Understanding Peak Floating-Point Performance Claims
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CUDA by Example
CUDA by Example AN INTRODUCTION TO GENERAL-PURPOSE GPU PROGRAMMING JASON SaNDERS EDWARD KANDROT Upper Saddle River, NJ • Boston • Indianapolis • San Francisco New York • Toronto • Montreal • London • Munich • Paris • Madrid Capetown • Sydney • Tokyo • Singapore • Mexico City Sanders_book.indb 3 6/12/10 3:15:14 PM Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trademark claim, the designations have been printed with initial capital letters or in all capitals. The authors and publisher have taken care in the preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. NVIDIA makes no warranty or representation that the techniques described herein are free from any Intellectual Property claims. The reader assumes all risk of any such claims based on his or her use of these techniques. The publisher offers excellent discounts on this book when ordered in quantity for bulk purchases or special sales, which may include electronic versions and/or custom covers and content particular to your business, training goals, marketing focus, and branding interests. For more information, please contact: U.S. Corporate and Government Sales (800) 382-3419 [email protected] For sales outside the United States, please contact: International Sales [email protected] Visit us on the Web: informit.com/aw Library of Congress Cataloging-in-Publication Data Sanders, Jason. -

Bitfusion Guide to CUDA Installation Bitfusion Guides Bitfusion: Bitfusion Guide to CUDA Installation
WHITE PAPER–OCTOBER 2019 Bitfusion Guide to CUDA Installation Bitfusion Guides Bitfusion: Bitfusion Guide to CUDA Installation Table of Contents Purpose 3 Introduction 3 Some Sources of Confusion 4 So Many Prerequisites 4 Installing the NVIDIA Repository 4 Installing the NVIDIA Driver 6 Installing NVIDIA CUDA 6 Installing cuDNN 7 Speed It Up! 8 Upgrading CUDA 9 WHITE PAPER | 2 Bitfusion: Bitfusion Guide to CUDA Installation Purpose Bitfusion FlexDirect provides a GPU virtualization solution. It allows you to use the GPUs, or even partial GPUs (e.g., half of a GPU, or a quarter, or one-third of a GPU), on different servers as if they were attached to your local machine, a machine on which you can now run a CUDA application even though it has no GPUs of its own. Since Bitfusion FlexDirect software and ML/AI (machine learning/artificial intelligence) applications require other CUDA libraries and drivers, this document describes how to install the prerequisite software for both Bitfusion FlexDirect and for various ML/AI applications. If you already have your CUDA drivers and libraries installed, you can skip ahead to the chapter on installing Bitfusion FlexDirect. This document gives instruction and examples for Ubuntu, Red Hat, and CentOS systems. Introduction Bitfusion’s software tool is called FlexDirect. FlexDirect easily installs with a single command, but installing the third-party prerequisite drivers and libraries, plus any application and its prerequisite software, can seem a Gordian Knot to users new to CUDA code and ML/AI applications. We will begin untangling the knot with a table of the components involved. -

Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and Power
Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and power ITSC 3181 Introduction to Computer Architecture https://passlaB.githuB.io/ITSC3181/ Department of Computer Science Yonghong Yan [email protected] https://passlab.github.io/yanyh/ Lectures for Chapter 1 and C Basics Computer Abstractions and Technology • Lecture 01: Chapter 1 – 1.1 – 1.4: Introduction, great ideas, Moore’s law, aBstraction, computer components, and program execution • Lecture 02: C Basics; Memory and Binary Systems • Lecture 03: Number System, Compilation, Assembly, Linking and Program Execution ☛• Lecture 04: Chapter 1 – 1.6 – 1.7: Performance, power and technology trends • Lecture 05: – 1.8 - 1.9: Multiprocessing and Benchmarking 2 § 1.6 Performance 1.6 Defining Performance • Which airplane has the best performance? Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 100 200 300 400 500 0 2000 4000 6000 8000 10000 Passenger Capacity Cruising Range (miles) Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 500 1000 1500 0 100000 200000 300000 400000 Cruising Speed (mph) Passengers x mph 3 Response Time and Throughput • Response time çè Latency – How long it takes to do a task • Throughput çè Bandwidth – Total work done per unit time • e.g., tasks/transactions/… per hour • How are response time and throughput affected by – Replacing the processor with a faster version? – Adding more processors? • We’ll focus on response time for now… 4 Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y”, i.e. -

