Potential Outcome and Directed Acyclic Graph Approaches to Causality: Relevance for Empirical Practice in Economics Arxiv:1907.0
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Historical Evidence from US Newspapers Matthew Gentzkow, Jesse M
NBER WORKING PAPER SERIES COMPETITION AND IDEOLOGICAL DIVERSITY: HISTORICAL EVIDENCE FROM US NEWSPAPERS Matthew Gentzkow Jesse M. Shapiro Michael Sinkinson Working Paper 18234 http://www.nber.org/papers/w18234 NATIONAL BUREAU OF ECONOMIC RESEARCH 1050 Massachusetts Avenue Cambridge, MA 02138 July 2012 We are grateful to Alan Bester, Ambarish Chandra, Tim Conley, Christian Hansen, Igal Hendel, Caroline Hoxby, Jon Levin, Kevin Murphy, Andrei Shleifer, E. Glen Weyl, and numerous seminar participants for advice and suggestions, and to our dedicated research assistants for important contributions to this project. This research was funded in part by the Initiative on Global Markets, the George J. Stigler Center for the Study of the Economy and the State, the Ewing Marion Kauffman Foundation, the Centel Foundation/Robert P. Reuss Faculty Research Fund, the Neubauer Family Foundation and the Kathryn C. Gould Research Fund, all at the University of Chicago Booth School of Business, the Social Sciences and Humanities Research Council of Canada, and the National Science Foundation. The views expressed herein are those of the authors and do not necessarily reflect the views of the National Bureau of Economic Research. NBER working papers are circulated for discussion and comment purposes. They have not been peer- reviewed or been subject to the review by the NBER Board of Directors that accompanies official NBER publications. © 2012 by Matthew Gentzkow, Jesse M. Shapiro, and Michael Sinkinson. All rights reserved. Short sections of text, not to exceed two paragraphs, may be quoted without explicit permission provided that full credit, including © notice, is given to the source. Competition and Ideological Diversity: Historical Evidence from US Newspapers Matthew Gentzkow, Jesse M. -

Bk Brll 010665.Pdf
12 THE BOOK OF WHY Figure I. How an “inference engine” combines data with causal knowl- edge to produce answers to queries of interest. The dashed box is not part of the engine but is required for building it. Arrows could also be drawn from boxes 4 and 9 to box 1, but I have opted to keep the diagram simple. the Data input, it will use the recipe to produce an actual Estimate for the answer, along with statistical estimates of the amount of uncertainty in that estimate. This uncertainty reflects the limited size of the data set as well as possible measurement errors or miss- ing data. To dig more deeply into the chart, I have labeled the boxes 1 through 9, which I will annotate in the context of the query “What is the effect of Drug D on Lifespan L?” 1. “Knowledge” stands for traces of experience the reasoning agent has had in the past, including past observations, past actions, education, and cultural mores, that are deemed relevant to the query of interest. The dotted box around “Knowledge” indicates that it remains implicit in the mind of the agent and is not explicated formally in the model. 2. Scientific research always requires simplifying assumptions, that is, statements which the researcher deems worthy of making explicit on the basis of the available Knowledge. While most of the researcher’s knowledge remains implicit in his or her brain, only Assumptions see the light of day and 9780465097609-text.indd 12 3/14/18 10:42 AM 26 THE BOOK OF WHY the direction from which to approach the mammoth; in short, by imagining and comparing the consequences of several hunting strategies. -

1 the University of Chicago the Harris School of Public
THE UNIVERSITY OF CHICAGO THE HARRIS SCHOOL OF PUBLIC POLICY PPHA 421: APPLIED ECONOMETRICS II Spring 2016: Mondays and Wednesdays 10:30 – 11:50 pm, Room 140C Instructor: Professor Koichiro Ito 157 Harris School [email protected] Office hours: Mondays 3-4pm TA: Katherine Goulde: [email protected] Course Description The goal of this course is for students to learn a set of statistical tools and research designs that are useful in conducting high-quality empirical research on topics in applied microeconomics and related fields. Since most applied economic research examines questions with direct policy implications, this course will focus on methods for estimating causal effects. This course differs from many other econometrics courses in that it is oriented towards applied practitioners rather than future econometricians. It therefore emphasizes research design (relative to statistical technique) and applications (relative to theoretical proofs), though it covers some of each. Prerequisites PPHA42000 (Applied Econometrics I) is the prerequisite for this course. Students should be familiar with graduate school level probability and statistics, matrix algebra, and the classical linear regression model at the level of PPHA420. In the Economics department, the equivalent level of preparation would be the 1st year Ph.D. econometrics coursework. In general, I do not recommend taking this course if you have not taken PPHA420: Applied Econometrics I or a Ph.D. level econometrics coursework. This course is a core course for Ph.D. students and MACRM students at Harris School. Those who are not in the Harris Ph.D. program, the MACRM program, or the economics Ph.D. program need permission from the instructor to take the course. -

