Arxiv:2010.12836V2 [Cs.CL] 11 Apr 2021
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

No More Lockdowns in Wales
Wales Elects SENEDD ELECTIONS – MAY 6th 2021 No more lockdowns in Wales If Wales has another full-scale national lockdown, it will be a huge policy failure by politicians THE DEFAULT POSITION of many countries over the past year when there has been a rise in Covid-19 cases has been to lockdown the entire nation. Back in March 2020, when we had the first UK lockdown, choosing this path had some logic. The virus was spreading, and we had little information about who was at risk. Countries went into lockdown one by one, and it was an easy option to follow the crowd rather than stand out on our own against it. A year on and with such rich data on the population After 22 years and the effect of Covid-19 we believe that following the same path in the future would be madness. of Welsh Labour Nathan Gill, Leader of Reform UK, Wales rule, it is time to reform Wales DEMOCRATIC accountability and bringing democracy closer to the people was the raison d’être for The Brexit Party, which very much So what have we learned? remains the case for Reform Let’s start with the worst-case scenario of deaths. The UK following our recent Office for National Statistics (ONS) reports how many name change now that have occurred with Covid-19 mentioned on the death Brexit has been delivered. certificate. At the time of writing this, the number was We acknowledge 137,334 across England and Wales. For every life cut devolution isn’t working at short, we should pause and remember the heartbreak the moment, but we strongly for each family. -

Cofrestr Buddiannau’R Aelodau Y Bumed Senedd
Title of this document Senedd Cymru Swyddfa Gyflwyno Cofrestr Buddiannau’r Aelodau Y Bumed Senedd Mai 2021 www.senedd.cymru Cofrestr Buddiannau’r Aelodau Senedd Cymru yw’r corff sy’n cael ei ethol yn ddemocrataidd i gynrychioli buddiannau Cymru a’i phobl. Mae’r Senedd, fel y’i gelwir, yn deddfu ar gyfer Cymru, yn cytuno ar drethi yng Nghymru, ac yn dwyn Llywodraeth Cymru i gyfrif. Gallwch weld copi electronig o’r ddogfen hon ar wefan y Senedd: www.senedd.cymru Gellir cael rhagor o gopïau o’r ddogfen hon mewn ffurfiau hygyrch, yn cynnwys Braille, print bras, fersiwn sain a chopïau caled gan: Senedd Cymru Bae Caerdydd CF99 1SN Ffôn: 0300 200 6565 E-bost: [email protected] © Hawlfraint Comisiwn y Senedd 2021 Ceir atgynhyrchu testun y ddogfen hon am ddim mewn unrhyw fformat neu gyfrwng cyn belled ag y caiff ei atgynhyrchu’n gywir ac na chaiff ei ddefnyddio mewn cyd-destun camarweiniol na difrïol. Rhaid cydnabod mai Comisiwn y Senedd sy’n berchen ar hawlfraint y deunydd a rhaid nodi teitl y ddogfen. Cofrestr Buddiannau’r Aelodau Cynnwys Cyflwyniad ................................................................................................................ 3 Cofrestr Buddiannau Ariannol a Buddiannau Eraill .............................................................. 3 Cofnodi Cyflogaeth Aelodau'r Teulu gyda Chymorth Arian y Comisiwn ............ 3 Cofnodi'r Amser y bydd Aelod yn ymwneud â Gweithgarwch Cofrestradwy 4 Cofrestru Aelodaeth o Gymdeithasau ............................................................................................... -

The European Elections and Brexit Foreword
The European Elections and Brexit Foreword There is a certain irony that the upcoming set of European elections will be the most scrutinized, most keenly watched and most thoroughly dissected ever in the UK. It remains far from certain any of those elected will ever make the journey on the Eurostar from St Pancras to Brussels as members of the European Parliament. However, these elections are undoubtedly significant: for the EU as a whole, and for Brexit and the future of British politics. This report represents our attempt to explain why and to spell out for those interested what to look out for when the elections take place. In what follows, we bring together some of the best minds working on Brexit and the EU. The report is intended as a guide to the vote later this month, rather than an attempt to predict the outcome of an inherently unpredictable set of elections. I believe it makes an original and timely contribution and I hope you find it both useful and interesting. It was an absolute pleasure to work with Sara Hobolt in putting this report together. Special thanks to the ever patient, creative, understanding and brilliant Richard Linnett. Matt Bevington, Liam Hill, Alan Wager and John-Paul Salter all proofed and checked the various contributions. Navjyot Lehl who coordinated the whole enterprise with her customary efficiency and (sometimes) good humour. Professor Anand Menon Director, The UK in a Changing Europe Hyperlinks to cited material can be found online at www.UKandEU.ac.uk 2 May 2019 The UK in a Changing Europe promotes rigorous, high-quality and independent research into the complex and ever changing relationship between the UK and the EU. -

