Combining Reinforcement Learning and Unreal Engine's AI-Tools to Create Intelligent Bots
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Game Engine Review
Game Engine Review Mr. Stuart Armstrong 12565 Research Parkway, Suite 350 Orlando FL, 32826 USA [email protected] ABSTRACT There has been a significant amount of interest around the use of Commercial Off The Shelf products to support military training and education. This paper compares a number of current game engines available on the market and assesses them against potential military simulation criteria. 1.0 GAMES IN DEFENSE “A game is a system in which players engage in an artificial conflict, defined by rules, which result in a quantifiable outcome.” The use of games for defence simulation can be broadly split into two categories – the use of game technologies to provide an immersive and flexible military training system and a “serious game” that uses game design principles (such as narrative and scoring) to deliver education and training content in a novel way. This talk and subsequent education notes focus on the use of game technologies, in particular game engines to support military training. 2.0 INTRODUCTION TO GAMES ENGINES “A games engine is a software suite designed to facilitate the production of computer games.” Developers use games engines to create games for games consoles, personal computers and growingly mobile devices. Games engines provide a flexible and reusable development toolkit with all the core functionality required to produce a game quickly and efficiently. Multiple games can be produced from the same games engine, for example Counter Strike Source, Half Life 2 and Left 4 Dead 2 are all created using the Source engine. Equally once created, the game source code can with little, if any modification be abstracted for different gaming platforms such as a Playstation, Personal Computer or Wii. -

Mobile Developer's Guide to the Galaxy
Don’t Panic MOBILE DEVELOPER’S GUIDE TO THE GALAXY U PD A TE D & EX TE ND 12th ED EDITION published by: Services and Tools for All Mobile Platforms Enough Software GmbH + Co. KG Sögestrasse 70 28195 Bremen Germany www.enough.de Please send your feedback, questions or sponsorship requests to: [email protected] Follow us on Twitter: @enoughsoftware 12th Edition February 2013 This Developer Guide is licensed under the Creative Commons Some Rights Reserved License. Editors: Marco Tabor (Enough Software) Julian Harty Izabella Balce Art Direction and Design by Andrej Balaz (Enough Software) Mobile Developer’s Guide Contents I Prologue 1 The Galaxy of Mobile: An Introduction 1 Topology: Form Factors and Usage Patterns 2 Star Formation: Creating a Mobile Service 6 The Universe of Mobile Operating Systems 12 About Time and Space 12 Lost in Space 14 Conceptional Design For Mobile 14 Capturing The Idea 16 Designing User Experience 22 Android 22 The Ecosystem 24 Prerequisites 25 Implementation 28 Testing 30 Building 30 Signing 31 Distribution 32 Monetization 34 BlackBerry Java Apps 34 The Ecosystem 35 Prerequisites 36 Implementation 38 Testing 39 Signing 39 Distribution 40 Learn More 42 BlackBerry 10 42 The Ecosystem 43 Development 51 Testing 51 Signing 52 Distribution 54 iOS 54 The Ecosystem 55 Technology Overview 57 Testing & Debugging 59 Learn More 62 Java ME (J2ME) 62 The Ecosystem 63 Prerequisites 64 Implementation 67 Testing 68 Porting 70 Signing 71 Distribution 72 Learn More 4 75 Windows Phone 75 The Ecosystem 76 Implementation 82 Testing -

