Popular MOOCs Starting in September 2015 and January 2016, Class Central (2015, 2016) • LPFI's Lux Award for being “Tech Diversity Champion” (2015) • NCWIT’s Undergraduate Research Mentoring (URM) Award (2016) • NCWIT’s Extension Services Transformation Award, Honorable Mention (2016) • CS10 becomes first introductory computing class at UC Berkeley with > 60% women (2017) • SAP Visionary Member Award (2017) • Google CS4HS Ambassador (2017) • CS10 becomes first introductory computing class at UC Berkeley with > 65% women (2018) Updated through 2018-07-01 1 / 28 Daniel D. -

ACM Education Board and Education Council FY2017-2018 Executive
ACM Education Board and Education Council FY2017-2018 Executive Summary This report summarizes the activities of the ACM Education Board and the Education Council1 in FY 2017-18 and outlines priorities for the coming year. Major accomplishments for this past year include the following: Curricular Volumes: Joint Taskforce on Cybersecurity Education CC2020 Completed: Computer Engineering Curricular Guidelines 2016 (CE2016) Enterprise Information Technology Body of Knowledge (EITBOK) Information Technology 2017 (IT2017) Masters of Science in Information Systems 2016 (MSIS2016) International Efforts: Educational efforts in China Educational efforts in Europe/Informatics for All Taskforces and Other Projects: Retention taskforce Learning at Scale Informatics for All Committee International Education Taskforce Global Awareness Taskforce Data Science Taskforce Education Policy Committee NDC Study Activities and Engagements with ACM SIGs and Other Groups: CCECC Code.org CSTA 1 The ACM Education Council was re-named in fall 2018 to the ACM Education Advisory Committee. For historical accuracy, the EAC will be called the Education Council for this report. 1 SIGCAS SIGCHI SIGCSE SIGHPC SIGGRAPH SIGITE Other Items: Education Board Rotation Education Council Rotation Future Initiatives Global Awareness Taskforce International Education Framework Highlights This is a very short list of the many accomplishments of the year. For full view of the work to date, please see Section One: Summary of FY 2017-2018 Activities. Diversity Taskforce: The Taskforce expects to complete its work by early 2019. Their goals of Exploring the data challenges Identifying factors contributing to the leaky pipeline Recommending potential interventions to improve retention Learning at Scale: The Fifth Annual ACM Conference on Learning @ Scale (L@S) was held in London, UK on June 26-28, 2018. -

Candidate for Chair Jeffrey K. Hollingsworth University Of
Candidate for Chair Jeffrey K. Hollingsworth University of Maryland, College Park, MD, USA BIOGRAPHY Academic Background: Ph.D., University of Wisconsin, 1994, Computer Sciences. Professional Experience: Professor, University of Maryland, College Park, MD, 2006 – Present; Associate /Assistant Professor, University of Maryland, College Park, MD, 1994 – 2006; Visiting Scientist, IBM, TJ Watson Research Center, 2000 – 2001. Professional Interest: Parallel Computing; Performance Measurement Tools; Auto-tuning; Binary Instrumentation; Computer Security. ACM Activities: Vice Chair, SIGHPC, 2011 – Present; Member, ACM Committee on Future of SIGs, 2014 – 2015; General Chair, SC Conference, 2012; Steering Committee Member (and Chair '13), SC Conference, 2009 – 2014. Membership and Offices in Related Organizations: Editor in Chief, PARCO, 2009 – Present; Program Chair, IPDPS, 2016; Board Member, Computing Research Association (CRA), 2008 – 2010. Awards Received: IPDPS, Best Paper - Software, 2011; SC, Best Paper - Student lead Author, 2005; IPDPS, Best Paper - Software, 2000. STATEMENT There is a critical need for a strong SIGHPC. Until SIGHPC was founded five years ago, the members of the HPC community lacked a home within ACM. While the SC conference provides a nexus for HPC activity in the fall, we needed a full-time community. Now that the initial transition of the SC conference from SIGARCH to SIGHPC is nearly complete, the time is right to start considering what other meetings and activities SIGHPC should undertake. We need to carefully identify meetings to sponsor or co-sponsor. Also, SIGHPC needs to continue and expand its role as a voice for the HPC community. This includes mentoring young professionals, actively identifying and nominating members for society wide awards, and speaking for the HPC community within both the scientific community and society at large. -