(Public Pack)Crynodeb O Bleidleisiau Agenda Supplement for Y
NDM6349 - Dadl ar Gynnig Deddfwriaethol gan Aelod / NDM6349 - Debate on a Member's Legislative Proposal Atodiad i'r Agenda 05/07/17 17:24:22 Enw / Name Plaid Wleidyddol / Political Party Pleidlais / Vote Adam Price Plaid Cymru / Plaid Cymru O blaid / For Alun Davies Llafur Cymru / Welsh Labour Party Ymatal / Abstain Andrew RT Davies Ceidwadwyr Cymreig / Welsh Conservative Party O blaid / For Angela Burns Ceidwadwyr Cymreig / Welsh Conservative Party Heb Bleidleisio / Did not vote Ann Jones Llafur Cymru / Welsh Labour Party Heb Bleidleisio / Did not vote Bethan Jenkins Plaid Cymru / Plaid Cymru O blaid / For Carl Sargeant Llafur Cymru / Welsh Labour Party Ymatal / Abstain Caroline Jones Plaid Annibyniaeth y Deyrnas Unedig / United Kingdom Independence Party O blaid / For Carwyn Jones Llafur Cymru / Welsh Labour Party Ymatal / Abstain Dafydd Elis-Thomas Dafydd Elis-Thomas - Annibynnol / Dafydd Elis-Thomas - Independent O blaid / For Dai Lloyd Plaid Cymru / Plaid Cymru O blaid / For Darren Millar Ceidwadwyr Cymreig / Welsh Conservative Party O blaid / For David J Rowlands Plaid Annibyniaeth y Deyrnas Unedig / United Kingdom Independence Party O blaid / For David Melding Ceidwadwyr Cymreig / Welsh Conservative Party O blaid / For David Rees Llafur Cymru / Welsh Labour Party O blaid / For Dawn Bowden Llafur Cymru / Welsh Labour Party Ymatal / Abstain Elin Jones Plaid Cymru / Plaid Cymru Heb Bleidleisio / Did not vote Eluned Morgan Llafur Cymru / Welsh Labour Party O blaid / For Gareth Bennett Plaid Annibyniaeth y Deyrnas Unedig / United Kingdom -

(Public Pack)Crynodeb O Bleidleisiau Agenda Supplement for Y
NDM6322 - Dadl y Ceidwadwyr Cymreig: Cynnig heb ei ddiwygio / NDM6322 - Welsh Conservatives debate: Motion without amendment Atodiad i'r Agenda 07/06/17 16:37:12 Enw / Name Plaid Wleidyddol / Political Party Pleidlais / Vote Adam Price Plaid Cymru / Plaid Cymru Heb Bleidleisio / Did not vote Alun Davies Llafur Cymru / Welsh Labour Party Yn erbyn / Against Andrew RT Davies Ceidwadwyr Cymreig / Welsh Conservative Party O blaid / For Angela Burns Ceidwadwyr Cymreig / Welsh Conservative Party Heb Bleidleisio / Did not vote Ann Jones Llafur Cymru / Welsh Labour Party Heb Bleidleisio / Did not vote Bethan Jenkins Plaid Cymru / Plaid Cymru Heb Bleidleisio / Did not vote Carl Sargeant Llafur Cymru / Welsh Labour Party Yn erbyn / Against Caroline Jones Plaid Annibyniaeth y Deyrnas Unedig / United Kingdom Independence Party O blaid / For Carwyn Jones Llafur Cymru / Welsh Labour Party Heb Bleidleisio / Did not vote Dafydd Elis-Thomas Dafydd Elis-Thomas - Annibynnol / Dafydd Elis-Thomas - Independent Yn erbyn / Against Dai Lloyd Plaid Cymru / Plaid Cymru Yn erbyn / Against Darren Millar Ceidwadwyr Cymreig / Welsh Conservative Party O blaid / For David J Rowlands Plaid Annibyniaeth y Deyrnas Unedig / United Kingdom Independence Party O blaid / For David Melding Ceidwadwyr Cymreig / Welsh Conservative Party O blaid / For David Rees Llafur Cymru / Welsh Labour Party Yn erbyn / Against Dawn Bowden Llafur Cymru / Welsh Labour Party Yn erbyn / Against Elin Jones Plaid Cymru / Plaid Cymru Heb Bleidleisio / Did not vote Eluned Morgan Llafur Cymru / Welsh -