Preschool Television Viewing and Adolescent Test Scores: Historical Evidence from the Coleman Study
PRESCHOOL TELEVISION VIEWING AND ADOLESCENT TEST SCORES: HISTORICAL EVIDENCE FROM THE COLEMAN STUDY MATTHEW GENTZKOW AND JESSE M. SHAPIRO We use heterogeneity in the timing of television’s introduction to different local markets to identify the effect of preschool television exposure on standardized test scores during adolescence. Our preferred point estimate indicates that an additional year of preschool television exposure raises average adolescent test scores by about 0.02 standard deviations. We are able to reject negative effects larger than about 0.03 standard deviations per year of television exposure. For reading and general knowledge scores, the positive effects we find are marginally statistically significant, and these effects are largest for children from households where English is not the primary language, for children whose mothers have less than a high school education, and for nonwhite children. I. INTRODUCTION Television has attracted young viewers since broadcasting be- gan in the 1940s. Concerns about its effects on the cognitive devel- opment of young children emerged almost immediately and have been fueled by academic research showing a negative association between early-childhood television viewing and later academic achievement.1 These findings have contributed to a belief among the vast majority of pediatricians that television has “negative effects on brain development” of children below age five (Gentile et al. 2004). They have also provided partial motivation for re- cent recommendations that preschool children’s television view- ing time be severely restricted (American Academy of Pediatrics 2001). According to a widely cited report on media use by young * We are grateful to Dominic Brewer, John Collins, Ronald Ehrenberg, Eric Hanushek, and Mary Morris (at ICPSR) for assistance with Coleman study data, and to Christopher Berry for supplying data on school quality. -

NBER WORKING PAPER SERIES TEXT AS DATA Matthew Gentzkow
NBER WORKING PAPER SERIES TEXT AS DATA Matthew Gentzkow Bryan T. Kelly Matt Taddy Working Paper 23276 http://www.nber.org/papers/w23276 NATIONAL BUREAU OF ECONOMIC RESEARCH 1050 Massachusetts Avenue Cambridge, MA 02138 March 2017 The views expressed herein are those of the authors and do not necessarily reflect the views of the National Bureau of Economic Research. At least one co-author has disclosed a financial relationship of potential relevance for this research. Further information is available online at http://www.nber.org/papers/w23276.ack NBER working papers are circulated for discussion and comment purposes. They have not been peer-reviewed or been subject to the review by the NBER Board of Directors that accompanies official NBER publications. © 2017 by Matthew Gentzkow, Bryan T. Kelly, and Matt Taddy. All rights reserved. Short sections of text, not to exceed two paragraphs, may be quoted without explicit permission provided that full credit, including © notice, is given to the source. Text as Data Matthew Gentzkow, Bryan T. Kelly, and Matt Taddy NBER Working Paper No. 23276 March 2017 JEL No. C1 ABSTRACT An ever increasing share of human interaction, communication, and culture is recorded as digital text. We provide an introduction to the use of text as an input to economic research. We discuss the features that make text different from other forms of data, offer a practical overview of relevant statistical methods, and survey a variety of applications. Matthew Gentzkow Matt Taddy Department of Economics Microsoft Research New England Stanford University 1 Memorial Drive 579 Serra Mall Cambridge MA 02142 Stanford, CA 94305 and University of Chicago Booth School of Business and NBER [email protected] [email protected] Bryan T. -

Donald Rubin Three-Day Course in Causality 5 to 7 February 2020 At
Donald Rubin Three-day Course in Causality 5 to 7 February 2020 at Waldhotel Doldenhorn, Kandersteg About the Course Most questions in social and biomedical sciences are causal in nature: what would happen to individuals, or to groups, if part of their environment were changed? In the course, the world-renowned expert Donald Rubin (Prof. em. Harvard) presents statistical methods for studying such questions. The course will follow his book Causal Inference for Statistics, Social, and Biomedical Sciences (Cambridge University Press, 2016) and starts with the notion of potential outcomes, each corresponding to the outcome that would be realized if a subject were exposed to a particular treatment or regime. In this approach, causal effects are comparisons of such potential outcomes. The fundamental problem of causal inference is that we can only observe one of the potential outcomes for a particular subject. Prof. Rubin will discuss how randomized experiments allow us to assess causal effects and then turn to observational studies. They lay out the assumptions needed for causal inference and describe the leading analysis methods, including matching, propensity-score methods, and instrumental variables. Many detailed applications will be shown, with special focus on practical aspects for the empirical researcher. About the Lecturer Donald B. Rubin is Professor Emeritus of Statistics, Harvard University, where he has been professor from 1984 to 2018 and department chair for fifteen years. Since 2018 he is professor at the Yau Mathematical Sciences Center, Tsinghua University, China, and Murray Shusterman Senior Research Fellow at the Department of Statistical Science, Fox School of Business, Temple University, Philadelphia. -