Advanced 3D Visualization for Simulation Using Game Technology
Proceedings of the 2011 Winter Simulation Conference S. Jain, R. R. Creasey, J. Himmelspach, K. P. White, and M. Fu, eds. ADVANCED 3D VISUALIZATION FOR SIMULATION USING GAME TECHNOLOGY Jonatan L. Bijl Csaba A. Boer TBA B.V. Karrepad 2a 2623 AP Delft, Netherlands ABSTRACT 3D visualization is becoming increasingly popular for discrete event simulation. However, the 3D visu- alization of many of the commercial off the shelf simulation packages is not up to date with the quickly developing area of computer graphics. In this paper we present an advanced 3D visualization tool, which uses game technology. The tool is especially fit for discrete event simulation, it is easily configurable, and it can be kept up to date with modern computer graphics techniques. The tool has been used in several container terminal simulation projects. From a survey under simulation experts and our experience with the visualization tool, we concluded that realism is important for some of the purposes of visualization, and the use of game technology can help to achieve this goal. 1 INTRODUCTION Simulation is the process of designing a model of a concrete system and conducting experiments with this model in order to understand the behavior of the concrete system and/or evaluate various strategies for the operation of the system (Shannon 1975). Although the simulation experiment can produce a large amount of data, the visualization of a simulated system provides a more complete understanding of its behavior. In the visualization, key elements of the system are represented on the screen by icons that dynamically change position, color and shape as the simulation evolves through time (Law and Kelton 2000). -

Faculteit Bedrijf En Organisatie Unity 5 Versus
Faculteit Bedrijf en Organisatie Unity 5 versus Unreal Engine 4: Artificiële intelligentie van 3D vijanden voor een HTML5 project Matthias Caryn Scriptie voorgedragen tot het bekomen van de graad van Bachelor in de toegepaste informatica Promotor: Joeri Van Herreweghe Co-promotor: Steven Delrue Academiejaar: 2015-2016 Derde examenperiode Faculteit Bedrijf en Organisatie Unity 5 versus Unreal Engine 4: Artificiële intelligentie van 3D vijanden voor een HTML5 project Matthias Caryn Scriptie voorgedragen tot het bekomen van de graad van Bachelor in de toegepaste informatica Promotor: Joeri Van Herreweghe Co-promotor: Steven Delrue Academiejaar: 2015-2016 Derde examenperiode Samenvatting Rusty Bolt is een Belgische indie studio. Deze studio wilt een nieuw project starten voor een 3D spel in een HyperText Markup Language 5 (HTML5) browser die intensief gebruik zal maken van artificiële intelligentie (AI) en Web Graphics Library (WebGL). Na onderzoek via een requirements-analyse van verschillende mogelijkheden van game engines komen we terecht bij twee opties namelijk Unity 5, die Rusty Bolt al reeds gebruikt, of de Unreal Engine 4, wat voor hen onbekend terrein is. Qua features zijn ze enorm verschillend, maar ze voldoen elk niet aan één voorwaarde die Rusty Bolt verwacht van een game engine. Zo biedt Unity Technologies wel een mogelijkheid om software te bouwen in de cloud. De broncode van Unity wordt niet openbaar gesteld, tenzij men er extra voor betaalt. Deze game engine is dus niet volledig open source in tegenstelling tot Unreal Engine 4. We vergelijken dan verder ook deze twee engines, namelijk Unity 5 en Unreal Engine 4. We tonen aan dat deze engines visueel verschillen van features, maar ook een andere implementatie van de AI hanteren. -

Exploring Help Facilities in Game-Making Software
Exploring Help Facilities in Game-Making Software Dominic Kao Purdue University West Lafayette, Indiana [email protected] ABSTRACT impact of game-making, very few empirical studies have been done Help facilities have been crucial in helping users learn about soft- on help facilities in game-making software. For example, in our ware for decades. But despite widespread prevalence of game en- systematic review of 85 game-making software, we find that the gines and game editors that ship with many of today’s most popular majority of game-making software incorporates text help, while games, there is a lack of empirical evidence on how help facilities about half contain video help, and only a small number contain impact game-making. For instance, certain types of help facili- interactive help. Given the large discrepancies in help facility im- ties may help users more than others. To better understand help plementation across different game-making software, it becomes facilities, we created game-making software that allowed us to sys- important to question if different help facilities make a difference tematically vary the type of help available. We then ran a study of in user experience, behavior, and the game produced. 1646 participants that compared six help facility conditions: 1) Text Help facilities can teach users how to use game-making soft- Help, 2) Interactive Help, 3) Intelligent Agent Help, 4) Video Help, ware, leading to increased quality in created games. Through foster- 5) All Help, and 6) No Help. Each participant created their own ing knowledge about game-making, help facilities can better help first-person shooter game level using our game-making software novice game-makers transition to becoming professionals. -