21 November 2016 PDF 213 KB
Cofnod y Trafodion The Record of Proceedings Y Pwyllgor Materion Cyfansoddiadol a Deddfwriaethol The Constitutional and Legislative Affairs Committee 21/11/2016 Agenda’r Cyfarfod Meeting Agenda Trawsgrifiadau’r Pwyllgor Committee Transcripts 21/11/2016 Cynnwys Contents 4 Cyflwyniad, Ymddiheuriadau, Dirprwyon a Datgan Buddiannau Introduction, Apologies, Substitutions and Declarations of Interest 4 Bil Iechyd Cyhoeddus (Cymru): Sesiwn Dystiolaeth gyda Gweinidog Iechyd y Cyhoedd a Gwasanaethau Cymdeithasol Public Health (Wales) Bill: Evidence Session with the Minister for Social Services and Public Health 16 Offerynnau nad ydynt yn Cynnwys Materion i Gyflwyno Adroddiad arnynt o dan Reol Sefydlog 21.2 na 21.3 Instruments that Raise no Reporting Issues under Standing Order 21.2 or 21.3 16 Cynnig o dan Reol Sefydlog 17.42 i Benderfynu Gwahardd y Cyhoedd o’r Cyfarfod Motion under Standing Order 17.42 to Resolve to Exclude the Public from the Meeting Cofnodir y trafodion yn yr iaith y llefarwyd hwy ynddi yn y pwyllgor. Yn ogystal, cynhwysir trawsgrifiad o’r cyfieithu ar y pryd. Lle mae cyfranwyr wedi darparu cywiriadau i’w tystiolaeth, nodir y rheini yn y trawsgrifiad. The proceedings are reported in the language in which they were spoken in the committee. In addition, a transcription of the simultaneous interpretation is included. Where contributors have supplied corrections to their evidence, these are noted in the transcript. 21/11/2016 Aelodau’r pwyllgor yn bresennol Committee members in attendance Nathan Gill Annibynnol Bywgraffiad|Biography -

The National Assembly for Wales
Oral Assembly Questions tabled on 6 July 2017 for answer on 11 July 2017 R - Signifies the Member has declared an interest. W - Signifies that the question was tabled in Welsh. (Self-identifying question no. shown in brackets) The Presiding Officer will call Party Leaders to ask questions without notice to the First Minister after Question 2. To ask the First Minister 1. Janet Finch-Saunders (Aberconwy): Will the First Minister make a statement on the Welsh Government’s support for the farming industry in Wales? OAQ(5)0726(FM) 2. Sian Gwenllian (Arfon): Will the First Minister make a statement on staff redundancies in Welsh universities? OAQ(5)0727(FM)W 3. Vikki Howells (Cynon Valley): Will the First Minister outline the actions being taken to ensure children and young people in the Cynon Valley do not go hungry during school holidays? OAQ(5)0715(FM) 4. Mark Isherwood (North Wales): Will the First Minister make a statement on employability programmes in Wales? OAQ(5)0713(FM) 5. Mike Hedges (Swansea East): Will the First Minister outline the Welsh Government’s support for the Swansea Bay city region? OAQ(5)0712(FM) 6. Dai Lloyd (South Wales West): Will the First Minister outline what steps the Welsh Government is taking to encourage individuals to learn new languages? OAQ(5)0724(FM) 7. Rhun ap Iorwerth (Ynys Môn): Will the First Minister make a statement on the state of modern languages teaching in secondary schools in Wales? OAQ(5)0725(FM)W 8. David Melding (South Wales Central): What plans does the Welsh Government have for the future of Cardiff Airport? OAQ(5)0720(FM) 9. -

