Reinforcement Learning for Routing in Communication Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Configuring Static Routing
Configuring Static Routing This chapter contains the following sections: • Finding Feature Information, on page 1 • Information About Static Routing, on page 1 • Licensing Requirements for Static Routing, on page 4 • Prerequisites for Static Routing, on page 4 • Guidelines and Limitations for Static Routing, on page 4 • Default Settings for Static Routing Parameters, on page 4 • Configuring Static Routing, on page 4 • Verifying the Static Routing Configuration, on page 10 • Related Documents for Static Routing, on page 10 • Feature History for Static Routing, on page 10 Finding Feature Information Your software release might not support all the features documented in this module. For the latest caveats and feature information, see the Bug Search Tool at https://tools.cisco.com/bugsearch/ and the release notes for your software release. To find information about the features documented in this module, and to see a list of the releases in which each feature is supported, see the "New and Changed Information"chapter or the Feature History table in this chapter. Information About Static Routing Routers forward packets using either route information from route table entries that you manually configure or the route information that is calculated using dynamic routing algorithms. Static routes, which define explicit paths between two routers, cannot be automatically updated; you must manually reconfigure static routes when network changes occur. Static routes use less bandwidth than dynamic routes. No CPU cycles are used to calculate and analyze routing updates. You can supplement dynamic routes with static routes where appropriate. You can redistribute static routes into dynamic routing algorithms but you cannot redistribute routing information calculated by dynamic routing algorithms into the static routing table. -

Dynamic Routing: Routing Information Protocol
CS 356: Computer Network Architectures Lecture 12: Dynamic Routing: Routing Information Protocol Chap. 3.3.1, 3.3.2 Xiaowei Yang [email protected] Today • ICMP applications • Dynamic Routing – Routing Information Protocol ICMP applications • Ping – ping www.duke.edu • Traceroute – traceroute nytimes.com • MTU discovery Ping: Echo Request and Reply ICMP ECHO REQUEST Host Host or or Router router ICMP ECHO REPLY Type Code Checksum (= 8 or 0) (=0) identifier sequence number 32-bit sender timestamp Optional data • Pings are handled directly by the kernel • Each Ping is translated into an ICMP Echo Request • The Pinged host responds with an ICMP Echo Reply 4 Traceroute • xwy@linux20$ traceroute -n 18.26.0.1 – traceroute to 18.26.0.1 (18.26.0.1), 30 hops max, 60 byte packets – 1 152.3.141.250 4.968 ms 4.990 ms 5.058 ms – 2 152.3.234.195 1.479 ms 1.549 ms 1.615 ms – 3 152.3.234.196 1.157 ms 1.171 ms 1.238 ms – 4 128.109.70.13 1.905 ms 1.885 ms 1.943 ms – 5 128.109.70.138 4.011 ms 3.993 ms 4.045 ms – 6 128.109.70.102 10.551 ms 10.118 ms 10.079 ms – 7 18.3.3.1 28.715 ms 28.691 ms 28.619 ms – 8 18.168.0.23 27.945 ms 28.028 ms 28.080 ms – 9 18.4.7.65 28.037 ms 27.969 ms 27.966 ms – 10 128.30.0.246 27.941 ms * * Traceroute algorithm • Sends out three UDP packets with TTL=1,2,…,n, destined to a high port • Routers on the path send ICMP Time exceeded message with their IP addresses until n reaches the destination distance • Destination replies with port unreachable ICMP messages Path MTU discovery algorithm • Send packets with DF bit set • If receive an ICMP error message, reduce the packet size Today • ICMP applications • Dynamic Routing – Routing Information Protocol Dynamic Routing • There are two parts related to IP packet handling: 1. -

Chapter 4 Dynamic Routing
CHAPTER 4 DYNAMIC ROUTING In this chapter we cover the basic principles of dynamic routing algorithms that form the basis of the experiments in Lab 4. The chapter has six sections. Each section covers material that you need to run the lab exercises. The first section gives an overview of dynamic routing protocols and discusses the differences between the two major classes of routing algorithms: intra domain and inter domain. Sections 2, 3, 4, and 5 give an overview of the most common routing algorithms such , RIP, OSPF, BGP and IGRP. Section 6 presents the commands used to configure the hosts and the routers for dynamic routing. TABLE OF CONTENT 1 ROUTING PROTOCOLS ........................................................................................................................ 3 1.1 AUTONOMOUS SYSTEMS (AS)............................................................................................................ 3 1.2 INTRADOMAIN ROUTING VERSUS INTERDOMAIN ROUTING ............................................................... 4 1.3 DYNAMIC ROUTING ............................................................................................................................ 4 1.3.1 Distance Vector Algorithm ........................................................................................................... 4 2 RIP ............................................................................................................................................................... 5 3 OSPF........................................................................................................................................................... -

