Performance Evaluation of Embedded Microcomputers for Avionics Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CPU ボードカタログ サポート CPU Intel :Core I7、Xeon-E5 Freescale :T4240、P4080、MPC8640D AMD :Radeon HD 6970M、HD 7970M GPGPU NVIDIA :Fermi、Kepler Architecture GPGPU
組込みシステム向け CPU ボードカタログ サポート CPU Intel :Core i7、Xeon-E5 Freescale :T4240、P4080、MPC8640D AMD :Radeon HD 6970M、HD 7970M GPGPU NVIDIA :Fermi、Kepler Architecture GPGPU サポートバス規格 OpenVPX VME/VXS CompactPCI PMC/XMC ATCA/AMC PCI Express 403102 Ⓒ MISH International Co., Ltd. MISH International Co., Ltd. ミッシュインターナショナルでは CPU ボードをスピーディに 導入頂けますよう、次のような サービスを提供しております CPU ボードのお貸出しサービス CPU ボードの性能評価検証サービス ミッシュインターナショナルでは、ユーザが実際に製品を導入する前に性能評価を実施していただけ ミッシュインターナショナルでは、専門の CPU ボードサポート技術者がお客様のご要望に応じて CPU ますよう各種評価用 CPU ボードをお貸出ししています。お貸出し時には、リアルタイム OS を含めた ボードの性能を評価・検証させていただきます。たとえばFFT の処理速度やボード間のデータ転送スピー CPU ボードに関するトータルな技術サポートを行っております。 ドの測定などユーザがシステムインテグレーションする上で必要なデータを検証の上、レポートさせて いただきます。(お客様のご要望内容によっては別途有償の場合もあります) CPU ボードの技術サポート ミッシュインターナショナルでは、専門のCPU ボードサポート技術者が導入前はもちろん、導入後もハー ド・ソフトの両面からお客様の技術サポートをいたします。CPU ボードのドライバソフトウェアやアプ リケーションの開発方法等をトータルにバックアップいたします。また、リアルタイム OS を含んだシ CPU ボード用フレームワークソフトウェアの開発サービス ステムインテグレーッションに関するアドバイスも対応しています。 CPU ボードを含んだ組込み用システムを構 築する上では、CPU ボードのハード・ソフ トに関する技術的な知識経験はもちろんです が、CPU ボード以外の A/D、D/A、DIO ボー ド等の各種 I/O ボードとのシームレスな高速 データ通信やリアルタイム OS を使用したイ ンテグレーションが必要です。当社では複数 のボードを使ったマルチ CPU ボードシステ ムやレーダ、ソナー、移動体通信等の無線信 号のリアルタイム処理等をトータルにサポートしています。全体的なデータのパスをサポートした『フ レームワークソフトウェア』の開発もお手伝いしています。ユーザは『フレームワークソフトウェア』 の開発を当社へ外注することにより、アプリケーションソフトウェアの開発や FPGA の開発に専念する ことが出来ます。(お客様のご要望内容によっては別途有償の場合もあります) インテル製 プロセッサ搭載 CPU ボード ボード CPU スピード 拡張 USB 耐環境 型名 プロセッサ メモリ NVRAM Ethernet インテル製 プロセッサ Core i7(Ivy Bridge)、 タイプ (Max) メザニン 2.0 仕様 Xeon E5-2648L x 2 32GB DDR3- 8MB NOR 1000BASE-T x 1 Level HDS6601 6U VPX 1.8GHz - 3 Xeon(8 Core) 搭載 CPU ボード (Sandy Bridge) -

Memory Hierarchy Memory Hierarchy
Memory Key challenge in modern computer architecture Lecture 2: different memory no point in blindingly fast computation if data can’t be and variable types moved in and out fast enough need lots of memory for big applications Prof. Mike Giles very fast memory is also very expensive [email protected] end up being pushed towards a hierarchical design Oxford University Mathematical Institute Oxford e-Research Centre Lecture 2 – p. 1 Lecture 2 – p. 2 CPU Memory Hierarchy Memory Hierarchy Execution speed relies on exploiting data locality 2 – 8 GB Main memory 1GHz DDR3 temporal locality: a data item just accessed is likely to be used again in the near future, so keep it in the cache ? 200+ cycle access, 20-30GB/s spatial locality: neighbouring data is also likely to be 6 used soon, so load them into the cache at the same 2–6MB time using a ‘wide’ bus (like a multi-lane motorway) L3 Cache 2GHz SRAM ??25-35 cycle access 66 This wide bus is only way to get high bandwidth to slow 32KB + 256KB main memory ? L1/L2 Cache faster 3GHz SRAM more expensive ??? 6665-12 cycle access smaller registers Lecture 2 – p. 3 Lecture 2 – p. 4 Caches Importance of Locality The cache line is the basic unit of data transfer; Typical workstation: typical size is 64 bytes 8 8-byte items. ≡ × 10 Gflops CPU 20 GB/s memory L2 cache bandwidth With a single cache, when the CPU loads data into a ←→ 64 bytes/line register: it looks for line in cache 20GB/s 300M line/s 2.4G double/s ≡ ≡ if there (hit), it gets data At worst, each flop requires 2 inputs and has 1 output, if not (miss), it gets entire line from main memory, forcing loading of 3 lines = 100 Mflops displacing an existing line in cache (usually least ⇒ recently used) If all 8 variables/line are used, then this increases to 800 Mflops. -

