Cygnus: GPU Meets FPGA for HPC
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Exploring Exoplanet Populations with NASA's Kepler Mission
SPECIAL FEATURE: PERSPECTIVE PERSPECTIVE SPECIAL FEATURE: Exploring exoplanet populations with NASA’s Kepler Mission Natalie M. Batalha1 National Aeronautics and Space Administration Ames Research Center, Moffett Field, 94035 CA Edited by Adam S. Burrows, Princeton University, Princeton, NJ, and accepted by the Editorial Board June 3, 2014 (received for review January 15, 2014) The Kepler Mission is exploring the diversity of planets and planetary systems. Its legacy will be a catalog of discoveries sufficient for computing planet occurrence rates as a function of size, orbital period, star type, and insolation flux.The mission has made significant progress toward achieving that goal. Over 3,500 transiting exoplanets have been identified from the analysis of the first 3 y of data, 100 planets of which are in the habitable zone. The catalog has a high reliability rate (85–90% averaged over the period/radius plane), which is improving as follow-up observations continue. Dynamical (e.g., velocimetry and transit timing) and statistical methods have confirmed and characterized hundreds of planets over a large range of sizes and compositions for both single- and multiple-star systems. Population studies suggest that planets abound in our galaxy and that small planets are particularly frequent. Here, I report on the progress Kepler has made measuring the prevalence of exoplanets orbiting within one astronomical unit of their host stars in support of the National Aeronautics and Space Admin- istration’s long-term goal of finding habitable environments beyond the solar system. planet detection | transit photometry Searching for evidence of life beyond Earth is the Sun would produce an 84-ppm signal Translating Kepler’s discovery catalog into one of the primary goals of science agencies lasting ∼13 h. -

Get Outside What to Look for in the Summer Sky Your Hosts of the Summer Sky Are Three Bright Stars — Vega, Altair and Deneb
Get Outside What to Look for in the Summer Sky Your hosts of the summer sky are three bright stars — Vega, Altair and Deneb. Together they make up the Summer Triangle. Look for the triangle in the east on a June evening, moving NORTH to overhead as the season progresses. Polaris The Big Dipper Deneb Cygnus Vega Lyra Hercules Arcturus EaST West Summer Triangle Altair Aquila Sagittarius Antares Turn the map so Scorpius the direction you are facing is at the Teapot the bottom. south facebook.com/KidsCanBooks @KidsCanPress GET OUTSIDE Text © 2013 Jane Drake & Ann Love Illustrations © 2013 Heather Collins www.kidscanpress.com Get Outside Vega The Keystone The brightest star in the Between Vega and Arcturus, Summer Triangle, Vega is look for four stars in a wedge or The summer bluish white. It is in the keystone shape. This is the body solstice constellation Lyra, the Harp. of Hercules, the Strongman. His feet are to the north and Every day from late Altair his arms to the south, making December to June, the The second-brightest star in his figure kneel Sun rises and sets a little the triangle, Altair is white. upside down farther north along the Altair is in the constellation in the sky. horizon. But about June Aquila, the Eagle. 21, the Sun seems to stop Keystone moving north. It rises in Deneb the northeast and sets in The dimmest star of the the northwest, seemingly Summer Triangle, Deneb would in the same spots for be the brightest if it were not so Hercules several days. -

Summer Constellations
Night Sky 101: Summer Constellations The Summer Triangle Photo Credit: Smoky Mountain Astronomical Society The Summer Triangle is made up of three bright stars—Altair, in the constellation Aquila (the eagle), Deneb in Cygnus (the swan), and Vega Lyra (the lyre, or harp). Also called “The Northern Cross” or “The Backbone of the Milky Way,” Cygnus is a horizontal cross of five bright stars. In very dark skies, Cygnus helps viewers find the Milky Way. Albireo, the last star in Cygnus’s tail, is actually made up of two stars (a binary star). The separate stars can be seen with a 30 power telescope. The Ring Nebula, part of the constellation Lyra, can also be seen with this magnification. In Japanese mythology, Vega, the celestial princess and goddess, fell in love Altair. Her father did not approve of Altair, since he was a mortal. They were forbidden from seeing each other. The two lovers were placed in the sky, where they were separated by the Celestial River, repre- sented by the Milky Way. According to the legend, once a year, a bridge of magpies form, rep- resented by Cygnus, to reunite the lovers. Photo credit: Unknown Scorpius Also called Scorpio, Scorpius is one of the 12 Zodiac constellations, which are used in reading horoscopes. Scorpius represents those born during October 23 to November 21. Scorpio is easy to spot in the summer sky. It is made up of a long string bright stars, which are visible in most lights, especially Antares, because of its distinctly red color. Antares is about 850 times bigger than our sun and is a red giant. -