RIP: Routing Information Protocol a Routing Protocol Based on the Distance-Vector Algorithm
Laboratory 6 RIP: Routing Information Protocol A Routing Protocol Based on the Distance-Vector Algorithm Objective The objective of this lab is to configure and analyze the performance of the Routing Information Protocol (RIP) model. Overview A router in the network needs to be able to look at a packet’s destination address and then determine which of the output ports is the best choice to get the packet to that address. The router makes this decision by consulting a forwarding table. The fundamental problem of routing is: How do routers acquire the information in their forwarding tables? Routing algorithms are required to build the routing tables and hence forwarding tables. The basic problem of routing is to find the lowest-cost path between any two nodes, where the cost of a path equals the sum of the costs of all the edges that make up the path. Routing is achieved in most practical networks by running routing protocols among the nodes. The protocols provide a distributed, dynamic way to solve the problem of finding the lowest-cost path in the presence of link and node failures and changing edge costs. One of the main classes of routing algorithms is the distance-vector algorithm. Each node constructs a vector containing the distances (costs) to all other nodes and distributes that vector to its immediate neighbors. RIP is the canonical example of a routing protocol built on the distance-vector algorithm. Routers running RIP send their advertisements regularly (e.g., every 30 seconds). A router also sends an update message whenever a triggered update from another router causes it to change its routing table. -
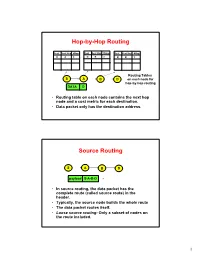
Hop-By-Hop Routing Source Routing
Hop-by-Hop Routing Dest. Next Hop #Hops Dest. Next Hop #Hops Dest. Next Hop #Hops D A 3 D B 2 D D 1 Routing Tables S A B D on each node for hop-by-hop routing DATA D • Routing table on each node contains the next hop node and a cost metric for each destination. • Data packet only has the destination address. Source Routing S A B D payload S-A-B-D • In source routing, the data packet has the complete route (called source route) in the header. • Typically, the source node builds the whole route • The data packet routes itself. • Loose source routing: Only a subset of nodes on the route included. 1 Static vs. Dynamic Routing • Static routing has fixed routes, set up by network administrators, for example. • Dynamic routing is network state- dependent. Routes may change dynamically depending on the “state” of the network. • State = link costs. Switch traffic from highly loaded links to less loaded links. Distributed, Dynamic Routing Protocols • Distributed because in a dynamic network, no single, centralized node “knows” the whole “state” of the network. • Dynamic because routing must respond to “state” changes in the network for efficiency. • Two class of protocols: Link State and Distance Vector. 2 Link State Protocol • Each node “floods” the network with link state packets (LSP) describing the cost of its own (outgoing) links. – Link cost metric = typically delay for traversing the link. – Every other node in the network gets the LSPs via the flooding mechanism. • Each node maintains a LSP database of all LSPs it received. -

CS 268: Computer Networking
CS 268: Computer Networking L-16 Changing the Network Adding New Functionality to the Internet • Overlay networks • Active networks • Assigned reading • Resilient Overlay Networks • Active network vision and reality: lessons from a capsule-based system 2 1 Outline • Active Networks • Overlay Routing (Detour) • Overlay Routing (RON) • Multi-Homing 3 Why Active Networks? • Traditional networks route packets looking only at destination • Also, maybe source fields (e.g. multicast) • Problem • Rate of deployment of new protocols and applications is too slow • Solution • Allow computation in routers to support new protocol deployment 4 2 Active Networks • Nodes (routers) receive packets: • Perform computation based on their internal state and control information carried in packet • Forward zero or more packets to end points depending on result of the computation • Users and apps can control behavior of the routers • End result: network services richer than those by the simple IP service model 5 Why not IP? • Applications that do more than IP forwarding • Firewalls • Web proxies and caches • Transcoding services • Nomadic routers (mobile IP) • Transport gateways (snoop) • Reliable multicast (lightweight multicast, PGM) • Online auctions • Sensor data mixing and fusion • Active networks makes such applications easy to develop and deploy 6 3 Variations on Active Networks • Programmable routers • More flexible than current configuration mechanism • For use by administrators or privileged users • Active control • Forwarding code remains the same -

