Personalisation for Smart Personal Assistants
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
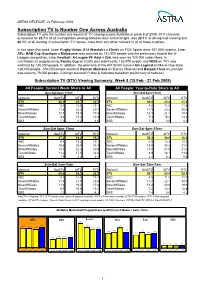
Subscription TV Is Number One Across Australia Subscription TV Was the Number One Source of TV Viewing Across Australia in Week 8 of 2009
MEDIA RELEASE- 23 February 2009 Subscription TV Is Number One Across Australia Subscription TV was the number one source of TV viewing across Australia in week 8 of 2009. STV channels accounted for 23.7% of all metropolitan viewing between 6am and midnight, was 22.1% of all regional viewing and 60.1% of all viewing in subscription TV homes, more than any other network in all of those markets. In live sport this week, Live: Rugby Union: S14 Waratahs v Chiefs on FOX Sports drew 167,000 viewers, Live: AFL: NAB Cup Hawthorn v Melbourne was watched by 142,000 people and the preliminary final of the A- League competition, Live: Football: A-League PF Adel v Qld, was seen by 124,000 subscribers. In entertainment programming, Family Guy on FOX8 was watched by 153,000 people and NCIS on TV1 was watched by 135,000 people. In addition, the premiere of the Will Smith movie I Am Legend on Movie One drew 128,000 people, 106,000 people watched Hannah Montana on Disney Channel and Bargain Hunt on Lifestyle was seen by 79,000 people. (Listings overleaf; Friday & Saturday based on preliminary schedules). Subscription TV (STV) Viewing Summary: Week 8 (15 Feb - 21 Feb 2009) All People: Current Week Share to All All People: Year-to-Date Share to All Sun-Sat 6am-12mn Sun-Sat 6am-12mn Network NatSTV MTV RTV Network NatSTV MTV RTV STV 60.1 23.7 22.1 STV 60.0 23.8 21.8 ABC 5.1 12.6 13.1 ABC 4.5 11.5 11.8 Seven/Affiliates 11.8 22.2 20.7 Seven/Affiliates 11.9 22.3 20.3 Nine/Affiliates 12.1 19.0 17.4 Nine/Affiliates 14.3 21.1 19.7 Ten/Affiliates 9.1 17.2 13.3 Ten/Affiliates -
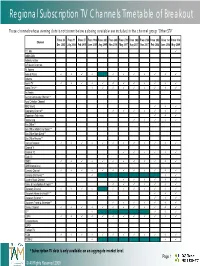
Regional Subscription TV Channels Timetable of Breakout
Regional Subscription TV Channels Timetable of Breakout Those channels whose viewing data is not shown below as being available are included in the channel group ‘Other STV’ From 28 From 11 From 27 From 19th From 28th From 26th From 27th From 26th From 25th From 24th From 1st From 31st Channel Dec 2003 July 2004 Feb 2005 June 2005 Aug 2005 Nov 2006 May 2007 Aug 2007 Nov 2007 Feb 2008 June 2008 May 2009 111 Hits 9 Adults Only Adventure One AIR Audio Channels Al Jazeera Animal Planet 9999 9999999 Antenna Arena TV 999999999999 Arena TV+2* * 999999999 Art Arabic Aurora Community Channel* * Aust Christian Channel BBC World 999 Biography Channel* * 9999999 Bloomberg Television 999 Boomerang 99999 Box Office* * Box Office Adults Only Select* * Box Office Main Event* * Box Office Preview* * Cartoon Network 999999999999 Channel V Channel V2 999999 Club (V) CNBC 999999999999 CNN International Comedy Channel 999999999999 Comedy Channel+2* * 9 99 Country Music Channel 999999 Crime & Investigation Network* * 9999999 Discovery Channel 9999 9999999 Discovery Home and Health* * 999 Discovery Science* * 999 Discovery Travel & Adventure* * 9999999 Disney Channel 999999999999 E!* * 9 999 ESPN 999999999999 Eurosportnews EXPO Fashion TV FOX8 999999999999 FOX8+2 9 99 * Subscription TV data is only available on an aggregate market level. Page 1 © All Rights Reserved 2009 Regional Subscription TV Channels Timetable of Breakout Those channels whose viewing data is not shown below as being available are included in the channel group ‘Other STV’ From 28 From 11 -

