18734 Homework 3
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Press Release Univision Communications Inc
PRESS RELEASE UNIVISION COMMUNICATIONS INC. Investor Contact: Media Contact: Adam Shippee Bobby Amirshahi (646) 560-4992 646-560-4902 [email protected] [email protected] Univision Communications Inc. Univision Communications Inc. UNIVISION COMMUNICATIONS INC. TO HOST Q2 2018 CONFERENCE CALL ON AUGUST 9, 2018 NEW YORK – AUGUST 2, 2018 – Univision Communications Inc. (UCI), the leading media company serving Hispanic America, will conduct a conference call to discuss its second quarter 2018 financial results at 11:00 a.m. ET/8:00 a.m. PT on Thursday, August 9, 2018. A press release summarizing its second quarter 2018 financial results will be available on UCI’s website at investors.univision.net/financial-reports/quarterly-reports before market opens on Thursday, August 9, 2018. To participate in the conference call, please dial (866) 858-0462 (within U.S.) or (360) 562-9850 (outside U.S.) fifteen minutes prior to the start of the call and provide the following pass code: 5289787. A playback of the conference call will be available beginning at 2:00 p.m. ET, Thursday, August 9, 2018, through Thursday, August 23, 2018. To access the playback, please dial (855) 859-2056 (within U.S.) or (404) 537-3406 (outside U.S.) and enter reservation number 5289787. About Univision Communications Inc. Univision Communications Inc. (UCI) is the leading media company serving Hispanic America. The Company, a chief content creator in the U.S., includes Univision Network, one of the top networks in the U.S. regardless of language and the most-watched Spanish-language broadcast television network in the country, available in approximately 88% of U.S. -

Univision Communications Inc to Acquire Digital Media Assets from Gawker Media for $135 Million
UNIVISION COMMUNICATIONS INC TO ACQUIRE DIGITAL MEDIA ASSETS FROM GAWKER MEDIA FOR $135 MILLION Acquisition of Digital Assets will Reinforce UCI’s Digital Strategy and is Expected to Increase Fusion Media Group’s Digital Reach to Nearly 75 Million Uniques, Building on Recent Investments in FUSION, The Root and The Onion NEW YORK – AUGUST 18, 2016 – Univision Communications Inc. (UCI) today announced it has entered into an agreement to acquire digital media assets as part of the bankruptcy proceedings of Gawker Media Group, Inc. and related companies that produce content under a series of original brands that reach nearly 50 million readers per month, according to comScore. UCI will acquire the digital media assets for $135 million, subject to certain adjustments, and these assets will be integrated into Fusion Media Group (FMG), the division of UCI that serves the young, diverse audiences that make up the rising American mainstream. The deal, which will be accounted for as an asset purchase, includes the following digital platforms, Gizmodo, Jalopnik, Jezebel, Deadspin, Lifehacker and Kotaku. UCI will not be operating the Gawker.com site. With this strategic acquisition, FMG’s digital reach is expected rise to nearly 75 million uniques, or 96 million uniques when including its extended network. The acquisition will further enrich FMG’s content offerings across key verticals including iconic platforms focused on technology (Gizmodo), car culture (Jalopnik), contemporary women’s interests (Jezebel) and sports (Deadspin), among others. The deal builds on UCI’s recently announced creation of FMG and investments in FUSION, The Root and The Onion, which includes The A.V. -

North Dakota Homeland Security Anti-Terrorism Summary
UNCLASSIFIED North Dakota Homeland Security Anti-Terrorism Summary The North Dakota Open Source Anti-Terrorism Summary is a product of the North Dakota State and Local Intelligence Center (NDSLIC). It provides open source news articles and information on terrorism, crime, and potential destructive or damaging acts of nature or unintentional acts. Articles are placed in the Anti-Terrorism Summary to provide situational awareness for local law enforcement, first responders, government officials, and private/public infrastructure owners. UNCLASSIFIED UNCLASSIFIED NDSLIC Disclaimer The Anti-Terrorism Summary is a non-commercial publication intended to educate and inform. Further reproduction or redistribution is subject to original copyright restrictions. NDSLIC provides no warranty of ownership of the copyright, or accuracy with respect to the original source material. Quick links North Dakota Energy Regional Food and Agriculture National Government Sector (including Schools and Universities) International Information Technology and Banking and Finance Industry Telecommunications Chemical and Hazardous Materials National Monuments and Icons Sector Postal and Shipping Commercial Facilities Public Health Communications Sector Transportation Critical Manufacturing Water and Dams Defense Industrial Base Sector North Dakota Homeland Security Emergency Services Contacts UNCLASSIFIED UNCLASSIFIED North Dakota Nothing Significant to Report Regional (Minnesota) Hacker charged over siphoning off funds meant for software devs. An alleged hacker has been charged with breaking into the e-commerce systems of Digital River before redirecting more than $250,000 to an account under his control. The hacker, of Houston, Texas, 35, is charged with fraudulently obtaining more than $274K between December 2008 and October 2009 following an alleged hack against the network of SWReg Inc, a Digital River subsidiary. -

