Analysis of Relationship Between Two Variables
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

04 – Everything You Want to Know About Correlation but Were
EVERYTHING YOU WANT TO KNOW ABOUT CORRELATION BUT WERE AFRAID TO ASK F R E D K U O 1 MOTIVATION • Correlation as a source of confusion • Some of the confusion may arise from the literary use of the word to convey dependence as most people use “correlation” and “dependence” interchangeably • The word “correlation” is ubiquitous in cost/schedule risk analysis and yet there are a lot of misconception about it. • A better understanding of the meaning and derivation of correlation coefficient, and what it truly measures is beneficial for cost/schedule analysts. • Many times “true” correlation is not obtainable, as will be demonstrated in this presentation, what should the risk analyst do? • Is there any other measures of dependence other than correlation? • Concordance and Discordance • Co-monotonicity and Counter-monotonicity • Conditional Correlation etc. 2 CONTENTS • What is Correlation? • Correlation and dependence • Some examples • Defining and Estimating Correlation • How many data points for an accurate calculation? • The use and misuse of correlation • Some example • Correlation and Cost Estimate • How does correlation affect cost estimates? • Portfolio effect? • Correlation and Schedule Risk • How correlation affect schedule risks? • How Shall We Go From Here? • Some ideas for risk analysis 3 POPULARITY AND SHORTCOMINGS OF CORRELATION • Why Correlation Is Popular? • Correlation is a natural measure of dependence for a Multivariate Normal Distribution (MVN) and the so-called elliptical family of distributions • It is easy to calculate analytically; we only need to calculate covariance and variance to get correlation • Correlation and covariance are easy to manipulate under linear operations • Correlation Shortcomings • Variances of R.V. -

11. Correlation and Linear Regression
11. Correlation and linear regression The goal in this chapter is to introduce correlation and linear regression. These are the standard tools that statisticians rely on when analysing the relationship between continuous predictors and continuous outcomes. 11.1 Correlations In this section we’ll talk about how to describe the relationships between variables in the data. To do that, we want to talk mostly about the correlation between variables. But first, we need some data. 11.1.1 The data Table 11.1: Descriptive statistics for the parenthood data. variable min max mean median std. dev IQR Dan’s grumpiness 41 91 63.71 62 10.05 14 Dan’s hours slept 4.84 9.00 6.97 7.03 1.02 1.45 Dan’s son’s hours slept 3.25 12.07 8.05 7.95 2.07 3.21 ............................................................................................ Let’s turn to a topic close to every parent’s heart: sleep. The data set we’ll use is fictitious, but based on real events. Suppose I’m curious to find out how much my infant son’s sleeping habits affect my mood. Let’s say that I can rate my grumpiness very precisely, on a scale from 0 (not at all grumpy) to 100 (grumpy as a very, very grumpy old man or woman). And lets also assume that I’ve been measuring my grumpiness, my sleeping patterns and my son’s sleeping patterns for - 251 - quite some time now. Let’s say, for 100 days. And, being a nerd, I’ve saved the data as a file called parenthood.csv. -