Wind Rose Data Comes in the Form >200,000 Wind Rose Images
Making Wind Speed and Direction Maps Rich Stromberg Alaska Energy Authority [email protected]/907-771-3053 6/30/2011 Wind Direction Maps 1 Wind rose data comes in the form of >200,000 wind rose images across Alaska 6/30/2011 Wind Direction Maps 2 Wind rose data is quantified in very large Excel™ spreadsheets for each region of the state • Fields: X Y X_1 Y_1 FILE FREQ1 FREQ2 FREQ3 FREQ4 FREQ5 FREQ6 FREQ7 FREQ8 FREQ9 FREQ10 FREQ11 FREQ12 FREQ13 FREQ14 FREQ15 FREQ16 SPEED1 SPEED2 SPEED3 SPEED4 SPEED5 SPEED6 SPEED7 SPEED8 SPEED9 SPEED10 SPEED11 SPEED12 SPEED13 SPEED14 SPEED15 SPEED16 POWER1 POWER2 POWER3 POWER4 POWER5 POWER6 POWER7 POWER8 POWER9 POWER10 POWER11 POWER12 POWER13 POWER14 POWER15 POWER16 WEIBC1 WEIBC2 WEIBC3 WEIBC4 WEIBC5 WEIBC6 WEIBC7 WEIBC8 WEIBC9 WEIBC10 WEIBC11 WEIBC12 WEIBC13 WEIBC14 WEIBC15 WEIBC16 WEIBK1 WEIBK2 WEIBK3 WEIBK4 WEIBK5 WEIBK6 WEIBK7 WEIBK8 WEIBK9 WEIBK10 WEIBK11 WEIBK12 WEIBK13 WEIBK14 WEIBK15 WEIBK16 6/30/2011 Wind Direction Maps 3 Data set is thinned down to wind power density • Fields: X Y • POWER1 POWER2 POWER3 POWER4 POWER5 POWER6 POWER7 POWER8 POWER9 POWER10 POWER11 POWER12 POWER13 POWER14 POWER15 POWER16 • Power1 is the wind power density coming from the north (0 degrees). Power 2 is wind power from 22.5 deg.,…Power 9 is south (180 deg.), etc… 6/30/2011 Wind Direction Maps 4 Spreadsheet calculations X Y POWER1 POWER2 POWER3 POWER4 POWER5 POWER6 POWER7 POWER8 POWER9 POWER10 POWER11 POWER12 POWER13 POWER14 POWER15 POWER16 Max Wind Dir Prim 2nd Wind Dir Sec -132.7365 54.4833 0.643 0.767 1.911 4.083 -

PPC400 Debugger C++ and JAVAC++ Aswell Asthe Debugging of the TPU
BDM-PPC400 Technical Information Technical PPC400 Debugger ■ Full HLL and ASM support available ■ Batch processing ■ Supports ELF/DWARF format ■ 3.3 volt support ■ Support for internal triggers ■ Break on code or data ■ Unlimited software breakpoints ■ Fast download (ETHERNET or PARALLEL) up to 600KB/sec The debugger for IBM PowerPC 400 family allows fast access to the BDM interface of the chip. Up to 450 KByte can be downloaded in 1 second. The systems supports C, C++ and JAVA as well as the debugging of the TPU. BDM-PPC400 14.06.13 TRACE32 - Technical Information 2 Features ❏ Active and Passive JTAG ❏ Variable Debug Clock Speed Debugger available ■ 10 kHz...5 MHz ■ 1/4 CPU Clock ■ 1/8 CPU Clock ❏ Software Compatible to In-Circuit ■ Variable up to 100 MHz (Pow- Emulator and Monitor erDebug only) ■ Operation System ■ PRACTICE ❏ ■ ASM Debugger Tr igger ■ HLL Debugger for C and C++ ■ Input from PODBUS ■ Peripheral Windows ■ Output to PODBUS ❏ High-Speed Download ❏ Support for EPROM/FLASH ■ Up to 450 KByte/sec Simulator ■ Breakpoints in ROM Area ■ 8, 16 and 32 Bit EPROM/ FLASH Emulation BDM-PPC400 Features TRACE32 - Technical Information 3 Connector Connector Type stanard 100 mil connector (BETRG, AMP, etc.) Connector 16 pin Signal Pin Pin Signal TDO 1 2 N/C TDI 3 4 TRST- (*) N/C 5 6 VCCS TCK 7 8 N/C TMS 9 10 N/C HALT- 11 12 N/C N/C 13 14 KEY N/C 15 16 GND BDM-PPC400 Connector TRACE32 - Technical Information 4 Operation Voltage Operation Voltage This list contains information on probes available for other voltage ranges. -