Top 100 Pay Television Programs Total Individuals Week 25, 2009 (14/06/2009 - 20/06/2009) Round to Nearest Thousand 5 City Metro Prepared by SEVEN NETWORK RESEARCH
Top 100 Pay Television Programs Total Individuals Week 25, 2009 (14/06/2009 - 20/06/2009) Round to Nearest Thousand 5 City Metro Prepared by SEVEN NETWORK RESEARCH TV Item Description (grouped) Channel 5 City Metro 1 LIVE: FOOTBALL: WORLD CUP QUALIFIER AUST V FOX SPORTS 1 288,000 JAPAN 2 LIVE: AFL ADELAIDE V NORTH MELBOURNE FOX SPORTS 1 195,000 3 LIVE: AFL HAWTHORN V BRISBANE LIONS FOX SPORTS 1 163,000 4 LIVE: NRL EELS V WESTS TIGERS FOX SPORTS 2 141,000 5 LIVE: NRL COWBOYS V ROOSTERS FOX SPORTS 2 121,000 6 LIVE: FOOTBALL: WORLD CUP QUALIFIER POST FOX SPORTS 1 108,000 GAME 7 LIVE: AFL PRE GAME SHOW FOX SPORTS 1 98,000 8 LIVE: FOOTBALL: WORLD CUP QUALIFIER PRE FOX SPORTS 1 88,000 GAME 9 LIVE: NRL RAIDERS V SHARKS FOX SPORTS 2 88,000 10 LIVE: AFL: ON THE COUCH FOX SPORTS 1 85,000 11 LIVE: RUGBY UNION: TEST MATCH FOX SPORTS 3 72,000 12 AUSTRALIA'S NEXT TOP MODEL FOX8 65,000 13 LIVE: AFL TEAMS FOX SPORTS 1 60,000 14 LIVE: NRL MONDAY POST GAME SHOW FOX SPORTS 2 59,000 15 NCIS TV1 56,000 16 MYSTERY MEN SHOWTIME Greats 54,000 17 LIVE: NRL SATURDAY PRE GAME SHOW FOX SPORTS 2 52,000 18 THE SIMPSONS FOX8 50,000 19 FAMILY GUY FOX8 46,000 20 LIVE: MOTORSPORT: MOTOGP RND 6, CATALUNA FOX SPORTS 2 45,000 21 AFL: BEFORE THE BOUNCE FOX SPORTS 1 45,000 22 CASPER MEETS WENDY Disney Channel 40,000 23 THE DOMINO PRINCIPLE FOX Classics 39,000 24 GRAND DESIGNS LifeStyle Channel 38,000 25 THE SEX CHAMBER Crime & Investigation 38,000 26 JONAS Disney Channel 37,000 27 TWO AND A HALF MEN FOX8 37,000 28 EYE OF THE NEEDLE FOX Classics 36,000 29 THE MAN FROM THE ALAMO -

2010 Regional Toolkit
REGIONAL TOOLKIT 2010 Contents 2010 Survey Calendar Summary 3 2010 Universe Estimates 4 Coverage Maps and Coverage Areas 23 Reporting Demographics 34 Regional Subscription TV Channels 38 Regional FTA TV Channels Breakout 41 Terms & Definitions 42 The Ratings Process 43 Regional Client Service Organisational Chart 46 Contact Details 47 Page 2 © All Rights Reserved 20102009 Survey Calendar Summary - 2010 Survey Weeks Surveyed Survey Commences (Sun) Survey Concludes (Sat) Summer Weeks 1 – 6 27 December 2009 06 February 2010 Survey 1 Weeks 7 – 10 07 February 2010 06 March 2010 Survey 2 Weeks 11 – 13 07 March 2010 27 March 2010 Easter Weeks 14-15 28 March 2010 10 April 2010 Survey 2 Week 16 11 April 2010 17 April 2010 Survey 3 Weeks 17 – 20 18 April 2010 15 May 2010 Survey 4 Weeks 21 – 24 16 May 2010 12 June 2010 Survey 5 Weeks 25 – 28 13 June 2010 10 July 2010 Survey 6 Weeks 29 – 32 11 July 2010 07 August 2010 Survey 7 Weeks 33 – 36 08 August 2010 04 September 2010 Survey 8 Weeks 37 – 40 05 September 2010 02 October 2010 Survey 9 Weeks 41 – 44 03 October 2010 30 October 2010 Survey 10 Weeks 45 – 48 31 October 2010 27 November 2010 Summer Weeks 49 – 52 28 November 2010 25 December 2010 The full Survey Calendar can be downloaded at: http://www.agbnielsen.net/whereweare/countries/australia/australia.asp?lang=english Page 3 © All Rights Reserved 2010 Universe Estimates - 2010 Total Households (000's) Total Individuals (000's) Number of Homes Installed Total QUEENSLAND (AM-A) 673.0 1696.0 535 CAIRNS 100.0 245.0 80 TOWNSVILLE 86.0 226.0 70 MACKAY -