Construct Validity and Reliability of the Work Environment Assessment Instrument WE-10
International Journal of Environmental Research and Public Health Article Construct Validity and Reliability of the Work Environment Assessment Instrument WE-10 Rudy de Barros Ahrens 1,*, Luciana da Silva Lirani 2 and Antonio Carlos de Francisco 3 1 Department of Business, Faculty Sagrada Família (FASF), Ponta Grossa, PR 84010-760, Brazil 2 Department of Health Sciences Center, State University Northern of Paraná (UENP), Jacarezinho, PR 86400-000, Brazil; [email protected] 3 Department of Industrial Engineering and Post-Graduation in Production Engineering, Federal University of Technology—Paraná (UTFPR), Ponta Grossa, PR 84017-220, Brazil; [email protected] * Correspondence: [email protected] Received: 1 September 2020; Accepted: 29 September 2020; Published: 9 October 2020 Abstract: The purpose of this study was to validate the construct and reliability of an instrument to assess the work environment as a single tool based on quality of life (QL), quality of work life (QWL), and organizational climate (OC). The methodology tested the construct validity through Exploratory Factor Analysis (EFA) and reliability through Cronbach’s alpha. The EFA returned a Kaiser–Meyer–Olkin (KMO) value of 0.917; which demonstrated that the data were adequate for the factor analysis; and a significant Bartlett’s test of sphericity (χ2 = 7465.349; Df = 1225; p 0.000). ≤ After the EFA; the varimax rotation method was employed for a factor through commonality analysis; reducing the 14 initial factors to 10. Only question 30 presented commonality lower than 0.5; and the other questions returned values higher than 0.5 in the commonality analysis. Regarding the reliability of the instrument; all of the questions presented reliability as the values varied between 0.953 and 0.956. -
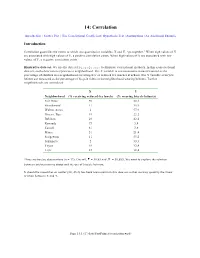
14: Correlation
14: Correlation Introduction | Scatter Plot | The Correlational Coefficient | Hypothesis Test | Assumptions | An Additional Example Introduction Correlation quantifies the extent to which two quantitative variables, X and Y, “go together.” When high values of X are associated with high values of Y, a positive correlation exists. When high values of X are associated with low values of Y, a negative correlation exists. Illustrative data set. We use the data set bicycle.sav to illustrate correlational methods. In this cross-sectional data set, each observation represents a neighborhood. The X variable is socioeconomic status measured as the percentage of children in a neighborhood receiving free or reduced-fee lunches at school. The Y variable is bicycle helmet use measured as the percentage of bicycle riders in the neighborhood wearing helmets. Twelve neighborhoods are considered: X Y Neighborhood (% receiving reduced-fee lunch) (% wearing bicycle helmets) Fair Oaks 50 22.1 Strandwood 11 35.9 Walnut Acres 2 57.9 Discov. Bay 19 22.2 Belshaw 26 42.4 Kennedy 73 5.8 Cassell 81 3.6 Miner 51 21.4 Sedgewick 11 55.2 Sakamoto 2 33.3 Toyon 19 32.4 Lietz 25 38.4 Three are twelve observations (n = 12). Overall, = 30.83 and = 30.883. We want to explore the relation between socioeconomic status and the use of bicycle helmets. It should be noted that an outlier (84, 46.6) has been removed from this data set so that we may quantify the linear relation between X and Y. Page 14.1 (C:\data\StatPrimer\correlation.wpd) Scatter Plot The first step is create a scatter plot of the data. -

Statistical Analysis 8: Two-Way Analysis of Variance (ANOVA)
Statistical Analysis 8: Two-way analysis of variance (ANOVA) Research question type: Explaining a continuous variable with 2 categorical variables What kind of variables? Continuous (scale/interval/ratio) and 2 independent categorical variables (factors) Common Applications: Comparing means of a single variable at different levels of two conditions (factors) in scientific experiments. Example: The effective life (in hours) of batteries is compared by material type (1, 2 or 3) and operating temperature: Low (-10˚C), Medium (20˚C) or High (45˚C). Twelve batteries are randomly selected from each material type and are then randomly allocated to each temperature level. The resulting life of all 36 batteries is shown below: Table 1: Life (in hours) of batteries by material type and temperature Temperature (˚C) Low (-10˚C) Medium (20˚C) High (45˚C) 1 130, 155, 74, 180 34, 40, 80, 75 20, 70, 82, 58 2 150, 188, 159, 126 136, 122, 106, 115 25, 70, 58, 45 type Material 3 138, 110, 168, 160 174, 120, 150, 139 96, 104, 82, 60 Source: Montgomery (2001) Research question: Is there difference in mean life of the batteries for differing material type and operating temperature levels? In analysis of variance we compare the variability between the groups (how far apart are the means?) to the variability within the groups (how much natural variation is there in our measurements?). This is why it is called analysis of variance, abbreviated to ANOVA. This example has two factors (material type and temperature), each with 3 levels. Hypotheses: The 'null hypothesis' might be: H0: There is no difference in mean battery life for different combinations of material type and temperature level And an 'alternative hypothesis' might be: H1: There is a difference in mean battery life for different combinations of material type and temperature level If the alternative hypothesis is accepted, further analysis is performed to explore where the individual differences are. -

CORRELATION COEFFICIENTS Ice Cream and Crimedistribute Difficulty Scale ☺ ☺ (Moderately Hard)Or
5 COMPUTING CORRELATION COEFFICIENTS Ice Cream and Crimedistribute Difficulty Scale ☺ ☺ (moderately hard)or WHAT YOU WILLpost, LEARN IN THIS CHAPTER • Understanding what correlations are and how they work • Computing a simple correlation coefficient • Interpretingcopy, the value of the correlation coefficient • Understanding what other types of correlations exist and when they notshould be used Do WHAT ARE CORRELATIONS ALL ABOUT? Measures of central tendency and measures of variability are not the only descrip- tive statistics that we are interested in using to get a picture of what a set of scores 76 Copyright ©2020 by SAGE Publications, Inc. This work may not be reproduced or distributed in any form or by any means without express written permission of the publisher. Chapter 5 ■ Computing Correlation Coefficients 77 looks like. You have already learned that knowing the values of the one most repre- sentative score (central tendency) and a measure of spread or dispersion (variability) is critical for describing the characteristics of a distribution. However, sometimes we are as interested in the relationship between variables—or, to be more precise, how the value of one variable changes when the value of another variable changes. The way we express this interest is through the computation of a simple correlation coefficient. For example, what’s the relationship between age and strength? Income and years of education? Memory skills and amount of drug use? Your political attitudes and the attitudes of your parents? A correlation coefficient is a numerical index that reflects the relationship or asso- ciation between two variables. The value of this descriptive statistic ranges between −1.00 and +1.00. -