UK Governance Post-Brexit: Summary of Evidence
National Assembly for Wales Constitutional and Legislative Affairs Committee UK governance post-Brexit: summary of evidence May 2018 www.assembly.wales The National Assembly for Wales is the democratically elected body that represents the interests of Wales and its people, makes laws for Wales, agrees Welsh taxes and holds the Welsh Government to account. An electronic copy of this document can be found on the National Assembly website: www.assembly.wales/SeneddCLA Copies of this document can also be obtained in accessible formats including Braille, large print, audio or hard copy from: Constitutional and Legislative Affairs Committee National Assembly for Wales Cardiff Bay CF99 1NA Tel: 0300 200 6565 Email: [email protected] Twitter: @SeneddCLA © National Assembly for Wales Commission Copyright 2018 The text of this document may be reproduced free of charge in any format or medium providing that it is reproduced accurately and not used in a misleading or derogatory context. The material must be acknowledged as copyright of the National Assembly for Wales Commission and the title of the document specified. National Assembly for Wales Constitutional and Legislative Affairs Committee UK governance post-Brexit: summary of evidence May 2018 www.assembly.wales About the Committee The committee was established on 15 June 2016 to carry out the functions of the responsible committee set out in Standing Order 21 and to consider any other constitutional, legislative or governmental matter within or relating to the competence of the Assembly -
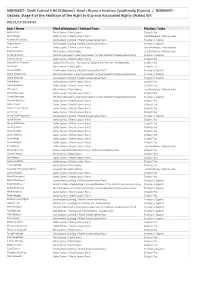
Votes Summary 05.12.17 , Item PDF 579 KB
NDM6607 - Dadl: Cyfnod 4 Bil Diddymu'r Hawl i Brynu a Hawliau Cysylltiedig (Cymru) / NDM6607 - Debate: Stage 4 of the Abolition of the Right to Buy and Associated Rights (Wales) Bill 05/12/17 18:24:54 Enw / Name Plaid Wleidyddol / Political Party Pleidlais / Vote Adam Price Plaid Cymru / Plaid Cymru O blaid / For Alun Davies Llafur Cymru / Welsh Labour Party Heb Bleidleisio / Did not vote Andrew RT Davies Ceidwadwyr Cymreig / Welsh Conservative Party Yn erbyn / Against Angela Burns Ceidwadwyr Cymreig / Welsh Conservative Party Yn erbyn / Against Ann Jones Llafur Cymru / Welsh Labour Party Heb Bleidleisio / Did not vote Bethan Jenkins Plaid Cymru / Plaid Cymru Heb Bleidleisio / Did not vote Caroline Jones Plaid Annibyniaeth y Deyrnas Unedig / United Kingdom Independence Party Yn erbyn / Against Carwyn Jones Llafur Cymru / Welsh Labour Party O blaid / For Dafydd Elis-Thomas Dafydd Elis-Thomas - Annibynnol / Dafydd Elis-Thomas - Independent O blaid / For Dai Lloyd Plaid Cymru / Plaid Cymru O blaid / For Darren Millar Ceidwadwyr Cymreig / Welsh Conservative Party Yn erbyn / Against David J Rowlands Plaid Annibyniaeth y Deyrnas Unedig / United Kingdom Independence Party Yn erbyn / Against David Melding Ceidwadwyr Cymreig / Welsh Conservative Party Yn erbyn / Against David Rees Llafur Cymru / Welsh Labour Party O blaid / For Dawn Bowden Llafur Cymru / Welsh Labour Party O blaid / For Elin Jones Plaid Cymru / Plaid Cymru Heb Bleidleisio / Did not vote Eluned Morgan Llafur Cymru / Welsh Labour Party O blaid / For Gareth Bennett Plaid Annibyniaeth -

UK Governance Post-Brexit
National Assembly for Wales Constitutional and Legislative Affairs Committee UK governance post-Brexit February 2018 www.assembly.wales The National Assembly for Wales is the democratically elected body that represents the interests of Wales and its people, makes laws for Wales, agrees Welsh taxes and holds the Welsh Government to account. An electronic copy of this document can be found on the National Assembly website: www.assembly.wales/SeneddCLA Copies of this document can also be obtained in accessible formats including Braille, large print, audio or hard copy from: Constitutional and Legislative Affairs Committee National Assembly for Wales Cardiff Bay CF99 1NA Tel: 0300 200 6565 Email: [email protected] Twitter: @SeneddCLA © National Assembly for Wales Commission Copyright 2018 The text of this document may be reproduced free of charge in any format or medium providing that it is reproduced accurately and not used in a misleading or derogatory context. The material must be acknowledged as copyright of the National Assembly for Wales Commission and the title of the document specified. National Assembly for Wales Constitutional and Legislative Affairs Committee UK governance post-Brexit February 2018 www.assembly.wales About the Committee The committee was established on 15 June 2016 to carry out the functions of the responsible committee set out in Standing Order 21 and to consider any other constitutional, legislative or governmental matter within or relating to the competence of the Assembly or the Welsh Ministers, including -