Make the Most out of Last Level Cache in Intel Processors In: Proceedings of the Fourteenth Eurosys Conference (Eurosys'19), Dresden, Germany, 25-28 March 2019
http://www.diva-portal.org Postprint This is the accepted version of a paper presented at EuroSys'19. Citation for the original published paper: Farshin, A., Roozbeh, A., Maguire Jr., G Q., Kostic, D. (2019) Make the Most out of Last Level Cache in Intel Processors In: Proceedings of the Fourteenth EuroSys Conference (EuroSys'19), Dresden, Germany, 25-28 March 2019. ACM Digital Library N.B. When citing this work, cite the original published paper. Permanent link to this version: http://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-244750 Make the Most out of Last Level Cache in Intel Processors Alireza Farshin∗† Amir Roozbeh∗ KTH Royal Institute of Technology KTH Royal Institute of Technology [email protected] Ericsson Research [email protected] Gerald Q. Maguire Jr. Dejan Kostić KTH Royal Institute of Technology KTH Royal Institute of Technology [email protected] [email protected] Abstract between Central Processing Unit (CPU) and Direct Random In modern (Intel) processors, Last Level Cache (LLC) is Access Memory (DRAM) speeds has been increasing. One divided into multiple slices and an undocumented hashing means to mitigate this problem is better utilization of cache algorithm (aka Complex Addressing) maps different parts memory (a faster, but smaller memory closer to the CPU) in of memory address space among these slices to increase order to reduce the number of DRAM accesses. the effective memory bandwidth. After a careful study This cache memory becomes even more valuable due to of Intel’s Complex Addressing, we introduce a slice- the explosion of data and the advent of hundred gigabit per aware memory management scheme, wherein frequently second networks (100/200/400 Gbps) [9]. -

Migration from IBM 750FX to MPC7447A by Douglas Hamilton European Applications Engineering Networking and Computing Systems Group Freescale Semiconductor, Inc
Freescale Semiconductor AN2808 Application Note Rev. 1, 06/2005 Migration from IBM 750FX to MPC7447A by Douglas Hamilton European Applications Engineering Networking and Computing Systems Group Freescale Semiconductor, Inc. Contents 1 Scope and Definitions 1. Scope and Definitions . 1 2. Feature Overview . 2 The purpose of this application note is to facilitate migration 3. 7447A Specific Features . 12 from IBM’s 750FX-based systems to Freescale’s 4. Programming Model . 16 MPC7447A. It addresses the differences between the 5. Hardware Considerations . 27 systems, explaining which features have changed and why, 6. Revision History . 30 before discussing the impact on migration in terms of hardware and software. Throughout this document the following references are used: • 750FX—which applies to Freescale’s MPC750, MPC740, MPC755, and MPC745 devices, as well as to IBM’s 750FX devices. Any features specific to IBM’s 750FX will be explicitly stated as such. • MPC7447A—which applies to Freescale’s MPC7450 family of products (MPC7450, MPC7451, MPC7441, MPC7455, MPC7445, MPC7457, MPC7447, and MPC7447A) except where otherwise stated. Because this document is to aid the migration from 750FX, which does not support L3 cache, the L3 cache features of the MPC745x devices are not mentioned. © Freescale Semiconductor, Inc., 2005. All rights reserved. Feature Overview 2 Feature Overview There are many differences between the 750FX and the MPC7447A devices, beyond the clear differences of the core complex. This section covers the differences between the cores and then other areas of interest including the cache configuration and system interfaces. 