2017 ALCF Operational Assessment Report
ANL/ALCF-20/04 2017 Operational Assessment Report ARGONNE LEADERSHIP COMPUTING FACILITY On the cover: This visualization shows a small portion of a cosmology simulation tracing structure formation in the universe. The gold-colored clumps are high-density regions of dark matter that host galaxies in the real universe. This BorgCube simulation was carried out on Argonne National Laboratory’s Theta supercomputer as part of the Theta Early Science Program. Image: Joseph A. Insley, Silvio Rizzi, and the HACC team, Argonne National Laboratory Contents Executive Summary ................................................................................................ ES-1 Section 1. User Support Results .............................................................................. 1-1 ALCF Response ........................................................................................................................... 1-1 Survey Approach ................................................................................................................ 1-2 1.1 User Support Metrics .......................................................................................................... 1-3 1.2 Problem Resolution Metrics ............................................................................................... 1-4 1.3 User Support and Outreach ................................................................................................. 1-5 1.3.1 Tier 1 Support ........................................................................................................ -

Daniel Andresen
Daniel Andresen Professor, Department of Computer Science Director, Institute for Computational Research in Engineering and Science Michelle Munson-Serban Simu Keystone Research Scholar Kansas State University 2174 Engineering Hall Manhattan, KS 66506-2302 Tel: 785–532–6350 Fax: 785–532–7353 Email: [email protected] WWW: http://www.cis.ksu.edu/∼dan EDUCATION Ph.D., Computer Science, University of California, Santa Barbara, CA. September, 1997 Thesis Title: “SWEB++: Distributed Scheduling and Software Support for High Performance WWW Applications.” Advisor: Prof. Tao Yang M.S., Computer Science, California Polytechnic State University, San Luis Obispo, CA. September, 1992. B.S., Computer Science and Mathematics, double major, magna cum laude, honors in major, Westmont College, Santa Barbara, CA. May, 1990. AWARDS Michelle Munson-Serban Simu Keystone Research Scholar September, 2020 NSF CAREER Award 2001 KSU Engineering Student Council Outstanding Leadership Award December, 2004, 2005, 2008 Residencehall’sProfessoroftheYearnominee 2000,2002 Cargill Faculty Fellow 1999, 2000 College of Engg. James L. Hollis Memorial Award for Excellence in Undergrad- uate Teaching nominee 1999, 2006 RESEARCH Parallel and distributed systems, HPC scheduling, Research Cyberinfrastructure, INTERESTS digital libraries/WWW applications, Grid/cloud computing, and scientific mod- eling. TEACHING Graduate-level parallel/distributed computing, scientific computing, networking, INTERESTS operating systems, and computer architectures. Courses taught include operat- ing systems (CIS520), Topics in Distributed Systems (CIS825), Introduction to Computer Architecture (CIS450), Software Engineering (CIS642), Web Interface Design (CIS526), and Advanced World Wide Web Technologies (CIS726). 1 WORK Professor in the Department of Computing and Information Sciences at EXPERIENCE Kansas State University. 2015-present Associate Professor in the Department of Computing and Information SciencesatKansasStateUniversity. -
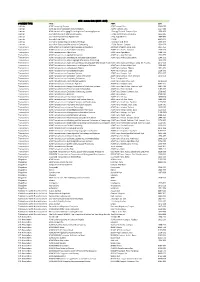
A ACM Transactions on Trans. 1553 TITLE ABBR ISSN ACM Computing Surveys ACM Comput. Surv. 0360‐0300 ACM Journal
