Memory Management Buddy Allocator Slab Allocator Table of Contents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CSE 220: Systems Programming
Memory Allocation CSE 220: Systems Programming Ethan Blanton Department of Computer Science and Engineering University at Buffalo Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Allocating Memory We have seen how to use pointers to address: An existing variable An array element from a string or array constant This lecture will discuss requesting memory from the system. © 2021 Ethan Blanton / CSE 220: Systems Programming 2 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Memory Lifetime All variables we have seen so far have well-defined lifetime: They persist for the entire life of the program They persist for the duration of a single function call Sometimes we need programmer-controlled lifetime. © 2021 Ethan Blanton / CSE 220: Systems Programming 3 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Examples int global ; /* Lifetime of program */ void foo () { int x; /* Lifetime of foo () */ } Here, global is statically allocated: It is allocated by the compiler It is created when the program starts It disappears when the program exits © 2021 Ethan Blanton / CSE 220: Systems Programming 4 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Examples int global ; /* Lifetime of program */ void foo () { int x; /* Lifetime of foo () */ } Whereas x is automatically allocated: It is allocated by the compiler It is created when foo() is called ¶ It disappears when foo() returns © 2021 Ethan Blanton / CSE 220: Systems Programming 5 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary The Heap The heap represents memory that is: allocated and released at run time managed explicitly by the programmer only obtainable by address Heap memory is just a range of bytes to C. -

Measuring Software Performance on Linux Technical Report
Measuring Software Performance on Linux Technical Report November 21, 2018 Martin Becker Samarjit Chakraborty Chair of Real-Time Computer Systems Chair of Real-Time Computer Systems Technical University of Munich Technical University of Munich Munich, Germany Munich, Germany [email protected] [email protected] OS program program CPU .text .bss + + .data +/- + instructions cache branch + coherency scheduler misprediction core + pollution + migrations data + + interrupt L1i$ miss access + + + + + + context mode + + (TLB flush) TLB + switch data switch miss L1d$ +/- + (KPTI TLB flush) miss prefetch +/- + + + higher-level readahead + page cache miss walk + + multicore + + (TLB shootdown) TLB coherency page DRAM + page fault + cache miss + + + disk + major minor I/O Figure 1. Event interaction map for a program running on an Intel Core processor on Linux. Each event itself may cause processor cycles, and inhibit (−), enable (+), or modulate (⊗) others. Abstract that our measurement setup has a large impact on the results. Measuring and analyzing the performance of software has More surprisingly, however, they also suggest that the setup reached a high complexity, caused by more advanced pro- can be negligible for certain analysis methods. Furthermore, cessor designs and the intricate interaction between user we found that our setup maintains significantly better per- formance under background load conditions, which means arXiv:1811.01412v2 [cs.PF] 20 Nov 2018 programs, the operating system, and the processor’s microar- chitecture. In this report, we summarize our experience on it can be used to improve high-performance applications. how performance characteristics of software should be mea- CCS Concepts • Software and its engineering → Soft- sured when running on a Linux operating system and a ware performance; modern processor. -