5. Dummy-Variable Regression and Analysis of Variance
Sociology 740 John Fox Lecture Notes 5. Dummy-Variable Regression and Analysis of Variance Copyright © 2014 by John Fox Dummy-Variable Regression and Analysis of Variance 1 1. Introduction I One of the limitations of multiple-regression analysis is that it accommo- dates only quantitative explanatory variables. I Dummy-variable regressors can be used to incorporate qualitative explanatory variables into a linear model, substantially expanding the range of application of regression analysis. c 2014 by John Fox Sociology 740 ° Dummy-Variable Regression and Analysis of Variance 2 2. Goals: I To show how dummy regessors can be used to represent the categories of a qualitative explanatory variable in a regression model. I To introduce the concept of interaction between explanatory variables, and to show how interactions can be incorporated into a regression model by forming interaction regressors. I To introduce the principle of marginality, which serves as a guide to constructing and testing terms in complex linear models. I To show how incremental I -testsareemployedtotesttermsindummy regression models. I To show how analysis-of-variance models can be handled using dummy variables. c 2014 by John Fox Sociology 740 ° Dummy-Variable Regression and Analysis of Variance 3 3. A Dichotomous Explanatory Variable I The simplest case: one dichotomous and one quantitative explanatory variable. I Assumptions: Relationships are additive — the partial effect of each explanatory • variable is the same regardless of the specific value at which the other explanatory variable is held constant. The other assumptions of the regression model hold. • I The motivation for including a qualitative explanatory variable is the same as for including an additional quantitative explanatory variable: to account more fully for the response variable, by making the errors • smaller; and to avoid a biased assessment of the impact of an explanatory variable, • as a consequence of omitting another explanatory variables that is relatedtoit. -

Analysis of Variance and Analysis of Variance and Design of Experiments of Experiments-I
Analysis of Variance and Design of Experimentseriments--II MODULE ––IVIV LECTURE - 19 EXPERIMENTAL DESIGNS AND THEIR ANALYSIS Dr. Shalabh Department of Mathematics and Statistics Indian Institute of Technology Kanpur 2 Design of experiment means how to design an experiment in the sense that how the observations or measurements should be obtained to answer a qqyuery inavalid, efficient and economical way. The desigggning of experiment and the analysis of obtained data are inseparable. If the experiment is designed properly keeping in mind the question, then the data generated is valid and proper analysis of data provides the valid statistical inferences. If the experiment is not well designed, the validity of the statistical inferences is questionable and may be invalid. It is important to understand first the basic terminologies used in the experimental design. Experimental unit For conducting an experiment, the experimental material is divided into smaller parts and each part is referred to as experimental unit. The experimental unit is randomly assigned to a treatment. The phrase “randomly assigned” is very important in this definition. Experiment A way of getting an answer to a question which the experimenter wants to know. Treatment Different objects or procedures which are to be compared in an experiment are called treatments. Sampling unit The object that is measured in an experiment is called the sampling unit. This may be different from the experimental unit. 3 Factor A factor is a variable defining a categorization. A factor can be fixed or random in nature. • A factor is termed as fixed factor if all the levels of interest are included in the experiment. -

THE ONE-SAMPLE Z TEST
10 THE ONE-SAMPLE z TEST Only the Lonely Difficulty Scale ☺ ☺ ☺ (not too hard—this is the first chapter of this kind, but youdistribute know more than enough to master it) or WHAT YOU WILL LEARN IN THIS CHAPTERpost, • Deciding when the z test for one sample is appropriate to use • Computing the observed z value • Interpreting the z value • Understandingcopy, what the z value means • Understanding what effect size is and how to interpret it not INTRODUCTION TO THE Do ONE-SAMPLE z TEST Lack of sleep can cause all kinds of problems, from grouchiness to fatigue and, in rare cases, even death. So, you can imagine health care professionals’ interest in seeing that their patients get enough sleep. This is especially the case for patients 186 Copyright ©2020 by SAGE Publications, Inc. This work may not be reproduced or distributed in any form or by any means without express written permission of the publisher. Chapter 10 ■ The One-Sample z Test 187 who are ill and have a real need for the healing and rejuvenating qualities that sleep brings. Dr. Joseph Cappelleri and his colleagues looked at the sleep difficul- ties of patients with a particular illness, fibromyalgia, to evaluate the usefulness of the Medical Outcomes Study (MOS) Sleep Scale as a measure of sleep problems. Although other analyses were completed, including one that compared a treat- ment group and a control group with one another, the important analysis (for our discussion) was the comparison of participants’ MOS scores with national MOS norms. Such a comparison between a sample’s mean score (the MOS score for par- ticipants in this study) and a population’s mean score (the norms) necessitates the use of a one-sample z test. -