$10,000,000 Says Hillary Wins
$10,000,000 Says Hillary Wins Haim Saban wants to put Clinton in the White House and take Univision public BY DEVIN LEONARD PHOTOGRAPH BY JEFF MINTON aim Saban, the billionaire chairman of Univision some of whom he said were rapists, Univision has taken an a garbage man and a disciplinarian. “I of the company’s affiliates that followed Communications, America’s largest Spanish-language adversarial stance. Nine days after Trump’s comments, the know,” he says, sitting in front of a large because so many were watching. media company, flew to Jerusalem in his private jet network canceled its plans to broadcast his Miss USA pageant. picture window through which you can Afterward, Saban says, News Corp. H on Sept. 29 to attend the funeral of his friend Shimon Trump filed a $500 million breach of contract lawsuit, alleg- see the late afternoon sun reddening the Chairman Rupert Murdoch wanted to buy Peres, Israel’s former prime minister. It was an event attended by ing Saban was interfering to benefit Clinton. (The suit was lush grounds outside. “You’re looking at his production company. “I said, ‘Bubbie, numerous world leaders. Saban gave one of them a lift: former settled confidentially.) The next month, Trump had Jorge me and thinking, ‘You were in charge of forget about it, I don’t need your money. U.S. President Bill Clinton. In Saban’s telling, it wasn’t a big deal. Ramos, Univision’s leading news anchor, tossed out of a news discipline?’ Yes, I was.” (It’s so not hard Let’s create a partnership. -
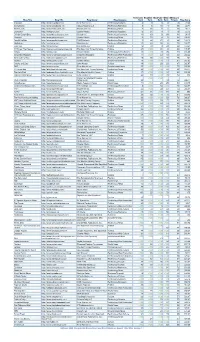
Blog Title Blog URL Blog Owner Blog Category Technorati Rank
Technorati Bloglines BlogPulse Wikio SEOmoz’s Blog Title Blog URL Blog Owner Blog Category Rank Rank Rank Rank Trifecta Blog Score Engadget http://www.engadget.com Time Warner Inc. Technology/Gadgets 4 3 6 2 78 19.23 Boing Boing http://www.boingboing.net Happy Mutants LLC Technology/Marketing 5 6 15 4 89 33.71 TechCrunch http://www.techcrunch.com TechCrunch Inc. Technology/News 2 27 2 1 76 42.11 Lifehacker http://lifehacker.com Gawker Media Technology/Gadgets 6 21 9 7 78 55.13 Official Google Blog http://googleblog.blogspot.com Google Inc. Technology/Corporate 14 10 3 38 94 69.15 Gizmodo http://www.gizmodo.com/ Gawker Media Technology/News 3 79 4 3 65 136.92 ReadWriteWeb http://www.readwriteweb.com RWW Network Technology/Marketing 9 56 21 5 64 142.19 Mashable http://mashable.com Mashable Inc. Technology/Marketing 10 65 36 6 73 160.27 Daily Kos http://dailykos.com/ Kos Media, LLC Politics 12 59 8 24 63 163.49 NYTimes: The Caucus http://thecaucus.blogs.nytimes.com The New York Times Company Politics 27 >100 31 8 93 179.57 Kotaku http://kotaku.com Gawker Media Technology/Video Games 19 >100 19 28 77 216.88 Smashing Magazine http://www.smashingmagazine.com Smashing Magazine Technology/Web Production 11 >100 40 18 60 283.33 Seth Godin's Blog http://sethgodin.typepad.com Seth Godin Technology/Marketing 15 68 >100 29 75 284 Gawker http://www.gawker.com/ Gawker Media Entertainment News 16 >100 >100 15 81 287.65 Crooks and Liars http://www.crooksandliars.com John Amato Politics 49 >100 33 22 67 305.97 TMZ http://www.tmz.com Time Warner Inc. -
Huzzah to the Double Helix! It's International DNA Day | Lifehacker
Huzzah To The Double Helix! It’s International DNA Day | L... http://www.lifehacker.com.au/2013/04/huzzah-to-the-double-h... Business Insider Gizmodo Kotaku Lifehacker PopSugar BellaSugar FabSugar ShopStyle Log In Register Life Work IT Pro RECENTLY ON KOTAKU RECENTLY ON KOTAKU Robin Has A Point In These Hilarious Conference Or Not, We’ll Cherish Superhero Texts These E3 Nintendo Memes Forever HOME Huzzah To The Double Helix! It’s International DNA Day CHRIS JAGER YESTERDAY 9:30 AM Share 5858 Discuss 22 Today is International DNA Day, which this year commemorates 60 years since the scientific paper A Structure for Deoxyribose Nucleic Acid was first published. Here’s what some of Australia’s leading scientists SUBSCRIBE have to say about the importance of the discovery… CONTACT DNA picture from Shutterstock Sixty years ago to the day, James Watson and Francis Crick published a revolutionary paper on the Like Lifehacker Australia 5,616 Followers structure of Deoxyribonucleic acid; the molecular key to all living things otherwise known as DNA. A Follow Lifehacker Australia 11,734 Followers century after Gregor Mendel first began messing about with peas, the final piece of the genetic puzzle had been slotted into place. Subscribe to all stories 15,269 Followers To mark this historic occasion, several Australian scientists have released statements in which they Australian stories 1,859 Followers basically wax lyrical about the wonders of DNA — what better way to start your morning? (And if you’re wondering what the Lifehacker angle is, the answer is quite simple: when someone smarter than you has something to say, it’s usually worth listening!) REGULARS LIFE Professor Suzanne Cory, President of the Australian Academy of Science: Sell Your Stuff And Get Some Extra Cash This Weekend The discovery of the structure of DNA by James Watson and Francis Crick was an epic moment in the history of science. -