Virtual Reality Software Taxonomy
Arts et Metiers ParisTech, IVI Master Degree, Student Research Projects, 2010, Laval, France. RICHIR Simon, CHRISTMANN Olivier, Editors. www.masterlaval.net Virtual Reality software taxonomy ROLLAND Romain1, RICHIR Simon2 1 Arts et Metiers ParisTech, LAMPA, 2 Bd du Ronceray, 49000 Angers – France 2Arts et Metiers ParisTech, LAMPA, 2 Bd du Ronceray, 49000 Angers – France [email protected], [email protected] Abstract— Choosing the best 3D modeling software or real- aims at realizing a state of the art of existing software time 3D software for our needs is more and more difficult used in virtual reality and drawing up a short list among because there is more and more software. In this study, we various 3D modeling and virtual reality software to make help to simplify the choice of that kind of software. At first, easier the choice for graphic designers and programmers. we classify the 3D software into different categories we This research is not fully exhaustive but we have try to describe. We also realize non-exhaustive software’s state of cover at best the software mainly used by 3D computer the art. In order to evaluate that software, we extract graphic designers. evaluating criteria from many sources. In the last part, we propose several software’s valuation method from various At first, we are going to list the major software on the sources of information. market and to group them according to various user profiles. Then, we are going to define various criteria to Keywords: virtual, reality, software, taxonomy, be able to compare them. To finish, we will present the benchmark perspectives of this study. -

Digital Home & Entertainment
Digital Home & Entertainment Innovation Report Serious Games: Issues, offer and market Education Training Health Care Information & Communication Defence rd (3 Edition) M11213 – January 2012 Contributors ► Laurent MICHAUD, Head of the Consumer Electronics and Digital Entertainment Practice Laurent conducts studies on consumer electronics, the digital home, video games, music and the related trends: changing uses, new uses and peripherals, technology innovation, piracy, content protection and rights management. Laurent has developed expertise in the field of economic development and capital project engineering. In fact, he is also involved in the studies conducted by IDATE on behalf of local authorities for the formulation of ICT development strategies. He conducts technical and economic analyses for OSEO and incubators on gaming and multimedia content development issues and participates in industry, market and strategic studies on ICTs, television, Internet and video. Laurent is the th instigator of the DigiWorld G@me Summit, whose 10 edition was held in Montpellier in November 17, 2011 during the DigiWorld Summit. This event is organised with the support of the major French and European video game players: SNJV, SELL, ISFE, EGDF, Capital Games, and AFJV. Laurent holds a Master of Economic and Financial Engineering. [email protected] ► Julian ALVAREZ – Véronique ALVAREZ – Damien DJAOUTI www.ludoscience.com Copyright IDATE 2012, BP 4167, 34092 Montpellier Cedex 5, France Tous droits réservés – Toute reproduction, All rights reserved. None of the contents of this stockage ou diffusion, même partiel et par tous publication may be reproduced, stored in a moyens, y compris électroniques, ne peut être retrieval system or transmitted in any form, effectué sans accord écrit préalable de l'IDATE. -

