Harnessing Omic Approaches to Understand How Carbon
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
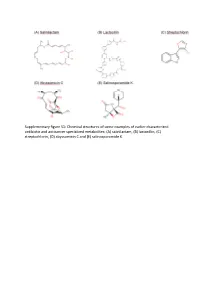
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

Novel Copper-Containing Membrane Monooxygenases (Cummos) Encoded by Alkane- Utilizing Betaproteobacteria
Lawrence Berkeley National Laboratory Recent Work Title Novel copper-containing membrane monooxygenases (CuMMOs) encoded by alkane- utilizing Betaproteobacteria. Permalink https://escholarship.org/uc/item/8z48x96q Journal The ISME journal, 14(3) ISSN 1751-7362 Authors Rochman, Fauziah F Kwon, Miye Khadka, Roshan et al. Publication Date 2020-03-01 DOI 10.1038/s41396-019-0561-2 Peer reviewed eScholarship.org Powered by the California Digital Library University of California 1 1 2 1Novel copper-containing membrane monooxygenases 2(CuMMOs) encoded by alkane-utilizing Betaproteobacteria 3 4Running title: Novel CuMMOs in Betaproteobacteria 5 6Fauziah F. Rochman1, Miye Kwon2, Roshan Khadka1, Ivica Tamas1,3, Azriel 7Abraham Lopez-Jauregui1,4, Andriy Sheremet1, Angela Smirnova1, Rex R. 8Malmstrom5, Sukhwan Yoon2, Tanja Woyke5, Peter F. Dunfield1*, Tobin J. 9Verbeke1 10 111 Department of Biological Sciences, University of Calgary, 2500 University 12Dr. NW Calgary AB Canada T2N 1N4 132 Department of Civil and Environmental Engineering, Korea Advanced 14Institute of Science and Technology, Daejeon, Korea 153Department of Biology and Ecology, University of Novi Sad Novi Sad, Serbia 164 Instituto Tecnologico y de Estudios Superiores de Monterrey, Chihuahua, 17Mexico 185 Department of Energy Joint Genome Institute, Walnut Creek, California, 19USA. 20 21*Corresponding author: [email protected]; 403-220-2469 22 3 2 4 23Competing interests: The authors declare that they have no competing 24interests. 5 3 6 25Abstract 26Copper-containing membrane monooxygenases (CuMMOs) are encoded by 27xmoCAB(D) gene clusters and catalyze the oxidation of methane, ammonia, 28or some short chain alkanes and alkenes. In a metagenome constructed from 29an oilsands tailings pond we detected an xmoCABD gene cluster with <59% 30derived amino acid identity to genes from known bacteria. -

Single-Cell Genomics Reveals the Lifestyle of Poribacteria, a Candidate Phylum Symbiotically Associated with Marine Sponges
The ISME Journal (2011) 5, 61–70 & 2011 International Society for Microbial Ecology All rights reserved 1751-7362/11 www.nature.com/ismej ORIGINAL ARTICLE Single-cell genomics reveals the lifestyle of Poribacteria, a candidate phylum symbiotically associated with marine sponges Alexander Siegl1,5, Janine Kamke1, Thomas Hochmuth2,Jo¨rn Piel2, Michael Richter3, Chunguang Liang4, Thomas Dandekar4 and Ute Hentschel1 1Department of Botany II, Julius-von-Sachs Institute for Biological Sciences, University of Wuerzburg, Wuerzburg, Germany; 2Kekule´ Institute of Organic Chemistry and Biochemistry, University of Bonn, Bonn, Germany; 3Ribocon GmbH, Bremen, Germany and 4Department of Bioinformatics, Biocenter, University of Wuerzburg, Wuerzburg, Germany In this study, we present a single-cell genomics approach for the functional characterization of the candidate phylum Poribacteria, members of which are nearly exclusively found in marine sponges. The microbial consortia of the Mediterranean sponge Aplysina aerophoba were singularized by fluorescence-activated cell sorting, and individual microbial cells were subjected to phi29 polymerase-mediated ‘whole-genome amplification’. Pyrosequencing of a single amplified genome (SAG) derived from a member of the Poribacteria resulted in nearly 1.6 Mb of genomic information distributed among 554 contigs analyzed in this study. Approximately two-third of the poribacterial genome was sequenced. Our findings shed light on the functional properties and lifestyle of a possibly ancient bacterial symbiont of marine sponges. The Poribacteria are mixotrophic bacteria with autotrophic CO2-fixation capacities through the Wood–Ljungdahl pathway. The cell wall is of Gram-negative origin. The Poribacteria produce at least two polyketide synthases (PKSs), one of which is the sponge-specific Sup-type PKS. -