Linux Kernel and Driver Development Training Slides
Linux Kernel and Driver Development Training Linux Kernel and Driver Development Training © Copyright 2004-2021, Bootlin. Creative Commons BY-SA 3.0 license. Latest update: October 9, 2021. Document updates and sources: https://bootlin.com/doc/training/linux-kernel Corrections, suggestions, contributions and translations are welcome! embedded Linux and kernel engineering Send them to [email protected] - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 1/470 Rights to copy © Copyright 2004-2021, Bootlin License: Creative Commons Attribution - Share Alike 3.0 https://creativecommons.org/licenses/by-sa/3.0/legalcode You are free: I to copy, distribute, display, and perform the work I to make derivative works I to make commercial use of the work Under the following conditions: I Attribution. You must give the original author credit. I Share Alike. If you alter, transform, or build upon this work, you may distribute the resulting work only under a license identical to this one. I For any reuse or distribution, you must make clear to others the license terms of this work. I Any of these conditions can be waived if you get permission from the copyright holder. Your fair use and other rights are in no way affected by the above. Document sources: https://github.com/bootlin/training-materials/ - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 2/470 Hyperlinks in the document There are many hyperlinks in the document I Regular hyperlinks: https://kernel.org/ I Kernel documentation links: dev-tools/kasan I Links to kernel source files and directories: drivers/input/ include/linux/fb.h I Links to the declarations, definitions and instances of kernel symbols (functions, types, data, structures): platform_get_irq() GFP_KERNEL struct file_operations - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 3/470 Company at a glance I Engineering company created in 2004, named ”Free Electrons” until Feb. -
Memory Allocation Pushq %Rbp Java Vs
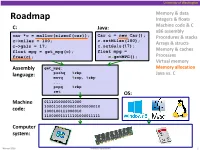
University of Washington Memory & data Roadmap Integers & floats C: Java: Machine code & C x86 assembly car *c = malloc(sizeof(car)); Car c = new Car(); Procedures & stacks c.setMiles(100); c->miles = 100; Arrays & structs c->gals = 17; c.setGals(17); float mpg = get_mpg(c); float mpg = Memory & caches free(c); c.getMPG(); Processes Virtual memory Assembly get_mpg: Memory allocation pushq %rbp Java vs. C language: movq %rsp, %rbp ... popq %rbp ret OS: Machine 0111010000011000 100011010000010000000010 code: 1000100111000010 110000011111101000011111 Computer system: Winter 2016 Memory Allocation 1 University of Washington Memory Allocation Topics Dynamic memory allocation . Size/number/lifetime of data structures may only be known at run time . Need to allocate space on the heap . Need to de-allocate (free) unused memory so it can be re-allocated Explicit Allocation Implementation . Implicit free lists . Explicit free lists – subject of next programming assignment . Segregated free lists Implicit Deallocation: Garbage collection Common memory-related bugs in C programs Winter 2016 Memory Allocation 2 University of Washington Dynamic Memory Allocation Programmers use dynamic memory allocators (such as malloc) to acquire virtual memory at run time . For data structures whose size (or lifetime) is known only at runtime Dynamic memory allocators manage an area of a process’ virtual memory known as the heap User stack Top of heap (brk ptr) Heap (via malloc) Uninitialized data (.bss) Initialized data (.data) Program text (.text) 0 Winter 2016 Memory Allocation 3 University of Washington Dynamic Memory Allocation Allocator organizes the heap as a collection of variable-sized blocks, which are either allocated or free . Allocator requests pages in heap region; virtual memory hardware and OS kernel allocate these pages to the process . -

Unleashing the Power of Allocator-Aware Software
P2126R0 2020-03-02 Pablo Halpern (on behalf of Bloomberg): [email protected] John Lakos: [email protected] Unleashing the Power of Allocator-Aware Software Infrastructure NOTE: This white paper (i.e., this is not a proposal) is intended to motivate continued investment in developing and maturing better memory allocators in the C++ Standard as well as to counter misinformation about allocators, their costs and benefits, and whether they should have a continuing role in the C++ library and language. Abstract Local (arena) memory allocators have been demonstrated to be effective at improving runtime performance both empirically in repeated controlled experiments and anecdotally in a variety of real-world applications. The initial development and subsequent maintenance effort of implementing bespoke data structures using custom memory allocation, however, are typically substantial and often untenable, especially in the limited timeframes that urgent business needs impose. To address such recurring performance needs effectively across the enterprise, Bloomberg has adopted a consistent, ubiquitous allocator-aware software infrastructure (AASI) based on the PMR-style1 plug-in memory allocator protocol pioneered at Bloomberg and adopted into the C++17 Standard Library. In this paper, we highlight the essential mechanics and subtle nuances of programing on top of Bloomberg’s AASI platform. In addition to delineating how to obtain performance gains safely at minimal development cost, we explore many of the inherent collateral benefits — such as object placement, metrics gathering, testing, debugging, and so on — that an AASI naturally affords. After reading this paper and surveying the available concrete allocators (provided in Appendix A), a competent C++ developer should be adequately equipped to extract substantial performance and other collateral benefits immediately using our AASI. -