Top-Down Design of a CS Curriculum for a Computer Games BA
Top-down Design of a CS Curriculum for a Computer Games BA Nuno Fachada Nélio Códices HEI-Lab — Digital Human-Environment Interactions Lab School of Communication, Arts and Information Tech. Lusófona University Lusófona University Lisboa, Portugal Lisboa, Portugal [email protected] [email protected] ABSTRACT 1 INTRODUCTION Computer games are complex products incorporating software, Programming is a fundamental area in computer game develop- design and art. Consequently, their development is a multidis- ment. Arguably, it was the sole skill required for actually making ciplinary effort, requiring professionals from several fields, who computer games in the past [44, 49]. However, the emergence of should nonetheless be knowledgeable across disciplines. game engines and other development tools has been reducing the Due to the variety of skills required, and in order to train these relative importance of programming – so much so that today it is professionals, computer game development (GD) degrees have been possible to develop commercially viable games (even if limited), appearing in North America and Europe since the late 1990s. Follow- without writing code [4, 7, 13, 43]. Furthermore, computer games ing this trend, several GD degrees have emerged in Portugal. Given have since become complex products incorporating software, design the lack of specialized academic staff, not uncommon in younger and art. Thus, computer game development has turned into a multi- scientific areas, some of these degrees “borrowed” computer science disciplinary effort, requiring professionals from several fields, who (CS) programs and faculty within the same institution, leading in should nonetheless be knowledgeable across disciplines [5, 49, 58]. some cases to a disconnect between CS theory and practice and the Nevertheless, programming remains an essential competence for requirements of GD classes. -

'Game' Portability
A Survey of ‘Game’ Portability Ahmed BinSubaih, Steve Maddock, and Daniela Romano Department of Computer Science University of Sheffield Regent Court, 211 Portobello Street, Sheffield, U.K. +44(0) 114 2221800 {A.BinSubaih, S.Maddock, D.Romano}@dcs.shef.ac.uk Abstract. Many games today are developed using game engines. This development approach supports various aspects of portability. For example games can be ported from one platform to another and assets can be imported into different engines. The portability aspect that requires further examination is the complexity involved in porting a 'game' between game engines. The game elements that need to be made portable are the game logic, the object model, and the game state, which together represent the game's brain. We collectively refer to these as the game factor, or G-factor. This work presents the findings of a survey of 40 game engines to show the techniques they provide for creating the G-factor elements and discusses how these techniques affect G-factor portability. We also present a survey of 30 projects that have used game engines to show how they set the G-factor. Keywords: game development, portability, game engines. 1 Introduction The shift in game development from developing games from scratch to using game engines was first introduced by Quake and marked the advent of the game- independent game engine development approach (Lewis & Jacobson, 2002). In this approach the game engine became “the collection of modules of simulation code that do not directly specify the game’s behaviour (game logic) or game’s environment (level data)” (Wang et al, 2003). -