Matthew Gentzkow, Winner of the 2014 Clark Medal
Matthew Gentzkow, Winner of the 2014 Clark Medal The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Shleifer, Andrei. 2015. “Matthew Gentzkow, Winner of the 2014 Clark Medal.” Journal of Economic Perspectives 29 (1): 181–92. https:// doi.org/10.1257/jep.29.1.181. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:41555813 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Journal of Economic Perspectives—Volume 29, Number 1—Winter 2015—Pages 181–192 Matthew Gentzkow, Winner of the 2014 Clark Medal Andrei Shleifer he 2014 John Bates Clark Medal of the American Economic Association was awarded to Matthew Gentzkow of the University of Chicago Booth School T of Business. The citation recognized Matt’s “fundamental contributions to our understanding of the economic forces driving the creation of media products, the changing nature and role of media in the digital environment, and the effect of media on education and civic engagement.” In addition to his work on the media, Matt has made a number of significant contributions to empirical industrial organi- zation more broadly, as well as to applied economic theory. In this essay, I highlight some of these contributions, which are listed on Table 1. I will be referring to these papers by their number on this list. -

Theory with Applications to Voting and Deliberation Experiments!
Randomized Evaluation of Institutions: Theory with Applications to Voting and Deliberation Experiments Yves Atchadey and Leonard Wantchekonz June 24, 2009 Abstract We study causal inference in randomized experiments where the treatment is a decision making process or an institution such as voting, deliberation or decentralized governance. We provide a statistical framework for the estimation of the intrinsic e¤ect of the institution. The proposed framework builds on a standard set-up for estimating causal e¤ects in randomized experiments with noncompliance (Hirano-Imbens-Rubin-Zhou [2000]). We use the model to re- analyze the e¤ect of deliberation on voting for programmatic platforms in Benin (Wantchekon [2008]), and provide practical suggestions for the implementation and analysis of experiments involving institutions. 1 Introduction Randomized experiments are a widely accepted approach to infer causal relations in statis- tics and the social sciences. The idea dates back at least to Neyman (1923) and Fisher (1935) and has been extended by D. Rubin and coauthors (Rubin (1974), Rubin (1978), Rosenbaum and Rubin (1983)) to observational studies and to other more general experimental designs. In this approach, causality is de…ned in terms of potential outcomes. The causal e¤ect of a treatment, say Treatment 1 (compared to another treatment, Treatment 0) on the variable Y and on the statistical unit i is de…ned as Y i(1) Y i(0) (or its expected value) where Y i(j) is the value we would observe on unit i if it receives Treatment j. The estimation of this e¤ect is problematic because unit i cannot be given both Treatment 1 and Treatment 0. -
![Arxiv:1805.08845V4 [Stat.ML] 10 Jul 2021 Outcomes Such As Images, Sequences, and Graphs](https://docslib.b-cdn.net/cover/9715/arxiv-1805-08845v4-stat-ml-10-jul-2021-outcomes-such-as-images-sequences-and-graphs-739715.webp)
Arxiv:1805.08845V4 [Stat.ML] 10 Jul 2021 Outcomes Such As Images, Sequences, and Graphs
Counterfactual Mean Embeddings Krikamol Muandet∗ [email protected] Max Planck Institute for Intelligent Systems Tübingen, Germany Motonobu Kanagaway [email protected] Data Science Department, EURECOM Sophia Antipolis, France Sorawit Saengkyongam [email protected] University of Copenhagen Copenhagen, Denmark Sanparith Marukatat [email protected] National Electronics and Computer Technology Center National Science and Technology Development Agency Pathumthani, Thailand Abstract Counterfactual inference has become a ubiquitous tool in online advertisement, recommen- dation systems, medical diagnosis, and econometrics. Accurate modelling of outcome distri- butions associated with different interventions—known as counterfactual distributions—is crucial for the success of these applications. In this work, we propose to model counter- factual distributions using a novel Hilbert space representation called counterfactual mean embedding (CME). The CME embeds the associated counterfactual distribution into a reproducing kernel Hilbert space (RKHS) endowed with a positive definite kernel, which allows us to perform causal inference over the entire landscape of the counterfactual distri- bution. Based on this representation, we propose a distributional treatment effect (DTE) which can quantify the causal effect over entire outcome distributions. Our approach is nonparametric as the CME can be estimated under the unconfoundedness assumption from observational data without requiring any parametric assumption about the underlying dis- tributions. We also establish a rate of convergence of the proposed estimator which depends on the smoothness of the conditional mean and the Radon-Nikodym derivative of the un- derlying marginal distributions. Furthermore, our framework allows for more complex arXiv:1805.08845v4 [stat.ML] 10 Jul 2021 outcomes such as images, sequences, and graphs. -