2.1 Cores The key processing elements of the G3 core complex used in the 750FX are shown below in Figure 1, and the G4 complex used in the 7447A is shown in Figure 2. -

EEMBC and the Purposes of Embedded Processor Benchmarking Markus Levy, President
EEMBC and the Purposes of Embedded Processor Benchmarking Markus Levy, President ISPASS 2005 Certified Performance Analysis for Embedded Systems Designers EEMBC: A Historical Perspective • Began as an EDN Magazine project in April 1997 • Replace Dhrystone • Have meaningful measure for explaining processor behavior • Developed business model • Invited worldwide processor vendors • A consortium was born 1 EEMBC Membership • Board Member • Membership Dues: $30,000 (1st year); $16,000 (subsequent years) • Access and Participation on ALL Subcommittees • Full Voting Rights • Subcommittee Member • Membership Dues Are Subcommittee Specific • Access to Specific Benchmarks • Technical Involvement Within Subcommittee • Help Determine Next Generation Benchmarks • Special Academic Membership EEMBC Philosophy: Standardized Benchmarks and Certified Scores • Member derived benchmarks • Determine the standard, the process, and the benchmarks • Open to industry feedback • Ensures all processor/compiler vendors are running the same tests • Certification process ensures credibility • All benchmark scores officially validated before publication • The entire benchmark environment must be disclosed 2 Embedded Industry: Represented by Very Diverse Applications • Networking • Storage, low- and high-end routers, switches • Consumer • Games, set top boxes, car navigation, smartcards • Wireless • Cellular, routers • Office Automation • Printers, copiers, imaging • Automotive • Engine control, Telematics Traditional Division of Embedded Applications Low High Power -

IBM Power System POWER8 Facts and Features
IBM Power Systems IBM Power System POWER8 Facts and Features April 29, 2014 IBM Power Systems™ servers and IBM BladeCenter® blade servers using IBM POWER7® and POWER7+® processors are described in a separate Facts and Features report dated July 2013 (POB03022-USEN-28). IBM Power Systems™ servers and IBM BladeCenter® blade servers using IBM POWER6® and POWER6+™ processors are described in a separate Facts and Features report dated April 2010 (POB03004-USEN-14). 1 IBM Power Systems Table of Contents IBM Power System S812L 4 IBM Power System S822 and IBM Power System S822L 5 IBM Power System S814 and IBM Power System S824 6 System Unit Details 7 Server I/O Drawers & Attachment 8 Physical Planning Characteristics 9 Warranty / Installation 10 Power Systems Software Support 11 Performance Notes & More Information 12 These notes apply to the description tables for the pages which follow: Y Standard / Supported Optional Optionally Available / Supported N/A or - Not Available / Supported or Not Applicable SOD Statement of General Direction announced SLES SUSE Linux Enterprise Server RHEL Red Hat Enterprise Linux a One x8 PCIe slots must contain a 4-port 1Gb Ethernet LAN available for client use b Use of expanded function storage backplane uses one PCIe slot Backplane provides dual high performance SAS controllers with 1.8 GB write cache expanded up to 7.2 GB with c compression plus Easy Tier function plus two SAS ports for running an EXP24S drawer d Full benchmark results are located at ibm.com/systems/power/hardware/reports/system_perf.html e Option is supported on IBM i only through VIOS. -