7/16 Dynamic Routing
7/2016 SATEL technical bulletin SATELLAR Dynamic Routing “A router with dynamically configured routing tables is known as a dynamic router. Dynamic routing consists of routing tables that are built and maintained automatically through an ongoing communication between routers. This communication is facilitated by a routing protocol, a series of periodic or on-demand messages containing routing information that is exchanged between routers. Except for their initial configuration, dynamic routers require little ongoing maintenance, and therefore can scale to larger internetworks. Dynamic routing is fault tolerant. Dynamic routes learned from other routers have a finite lifetime. If a router or link goes down, the routers sense the change in the internetwork topology through the expiration of the lifetime of the learned route in the routing table. This change can then be propagated to other routers so that all the routers on the internetwork become aware of the new internetwork topology. [https://technet.microsoft.com/en-us/library/cc957844.aspx]” Dynamic routing benefits: • Easy setup of routing • Fast setup of routing • Load sharing by routing • Redundancy by routing SATELLAR support dynamic routing protocol by providing OSPF (Open Shortest Path First) functionality. SATELLAR uses the OSPFv2 daemon from the Quagga Routing Suite to implement OSPF. More information, such as full documentation, can be found on the following web page: http://www.nongnu.org/quagga/ In the following image, there are two redundant paths from SCADA system to remote network. The router connected to SATELLARs is an OSPF enabled router, and thus the OSPF enabled SATELLARs and the gateway router will be able to communicate with the dynamic routing protocol. -

Constraint-Based Routing in the Internet: Basic Principles and Recent Research Ossama Younis and Sonia Fahmy Department of Computer Sciences, Purdue University 250 N
1 Constraint-Based Routing in the Internet: Basic Principles and Recent Research Ossama Younis and Sonia Fahmy Department of Computer Sciences, Purdue University 250 N. University Street, West Lafayette, IN 47907–2066, USA Phone: +1-765-494-6183, Fax: +1-765-494-0739 g E-mail: foyounis,fahmy @cs.purdue.edu Abstract— Novel routing paradigms based on policies, Quality of Service (QoS) requirements. Constraints im- quality of service (QoS) requirements, and packet content posed by policies are referred to as policy constraints, and have been proposed for the Internet over the last decade. the associated routing is referred to as policy routing (or Constraint-based routing algorithms select a routing path policy-based routing). Constraints imposed by QoS re- satisfying constraints which are either administrative- quirements, such as bandwidth, delay, or loss, are referred oriented (policy routing), or service-oriented (QoS routing). The routes, in addition to satisfying constraints, are selected to as QoS constraints, and the associated routing is referred to reduce costs, balance network load, or increase secu- to as QoS routing [1]. rity. In this paper, we discuss several constraint-based rout- ing approaches and explain their requirements, complexity, and recent research proposals. In addition, we illustrate how these approaches can be integrated with Internet label switching and QoS architectures. We also discuss examples of application-level routing techniques used in today’s Inter- net. Keywords—constraint-based routing, QoS routing, policy routing, MPLS, DiffServ, content routing I. INTRODUCTION With the proliferation of Web and multimedia services, and virtual private networks (VPNs) connecting corporate sites, more versatile Internet routing protocols have be- come critical. -

Intelligent Routing Information Protocol Using Full Triggered Update Mechanism
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by UM Digital Repository International Journal of the Physical Sciences Vol. 6(11), pp. 2750-2761, 4 June, 2011 Available online at http://www.academicjournals.org/IJPS DOI: 10.5897/AJBM11.282 ISSN 1992 - 1950 ©2011 Academic Journals Full Length Research Paper Intelligent routing information protocol using full triggered update mechanism Abdullah Gani1, M. K. Hassan1, A. A. Zaidan2,3* and B. B. Zaidan2,3 1Faculty of Computer Science and Information Technology, University of Malaya, 50603 Kuala Lumpur, Malaysia. 2Faculty of Engineering, Multimedia University, 63100 Cyberjaya, Selangor Darul Ehsan, Malaysia. 3Predictive Intelligence Research Cluster, Sunway University, No 5, Jalan University, Bandar Sunway, 46150 Petaling Jaya, Selangor, Malaysia. Accepted 06 April, 2011 The heartbeat of network is the routing services which are available upon the execution of protocols. Many routing protocols emerge over one another to strive for betterment in performing the main function of routing the packets to destination efficiently. Despite the superiority of the new protocols in certain feature, the old routing information protocol (RIP) is still widely used due to its simplicity. RIP updates its routing table on a constant interval period by checking the existence of neighbor nodes and changes on the path availability. This mechanism, however, has some drawbacks of bandwidth consumption and higher routing overhead generation. This paper studies the affect of periodic update mechanism on the consumption of bandwidth and proposes a new routing update mechanism. Our technique eliminates the periodic update mechanism in RIP and replaces it with full triggered update by topology change detection mechanism (TRIP). -