Wholesale Must-Offer Remedies: International Examples
Wholesale must-offer remedies: international examples Annex 11 to pay TV phase three document Publication date: 26 June 2009 FINAL REPORT WHOLESALE MUST-OFFER REMEDIES: INTERNATIONAL EXAMPLES London, April 2009 © Value Partners 2009. This document is confidential and intended solely for the use and information of the addressee Contents 1 Introduction 1 2 Executive summary 2 3 Italy 6 3.1 Background 6 3.2 Details of the remedy 9 3.3 Impact of the remedy 13 3.4 Future 15 3.5 Summary 16 4 France 17 4.1 Background 17 4.2 Details of the remedy 20 4.3 Impact of the remedy 23 4.4 Future 25 4.5 Summary 25 5 US 27 5.1 Background 27 5.2 Details of the remedy 29 5.3 Impact of the remedy 32 5.4 Future 34 5.5 Summary 34 6 Spain 36 6.1 Background 36 6.2 Details of the remedy 38 6.3 Impact of the remedy 39 6.4 Future 40 6.5 Summary 40 7 Australia 41 7.1 Background 41 7.2 Details of the remedy 47 7.3 Impact of the remedy 49 7.4 Future 51 7.5 Summary 51 8 Singapore 52 8.1 Background 52 8.2 Details of the MDA’s investigation 54 8.3 Impact of the MDA’s decision 55 8.4 Future 56 8.5 Summary 56 © Value Partners 2009. | 09 04 16 International study of wholesale must-offer pay TV remedies 1 International study of wholesale must-offer pay TV remedies 1 Introduction In September 2008, Ofcom published its Second Consultation on the pay TV Investigation which focuses on access to premium content and whether BSkyB’s (Sky) competitors are able to compete effectively at the wholesale level for such content. -

Aucun Titre De Diapositive
Channels available programme by programme, territory by territory, via Eurodata TV Worldwide. * Channels measured only on a minute by minute basis are available on an ad-hoc basis “Standard countries” : data available in house, catalogue tariffs are applied “Non-standard countries” : Ad hoc tariffs are applied “Special countries” : special rate card applies “Standard countries” : Eurodata TV’s tariffs are applied, “Non-standard10/05/2006 countries” : Ad hoc tariffs are applied “Special countries” : Fixed and separated prices apply data available in Paris except for channels in blue 14/02/2006 issue This document is subject to change Channels available programme by programme in EUROPE AUSTRIA BELGIUM BOSNIA HERZEGOVINA BULGARIA CROATIA ORF1 ZDF NORTH SOUTH BHT 1 TV TK ALEXANDRA TV GTV HTV 1 ORF2 ATV+ EEN (ex TV1) LA 1 FTV TV TUZLA BBT FoxLife HTV 2 3SAT KANAAL 2 LA 2 HTV OSCAR C BTV NOVA TV ARD Channels available on KETNET/CANVAS RTL - TVI NTV HAYAT BNT/Channel 1 RTL KABEL 1 ad-hoc NICKELODEON CLUB RTL OBN DIEMA 2 PRO7 ARTE SPORZA AB 3 Pink BiH DIEMA + RTL DSF VIJFTV AB 4 RTRS NOVA TV RTL II EUROSPORT VITAYA PLUG TV RTV MOSTAR MM SAT 1 GOTV VT4 BE 1 (ex CANAL+) RTV TRAVNIK MSAT SUPER RTL Puls TV VTM TV BN Evropa TV VOX TW1 Planeta TV TELETEST / FESSEL - GFK/ORF CIM - AUDIMETRIE MARECO INDEX BOSNIA TNS TV PLAN AGB NMR CYPRUS CZECH REP DENMARK ESTONIA FINLAND FRANCE GERMANY ANT 1 CT 1 3+ EESTI TV (ETV) YLE 1 TF1 ARD ARTE SUPER RTL O LOGOS CT 2 ANIMAL PLANET KANAL 2 YLE 2 FRANCE 2 ZDF 3SAT NTV RIK 1 TV NOVA DISCOVERY PBK MTV FRANCE 3 HESSEN -