Ray Tracing on the Cell Processor
Ray Tracing on the Cell Processor Carsten Benthin† Ingo Wald Michael Scherbaum† Heiko Friedrich‡ †inTrace Realtime Ray Tracing GmbH SCI Institute, University of Utah ‡Saarland University {benthin, scherbaum}@intrace.com, [email protected], [email protected] Abstract band”) architectures1 to hide memory latencies, at exposing par- Over the last three decades, higher CPU performance has been allelism through SIMD units, and at multi-core architectures. At achieved almost exclusively by raising the CPU’s clock rate. Today, least for specialized tasks such as triangle rasterization, these con- the resulting power consumption and heat dissipation threaten to cepts have been proven as very powerful, and have made modern end this trend, and CPU designers are looking for alternative ways GPUs as fast as they are; for example, a Nvidia 7800 GTX offers of providing more compute power. In particular, they are looking 313 GFlops [16], 35 times more than a 2.2 GHz AMD Opteron towards three concepts: a streaming compute model, vector-like CPU. Today, there seems to be a convergence between CPUs and SIMD units, and multi-core architectures. One particular example GPUs, with GPUs—already using the streaming compute model, of such an architecture is the Cell Broadband Engine Architecture SIMD, and multi-core—become increasingly programmable, and (CBEA), a multi-core processor that offers a raw compute power CPUs are getting equipped with more and more cores and stream- of up to 200 GFlops per 3.2 GHz chip. The Cell bears a huge po- ing functionalities. Most commodity CPUs already offer 2–8 tential for compute-intensive applications like ray tracing, but also cores [1, 9, 10, 25], and desktop PCs with more cores can be built requires addressing the challenges caused by this processor’s un- by stacking and interconnecting smaller multi-core systems (mostly conventional architecture. -

IBM System P5 Quad-Core Module Based on POWER5+ Technology: Technical Overview and Introduction
Giuliano Anselmi Redpaper Bernard Filhol SahngShin Kim Gregor Linzmeier Ondrej Plachy Scott Vetter IBM System p5 Quad-Core Module Based on POWER5+ Technology: Technical Overview and Introduction The quad-core module (QCM) is based on the well-known POWER5™ dual-core module (DCM) technology. The dual-core POWER5 processor and the dual-core POWER5+™ processor are packaged with the L3 cache chip into a cost-effective DCM package. The QCM is a package that enables entry-level or midrange IBM® System p5™ servers to achieve additional processing density without increasing the footprint. Figure 1 shows the DCM and QCM physical views and the basic internal architecture. to I/O to I/O Core Core 1.5 GHz 1.5 GHz Enhanced Enhanced 1.9 MB MB 1.9 1.9 MB MB 1.9 L2 cache L2 L2 cache switch distributed switch distributed switch 1.9 GHz POWER5 Core Core core or CPU or core 1.5 GHz L3 Mem 1.5 GHz L3 Mem L2 cache L2 ctrl ctrl ctrl ctrl Enhanced distributed Enhanced 1.9 MB Shared Shared MB 1.9 Ctrl 1.9 GHz L3 Mem Ctrl POWER5 core or CPU or core 36 MB 36 MB 36 L3 cache L3 cache L3 DCM 36 MB QCM L3 cache L3 to memory to memory DIMMs DIMMs POWER5+ Dual-Core Module POWER5+ Quad-Core Module One Dual-Core-chip Two Dual-Core-chips plus two L3-cache-chips plus one L3-cache-chip Figure 1 DCM and QCM physical views and basic internal architecture © Copyright IBM Corp. 2006. -