Chapter 5: Dynamic Routing
Chapter 5: Dynamic Routing CCNA Routing and Switching Scaling Networks v6.0 Chapter 5 - Sections & Objectives . 5.1 Dynamic Routing Protocols • Explain the features and characteristics of dynamic routing protocols. • Compare the different types of routing protocols. 5.2 Distance Vector Dynamic Routing • Explain how distance vector routing protocols operate. • Explain how dynamic routing protocols achieve convergence. • Describe the algorithm used by distance vector routing protocols to determine the best path. • Identify the types of distance-vector routing protocols. 5.3 Link-State Dynamic Routing • Explain how link-state protocols operate. • Describe the algorithm used by link-state routing protocols to determine the best path. • Explain how the link-state routing protocol uses information sent in a link-state update. • Explain the advantages and disadvantages of using link-state routing protocols. © 2016 Cisco and/or its affiliates. All rights reserved. Cisco Confidential 2 5.1 Dynamic Routing Protocols © 2016 Cisco and/or its affiliates. All rights reserved. Cisco Confidential 3 Types of Routing Protocols Classifying Routing Protocols . The purpose of dynamic routing protocols includes: • Discovery of remote networks. • Maintaining up-to-date routing information. • Choosing the best path to destination networks. • Ability to find a new best path if current path is no longer available. © 2016 Cisco and/or its affiliates. All rights reserved. Cisco Confidential 4 Types of Routing Protocols IGP and EGP Routing Protocols . Interior Gateway Protocols (IGP) - Used for routing within an Autonomous System (AS). • RIP, EIGRP, OSPF, and IS-IS. Exterior Gateway Protocols (EGP) - Used for routing between Autonomous Systems. • BGP © 2016 Cisco and/or its affiliates. -
BGP Vs OSPF Vs RIP Vs MME
BGP vs OSPF vs RIP vs MME Battle of the Dynamic Protocols Presentation Outline • Introduction • Who am I? • What is this presentation all about • What will I learn from this • What are dynamic routing protocols? • Basics of RIP • Basics of OSPF • Basics of BGP • Basics of MME • When should I be using these protocols • Application of RIP • Application of OSPF • Application of BGP • Application of MME Outline Continued • Best Practices • How do I combine these protocols together? • What do I need to support larger networks • E.g. MPLS, VPLS, Traffic Engineering, VRF’s • Conclusion About MikroTik SA • Independent Wireless Specialist company • Not owned by / affiliated to MikroTik Latvia • Official training and support partner for MikroTik • Specialist in all forms of wireless and wired networking technologies • Offers high speed PTP links, carrier independent backbone services, high availability SLA’s, ad-hoc consultation, retainer based consultation David Savage • Is a MikroTik Certified Trainer and consultant – 11+ years • Installs and manages and wireless networks • Has over 30 years experience in the IT field • Teaches general networking and MikroTik RouterOS • Provides high level support for many companies around the world • More recently partnering with Teraco to present Teraco Tech Days featuring MikroTik RouterOS What is this all about? • MikroTik provides a number of dynamic routing protocols that can be deployed to build robust, fault tolerant layer 3 networks • It is often confusing as to which protocol is suitable for which network application • This presentation will explore the fundamental differences between these protocols • I will provide guidelines on when to deploy them, where to deploy them and why. -

Comparison of RIP, OSPF and EIGRP Routing Protocols Based on OPNET
ENSC 427: COMMUNICATION NETWORKS SPRING 2014 FINAL PROJECT Comparison of RIP, OSPF and EIGRP Routing Protocols based on OPNET Project Group # 9 http://www.sfu.ca/~sihengw/ENSC427_Group9/ Justin Deng Siheng Wu Kenny Sun 301138281 301153928 301154475 [email protected] [email protected] [email protected] Table of Contents List of Figures………………………………………………………………………….……..….1 Abstract..........................................................................................................................................2 1. Introduction................................................................................................................................3 1.1 Routing Protocol Basics ……….……………………………………...….…………………..3 1.2 Routing Metrics Basics ……………...…..…………………….………………………….….3 1.3 Static Routing and Dynamic Routing ………………………………………………………..3 1.4 Distance Vector and Link State ……………………………………………………………...3 2. Three Routing Protocols………………………………………………….………………..….4 2.1 Routing Information Protocol (RIP) ……….…………………………….…………………...4 2.2 Open Shortest Path First (OSPF)………..…………………….…………………………...….5 2.3 Enhanced Interior Gateway Routing Protocol (EIGRP) …….....……………………………..7 3. OPNET Simulations………………………………………………………………………......8 3.1 Topologies ……………………………….…………………………………………………...8 3.1.1 Mesh Topology ………..………….……………………………………………………....8 3.1.2 Tree Topology ……………………..……………………………………………………...9 3.2 Simulation Setup …………………………………………………………………………….10 3.2.1 Simulation Setup for Failure/Recovery Configuration...........…………………………...10 3.2.2 Simulation Setup for Individual