New Eligible Drama Expenditure Scheme Results for 2007–08 Australian Content and Pay TV
NEWSnews New Eligible Drama Expenditure Scheme results for 2007–08 AusTrAlIAN CONTeNT ANd pAy TV The subscription television industry spent $20.06 million on festival, the Optus one80 project competition, and Nick Shorts, where selected new original Australian and New Zealand drama programs in the 2007–08 animation short films will be broadcast financial year in meeting its obligations under the New eligible nationally on a range of Nickelodeon Australia’s media platforms. drama expenditure scheme. The scheme accommodates the dynamics of production schedules by allowing licensees and The Broadcasting Services Act 1992 films, including The King, Balibo 5, and 2:37 ; and channel providers to operate under an ‘accrual- (the BSA) requires subscription TV licensees that drama series, including H2O: Just Add Water, type’ system, where obligations that arise in broadcast drama channels, and drama channel Chandon Pictures, Satisfaction, Whatever one reporting period and are not then acquitted package providers, to invest at least 10 per Happened To That Guy?, Blue Water High and must be fully acquitted in the following period. cent of their total program expenditure on new The Mansion. Each year licensees and channel providers report Australian drama. The 2007–08 investments also supported their drama expenditure, which must be at least This investment enabled Australians to new opportunities for Australian film and enough to acquit any obligation accrued from participate in the production of a wide variety of animation, such as the Tropfest short film the previous year. They indicate the amount 4 ACMAsphere | Issue 40 — April 2009 NEWSnews of any obligation acquitted for the previous The licensees that broadcast relevant drama program’. -

Regional Subscription TV Channels Timetable of Breakout
Regional Subscription TV Channels Timetable of Breakout Channel From 28 Dec From 11 July From 27 Feb From 19 From 28 Aug From 26 Nov From 27 May From 26 Aug From 25 Nov From 24 Feb From 1 June From 31 May From 30 Aug From 29 Nov From 28 Feb From 30 May From 29 Aug From 28 Nov From 9 Jan From 29 May From 28 From 12 From 26 From 6 Jan From 24 Feb From 1 Sept From 1 Dec From 29 From 23 From 6 Apr From 2 From 1 Mar From 31 From 29 From 28 From 26 From 28 From 2 Oct From 26 From 27 From 15 From 4 Mar From 8 Apr From 27 From 26 '03 '04 '05 June '05 '05 '06 '07 '07 '07 '08 '08 '09 '09 '09 '10 '10 '10 '10 '11 '11 Aug '11 Feb '12 Aug '12 '13 '13 '13 '13 Dec '13 Feb '14 '14 Nov '14 '15 May '15 Nov '15 Feb '16 Jun '16 Aug '16 '16 Feb '17 Aug '17 Oct '17 '18 '18 May '18 Aug '18 111*** 111 +2*** 13th STREET 13th STREET +2 A&E*** A&E =2*** (5 Oct 16) Adults Only 1 Adults Only 2 Al Jazeera Animal Planet Antenna Arena Arena+2 A-PAC ART Aurora Australian Christian Channel BBC Knowledge BBC WORLD NEWS beIN Sports (Setanta Sports) Binge* (5 Oct 2016) Bio*** Bloomberg Boomerang Box Sets Cartoon Network -