Constellation at Your Fingertips: Cygnus
The National Optical Astronomy Observatory’s Dark Skies and Energy Education Program Constellation at Your Fingertips: Cygnus (Cygnus version adapted from Constellation at Your Fingertips: Orion at www.globeatnight.org) Grades: 3rd - 8th grade Overview: Constellation at Your Fingertips introduces the novice constellation hunter to a method for spotting the main stars in the constellation, Cygnus, the swan. Students will make an outline of the constellation used to locate the stars in Cygnus and visualize its shape. This lesson will engage children and first-time night sky viewers in observations of the night sky. The lesson links history, Greek mythology, literature, and astronomy. Once the constellation is identified, it may be easy to find the summer triangle. The simplicity of Cygnus makes locating and observing it exciting for young learners. More on Cygnus is at the Great World Wide Star Count at http://www.starcount.org. Materials for another citizen-science star hunt, Globe at Night, are available at http://www.globeatnight.org. Purpose: Students will use the this activity to visualize the constellation of Cygnus. This will help them more easily participate in the Great World Wide Star Count citizen-science campaign. The campaign asks participants to match one of 7 different charts of Cygnus with what the participant sees toward Cygnus. Chart 1 has only a few stars. Chart 7 has many. What they will be recording for the campaign is the chart with the faintest star they see. In many cases, observations over years will build knowledge of how light pollution changes over time. Why is this important to astronomers? What causes the variation year to year? The focus is on light pollution and the options we have as consumers when purchasing outdoor lighting and shields. -

The Kepler Characterization of the Variability Among A- and F-Type Stars I
A&A 534, A125 (2011) Astronomy DOI: 10.1051/0004-6361/201117368 & c ESO 2011 Astrophysics The Kepler characterization of the variability among A- and F-type stars I. General overview K. Uytterhoeven1,2,3,A.Moya4, A. Grigahcène5,J.A.Guzik6, J. Gutiérrez-Soto7,8,9, B. Smalley10, G. Handler11,12, L. A. Balona13,E.Niemczura14, L. Fox Machado15,S.Benatti16,17, E. Chapellier18, A. Tkachenko19, R. Szabó20, J. C. Suárez7,V.Ripepi21, J. Pascual7, P. Mathias22, S. Martín-Ruíz7,H.Lehmann23, J. Jackiewicz24,S.Hekker25,26, M. Gruberbauer27,11,R.A.García1, X. Dumusque5,28,D.Díaz-Fraile7,P.Bradley29, V. Antoci11,M.Roth2,B.Leroy8, S. J. Murphy30,P.DeCat31, J. Cuypers31, H. Kjeldsen32, J. Christensen-Dalsgaard32 ,M.Breger11,33, A. Pigulski14, L. L. Kiss20,34, M. Still35, S. E. Thompson36,andJ.VanCleve36 (Affiliations can be found after the references) Received 30 May 2011 / Accepted 29 June 2011 ABSTRACT Context. The Kepler spacecraft is providing time series of photometric data with micromagnitude precision for hundreds of A-F type stars. Aims. We present a first general characterization of the pulsational behaviour of A-F type stars as observed in the Kepler light curves of a sample of 750 candidate A-F type stars, and observationally investigate the relation between γ Doradus (γ Dor), δ Scuti (δ Sct), and hybrid stars. Methods. We compile a database of physical parameters for the sample stars from the literature and new ground-based observations. We analyse the Kepler light curve of each star and extract the pulsational frequencies using different frequency analysis methods. -