Eight Things You Need to Know About Interpreting Correlations
Research Skills One, Correlation interpretation, Graham Hole v.1.0. Page 1 Eight things you need to know about interpreting correlations: A correlation coefficient is a single number that represents the degree of association between two sets of measurements. It ranges from +1 (perfect positive correlation) through 0 (no correlation at all) to -1 (perfect negative correlation). Correlations are easy to calculate, but their interpretation is fraught with difficulties because the apparent size of the correlation can be affected by so many different things. The following are some of the issues that you need to take into account when interpreting the results of a correlation test. 1. Correlation does not imply causality: This is the single most important thing to remember about correlations. If there is a strong correlation between two variables, it's easy to jump to the conclusion that one of the variables causes the change in the other. However this is not a valid conclusion. If you have two variables, X and Y, it might be that X causes Y; that Y causes X; or that a third factor, Z (or even a whole set of other factors) gives rise to the changes in both X and Y. For example, suppose there is a correlation between how many slices of pizza I eat (variable X), and how happy I am (variable Y). It might be that X causes Y - so that the more pizza slices I eat, the happier I become. But it might equally well be that Y causes X - the happier I am, the more pizza I eat. -

Chapter 11 -- Correlation
Contents 11 Association Between Variables 795 11.4 Correlation . 795 11.4.1 Introduction . 795 11.4.2 Correlation Coe±cient . 796 11.4.3 Pearson's r . 800 11.4.4 Test of Signi¯cance for r . 810 11.4.5 Correlation and Causation . 813 11.4.6 Spearman's rho . 819 11.4.7 Size of r for Various Types of Data . 828 794 Chapter 11 Association Between Variables 11.4 Correlation 11.4.1 Introduction The measures of association examined so far in this chapter are useful for describing the nature of association between two variables which are mea- sured at no more than the nominal scale of measurement. All of these measures, Á, C, Cramer's xV and ¸, can also be used to describe association between variables that are measured at the ordinal, interval or ratio level of measurement. But where variables are measured at these higher levels, it is preferable to employ measures of association which use the information contained in these higher levels of measurement. These higher level scales either rank values of the variable, or permit the researcher to measure the distance between values of the variable. The association between rankings of two variables, or the association of distances between values of the variable provides a more detailed idea of the nature of association between variables than do the measures examined so far in this chapter. While there are many measures of association for variables which are measured at the ordinal or higher level of measurement, correlation is the most commonly used approach. -

ANALYSIS of VARIANCE and MISSING OBSERVATIONS in COMPLETELY RANDOMIZED, RANDOMIZED BLOCKS and LATIN SQUARE DESIGNS a Thesis
ANALYSIS OF VARIANCE AND MISSING OBSERVATIONS IN COMPLETELY RANDOMIZED, RANDOMIZED BLOCKS AND LATIN SQUARE DESIGNS A Thesis Presented to The Department of Mathematics Kansas State Teachers College, Emporia, Kansas In Partial Fulfillment of the Requirements for the Degree Master of Science by Kiritkumar K. Talati May 1972 c; , ACKNOWLEDGEMENTS Sincere thanks and gratitude is expressed to Dr. John Burger for his assistance, patience, and his prompt attention in all directions in preparing this paper. A special note of appreciation goes to Dr. Marion Emerson, Dr. Thomas Davis, Dr. George Poole, Dr. Darrell Wood, who rendered assistance in the research of this paper. TABLE OF CONTENTS CHAPTER I. INTRODUCTION • • • • • • • • • • • • • • • • 1 A. Preliminary Consideration. • • • • • • • 1 B. Purpose and Assumptions of the Analysis of Variance • • • • • • • • •• 1 C. Analysis of Covariance • • • • • • • • • 2 D. Definitions. • • • • • • • • • • • • • • ) E. Organization of Paper. • • • • • • • • • 4 II. COMPLETELY RANDOMIZED DESIGN • • • • • • • • 5 A. Description............... 5 B. Randomization. • • • • • • • • • • • • • 5 C. Problem and Computations •••••••• 6 D. Conclusion and Further Applications. •• 10 III. RANDOMIZED BLOCK DESIGN. • • • • • • • • • • 12 A. Description............... 12 B. Randomization. • • • • • • • • • • • • • 1) C. Problem and Statistical Analysis • • • • 1) D. Efficiency of Randomized Block Design as Compared to Completely Randomized Design. • • • • • • • • • •• 20 E. Missing Observations • • • • • • • • •• 21 F.