P1083r2 | Move Resource Adaptor from Library TS to the C++ WP
P1083r2 | Move resource_adaptor from Library TS to the C++ WP Pablo Halpern [email protected] 2018-11-13 | Target audience: LWG 1 Abstract When the polymorphic allocator infrastructure was moved from the Library Fundamentals TS to the C++17 working draft, pmr::resource_adaptor was left behind. The decision not to move pmr::resource_adaptor was deliberately conservative, but the absence of resource_adaptor in the standard is a hole that must be plugged for a smooth transition to the ubiquitous use of polymorphic_allocator, as proposed in P0339 and P0987. This paper proposes that pmr::resource_adaptor be moved from the LFTS and added to the C++20 working draft. 2 History 2.1 Changes from R1 to R2 (in San Diego) • Paper was forwarded from LEWG to LWG on Tuesday, 2018-10-06 • Copied the formal wording from the LFTS directly into this paper • Minor wording changes as per initial LWG review • Rebased to the October 2018 draft of the C++ WP 2.2 Changes from R0 to R1 (pre-San Diego) • Added a note for LWG to consider clarifying the alignment requirements for resource_adaptor<A>::do_allocate(). • Changed rebind type from char to byte. • Rebased to July 2018 draft of the C++ WP. 3 Motivation It is expected that more and more classes, especially those that would not otherwise be templates, will use pmr::polymorphic_allocator<byte> to allocate memory. In order to pass an allocator to one of these classes, the allocator must either already be a polymorphic allocator, or must be adapted from a non-polymorphic allocator. The process of adaptation is facilitated by pmr::resource_adaptor, which is a simple class template, has been in the LFTS for a long time, and has been fully implemented. -

The Slab Allocator: an Object-Caching Kernel Memory Allocator
The Slab Allocator: An Object-Caching Kernel Memory Allocator Jeff Bonwick Sun Microsystems Abstract generally superior in both space and time. Finally, Section 6 describes the allocator’s debugging This paper presents a comprehensive design over- features, which can detect a wide variety of prob- view of the SunOS 5.4 kernel memory allocator. lems throughout the system. This allocator is based on a set of object-caching primitives that reduce the cost of allocating complex objects by retaining their state between uses. These 2. Object Caching same primitives prove equally effective for manag- Object caching is a technique for dealing with ing stateless memory (e.g. data pages and temporary objects that are frequently allocated and freed. The buffers) because they are space-efficient and fast. idea is to preserve the invariant portion of an The allocator’s object caches respond dynamically object’s initial state — its constructed state — to global memory pressure, and employ an object- between uses, so it does not have to be destroyed coloring scheme that improves the system’s overall and recreated every time the object is used. For cache utilization and bus balance. The allocator example, an object containing a mutex only needs also has several statistical and debugging features to have mutex_init() applied once — the first that can detect a wide range of problems throughout time the object is allocated. The object can then be the system. freed and reallocated many times without incurring the expense of mutex_destroy() and 1. Introduction mutex_init() each time. An object’s embedded locks, condition variables, reference counts, lists of The allocation and freeing of objects are among the other objects, and read-only data all generally qual- most common operations in the kernel. -