Scientists Discover Planetary System Orbiting Kepler-47 13 September 2012, by Dr
Scientists discover planetary system orbiting Kepler-47 13 September 2012, by Dr. Tony Phillips "The presence of a full-fledged planetary system orbiting Kepler-47 is an amazing discovery," says Greg Laughlin, professor of Astrophysics and Planetary Science at the University of California in Santa Cruz. "This is going to change the way we think about the formation of planets." The inner planet, Kepler-47b, closely circles the pair of stars, completing each orbit in less than 50 days. Astronomers think it is a sweltering world, where the destruction of methane in its super- heated atmosphere might lead to a thick global haze. Kepler-47b is about three times the size of Earth. The outer planet, Kepler-47c, orbits every 303 days. This puts it in the system's habitable zone, a This diagram compares our own solar system to band of orbits that are "just right" for liquid water to Kepler-47, a double-star system containing two planets, exist on the surface of a planet. But does this one orbiting in the so-called "habitable zone." This is the sweet spot in a planetary system where liquid water planet even have a surface? Possibly not. The might exist on the surface of a planet. Credit: NASA/JPL- astronomers think it is a gas giant slightly larger Caltech/T. Pyle than Neptune. The discovery of planets orbiting double stars means that planetary systems are even weirder News flash: The Milky Way galaxy just got a little and more abundant than previously thought. weirder. Back in 2011 astronomers were amazed when NASA's Kepler spacecraft discovered a "Many stars are part of multiple-star systems where planet orbiting a double star system. -

Exoplanet Community Report
JPL Publication 09‐3 Exoplanet Community Report Edited by: P. R. Lawson, W. A. Traub and S. C. Unwin National Aeronautics and Space Administration Jet Propulsion Laboratory California Institute of Technology Pasadena, California March 2009 The work described in this publication was performed at a number of organizations, including the Jet Propulsion Laboratory, California Institute of Technology, under a contract with the National Aeronautics and Space Administration (NASA). Publication was provided by the Jet Propulsion Laboratory. Compiling and publication support was provided by the Jet Propulsion Laboratory, California Institute of Technology under a contract with NASA. Reference herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise, does not constitute or imply its endorsement by the United States Government, or the Jet Propulsion Laboratory, California Institute of Technology. © 2009. All rights reserved. The exoplanet community’s top priority is that a line of probeclass missions for exoplanets be established, leading to a flagship mission at the earliest opportunity. iii Contents 1 EXECUTIVE SUMMARY.................................................................................................................. 1 1.1 INTRODUCTION...............................................................................................................................................1 1.2 EXOPLANET FORUM 2008: THE PROCESS OF CONSENSUS BEGINS.....................................................2 -

Trillium Compact User Guide © 2015 Nanometrics Inc
Trillium Compact User Guide © 2015 Nanometrics Inc. All Rights Reserved. Trillium Compact Seismometer User Guide Applies to the following products: Product Name Model Number Part Number Trillium Compact, 120 second TC120-SV1 16838 Trillium Compact, 20 second TC20-SV1 16838-20 Trillium Compact Posthole, 120 second, 300 m TC120-PH2 17327 Trillium Compact Posthole, 20 second, 300 m TC20-PH2 17327-20 The information in this document has been carefully reviewed and is believed to be reliable. Nanometrics Inc. reserves the right to make changes at any time without notice to improve the reliability and function of the product. No part of this publication may be reproduced, stored in a retrieval system or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of Nanometrics Inc. Nanometrics Inc. 250 Herzberg Road, Kanata, Ontario, Canada K2K 2A1 Tel +1 613-592-6776 Fax +1 613-592-5929 Email [email protected] www.nanometrics.ca Part number 16889R7 Release date 2015-11-02 About This Document Document Conventions Essential and Supplementary Information Explains a risk of irreversible damage to data, software, or equipment Warning and provides recommendations for preventive action. Explains a risk of damage to data, software, or equipment where Caution recovery is likely to be troublesome and provides recommendations for preventive action. Provides additional information related to the current text. Note Explains a best practice or provides helpful information related to the Tip current text. Provides an example related to the current text. Example Text Conventions bold text Identifies referenced elements in the graphical user interface (GUI) (for example, “click Cancel to discard the changes”). -