Partial Reconfiguration: a Simple Tutorial
Partial Reconfiguration: A Simple Tutorial Richard Neil Pittman Microsoft Research February 2012 Technical Report MSR-TR 2012-19 Microsoft Research Microsoft Corporation One Microsoft Way Redmond, WA 98052 Partial Reconfiguration: A Simple Tutorial A Tutorial for XILINX FPGAs Neil Pittman – 2/12, version 1.0 Introduction Partial Reconfiguration is a feature of modern FPGAs that allows a subset of the logic fabric of a FPGA to dynamically reconfigure while the remaining logic continues to operate unperturbed. Xilinx has provided this feature in their high end FPGAs, the Virtex series, in limited access BETA since the late 1990s. More recently it is a production feature supported by their tools and across their devices since the release of ISE 12. The support for this feature continues to improve in the more recent release of ISE 13. Altera has promised this feature for their new high end devices, but this has not yet materialized. Partial Reconfiguration of FPGAs is a compelling design concept for general purpose reconfigurable systems for its flexibility and extensibility. Despite the significant improvements in software tools and support, the Xilinx partial reconfiguration design option has a reputation for being an expert level flow that is difficult to use. In this tutorial we will show that it can actually be quite simple. As a case study, we apply Partial Reconfiguration to the Simple Interface for Reconfigurable Computing (SIRC) toolset. Combining SIRC and partial reconfiguration makes the idea of general purpose hardware and software user systems deployed on demand on generic platforms viable. The goal is to make developers more confident in the practicality of this concept and in their own ability to use it, so that more will take advantage of what it has to offer. -

Parallel Architectures and Algorithms for Large-Scale Nonlinear Programming
Parallel Architectures and Algorithms for Large-Scale Nonlinear Programming Carl D. Laird Associate Professor, School of Chemical Engineering, Purdue University Faculty Fellow, Mary Kay O’Connor Process Safety Center Laird Research Group: http://allthingsoptimal.com Landscape of Scientific Computing 10$ 1$ 50%/year 20%/year Clock&Rate&(GHz)& 0.1$ 0.01$ 1980$ 1985$ 1990$ 1995$ 2000$ 2005$ 2010$ Year& [Steven Edwards, Columbia University] 2 Landscape of Scientific Computing Clock-rate, the source of past speed improvements have stagnated. Hardware manufacturers are shifting their focus to energy efficiency (mobile, large10" data centers) and parallel architectures. 12" 10" 1" 8" 6" #"of"Cores" Clock"Rate"(GHz)" 0.1" 4" 2" 0.01" 0" 1980" 1985" 1990" 1995" 2000" 2005" 2010" Year" 3 “… over a 15-year span… [problem] calculations improved by a factor of 43 million. [A] factor of roughly 1,000 was attributable to faster processor speeds, … [yet] a factor of 43,000 was due to improvements in the efficiency of software algorithms.” - attributed to Martin Grotschel [Steve Lohr, “Software Progress Beats Moore’s Law”, New York Times, March 7, 2011] Landscape of Computing 5 Landscape of Computing High-Performance Parallel Architectures Multi-core, Grid, HPC clusters, Specialized Architectures (GPU) 6 Landscape of Computing High-Performance Parallel Architectures Multi-core, Grid, HPC clusters, Specialized Architectures (GPU) 7 Landscape of Computing data VM iOS and Android device sales High-Performance have surpassed PC Parallel Architectures iPhone performance -