Modified Roomba Det
Robots: Modified Roomba Detects Stress, Runs Away When It Thinks Y... http://i.gizmodo.com/5170892/modified-roomba-detects-stress-runs-awa... IPHONE 3.0 GIZ EXPLAINS PHOTOSHOP APPLE LUNCH NSFW iPhone 3.0 Beta Giz Explains: CONTEST iPhone 3.0 OS The Genius iPhone OS 3.0 OS Walkthrough What Makes The 42 Even More Guide: Behind Will Turn Your Video Five Smartphone Ludicrous Everything You Scanwiches.com's Phone Into a Platforms Control Schemes Need to Know Juicy Sandwich Revolutionary Different Apple Might Just Porn Sex Toy Try Gizmodo ROBOTS Modified Roomba Detects Stress, Runs Away When It Thinks You Might Abuse It By Sean Fallon, 4:40 PM on Mon Mar 16 2009, 7,205 views The last thing you need when you get home is something making noise and hovering underfoot. This modified Roomba avoids users when it detects high levels of stress. Designed by researchers at the University of Calgary, this Roomba interacts with a commercial headband for gamers that detects muscle tension in the face. The more tension it detects, the farther away the Roomba will hover from the subject. The purpose of this rather simple device is to explore the potential of human and machine interaction on an emotional level. The researchers envision gadgets that approach you like a pet when it detects that you are lonely and in need of comfort. Conversely, the Roomba model could be taken a step further—imagine if it cowered under the bed when you came home drunk and angry. Then, fearing for it's life, the Roomba calls 911 and gets you thrown in the slammer for appliance abuse. -

Performance Indicators of Basic Infrastructure of Kotaku Program (The City Without Slums)
Jurnal Teknik Sipil & Perencanaan 22 (2) (2020) p. 94 – 102 JURNAL TEKNIK SIPIL & PERENCANAAN 10.15294/jtsp.v22i2.24011 Performance Indicators of Basic Infrastructure of Kotaku Program (The City without Slums) Awliya Tribhuwana1, a) and Ohan Farhan1, b) 1Fakultas Teknik, Program Studi Teknik Sipil, Universitas Swadaya Gunung Jati Cirebon a) Corresponding author: [email protected] b) [email protected] Abstract. Wotgali Village is a slum area. The aim of the current research is to find out the performance of slum base infrastructure using Lakip (Government Agency Accountability Report) of Kotaku (City without Slums) Program. The first step was performed by identifying the initial settlement (base line), then some treatments on the facilities and infrastructure (finish line), performance evaluation stages of the preparation, planning, implementation, and sustainability stages. The research used qualitative and quantitative approach. Qualitative measurement began with a numerical assessment of the results on the level of regional slum. In addition, quantitative data used the Lakip simulation using results of the Kotaku program stage performance. Results of the initial condition reach value of 32%. It is categorized as slight slums with an average sectoral slum of 36.68%. Basic infrastructure development which has final technical reached 24% and is included in slight slum with an average sectoral of 27.50%. The performance of LAKIP Kotaku was in preparation phase 90.46% (very good performance), planning stage was 89.93% (very good performance), implementation stage was 90.25% (very good performance), sustainability stage was 85.21% (better performance). Thus, the achievement of Kotaku program is 85.19% with a range of value of 80-90. -