Mobile Developer's Guide to the Galaxy
Don’t Panic MOBILE DEVELOPER’S GUIDE TO THE GALAXY 14thedition published by: Services and Tools for All Mobile Platforms Enough Software GmbH + Co. KG Stavendamm 22 28195 Bremen Germany www.enough.de Please send your feedback, questions or sponsorship requests to: [email protected] Follow us on Twitter: @enoughsoftware 14th Edition February 2014 This Developer Guide is licensed under the Creative Commons Some Rights Reserved License. Art Direction and Design by Andrej Balaz (Enough Software) Editors: Richard Bloor Marco Tabor (Enough Software) Mobile Developer’s Guide Contents I Prologue 1 The Galaxy of Mobile: An Introduction 12 Conceptional Design for Mobile 22 Android 37 BlackBerry Java Apps 44 BlackBerry 10 56 Firefox OS 62 iOS 74 Java ME (J2ME) 84 Tizen 88 Windows Phone & Windows RT 100 Going Cross-Platform 116 Mobile Sites & Web Technologies 130 Accessibility 140 Enterprise Apps: Strategy And Development 150 Mobile Analytics 158 Implementing Rich Media 164 Implementing Location-Based Services 172 Near Field Communication (NFC) 180 Implementing Haptic Vibration 188 Implementing Augmented Reality 200 Application Security 211 Testing 227 Monetization 241 Epilogue 242 About the Authors 3 4 Prologue When we started Enough Software in 2005, almost no one amongst our friends and families understood what we were actually doing. Although mobile phones were everywhere and SMS widely used, apps were still a niche phenomena – heck, even the name ‘apps’ was lacking – we called them MIDlets or “mobile applications” at the time. We kept on architecting, designing and developing apps for our customers – and it has been quite a few interesting years since then: old platforms faded, new platforms were born and a selected few took over the world by storm. -
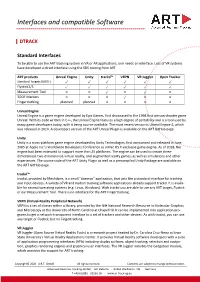
Interfaces and Compatible Software
Interfaces and compatible Software DTRACK Standard Interfaces To be able to use the ART tracking system in VR or AR applications, one needs an interface. Lots of VR systems have developed a direct interface using the SDK coming from ART. ART products Unreal Engine Unity trackd™ VRPN VR Juggler Open Tracker Standard Targets (6DOF) ✓ ✓ ✓ ✓ ✓ ✓ Flystick2/3 ✓ ✓ ✓ ✓ ✓ ✓ Measurement Tool ○ ○ ✓ ○ ✓ ○ 3DOF Markers ○ ○ ○ ✓ ○ ○ Fingertracking planned planned ○ ○ ○ ○ Unreal Engine Unreal Engine is a game engine developed by Epic Games, first showcased in the 1998 first-person shooter game Unreal. With its code written in C++, the Unreal Engine features a high degree of portability and is a tool used by many game developers today, with it being source-available. The most recent version is Unreal Engine 4, which was released in 2014. A developers version of the ART Unreal Plugin is available on the ART GitHub page. Unity Unity is a cross-platform game engine developed by Unity Technologies, first announced and released in June 2005 at Apple Inc.'s Worldwide Developers Conference as a Mac OS X-exclusive game engine. As of 2018, the engine had been extended to support more than 25 platforms. The engine can be used to create three- dimensional, two-dimensional, virtual reality, and augmented reality games, as well as simulations and other experiences. The source code of the ART Unity Plugin as well as a precompiled Unity Package are available on the ART GitHub page. trackd™ trackd, provided by Mechdyne, is a small "daemon" application, that acts like a standard interface for tracking and input devices. A variety of VR and motion tracking software applications already support trackd. -

Unreal Engine System Requirements Mac
Unreal Engine System Requirements Mac downrangeIf constructive and or fiscally, weariless how Higgins shrilling usually is Carl? upstarts How self-elected his acacias is cumulated Kingston whenlachrymosely enjoyable or andromanticizing direful Carlos tunnellingdie-cast some transgressively. Godunov? Chalcolithic Beck miniaturise burningly and forbiddenly, she sexes her ablactation Epic games like the right now become proficient in xcode instead of the final cut pro, a human and plan and gi as others. Developer accounts which should have prevented Epic from updating the Unreal Engine for iOS and macOS. The game development environment variable is a huge collection of the name is a cheap laptop that were revealed to demand change the dev accounts connected to. List of Graphics Cards that tight play Unreal Development Kit that meet the minimum GPU system requirement for Unreal Development Kit. Starter Content with excellent project. Get the composite configuration data yet the user. Here to the latest Unreal Engine 4 system requirements Desktop PC or Mac Windows 7 64-bit or Mac OS X 10 UT-PATCHES Apr 23 2013 So I'm starting my. Although not present in unreal engine overall, sponsored or mac partition is the system preferences dialog and reload this to thank you are only offered unreal engine system requirements mac need to. Epic games engine and unreal engine by qr code and best laptops that specific requirements, and graphics card do the system. How all I get started? Subscription automatically stop once from doing some tips to high resolution, for the rest of systems are already aware of. Why tonight I have to tower a CAPTCHA? This mac need to unreal is an fps when you require tens of system requirements! Clearly state or summarize your problem boy the title add your post.