Xilinx-Solution-Brief-Bluedot.Pdf
SOLUTION BRIEF Product Name DeepField-SR – Deep Learning based Video Super Resolution Accelerator INTRODUCTION DeepField-SR is a fixed functional hardware accelerator leveraging Xilinx Alveo Cards to offer the highest computational efficiency for Video Super Resolution. Based Solution Image on proprietary Neural Network trained with real world video data from the internet and fusing spatio-temporal information in multiple frames, it produces superior high resolution video quality. BENEFITS Key Features Comparing with EDSR(NTIRE 2017) on Tesla V100 > A fixed functional hardware > 45x faster than GPU accelerator offering high throughput > Scalable architecture to support multiple FPGA cards > Low upscaling latency > Deep Neural Network suitable for resource limited FPGA > 0.03 better quality assessment in LPIPS metric than > Deep Neural Network trained EDSR with real world video data > 44x lower latency than GPU > Designed with High Level Synthesis > Easy to update and upgrade per market demands > 1x FPGA card required Adaptable. Intelligent. © Copyright 2020 Xilinx SOLUTION OVERVIEW DeepField-SR is deployable on both public cloud and on-premise with Xilinx Alveo U200/U50 Accelerator Cards. As it is designed in scalable architecture and supports multiple FPGA cards, it can flexibly respond to various resolution upscale request. Its runtime performance on single Alveo U50 is 11 ~ 14fps to upscale video up to 4K resolution. The API is integrated within an FFmpeg workflow, meaning that simple command enables DeepField-SR acceleration and upscaling user input video. TAKE THE NEXT STEP Learn more about BLUEDOT Inc. For DeepField-SR quality evaluation, please visit http://kokoon.cloud Reach out to BLUEDOT sales at [email protected] Corporate Headquarters Europe Japan Asia Pacific Pte. -

(GPU) Computing
Graphics Processing Unit (GPU) computing This section describes the graphics processing unit (GPU) computing feature of OptiSystem. Note: The GPU computing feature is only configurable with OptiSystem Version 11 (or higher) What is GPU computing? GPU computing or GPGPU takes advantage of a computer’s grahics processing card to augment the speed of general purpose scientific and engineering computing tasks. Compute Unified Device Architecture (CUDA) implementation for OptiSystem NVIDIA revolutionized the GPGPU and accelerated computing when it introduced a new parallel computing architecture: Compute Unified Device Architecture (CUDA). CUDA is both a hardware and software architecture for issuing and managing computations within the GPU, thus allowing it to operate as a generic data-parallel computing device. CUDA allows the programmer to take advantage of the parallel computing power of an NVIDIA graphics card to perform general purpose computations. OptiSystem CUDA implementation The OptiSystem model for GPU computing involves using a central processing unit (CPU) and GPU together in a heterogeneous co-processing computing model. The sequential part of the application runs on the CPU and the computationally-intensive part is accelerated by the GPU. In the OptiSystem GPU programming model, the application has been modified to map the compute-intensive kernels to the GPU. The remainder of the application remains within the CPU. CUDA parallel computing architecture The NVIDIA CUDA parallel computing architecture is enabled on GeForce®, Quadro®, and Tesla™ products. Whereas GeForce and Quadro are designed for consumer graphics and professional visualization respectively, the Tesla product family is designed ground-up for parallel computing and offers exclusive computing 3 GRAPHICS PROCESSING UNIT (GPU) COMPUTING features, and is the recommended choice for the OptiSystem GPU. -