Newsletter CLUSIT - 31 Dicembre 2010
Newsletter CLUSIT - 31 dicembre 2010 Indice 1. RINNOVO DIRETTIVO CLUSIT 2. FORMAZIONE NELLE SCUOLE 3. AGGIORNAMENTO QUADERNO PCI-DSS 4. CALENDARIO SEMINARI CLUSIT 2011 5. NOTIZIE DAL BLOG 6. NOTIZIE E SEGNALAZIONI DAI SOCI 1. RINNOVO DIRETTIVO CLUSIT Nel corso dell'assemblea generale dello scorso 17 dicembre, si è proceduto all'elezione del nuovo Comitato Direttivo e del suo Presidente. Riportiamo di seguito l'elenco dei nuovi eletti, con i relativi ruoli e materie di competenza. • Gigi TAGLIAPIETRA - Presidente • Paolo GIUDICE - Segretario Generale • Giorgio GIUDICE - Tesoriere e Webmaster • Luca BECHELLI - Sicurezza e Compliance • Raoul CHIESA - Sicurezza delle Infrastrutture Critiche, CyberWar • Mauro CICOGNINI - Responsabile Seminari Clusit • Gabriele FAGGIOLI - Ufficio Legale • Mariangela FAGNANI - Aspetti etici e regolamenti interni • Massimiliano MANZETTI - Rapporti con il Mondo Sanitario • Marco MISITANO - Convergence tra sicurezza fisica e sicurezza logica • Mattia MONGA - Rapporti con i CERT ed il Mondo Universitario • Alessio PENNASILICO - Security Summit, Hacking Film Festival • Stefano QUINTARELLI - Rapporti con gli operatori Telcom e ISP • Claudio TELMON - Responsabile Iniziative "Rischio IT e PMI", "Premio Tesi", "Adotta una scuola", "video pillole di sicurezza" • Alessandro Vallega - Coordinamento Gruppi di Lavoro 2. FORMAZIONE NELLE SCUOLE Come discusso durante l'ultima assemblea, stiamo attivando l'iniziativa Adotta una scuola, che mira a sviluppare un'attività di sensibilizzazione alle problematiche della sicurezza ICT presso le scuole, da parte dei soci. www.clusit.it pag. 1 [email protected] Newsletter CLUSIT - 31 dicembre 2010 Una volta che l'iniziativa sarà a regime, i soci ci potranno comunicare scuole, presumibilmente della loro area, che sono disposti ad "adottare". A seguito di questa richiesta il Clusit contatterà il preside con una lettera in cui propone l'iniziativa e "accredita" il socio che quindi, se il preside sarà d'accordo, andrà a fare uno o più interventi di sensibilizzazione sul tema della sicurezza ICT presso quella scuola. -

Leading Television Broadcasters Name John Hane President of Spectrum Consortium
LEADING TELEVISION BROADCASTERS NAME JOHN HANE PRESIDENT OF SPECTRUM CONSORTIUM BALTIMORE, Maryland and IRVING, Texas – January 31, 2018 – Spectrum Co, LLC (“Spectrum Co”), the ATSC 3.0 spectrum consortium founded by Sinclair Broadcast Group, Inc. (Nasdaq: SBGI) (“Sinclair”) and Nexstar Media Group, Inc. (Nasdaq: NXST) (“Nexstar”) and for which Univision Local Media, Inc. (“Univision”) has signed a Memorandum of Understanding to join, announced today that John Hane has been named President. Mr. Hane most recently served as a partner in the Washington, D.C. office of Pillsbury Winthrop Shaw Pittman LLP, a global law firm with a leading technology practice, where he primarily focused on counseling clients in telecom, broadcast and technology sectors and was deeply involved in matters related to the development and regulatory approval of ATSC 3.0 (“NextGen”). A “go-to” advisor on spectrum matters, before joining Pillsbury Mr. Hane led a large satellite and wireless network development group. He is the inventor or co-inventor of four patents related to wireless and satellite spectrum. Mr. Hane’s appointment reflects the consortium’s shared goal of promoting spectrum utilization, innovation and monetization by advancing the adoption of the ATSC 3.0 transmission standard across the broadcast industry. As President of Spectrum Co., he will oversee the development of the newly- formed entity as it pursues advanced nationwide business opportunities made available by the NextGen standard and aggregation of spectrum bandwidth. John Hane commented, “The consortium’s strong commitment to innovation and the advancement of the local broadcast television industry through future digital technology capabilities, were strong factors in attracting me to this position. -