ACM - zoznam titulov (2016 - 2019) CONTENT TYPE TITLE ABBR ISSN Journals ACM Computing Surveys ACM Comput. Surv. 0360‐0300 Journals ACM Journal of Computer Documentation ACM J. Comput. Doc. 1527‐6805 Journals ACM Journal on Emerging Technologies in Computing Systems J. Emerg. Technol. Comput. Syst. 1550‐4832 Journals Journal of Data and Information Quality J. Data and Information Quality 1936‐1955 Journals Journal of Experimental Algorithmics J. Exp. Algorithmics 1084‐6654 Journals Journal of the ACM J. ACM 0004‐5411 Journals Journal on Computing and Cultural Heritage J. Comput. Cult. Herit. 1556‐4673 Journals Journal on Educational Resources in Computing J. Educ. Resour. Comput. 1531‐4278 Transactions ACM Letters on Programming Languages and Systems ACM Lett. Program. Lang. Syst. 1057‐4514 Transactions ACM Transactions on Accessible Computing ACM Trans. Access. Comput. 1936‐7228 Transactions ACM Transactions on Algorithms ACM Trans. Algorithms 1549‐6325 Transactions ACM Transactions on Applied Perception ACM Trans. Appl. Percept. 1544‐3558 Transactions ACM Transactions on Architecture and Code Optimization ACM Trans. Archit. Code Optim. 1544‐3566 Transactions ACM Transactions on Asian Language Information Processing 1530‐0226 Transactions ACM Transactions on Asian and Low‐Resource Language Information Proce ACM Trans. Asian Low‐Resour. Lang. Inf. Process. 2375‐4699 Transactions ACM Transactions on Autonomous and Adaptive Systems ACM Trans. Auton. Adapt. Syst. 1556‐4665 Transactions ACM Transactions on Computation Theory ACM Trans. Comput. Theory 1942‐3454 Transactions ACM Transactions on Computational Logic ACM Trans. Comput. Logic 1529‐3785 Transactions ACM Transactions on Computer Systems ACM Trans. Comput. Syst. 0734‐2071 Transactions ACM Transactions on Computer‐Human Interaction ACM Trans. -
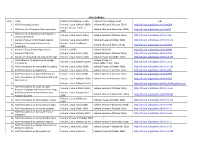
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1 (March 1969) Volume 49 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J204 Volume 24 Issue 1 (Feb. 1, 2. ACM Journal of Computer Documentation Volume 26 Issue 4 (November 2002) http://dl.acm.org/citation.cfm?id=J24 2000) ACM Journal on Emerging Technologies in 3. Volume 1 Issue 1 (April 2005) Volume 13 Issue 2 (October 2016) http://dl.acm.org/citation.cfm?id=J967 Computing Systems 4. Journal of Data and Information Quality Volume 1 Issue 1 (June 2009) Volume 8 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1191 Journal on Educational Resources in Volume 1 Issue 1es (March 5. Volume 16 Issue 2 (March 2016) http://dl.acm.org/citation.cfm?id=J814 Computing 2001) 6. Journal of Experimental Algorithmics Volume 1 (1996) Volume 21 (2016) http://dl.acm.org/citation.cfm?id=J430 7. Journal of the ACM Volume 1 Issue 1 (Jan. 1954) Volume 63 Issue 4 (October 2016) http://dl.acm.org/citation.cfm?id=J401 8. Journal on Computing and Cultural Heritage Volume 1 Issue 1 (June 2008) Volume 9 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J1157 ACM Letters on Programming Languages Volume 2 Issue 1-4 9. Volume 1 Issue 1 (March 1992) http://dl.acm.org/citation.cfm?id=J513 and Systems (March–Dec. 1993) 10. ACM Transactions on Accessible Computing Volume 1 Issue 1 (May 2008) Volume 9 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1156 11. -

Conference Program
The International Conference for High Performance Computing, Networking, Storage and Analysis Sponsors: Conference Program Colorado Convention Center Conference Dates: November 12-17, 2017 Exhibition Dates: November 13-16, 2017 General Information Registration and Conference Store The registration area and conference store are located in Lobby F. They will be open during the following days and hours: Day Date Hours Saturday November 11 1pm – 6pm Sunday November 12 7am – 6pm Monday November 13 7am – 9pm Tuesday November 14 7:30am – 6pm Wednesday November 15 7:30am – 6pm Thursday November 16 7:30am – 5pm Friday November 17 8am – 11am Exhibition Hall Hours Day Date Hours Tuesday November 14 10am-6pm Wednesday November 15 10am-6pm Thursday November 16 10am-3pm SC17 Information BootHs Need up-to-the-minute information about what’s happening at the conference. Need to know where to find your next session? What restaurants are close by? Where to get a document printed? These questions and more can be answered by a quick stop at one of the SC information booths. There are two booth locations for your convenience. The Main Booth is located in Lobby F near the conference store and registration. The Satellite Booth is located in the D concourse near the 600 series rooms. Main BootH Satellite BootH Saturday 1pm-5pm Closed Sunday 8am-6pm 8am-5pm Monday 8am-7pm 8am-5pm Tuesday 8am-6pm 10am-6pm Wednesday 8am-6pm 8am-4pm Thursday 8am-6pm Closed Friday 8:30am-12pm Closed SC18 Preview BootH Members of next year’s SC committee will be available in the SC18 preview booth (located in the A Atrium) to offer information and discuss next year’s SC conference in Dallas, Texas. -