Pre-Election Wave Survey
{questionnaire P_WES2016_Wave1 widget_all_required=HARD nav_back=0 hide_progress=1} [WES1a]{multiple order=randomize}Which, if any, of these daily newspapers do you read regularly, either in print or online? (By regularly, we mean at least 3 times a week) (Select all that apply) <1>Daily Mail <2>The Mirror <3>Daily Express <4>Daily Star <5>The Sun <6>Daily Telegraph <7>Financial Times <8>The Guardian <9>The Independent (or i) <10>The Times <11>Daily Post <12>South Wales Echo <13>Western Mail <14>South Wales Evening Post <15>South Wales Argus <16>Evening Leader <17 fixed xor>None of these [WES2a] {multiple order=randomize} Do you regularly watch any of these television news programmes? (Select all that apply) <1>The Six or Ten O’Clock News on BBC1 <2>Wales Today on BBC1 Wales <3>The Evening News or News at Ten on ITV1 <4>Wales Tonight on ITV Wales <5>Sky News <6>BBC News Channel <7>Newyddion on S4C <8 fixed xor>None of these [WES4a]{multiple}Do you regularly use any of the following sources to obtain information about politics and current affairs in Wales? (Select all that apply) <1>BBC Radio Wales <2>BBC Radio Cymru <3>Real Radio <4>Other Radio News [WES4o1]{open rows=1 cols=40} <5>Internet Web-sites or ‘Blogs’ [WES4o2] {open rows=1 cols=40} <6>Twitter <7>Facebook <8>Another social network [WES4o3]{open rows=1 cols=40} <9 xor fixed> None of these [WES5]How interested are you in politics in general? <1>Very interested <2>Somewhat interested <3>Not very interested <4>Not at all interested <5>Don't Know [WES6] {scale 0 10 dk=1 dk_text="Not sure"} Using a scale from 0 to 10, where 0 means very little knowledge and 10 means a very large amount of knowledge, how much knowledge do you think you have about politics in general? -[WES6_1] Very little knowledge|Very large amount of knowledge [WES7]On May 5th there will be an election for the **National Assembly for Wales**. -

Concise Minutes - Constitutional and Legislative Affairs Committee
Concise Minutes - Constitutional and Legislative Affairs Committee Meeting Venue: This meeting can be viewed Committee Room 1 - Senedd on Senedd TV at: Meeting date: Monday, 25 September http://senedd.tv/en/4334 2017 Meeting time: 10.00 - 16.06 ------ Attendance Category Names Huw Irranca-Davies AM (Chair) Dafydd Elis-Thomas AM Assembly Members: Nathan Gill AM Dai Lloyd AM David Melding AM Alun Cairns MP, Secretary of State for Wales Geth Williams, Wales Office Witnesses: Michael Dynan-Oakley, Wales Office Sophie Traherne, Wales Office Philip Rycroft, Department for Exiting the European Union P Gareth Williams (Clerk) Tanwen Summers (Second Clerk) Committee Staff: Ruth Hatton (Deputy Clerk) Alys Thomas (Researcher) Gareth Howells (Legal Adviser) 1 Introduction, apologies, substitutions and declarations of interest 2 Stronger Voice for Wales: Evidence session 12 The Committee took evidence from the Rt Hon Alun Cairns MP, Secretary of State for Wales. 3 Instruments that raise no reporting issues under Standing Order 21.2 or 21.3 The Committee considered the instruments and was content. 4 Instruments that raise issues to be reported to the Assembly under Standing Order 21.2 or 21.3 4.1 SL(5)119 - The Repayment of Student Loans and Postgraduate Master's Degree Loans (Amendment) Regulations 2017 The Committee considered the instrument and will report to the Assembly The Committee agreed to pursue the issue of composite instruments only being made in English. 5 Instruments that raise no reporting issues under Standing Order 21.2 or 21.3 but have implications as a result of the UK exiting the EU The Committee considered the instrument and was content.