Carnival Corporation Announces Partnership with Univision Communications with Launch of New Primetime Show - 'La Gran Sorpresa'
Carnival Corporation Announces Partnership with Univision Communications with Launch of New Primetime Show - 'La Gran Sorpresa' December 18, 2017 Making its debut on Sunday, January 7, the O·C·E·A·N original series from the world's largest leisure travel company unites families through travel to engage growing Hispanic community MIAMI, Dec. 18, 2017 /PRNewswire/ -- Carnival Corporation & plc (NYSE/LSE: CCL; NYSE: CUK), the world's largest leisure travel company, today announced it is partnering with Univision Communications Inc. (UCI) – the leading media company serving Hispanic America – to develop the first O·C·E·A·N primetime series. The show will air on Sundays at 8 p.m. ET/PT / 7 p.m. CT beginning January 7 on the Univision Network. 'La Gran Sorpresa' (The Great Surprise) uses the power of travel to reunite families as they overcome hardships created by illness, separation and other challenges. The one-hour program is hosted by award-winning television personality Poncho de Anda. For the series' first six episodes, de Anda will be joined by several well-known personalities, including Univision Deportes' Karina Banda; "Despierta America's" Franscisca Lachapel and Maity Interiano; and Ligia Uriarte of Univision's primetime dramedy, "Mi Marido Tiene Familia." In its first season, the series surprises a number of families as they sail aboard ships from Carnival Cruise Line, Princess Cruises and Holland America Line – three of Carnival Corporation's nine global cruise brands – to exotic destinations including Cozumel (Mexico), Mahogany Bay (Honduras) and Half Moon Cay (Bahamas). "Based on the exceptionally positive viewing results that exceed all other travel-related shows and the increased interest in cruise vacations our shows continue to generate, we are very excited to partner with Univision on 'La Gran Sorpresa' and build on their strong connection with the Hispanic community," said John Padgett, chief experience and innovation officer for Carnival Corporation. -

Lifehacker Australia 4,842 Followers Is DNA the Future of Data Storage? Follow Lifehacker Australia 8,163 Followers Subscribe to All Stories 24,900 Followers
Gizmodo Kotaku Lifehacker PopSugar BellaSugar FabSugar ShopStyle Log In Register Life Work IT Pro Search SUBSCRIBE CONTACT Like Lifehacker Australia 4,842 Followers Is DNA The Future Of Data Storage? Follow Lifehacker Australia 8,163 Followers Subscribe to all stories 24,900 Followers Australian stories 2,583 Followers JONATHAN KEITH YESTERDAY 3:30 PM Share 77 Discuss 22 Bookmark REGULARS IT PRO Ask LH: Can I Apply For A Job Without A Degree? Ask LH: What Should I Do Now That Google Apps Accounts Are No Longer Free? App Directory: The Best Programming Text Editor For Linux LIFEHACKER SECURITY CENTRE Biological systems have been using DNA as an information storage molecule for billions of years. Vast amounts of data can thus be encoded within microscopic volumes, and we carry the proof of this concept in the cells of our own bodies. Could this ultimate storage solution meet the ever-growing needs of archivists in this age of digital information? Ask LH: How Can I Keep A Private DNA picture from Shutterstock Journal Online? Stored In DNA Stream Photos Live And Online From Any Camera This dream has come a step closer to reality with the publication of a new technique in this week’s edition of the scientific journal Nature. A team of researchers headed by Nick Goldman and Ewan Birney at the European Bioinformatics Institute of the European Molecular Biology Laboratory (EMBL-EBI) has How Much Your Stolen Data Is Worth dramatically demonstrated the potential of the technique to store and transport human-made data. To Scammers Their data included some well-chosen iconic elements: Shakespeare’s 154 sonnets, an audio excerpt from Internet Explorer 8 And Earlier Martin Luther King’s “I have a dream” speech, Watson and Crick’s classic paper on the structure of DNA, and Vulnerable To New Exploit a colour photograph of the European Bioinformatics Institute.