Top 100 Pay Television Programs Total Individuals Week 42, 2009 (11/10/2009 - 17/10/2009) Round to Nearest Thousand 5 City Metro Prepared by SEVEN NETWORK RESEARCH
Top 100 Pay Television Programs Total Individuals Week 42, 2009 (11/10/2009 - 17/10/2009) Round to Nearest Thousand 5 City Metro Prepared by SEVEN NETWORK RESEARCH TV Item Description (grouped) Channel 5 City Metro 1 LIVE: FOOTBALL: AFC ASIAN CUP QUALIFIER AUS V OMAN FOX SPORTS 1 174,000 2 LIVE: FOOTBALL: AFC ASIAN CUP QUALIFIER POST GAME FOX SPORTS 1 64,000 3 THE MUMMY: TOMB OF THE DRAGON EMPEROR SHOWTIME 54,000 4 LIVE: FOOTBALL: EPL A VILLA V CHELSEA FOX SPORTS 1 54,000 5 LIVE: FOOTBALL: A-LEAGUE ADEL V SYDNEY FOX SPORTS 1 53,000 6 IN THE LINE OF FIRE FOX Classics 53,000 7 IRON MAN SHOWTIME 51,000 8 WIZARDS OF WAVERLY PLACE: THE MOVIE Disney Channel 47,000 9 THE SILENCE OF THE LAMBS FOX Classics 46,000 10 THE RETURN OF FRANK JAMES FOX Classics 46,000 11 THE MAN FROM THE ALAMO FOX Classics 46,000 12 NEW ZEALAND'S NEXT TOP MODEL FOX8 44,000 13 LIVE: FOOTBALL: A-LEAGUE BRIS V C'COAST FOX SPORTS 1 42,000 14 LIVE: CRICKET: FORD RANGER CUP FOX SPORTS 2 42,000 15 NCIS TV1 41,000 16 ALL ABOUT EVE FOX Classics 38,000 17 THE INSPECTOR LYNLEY MYSTERIES UKTV 37,000 18 SHALLOW HAL SHOWTIME Greats 37,000 19 MAID IN MANHATTAN TV1 37,000 20 STARGATE: UNIVERSE SCI FI 36,000 21 SECRET LIFE OF THE AMERICAN TEENAGER FOX8 35,000 22 THE SIMPSONS FOX8 31,000 23 LAW & ORDER: SVU TV1 31,000 24 FAMILY GUY FOX8 30,000 25 THE LOVE GURU SHOWTIME 30,000 26 LIVE: FOOTBALL: AFC ASIAN CUP QUALIFIER PRE GAME FOX SPORTS 1 29,000 27 BEST HOUSE ON THE STREET LifeStyle Channel 29,000 28 MEN IN BLACK II SCI FI 29,000 29 HOT PROPERTY LifeStyle Channel 28,000 30 LIVE: FOOTBALL: -

Regional Subscription TV Channels Timetable of Breakout
Regional Subscription TV Channels Timetable of Breakout Channel From 28 Dec From 11 July From 27 Feb From 19 From 28 Aug From 26 Nov From 27 May From 26 Aug From 25 Nov From 24 Feb From 1 June From 31 May From 30 Aug From 29 Nov From 28 Feb From 30 May From 29 Aug From 28 Nov From 9 Jan From 29 May From 28 From 12 Feb From 26 From 6 Jan From 24 Feb From 1 Sept From 1 Dec From 29 From 23 From 6 Apr From 2 Nov From 1 Mar From 31 From 29 From 28 From 26 From 28 From 2 Oct From 26 From 27 From 15 From 4 Mar From 8 Apr From 27 From 26 From 24 From 3 Nov From 29 '03 '04 '05 June '05 '05 '06 '07 '07 '07 '08 '08 '09 '09 '09 '10 '10 '10 '10 '11 '11 Aug '11 '12 Aug '12 '13 '13 '13 '13 Dec '13 Feb '14 '14 '14 '15 May '15 Nov '15 Feb '16 Jun '16 Aug '16 '16 Feb '17 Aug '17 Oct '17 '18 '18 May '18 Aug '18 Feb '19 '19 Dec '19 111 *** (ceased 6 Nov 19) 111 +2*** (ceased 6 Nov 19) 13th STREET (ceased 29 Dec 19) 13th STREET +2 (ceased 29 Dec 19) A&E*** A&E =2*** (5 Oct 16) Adults Only 1 Adults Only 2 Al Jazeera Animal Planet Antenna Arena Arena+2 A-PAC ART Aurora Australian Christian Channel BBC Knowledge BBC WORLD NEWS beIN Sports (Setanta Sports) Binge* (ceased 6 Nov 19) Bio*** -

Top 100 Pay Television Programs Total Individuals Week 08, 2009 (15/02/2009 - 21/02/2009) Round to Nearest Thousand 5 City Metro Prepared by SEVEN NETWORK RESEARCH