A N N U a L R E P O R T
A N N U A L R E P O R T 2014 – 2015 SIEPR’s Mission The Stanford Institute for Economic Policy Research supports research, trains undergraduate and graduate students, and shares nonpartisan scholarship that will lead to better economic policies in the United States and abroad. Table of Contents From the Director 2 New Faculty 4 Policy Impact 6 Young Scholars Program 8 Student Support 9 Events and Conferences 14 Policy Briefs 18 Income and Expenditures 19 Research Centers and Programs 20 Development 24 Donors 28 Visitors 32 Senior Fellows 34 Steering Committee 38 Advisory Board 39 ANNUAL REPORT | 2014 – 2015 1 From the Director Dear Friends, My first six months as the Trione Director of the undergraduates working as research assistants with Stanford Institute for Economic Policy Research have been SIEPR scholars. We have also organized a number of marked with significant activity. We added more than a policy forums that were geared toward students, including dozen faculty to our Senior Fellow ranks in the Fall. They one on innovation challenges for the next presidential include Professors from the Department of Economics administration and others that focused on the “app along with the schools of Business, Education, Law, and economy” and the evolution of finance. Medicine. We also welcomed 11 Assistant Professors as We have hosted some of the most important and Faculty Fellows. These additions mean SIEPR’s arsenal of influential leaders in government and business who have expertise on economic policy includes more shared with us their insights on economic than 80 faculty from all seven Stanford schools policy and many other issues. -

The Neyman-Rubin Model of Causal Inference and Estimation Via Matching Methods∗
The Neyman-Rubin Model of Causal Inference and Estimation via Matching Methods∗ Forthcoming in The Oxford Handbook of Political Methodology, Janet Box-Steffensmeier, Henry Brady, and David Collier, eds. Jasjeet S. Sekhon † 11/16/2007 (15:57) ∗I thank Henry Brady, Wendy Tam Cho, David Collier and Roc´ıo Titiunik for valuable comments on earlier drafts, and David Freedman, Walter R. Mebane, Jr., Donald Rubin and Jonathan N. Wand for many valuable discussions on these topics. All errors are my responsibility. †Associate Professor, Travers Department of Political Science, Survey Research Center, UC Berkeley. [email protected], HTTP://sekhon.berkeley.edu/, 510.642.9974. “Correlation does not imply causation” is one of the most repeated mantras in the social sciences, but its full implications are sobering and often ignored. The Neyman-Rubin model of causal inference helps to clarify some of the issues which arise. In this chapter, the model is briefly described, and some consequences of the model are outlined for both quantitative and qualitative research. The model has radical implications for work in the social sciences given current practices. Matching methods, which are usually motivated by the Neyman-Rubin model, are reviewed and their properties discussed. For example, applied researchers are often surprised to learn that even if the selection on observables assumption is satisfied, the commonly used matching methods will generally make even linear bias worse unless specific and often implausible assumptions are satisfied. Some of the intuition of matching methods, such as propensity score matching, should be familiar to social scientists because they share many features with Mill’s methods, or canons, of inference. -
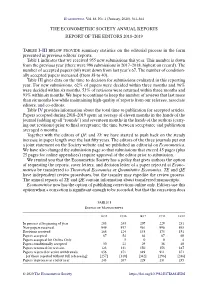
The Econometric Society Annual Reports. Report of the Editors 2018
Econometrica, Vol. 88, No. 1 (January, 2020), 361–364 THE ECONOMETRIC SOCIETY ANNUAL REPORTS REPORT OF THE EDITORS 2018–2019 TABLES I–III BELOW PROVIDE summary statistics on the editorial process in the form presented in previous editors’ reports. Ta b l e I indicates that we received 955 new submissions this year. This number is down from the previous year (there were 996 submissions in 2017–2018, highest on record). The number of accepted papers (60) went down from last year’s 67. The number of condition- ally accepted papers increased (from 38 to 40). Ta b l e III gives data on the time to decision for submissions evaluated in this reporting year. For new submissions, 62% of papers were decided within three months and 96% were decided within six months. 53% of revisions were returned within three months and 93% within six months. We hope to continue to keep the number of reviews that last more than six months low while maintaining high-quality of reports from our referees, associate editors, and co-editors. Ta b l e IV provides information about the total time to publication for accepted articles. Papers accepted during 2018–2019 spent an average of eleven months in the hands of the journal (adding up all “rounds”) and seventeen months in the hands of the authors (carry- ing out revisions) prior to final acceptance; the time between acceptance and publication averaged 6 months. Together with the editors of QE and TE we have started to push back on the steady increase in paper length over the last fifty years.