Daniel Andresen
Daniel Andresen Professor, Department of Computer Science Director, Institute for Computational Research in Engineering and Science Michelle Munson-Serban Simu Keystone Research Scholar Kansas State University 2174 Engineering Hall Manhattan, KS 66506-2302 Tel: 785–532–6350 Fax: 785–532–7353 Email: [email protected] WWW: http://www.cis.ksu.edu/∼dan EDUCATION Ph.D., Computer Science, University of California, Santa Barbara, CA. September, 1997 Thesis Title: “SWEB++: Distributed Scheduling and Software Support for High Performance WWW Applications.” Advisor: Prof. Tao Yang M.S., Computer Science, California Polytechnic State University, San Luis Obispo, CA. September, 1992. B.S., Computer Science and Mathematics, double major, magna cum laude, honors in major, Westmont College, Santa Barbara, CA. May, 1990. AWARDS Michelle Munson-Serban Simu Keystone Research Scholar September, 2020 NSF CAREER Award 2001 KSU Engineering Student Council Outstanding Leadership Award December, 2004, 2005, 2008 Residencehall’sProfessoroftheYearnominee 2000,2002 Cargill Faculty Fellow 1999, 2000 College of Engg. James L. Hollis Memorial Award for Excellence in Undergrad- uate Teaching nominee 1999, 2006 RESEARCH Parallel and distributed systems, HPC scheduling, Research Cyberinfrastructure, INTERESTS digital libraries/WWW applications, Grid/cloud computing, and scientific mod- eling. TEACHING Graduate-level parallel/distributed computing, scientific computing, networking, INTERESTS operating systems, and computer architectures. Courses taught include operat- ing systems (CIS520), Topics in Distributed Systems (CIS825), Introduction to Computer Architecture (CIS450), Software Engineering (CIS642), Web Interface Design (CIS526), and Advanced World Wide Web Technologies (CIS726). 1 WORK Professor in the Department of Computing and Information Sciences at EXPERIENCE Kansas State University. 2015-present Associate Professor in the Department of Computing and Information SciencesatKansasStateUniversity. -

Sunita Chandrasekaran
Sunita Chandrasekaran Assistant Professor Department of Computer and Information Sciences University of Delaware [email protected] Ph: 302 831 2714 https://www.eecis.udel.edu/ schandra/ CRPL: https://crpl.cis.udel.edu/ PROFESSIONAL EXPERIENCE September 2015–Present: Assistant Professor; Department of Computer and Information Sciences, Uni- versity of Delaware, Newark, USA September 2016–Present: Affiliated Professor; The Center for Bioinformatics & Computational Biol- ogy (CBCB), Data Science Institute (DSI), University of Delaware, Newark, USA September 2016–Present: Adjunct Professor; Department of Computer Science, University of Houston, Houston, TX, USA June 2017 – Present: Director of OpenACC User Adoption December 2010–August 2015: Postdoctoral Researcher, Department of Computer Science, University of Houston,TX, USA EDUCATION Nanyang Technological University (NTU), Singapore, Ph.D., School of Computer Science, Title: Tools and Algorithms for High Level Algorithm Mapping to FPGA, 2012 Anna University, India, Bachelors of Engineering (B.E.), Electrical & Electronics, Final Year Thesis Ti- tle: Experimental Studies in Statistical Signal Processing, 2005 RESEARCH INTERESTS High Performance Computing, Parallel Programming Models, Machine Learning, Validation & Verifica- tion Testsuites for OpenMP and OpenACC Parallelizing and Accelerating Scientific Applications from domains such as Molecular Dynamics, Next Gen- eration Sequencing, Molecular Dynamics, Nuclear Physics, Weather Modeling to Supercomputers AWARDS 2018 Vertically Integrated -