Modeling the Non-Thermal Emission of the Gamma Cygni Supernova Remnant up to the Highest Energies
Modeling the non-thermal emission of the gamma Cygni Supernova Remnant up to the highest energies Henrike Fleischhack∗ Michigan Technological University E-mail: [email protected] for the HAWC collaboration y The gamma Cygni supernova remnant (SNR) is a middle-aged, Sedov-phase SNR in the Cygnus region. It is a known source of non-thermal emission at radio, X-ray, and gamma-ray energies. Very-high energy (VHE, >100 GeV) gamma-ray emission from gamma Cygni was first detected by the VERITAS observatory and it has since been observed by other experiments. Observations so far indicate that there must be a population of non-thermal particles present in the remnant which produces the observed emission. However, it is not clear what kind of particles (protons/ions or electrons) are accelerated in the remnant, how efficient the acceleration is, and up to which energy particles can be accelerated. Accurate measurements of the VHE gamma-ray spectrum are crucial to investigate particle acceleration above TeV energies. This presentation will focus on multi-wavelength observations of the gamma Cygni SNR and their interpretation. We will present improved measurements of the VHE gamma-ray emission spec- trum of gamma Cygni by the High-Altitude Water Cherenkov (HAWC) gamma-ray observatory, and use these results as well as measurements from other instruments to model the underlying particle populations producing this emission. HAWC’s excellent sensitivity at TeV energies and above enables us to extend spectral measurements to higher energies and better constrain the maximum acceleration energy. arXiv:1907.08572v1 [astro-ph.HE] 19 Jul 2019 36th International Cosmic Ray Conference -ICRC2019- July 24th - August 1st, 2019 Madison, WI, U.S.A. -