An Evolutionary Study of Linux Memory Management for Fun and Profit Jian Huang, Moinuddin K
An Evolutionary Study of Linux Memory Management for Fun and Profit Jian Huang, Moinuddin K. Qureshi, and Karsten Schwan, Georgia Institute of Technology https://www.usenix.org/conference/atc16/technical-sessions/presentation/huang This paper is included in the Proceedings of the 2016 USENIX Annual Technical Conference (USENIX ATC ’16). June 22–24, 2016 • Denver, CO, USA 978-1-931971-30-0 Open access to the Proceedings of the 2016 USENIX Annual Technical Conference (USENIX ATC ’16) is sponsored by USENIX. An Evolutionary Study of inu emory anagement for Fun and rofit Jian Huang, Moinuddin K. ureshi, Karsten Schwan Georgia Institute of Technology Astract the patches committed over the last five years from 2009 to 2015. The study covers 4587 patches across Linux We present a comprehensive and uantitative study on versions from 2.6.32.1 to 4.0-rc4. We manually label the development of the Linux memory manager. The each patch after carefully checking the patch, its descrip- study examines 4587 committed patches over the last tions, and follow-up discussions posted by developers. five years (2009-2015) since Linux version 2.6.32. In- To further understand patch distribution over memory se- sights derived from this study concern the development mantics, we build a tool called MChecker to identify the process of the virtual memory system, including its patch changes to the key functions in mm. MChecker matches distribution and patterns, and techniues for memory op- the patches with the source code to track the hot func- timizations and semantics. Specifically, we find that tions that have been updated intensively. -

Review Der Linux Kernel Sourcen Von 4.9 Auf 4.10
Review der Linux Kernel Sourcen von 4.9 auf 4.10 Reviewed by: Tested by: stecan stecan Period of Review: Period of Test: From: Thursday, 11 January 2018 07:26:18 o'clock +01: From: Thursday, 11 January 2018 07:26:18 o'clock +01: To: Thursday, 11 January 2018 07:44:27 o'clock +01: To: Thursday, 11 January 2018 07:44:27 o'clock +01: Report automatically generated with: LxrDifferenceTable, V0.9.2.548 Provided by: Certified by: Approved by: Account: stecan Name / Department: Date: Friday, 4 May 2018 13:43:07 o'clock CEST Signature: Review_4.10_0_to_1000.pdf Page 1 of 793 May 04, 2018 Review der Linux Kernel Sourcen von 4.9 auf 4.10 Line Link NR. Descriptions 1 .mailmap#0140 Repo: 9ebf73b275f0 Stephen Tue Jan 10 16:57:57 2017 -0800 Description: mailmap: add codeaurora.org names for nameless email commits ----------- Some codeaurora.org emails have crept in but the names don't exist for them. Add the names for the emails so git can match everyone up. Link: http://lkml.kernel.org/r/[email protected] 2 .mailmap#0154 3 .mailmap#0160 4 CREDITS#2481 Repo: 0c59d28121b9 Arnaldo Mon Feb 13 14:15:44 2017 -0300 Description: MAINTAINERS: Remove old e-mail address ----------- The ghostprotocols.net domain is not working, remove it from CREDITS and MAINTAINERS, and change the status to "Odd fixes", and since I haven't been maintaining those, remove my address from there. CREDITS: Remove outdated address information ----------- This address hasn't been accurate for several years now. -

Fast Efficient Fixed-Size Memory Pool: No Loops and No Overhead
COMPUTATION TOOLS 2012 : The Third International Conference on Computational Logics, Algebras, Programming, Tools, and Benchmarking Fast Efficient Fixed-Size Memory Pool No Loops and No Overhead Ben Kenwright School of Computer Science Newcastle University Newcastle, United Kingdom, [email protected] Abstract--In this paper, we examine a ready-to-use, robust, it can be used in conjunction with an existing system to and computationally fast fixed-size memory pool manager provide a hybrid solution with minimum difficulty. On with no-loops and no-memory overhead that is highly suited the other hand, multiple instances of numerous fixed-sized towards time-critical systems such as games. The algorithm pools can be used to produce a general overall flexible achieves this by exploiting the unused memory slots for general solution to work in place of the current system bookkeeping in combination with a trouble-free indexing memory manager. scheme. We explain how it works in amalgamation with Alternatively, in some time critical systems such as straightforward step-by-step examples. Furthermore, we games; system allocations are reduced to a bare minimum compare just how much faster the memory pool manager is to make the process run as fast as possible. However, for when compared with a system allocator (e.g., malloc) over a a dynamically changing system, it is necessary to allocate range of allocations and sizes. memory for changing resources, e.g., data assets Keywords-memory pools; real-time; memory allocation; (graphical images, sound files, scripts) which are loaded memory manager; memory de-allocation; dynamic memory dynamically at runtime. -