Power4 Focuses on Memory Bandwidth IBM Confronts IA-64, Says ISA Not Important
VOLUME 13, NUMBER 13 OCTOBER 6,1999 MICROPROCESSOR REPORT THE INSIDERS’ GUIDE TO MICROPROCESSOR HARDWARE Power4 Focuses on Memory Bandwidth IBM Confronts IA-64, Says ISA Not Important by Keith Diefendorff company has decided to make a last-gasp effort to retain control of its high-end server silicon by throwing its consid- Not content to wrap sheet metal around erable financial and technical weight behind Power4. Intel microprocessors for its future server After investing this much effort in Power4, if IBM fails business, IBM is developing a processor it to deliver a server processor with compelling advantages hopes will fend off the IA-64 juggernaut. Speaking at this over the best IA-64 processors, it will be left with little alter- week’s Microprocessor Forum, chief architect Jim Kahle de- native but to capitulate. If Power4 fails, it will also be a clear scribed IBM’s monster 170-million-transistor Power4 chip, indication to Sun, Compaq, and others that are bucking which boasts two 64-bit 1-GHz five-issue superscalar cores, a IA-64, that the days of proprietary CPUs are numbered. But triple-level cache hierarchy, a 10-GByte/s main-memory IBM intends to resist mightily, and, based on what the com- interface, and a 45-GByte/s multiprocessor interface, as pany has disclosed about Power4 so far, it may just succeed. Figure 1 shows. Kahle said that IBM will see first silicon on Power4 in 1Q00, and systems will begin shipping in 2H01. Looking for Parallelism in All the Right Places With Power4, IBM is targeting the high-reliability servers No Holds Barred that will power future e-businesses. -
Local, Compressed
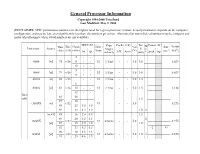
General Processor Information Copyright 1994-2000 Tom Burd Last Modified: May 2, 2000 (DISCLAIMER: SPEC performance numbers are the highest rated for a given processor version. Actual performance depends on the computer configuration, and may be less, even significantly less than, the numbers given here. Also note that non-italicized numbers may be company esti- mates of perforamnce when actual numbers are not available) SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ 5 - - 8086 [vi] 78 v/16 8 - - 1/1 1/1/na - - 5.0 3.0 0.029 10 - - 5 - - 8088 [vi] 79 v/16 1/1 1/1/na - - 5.0 3.0 0.029 8 - - 80186 [vi] 82 v/16 - - 1/1 1/1/na - - 5.0 1.5 6 - - 80286 [vi] 82 v/16 10 - - 1/1 1/1/na - - 5.0 1.5 0.134 12 - - Intel 85 16 x86 1.5 87 20 i386DX [vi] v/32 1/1 - - 5.0 0.275 88 25 6.5 1.9 89 33 8.4 3.0 1.0 2 [vi,41] 88 16 2.4 0.9 1.5 89 20 3.5 1.3 2 i386SX v/32 1/1 4/na/na - - 5.0 0.275 [vi] 89 25 4.6 1.9 1.0 92 33 6.2 3.3 ~2 43 90 20 3.5 1.3 i386SL [vi] v/32 1/1 4/na/na - - 5.0 1.0 2 0.855 91 25 4.6 1.9 SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ [vi] 89 25 14.2 6.7 1.0 2 i486DX [vi,45] 90 v/32 33 18.6 8.5 2/1 5/na/5? 8 u.