IDENTIFYING EXOPLANETS with DEEP LEARNING II: TWO NEW SUPER-EARTHS UNCOVERED by a NEURAL NETWORK in K2 DATA Anne Dattilo1,†, Andrew Vanderburg1,?, Christopher J
Preprint typeset using LATEX style emulateapj v. 12/16/11 IDENTIFYING EXOPLANETS WITH DEEP LEARNING II: TWO NEW SUPER-EARTHS UNCOVERED BY A NEURAL NETWORK IN K2 DATA Anne Dattilo1,y, Andrew Vanderburg1,?, Christopher J. Shallue2, Andrew W. Mayo3,z, Perry Berlind4, Allyson Bieryla4, Michael L. Calkins4, Gilbert A. Esquerdo4, Mark E. Everett5, Steve B. Howell6, David W. Latham4, Nicholas J. Scott6, Liang Yu7 ABSTRACT For years, scientists have used data from NASA's Kepler Space Telescope to look for and discover thousands of transiting exoplanets. In its extended K2 mission, Kepler observed stars in various regions of sky all across the ecliptic plane, and therefore in different galactic environments. Astronomers want to learn how the population of exoplanets are different in these different environments. However, this requires an automatic and unbiased way to identify the exoplanets in these regions and rule out false positive signals that mimic transiting planet signals. We present a method for classifying these exoplanet signals using deep learning, a class of machine learning algorithms that have become popular in fields ranging from medical science to linguistics. We modified a neural network previously used to identify exoplanets in the Kepler field to be able to identify exoplanets in different K2 campaigns, which range in galactic environments. We train a convolutional neural network, called AstroNet-K2, to predict whether a given possible exoplanet signal is really caused by an exoplanet or a false positive. AstroNet-K2 is highly successful at classifying exoplanets and false positives, with accuracy of 98% on our test set. It is especially efficient at identifying and culling false positives, but for now, still needs human supervision to create a complete and reliable planet candidate sample. -
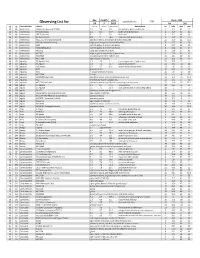
Observing List
day month year Epoch 2000 local clock time: 2.00 Observing List for 24 7 2019 RA DEC alt az Constellation object mag A mag B Separation description hr min deg min 39 64 Andromeda Gamma Andromedae (*266) 2.3 5.5 9.8 yellow & blue green double star 2 3.9 42 19 51 85 Andromeda Pi Andromedae 4.4 8.6 35.9 bright white & faint blue 0 36.9 33 43 51 66 Andromeda STF 79 (Struve) 6 7 7.8 bluish pair 1 0.1 44 42 36 67 Andromeda 59 Andromedae 6.5 7 16.6 neat pair, both greenish blue 2 10.9 39 2 67 77 Andromeda NGC 7662 (The Blue Snowball) planetary nebula, fairly bright & slightly elongated 23 25.9 42 32.1 53 73 Andromeda M31 (Andromeda Galaxy) large sprial arm galaxy like the Milky Way 0 42.7 41 16 53 74 Andromeda M32 satellite galaxy of Andromeda Galaxy 0 42.7 40 52 53 72 Andromeda M110 (NGC205) satellite galaxy of Andromeda Galaxy 0 40.4 41 41 38 70 Andromeda NGC752 large open cluster of 60 stars 1 57.8 37 41 36 62 Andromeda NGC891 edge on galaxy, needle-like in appearance 2 22.6 42 21 67 81 Andromeda NGC7640 elongated galaxy with mottled halo 23 22.1 40 51 66 60 Andromeda NGC7686 open cluster of 20 stars 23 30.2 49 8 46 155 Aquarius 55 Aquarii, Zeta 4.3 4.5 2.1 close, elegant pair of yellow stars 22 28.8 0 -1 29 147 Aquarius 94 Aquarii 5.3 7.3 12.7 pale rose & emerald 23 19.1 -13 28 21 143 Aquarius 107 Aquarii 5.7 6.7 6.6 yellow-white & bluish-white 23 46 -18 41 36 188 Aquarius M72 globular cluster 20 53.5 -12 32 36 187 Aquarius M73 Y-shaped asterism of 4 stars 20 59 -12 38 33 145 Aquarius NGC7606 Galaxy 23 19.1 -8 29 37 185 Aquarius NGC7009 -

Three Editions of the Star Catalogue of Tycho Brahe*
A&A 516, A28 (2010) Astronomy DOI: 10.1051/0004-6361/201014002 & c ESO 2010 Astrophysics Three editions of the star catalogue of Tycho Brahe Machine-readable versions and comparison with the modern Hipparcos Catalogue F. Verbunt1 andR.H.vanGent2,3 1 Astronomical Institute, Utrecht University, PO Box 80 000, 3508 TA Utrecht, The Netherlands e-mail: [email protected] 2 URU-Explokart, Faculty of Geosciences, Utrecht University, PO Box 80 115, 3508 TC Utrecht, The Netherlands 3 Institute for the History and Foundations of Science, PO Box 80 000, 3508 TA Utrecht, The Netherlands Received 6 January 2010 / Accepted 3 February 2010 ABSTRACT Tycho Brahe completed his catalogue with the positions and magnitudes of 1004 fixed stars in 1598. This catalogue circulated in manuscript form. Brahe edited a shorter version with 777 stars, printed in 1602, and Kepler edited the full catalogue of 1004 stars, printed in 1627. We provide machine-readable versions of the three versions of the catalogue, describe the differences between them and briefly discuss their accuracy on the basis of comparison with modern data from the Hipparcos Catalogue. We also compare our results with earlier analyses by Dreyer (1916, Tychonis Brahe Dani Scripta Astronomica, Vol. II) and Rawlins (1993, DIO, 3, 1), finding good overall agreement. The magnitudes given by Brahe correlate well with modern values, his longitudes and latitudes have error distributions with widths of 2, with excess numbers of stars with larger errors (as compared to Gaussian distributions), in particular for the faintest stars. Errors in positions larger than 10, which comprise about 15% of the entries, are likely due to computing or copying errors.