Evolution Génomique Chez Les Bactéries Du Super Phylum Planctomycetes-Verrucomicrobiae-Chlamydia
AIX-MARSEILLE UNIVERSITE FACULTE DE MEDECINE DE MARSEILLE ECOLE DOCTORALE : SCIENCE DE LA VIE ET DE LA SANTE THESE Présentée et publiquement soutenue devant LA FACULTE DE MEDECINE DE MARSEILLE Le 15 janvier 2016 Par Mme Sandrine PINOS Née à Saint-Gaudens le 09 octobre 1989 TITRE DE LA THESE: Evolution génomique chez les bactéries du super phylum Planctomycetes-Verrucomicrobiae-Chlamydia Pour obtenir le grade de DOCTORAT d'AIX-MARSEILLE UNIVERSITE Spécialité : Génomique et Bioinformatique Membres du jury de la Thèse: Pr Didier RAOULT .................................................................................Directeur de thèse Dr Pierre PONTAROTTI ....................................................................Co-directeur de thèse Pr Gilbert GREUB .............................................................................................Rapporteur Dr Pascal SIMONET............................................................................................Rapporteur Laboratoires d’accueil Unité de Recherche sur les Maladies Infectieuses et Tropicales Emergentes – UMR CNRS 6236, IRD 198 I2M - UMR CNRS 7373 - EBM 1 Avant propos Le format de présentation de cette thèse correspond à une recommandation de la spécialité Maladies Infectieuses et Microbiologie, à l’intérieur du Master de Sciences de la Vie et de la Santé qui dépend de l’Ecole Doctorale des Sciences de la Vie de Marseille. Le candidat est amené à respecter des règles qui lui sont imposées et qui comportent un format de thèse utilisé dans le Nord de l’Europe permettant un meilleur rangement que les thèses traditionnelles. Par ailleurs, la partie introduction et bibliographie est remplacée par une revue envoyée dans un journal afin de permettre une évaluation extérieure de la qualité de la revue et de permettre à l’étudiant de le commencer le plus tôt possible une bibliographie exhaustive sur le domaine de cette thèse. Par ailleurs, la thèse est présentée sur article publié, accepté ou soumis associé d’un bref commentaire donnant le sens général du travail. -

Oceans of Archaea Abundant Oceanic Crenarchaeota Appear to Derive from Thermophilic Ancestors That Invaded Low-Temperature Marine Environments
Oceans of Archaea Abundant oceanic Crenarchaeota appear to derive from thermophilic ancestors that invaded low-temperature marine environments Edward F. DeLong arth’s microbiota is remarkably per- karyotes), Archaea, and Bacteria. Although al- vasive, thriving at extremely high ternative taxonomic schemes have been recently temperature, low and high pH, high proposed, whole-genome and other analyses E salinity, and low water availability. tend to support Woese’s three-domain concept. One lineage of microbial life in par- Well-known and cultivated archaea generally ticular, the Archaea, is especially adept at ex- fall into several major phenotypic groupings: ploiting environmental extremes. Despite their these include extreme halophiles, methanogens, success in these challenging habitats, the Ar- and extreme thermophiles and thermoacido- chaea may now also be viewed as a philes. Early on, extremely halo- cosmopolitan lot. These microbes philic archaea (haloarchaea) were exist in a wide variety of terres- first noticed as bright-red colonies trial, freshwater, and marine habi- Archaea exist in growing on salted fish or hides. tats, sometimes in very high abun- a wide variety For many years, halophilic isolates dance. The oceanic Marine Group of terrestrial, from salterns, salt deposits, and I Crenarchaeota, for example, ri- freshwater, and landlocked seas provided excellent val total bacterial biomass in wa- marine habitats, model systems for studying adap- ters below 100 m. These wide- tations to high salinity. It was only spread Archaea appear to derive sometimes in much later, however, that it was from thermophilic ancestors that very high realized that these salt-loving invaded diverse low-temperature abundance “bacteria” are actually members environments. -

Characterization of the First Cultured Representative of Verrucomicrobia Subdivision 5 Indicates the Proposal of a Novel Phylum
The ISME Journal (2016) 10, 2801–2816 OPEN © 2016 International Society for Microbial Ecology All rights reserved 1751-7362/16 www.nature.com/ismej ORIGINAL ARTICLE Characterization of the first cultured representative of Verrucomicrobia subdivision 5 indicates the proposal of a novel phylum Stefan Spring1, Boyke Bunk2, Cathrin Spröer3, Peter Schumann3, Manfred Rohde4, Brian J Tindall1 and Hans-Peter Klenk1,5 1Department Microorganisms, Leibniz Institute DSMZ-German Collection of Microorganisms and Cell Cultures, Braunschweig, Germany; 2Department Microbial Ecology and Diversity Research, Leibniz Institute DSMZ-German Collection of Microorganisms and Cell Cultures, Braunschweig, Germany; 3Department Central Services, Leibniz Institute DSMZ-German Collection of Microorganisms and Cell Cultures, Braunschweig, Germany and 4Central Facility for Microscopy, Helmholtz-Centre of Infection Research, Braunschweig, Germany The recently isolated strain L21-Fru-ABT represents moderately halophilic, obligately anaerobic and saccharolytic bacteria that thrive in the suboxic transition zones of hypersaline microbial mats. Phylogenetic analyses based on 16S rRNA genes, RpoB proteins and gene content indicated that strain L21-Fru-ABT represents a novel species and genus affiliated with a distinct phylum-level lineage originally designated Verrucomicrobia subdivision 5. A survey of environmental 16S rRNA gene sequences revealed that members of this newly recognized phylum are wide-spread and ecologically important in various anoxic environments ranging from hypersaline sediments to wastewater and the intestine of animals. Characteristic phenotypic traits of the novel strain included the formation of extracellular polymeric substances, a Gram-negative cell wall containing peptidoglycan and the absence of odd-numbered cellular fatty acids. Unusual metabolic features deduced from analysis of the genome sequence were the production of sucrose as osmoprotectant, an atypical glycolytic pathway lacking pyruvate kinase and the synthesis of isoprenoids via mevalonate. -