Stephen Lien Harrell Updated: July 19, 2021
Stephen Lien Harrell Updated: July 19, 2021 Contact Email: [email protected] Information GitHub: stephenlienharrell ORCiD: 0000-0001-5327-525X Latest CV Version: harrell.cc Education B.S., Computer Science Minors: Gender Studies; Sociology Purdue University Recent HPC Engineering Scientist, Texas Advanced Computing Center, The University of Professional Texas at Austin, March 2020 - present Positions Senior Computational Scientist, Research Computing, Purdue University, April 2014 - March 2020 Senior HPC Systems Administrator, Research Computing, Purdue University, July 2008 - April 2014 Linux Systems Administrator, Enterprise, Google, April 2006 - June 2008 Complete work history below Peer 23. Bird, R., Tan, N., Luedtke, S., Harrell, S., Taufer, M., Albright, B. VPIC 2.0: Reviewed Next Generation Particle-in-Cell Simulations, IEEE Transactions on Parallel and Publications Distributed Computing 10.1109/TPDS.2021.3058393 22. Cawood, M., Harrell, S., Evans, R., BenchTool: a framework for the automation and standardization of HPC performance benchmarking, PEARC'21: Practice and Experience in Advanced Research Computing, Virtual Conference, July 19th-22nd, 2021 10.1145/3437359.3465611 21. Wu, T., Harrell, S., Lentner, G., Younts, A., Weekly, S., Mertes, Z., Maji, A., Smith, P., Zhu, X., Defining Performance of Scientific Application Workloads on the AMD Milan Platform, PEARC'21: Practice and Experience in Advanced Research Computing, Virtual Conference, July 19th-22nd, 2021 10.1145/3437359.3465596 20. Smith, P., Harrell, S.. Research Computing on Campus - Application of a Production Function to the Value of Academic High-Performance Computing, PEARC'21: Practice and Experience in Advanced Research Computing, Virtual Conference, July 19th-22nd, 2021 10.1145/3437359.3465564 1 of 11 19. -

See Complete Vita
Ümit V. Çatalyürek School of Computational Science and Engineering, Georgia Institute of Technology Klaus Advanced Computing Building, 266 Ferst Drive, Atlanta GA 30332 e-mail: [email protected] Phone: (404) 894-2592 http://cc.gatech.edu/~umit RESEARCH INTERESTS Broad topics: high performance computing, combinatorial scientific computing, and biomedical informatics. In particular: graph analytics, parallel algorithms for scientific applications, scheduling, graph and hypergraph partitioning, workload and data decomposition for irregular applications, programing models and runtime systems for high performance computing, data-intensive computing, and large scale genomic and biomedical applications. EDUCATION Ph.D. Computer Engineering and Information Science, 2000, Bilkent University, Turkey Thesis: Hypergraph Models for Sparse Matrix Partitioning and Reordering M.S. Computer Engineering and Information Science, 1994, Bilkent University, Turkey B.S. Computer Engineering and Information Science, 1992, Bilkent University, Turkey PROFESSIONAL EXPERIENCE Jul 2021 – Amazon Scholar AmaZon Web Services Jan 2017 – Jul 2021 Associate Chair School of Computational Science and Engineering Georgia Institute of Technology Jan 2017 – Dec 2020 Director CSE Graduate Programs Georgia Institute of Technology Aug 2016 – Professor School of Computational Science and Engineering Georgia Institute of Technology Aug 2016 – Adjunct Professor Dept. of Biomedical Informatics, The Ohio State University Sep 2014 – Aug 2016 Vice Chair for Academic Dept. of Biomedical Informatics, Affairs The Ohio State University Sep 2014 – Aug 2016 Director, Division of Data Dept. of Biomedical Informatics, Sciences The Ohio State University Aug 2015 – Aug 2016 Affiliated Faculty Translational Data Analytics @ Ohio State Mar 2015 – Aug 2016 Professor Division of Biostatistics (courtesy), College of Public Health The Ohio State University Sep 2012 – Aug 2016 Professor Dept.