Top 100 Pay Television Programs Total Individuals Week 08, 2009 (15/02/2009 - 21/02/2009) Round to Nearest Thousand 5 City Metro Prepared by SEVEN NETWORK RESEARCH TV Item Description (grouped) Channel 5 City Metro 1 LIVE: AFL: NAB CUP HAWTHORN V MELBOURNE FOX SPORTS 1 116,000 2 LIVE: RUGBY UNION: S14 WARATAHS V CHIEFS FOX SPORTS 2 112,000 3 LIVE: FOOTBALL: A-LEAGUE PF ADEL V QLD FOX SPORTS 3 100,000 4 LIVE: AFL: NAB CUP FREMANTLE V RICHMOND FOX SPORTS 1 86,000 5 LIVE: RUGBY UNION: S14 PRE GAME SHOW FOX SPORTS 2 73,000 6 ACTIVE: I AM LEGEND MOVIE ONE 72,000 7 NCIS TV1 72,000 8 LIVE: RUGBY UNION: S14 FORCE V CHEETAHS FOX SPORTS 2 64,000 9 THE MUMMY RETURNS SHOWTIME Greats 61,000 10 DALZIEL AND PASCOE UKTV 55,000 11 LIVE: RUGBY UNION: S14 BRUMBIES V CRUS FOX SPORTS 2 54,000 12 GONE WITH THE WIND FOX Classics 52,000 13 AS TIME GOES BY UKTV 49,000 14 SWORDFISH MOVIE EXTRA 49,000 15 FAWLTY TOWERS UKTV 46,000 16 FAMILY GUY FOX8 46,000 17 OPERATION PETTICOAT FOX Classics 45,000 18 THE ENFORCER FOX Classics 44,000 19 I AM LEGEND MOVIE ONE 44,000 20 MCHALE'S NAVY FOX Classics 42,000 21 THE SIMPSONS FOX8 42,000 22 TWO AND A HALF MEN FOX8 40,000 23 EYES WIDE SHUT MOVIE EXTRA 40,000 24 27 DRESSES SHOWTIME 40,000 25 LIVE: FOOTBALL: EPL A VILLA V CHELSEA FOX SPORTS 3 39,000 26 DESTROYED IN SECONDS Discovery Channel 39,000 27 FISHING WESTERN AUSTRALIA LifeStyle Channel 39,000 28 LAW & ORDER: SVU TV1 39,000 29 LIVE: RUGBY UNION: S14 HURR V H'LAND FOX SPORTS 2 38,000 30 ENCHANTED Disney Channel 38,000 31 JUDGE JOHN DEED UKTV 37,000 32 GOSSIP GIRL FOX8 -

95 Subscription TV Channels
Channel Start Date End Date 111 30th Nov 2008 111 +2 29th Nov 2009 13th Street 29th Nov 2009 16th Dec 2019 13th Street +2 28th Nov 2010 16th Dec 2019 A&E 12th Feb 2012 A&E +2 2nd Oct 2016 Animal Planet 28th Dec 2003 BBC First 3rd August 2014 BBC Earth 30th Nov 2008 BBC World News 9th Jan 2011 beIN Sports 1 29th Nov 2011 beIN Sports 2 28th Aug 2016 beIN Sports 3 28th Aug 2016 Binge 2nd Oct 2016 6th Nov 2019 Bio 28th May 2016 1st Nov 2015 Boomerang 4th Sept 2005 BoxSets 3rd Nov 2014 Cartoon Network 3rd August 2003 Cbeebies 30th Nov 2008 CMT 1st July 2020 Channel [V] 3rd Aug 2003 Club MTV 27th Feb 2005 CNBC 3rd Aug 2003 28th Dec 2014 Comedy Channel 3rd Aug 2003 31st Aug 2020 Comedy Channel +2 19th June 2005 6th Nov 2019 Country Music Channel 28th Aug 2016 30th June 2020 crime + investigation 1st Jan 2006 Discovery Channel 3rd Aug 2003 Discovery Channel +2 29th Nov 2009 Discovery Home & Health 1st Jan 2006 3rd Aug 2014 Discovery Kids 3rd Nov 2014 31st Jan 2020 Discovery Turbo 29th Nov 2009 Discovery Turbo +2 29th Nov 2009 Disney Channel 3rd Aug 2003 29th Feb 2020 Disney Junior 26th Feb 2006 29th Feb 2020 DreamWorks 1st July 2021 E! 19th June 2005 E! +2 23rd Feb 2020 ESPN 28th Dec 2003 ESPN2 27th Nov 2011 Eurosport 28th June 2015 31st Jan 2020 FMC - Family Movie Channel 29th Nov 2009 26th Aug 2012 FOX Arena 3rd Aug 2003 FOX Arena +2 19th June 2005 FOX Classics 3rd Aug 2003 FOX Classics +2 19th June 2005 FOX COMEDY 3rd Nov 2019 FOX COMEDY +2 3rd Nov 2019 FOX CRICKET 26th Aug 2018 FOX CRIME 3rd Nov 2019 FOX CRIME +2 3rd Nov 2019 Channel Start