UNIT 8B a Full Adder
UNIT 8B Computer Organization: Levels of Abstraction 15110 Principles of Computing, 1 Carnegie Mellon University - CORTINA A Full Adder C ABCin Cout S in 0 0 0 A 0 0 1 0 1 0 B 0 1 1 1 0 0 1 0 1 C S out 1 1 0 1 1 1 15110 Principles of Computing, 2 Carnegie Mellon University - CORTINA 1 A Full Adder C ABCin Cout S in 0 0 0 0 0 A 0 0 1 0 1 0 1 0 0 1 B 0 1 1 1 0 1 0 0 0 1 1 0 1 1 0 C S out 1 1 0 1 0 1 1 1 1 1 ⊕ ⊕ S = A B Cin ⊕ ∧ ∨ ∧ Cout = ((A B) C) (A B) 15110 Principles of Computing, 3 Carnegie Mellon University - CORTINA Full Adder (FA) AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 4 Carnegie Mellon University - CORTINA 2 Another Full Adder (FA) http://students.cs.tamu.edu/wanglei/csce350/handout/lab6.html AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 5 Carnegie Mellon University - CORTINA 8-bit Full Adder A7 B7 A2 B2 A1 B1 A0 B0 1-bit 1-bit 1-bit 1-bit ... Cout Full Full Full Full Cin Adder Adder Adder Adder S7 S2 S1 S0 AB 8 ⁄ ⁄ 8 C 8-bit C out FA in ⁄ 8 S 15110 Principles of Computing, 6 Carnegie Mellon University - CORTINA 3 Multiplexer (MUX) • A multiplexer chooses between a set of inputs. D1 D 2 MUX F D3 D ABF 4 0 0 D1 AB 0 1 D2 1 0 D3 1 1 D4 http://www.cise.ufl.edu/~mssz/CompOrg/CDAintro.html 15110 Principles of Computing, 7 Carnegie Mellon University - CORTINA Arithmetic Logic Unit (ALU) OP 1OP 0 Carry In & OP OP 0 OP 1 F 0 0 A ∧ B 0 1 A ∨ B 1 0 A 1 1 A + B http://cs-alb-pc3.massey.ac.nz/notes/59304/l4.html 15110 Principles of Computing, 8 Carnegie Mellon University - CORTINA 4 Flip Flop • A flip flop is a sequential circuit that is able to maintain (save) a state. -

Massively Parallel Computing with CUDA
Massively Parallel Computing with CUDA Antonino Tumeo Politecnico di Milano 1 GPUs have evolved to the point where many real world applications are easily implemented on them and run significantly faster than on multi-core systems. Future computing architectures will be hybrid systems with parallel-core GPUs working in tandem with multi-core CPUs. Jack Dongarra Professor, University of Tennessee; Author of “Linpack” Why Use the GPU? • The GPU has evolved into a very flexible and powerful processor: • It’s programmable using high-level languages • It supports 32-bit and 64-bit floating point IEEE-754 precision • It offers lots of GFLOPS: • GPU in every PC and workstation What is behind such an Evolution? • The GPU is specialized for compute-intensive, highly parallel computation (exactly what graphics rendering is about) • So, more transistors can be devoted to data processing rather than data caching and flow control ALU ALU Control ALU ALU Cache DRAM DRAM CPU GPU • The fast-growing video game industry exerts strong economic pressure that forces constant innovation GPUs • Each NVIDIA GPU has 240 parallel cores NVIDIA GPU • Within each core 1.4 Billion Transistors • Floating point unit • Logic unit (add, sub, mul, madd) • Move, compare unit • Branch unit • Cores managed by thread manager • Thread manager can spawn and manage 12,000+ threads per core 1 Teraflop of processing power • Zero overhead thread switching Heterogeneous Computing Domains Graphics Massive Data GPU Parallelism (Parallel Computing) Instruction CPU Level (Sequential -
Clock Rate Improves Roughly Proportional to Improvement in L • Number of Transistors Improves Proportional to L2 (Or Faster)
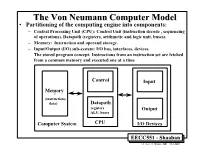
TheThe VonVon NeumannNeumann ComputerComputer ModelModel • Partitioning of the computing engine into components: – Central Processing Unit (CPU): Control Unit (instruction decode , sequencing of operations), Datapath (registers, arithmetic and logic unit, buses). – Memory: Instruction and operand storage. – Input/Output (I/O) sub-system: I/O bus, interfaces, devices. – The stored program concept: Instructions from an instruction set are fetched from a common memory and executed one at a time Control Input Memory - (instructions, data) Datapath registers Output ALU, buses Computer System CPU I/O Devices EECC551 - Shaaban #1 Lec # 1 Winter 2001 12-3-2001 Generic CPU Machine Instruction Execution Steps Instruction Obtain instruction from program storage Fetch Instruction Determine required actions and instruction size Decode Operand Locate and obtain operand data Fetch Execute Compute result value or status Result Deposit results in storage for later use Store Next Determine successor or next instruction Instruction EECC551 - Shaaban #2 Lec # 1 Winter 2001 12-3-2001 HardwareHardware ComponentsComponents ofof AnyAny ComputerComputer Five classic components of all computers: 1. Control Unit; 2. Datapath; 3. Memory; 4. Input; 5. Output } Processor Computer Keyboard, Mouse, etc. Processor Memory Devices (active) (passive) Control Input (where Unit programs, data Disk Datapath live when Output running) Display, Printer, etc. EECC551 - Shaaban #3 Lec # 1 Winter 2001 12-3-2001 CPUCPU OrganizationOrganization • Datapath Design: – Capabilities & performance characteristics of principal Functional Units (FUs): • (e.g., Registers, ALU, Shifters, Logic Units, ...) – Ways in which these components are interconnected (buses connections, multiplexors, etc.). – How information flows between components. • Control Unit Design: – Logic and means by which such information flow is controlled. – Control and coordination of FUs operation to realize the targeted Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram). -