OMV Crash 25Feb2020 Syslog
Feb 25 00:00:00 prometheus rsyslogd: [origin software="rsyslogd" swVersion="8.1901.0" x-pid="858" x-info="https://www.rsyslog.com"] rsyslogd was HUPed Feb 25 00:00:00 prometheus systemd[1]: logrotate.service: Succeeded. Feb 25 00:00:00 prometheus systemd[1]: Started Rotate log files. Feb 25 00:00:01 prometheus CRON[10420]: (root) CMD (/usr/sbin/omv- mkrrdgraph >/dev/null 2>&1) Feb 25 00:09:00 prometheus systemd[1]: Starting Clean php session files... Feb 25 00:09:00 prometheus sessionclean[10668]: PHP Warning: PHP Startup: Unable to load dynamic library '/usr/lib/php/20151012/pam.so' - /usr/lib/php/20151012/pam.so: cannot open shared object file: No such file or directory in Unknown on line 0 Feb 25 00:09:00 prometheus sessionclean[10668]: PHP Warning: PHP Startup: Unable to load dynamic library '/usr/lib/php/20151012/pam.so' - /usr/lib/php/20151012/pam.so: cannot open shared object file: No such file or directory in Unknown on line 0 Feb 25 00:09:00 prometheus sessionclean[10668]: PHP Warning: PHP Startup: Unable to load dynamic library '/usr/lib/php/20151012/pam.so' - /usr/lib/php/20151012/pam.so: cannot open shared object file: No such file or directory in Unknown on line 0 Feb 25 00:09:00 prometheus systemd[1]: phpsessionclean.service: Succeeded. Feb 25 00:09:00 prometheus systemd[1]: Started Clean php session files. Feb 25 00:09:01 prometheus CRON[10770]: (root) CMD ( [ -x /usr/lib/ php/sessionclean ] && if [ ! -d /run/systemd/system ]; then /usr/lib/ php/sessionclean; fi) Feb 25 00:15:01 prometheus CRON[10858]: (root) CMD (/usr/sbin/omv- mkrrdgraph >/dev/null 2>&1) Feb 25 00:17:01 prometheus CRON[10990]: (root) CMD ( cd / && run- parts --report /etc/cron.hourly) Feb 25 00:17:01 prometheus postfix/postsuper[10993]: fatal: scan_dir_push: open directory hold: No such file or directory Feb 25 00:30:01 prometheus CRON[11200]: (root) CMD (/usr/sbin/omv- mkrrdgraph >/dev/null 2>&1) Feb 25 00:39:00 prometheus systemd[1]: Starting Clean php session files.. -

Open Source Practice of LG Electronics
Open Source Practice of LG Electronics Hyo Jun Im Software Platform Laboratory, LG Electronics Introduction to LG Electronics LG Electronics is a global leader and technology innovator in consumer electronics, mobile communications and home appliances. Overview This presentation covers both the open source compliance and open source engagement Compliance LG Community Engagement Open Source Compliance How LG Electronics built the open source compliance process from scratch. Steps for Building Up Open Source Compliance Process | Kick-starting open source compliance | Raising awareness | Setting up the process | Filling holes in the process | Efficient open source compliance Kick-starting Open Source Compliance | Challenges > Lack of knowledge on open source compliance > Lack of verification tools | What we did > Just rushed into writing the open source software notice in the user manual > Manual open source identification and verification | What we got > Basic knowledge of popular open source licenses > Need for automated verification tools > Knowledge on practical issues with open source compliance Raising Awareness | Introduction to relevant lawsuit case | Online / Offline training | Escalation of the open source compliance issues to management | Help from outside experts Industry Lawsuit Case • 2006 Set the precedent that the sale of a product can be prohibited 2007 • Distributors can be held responsible, and lawsuits filed against them • 2008 Similar to the case with Skype • 2010 Forced to give TVs to charity organizations as well as