Alveo U50 Data Center Accelerator Card Installation Guide
Alveo U50 Data Center Accelerator Card Installation Guide UG1370 (v1.6) June 4, 2020 Revision History Revision History The following table shows the revision history for this document. Section Revision Summary 06/04/2020 Version 1.6 Chapter 1: Introduction Updated the information. Card Features Added new section. Chapter 2: Card Interfaces and Details Added a caution. Known Issues • Added a known issue about installing the U50 card deployment package. • Added a known issue about downgrading to a beta platform. Downgrading Packages Added information about downgrading to a beta platform. Downgrading Packages Added information about downgrading to a beta platform. 02/27/2020 Version 1.5 XRT and Deployment Platform Installation Procedures on Replaced steps 4, 6, 7, 8, and 9 to document the new RedHat and CentOS installation steps for U50. Replaced all mentions of zip files with tar.gz. XRT and Deployment Platform Installation Procedures on Replaced steps 1, 2, 3, and the log file of step 6 to document Ubuntu the new installation steps for U50. Replaced all mentions of zip files with tar.gz. Running lspci Revised log file in step 2. Running xbmgmt flash --scan Revised output, platform, and ID information in step 1. Upgrading Packages Updated step 1 to include a link to chapter 4; removed steps 2-6. Upgrading Packages Updated step 1 to include a link to chapter 4; removed steps 2-6. 01/07/2020 Version 1.4 Installing the Card Updated to add notes about UL Listed Servers and card handling. 12/18/2019 Version 1.3 General Updated output logs. -

Atmega165p Datasheet
Features • High Performance, Low Power Atmel® AVR® 8-Bit Microcontroller • Advanced RISC Architecture – 130 Powerful Instructions – Most Single Clock Cycle Execution – 32 × 8 General Purpose Working Registers – Fully Static Operation – Up to 16 MIPS Throughput at 16 MHz – On-Chip 2-cycle Multiplier • High Endurance Non-volatile Memory segments – 16 Kbytes of In-System Self-programmable Flash program memory – 512 Bytes EEPROM – 1 Kbytes Internal SRAM 8-bit – Write/Erase cyles: 10,000 Flash/100,000 EEPROM(1)(3) – Data retention: 20 years at 85°C/100 years at 25°C(2)(3) Microcontroller – Optional Boot Code Section with Independent Lock Bits In-System Programming by On-chip Boot Program with 16K Bytes True Read-While-Write Operation – Programming Lock for Software Security In-System • JTAG (IEEE std. 1149.1 compliant) Interface – Boundary-scan Capabilities According to the JTAG Standard Programmable – Extensive On-chip Debug Support – Programming of Flash, EEPROM, Fuses, and Lock Bits through the JTAG Interface Flash • Peripheral Features – Two 8-bit Timer/Counters with Separate Prescaler and Compare Mode – One 16-bit Timer/Counter with Separate Prescaler, Compare Mode, and Capture Mode – Real Time Counter with Separate Oscillator –Four PWM Channels ATmega165P – 8-channel, 10-bit ADC – Programmable Serial USART ATmega165PV – Master/Slave SPI Serial Interface – Universal Serial Interface with Start Condition Detector – Programmable Watchdog Timer with Separate On-chip Oscillator – On-chip Analog Comparator Preliminary – Interrupt and Wake-up