Structural, Spectroscopic, and Mechanistic Insights Into the Three Phases of Nitrification Metallobiochemistry
STRUCTURAL, SPECTROSCOPIC, AND MECHANISTIC INSIGHTS INTO THE THREE PHASES OF NITRIFICATION METALLOBIOCHEMISTRY A Dissertation Presented to the Faculty of the Graduate School of Cornell University In Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy | Chemistry and Chemical Biology By Meghan Anne Smith August 2018 © 2018 Meghan Anne Smith STRUCTURAL, SPECTROSCOPIC, AND MECHANISTIC INSIGHTS INTO THE THREE PHASES OF NITRIFICATION METALLOBIOCHEMISTRY Meghan Anne Smith, Ph. D. Cornell University 2018 Biological ammonia (NH3) oxidation, referred to as nitrification, is a critical part of the biogeochemical nitrogen cycle. Nitrification is mediated by both bacteria and – archaea to ultimately oxidize NH3 to nitrite (NO 2 ), though there are also complete NH3-oxidizing (comammox) bacteria capable of oxidizing NH3 completely to nitrate – (NO3 ). In addition to these products, nitrification is also a major source of the by- products and environmental pollutants nitric oxide (NO), nitrous oxide (N2O) and nitrogen dioxide (NO2). Many steps of biological nitrification, including those leading to the production of these harmful products, are not currently clear; however, the work presented in this dissertation describes recent efforts and discoveries towards a complete understanding of the nitrification pathway. This process begins in both bacteria and archaea with the enzyme ammonia monooxygenase (AMO), which oxidizes NH3 to hydroxylamine (NH2OH). There exist two metal-binding sites in AMO of interest as these are highly conserved in AMOs and related enzymes. The true active site of this enzyme remains in debate, but here we show that both sites must remain intact for effective catalysis. In bacteria, the formed NH2OH is further oxidized to NO by the enzyme NH2OH oxidoreductase (HAO), though prior convention stated – that HAO was able to oxidize NH2OH fully to NO2 . -

Corals and Sponges Under the Light of the Holobiont Concept: How Microbiomes Underpin Our Understanding of Marine Ecosystems
fmars-08-698853 August 11, 2021 Time: 11:16 # 1 REVIEW published: 16 August 2021 doi: 10.3389/fmars.2021.698853 Corals and Sponges Under the Light of the Holobiont Concept: How Microbiomes Underpin Our Understanding of Marine Ecosystems Chloé Stévenne*†, Maud Micha*†, Jean-Christophe Plumier and Stéphane Roberty InBioS – Animal Physiology and Ecophysiology, Department of Biology, Ecology & Evolution, University of Liège, Liège, Belgium In the past 20 years, a new concept has slowly emerged and expanded to various domains of marine biology research: the holobiont. A holobiont describes the consortium formed by a eukaryotic host and its associated microorganisms including Edited by: bacteria, archaea, protists, microalgae, fungi, and viruses. From coral reefs to the Viola Liebich, deep-sea, symbiotic relationships and host–microbiome interactions are omnipresent Bremen Society for Natural Sciences, and central to the health of marine ecosystems. Studying marine organisms under Germany the light of the holobiont is a new paradigm that impacts many aspects of marine Reviewed by: Carlotta Nonnis Marzano, sciences. This approach is an innovative way of understanding the complex functioning University of Bari Aldo Moro, Italy of marine organisms, their evolution, their ecological roles within their ecosystems, and Maria Pia Miglietta, Texas A&M University at Galveston, their adaptation to face environmental changes. This review offers a broad insight into United States key concepts of holobiont studies and into the current knowledge of marine model *Correspondence: holobionts. Firstly, the history of the holobiont concept and the expansion of its use Chloé Stévenne from evolutionary sciences to other fields of marine biology will be discussed. -

Link to the Report
DISCLAIMER This report was prepared as an account of a workshop sponsored by the U.S. Department of Energy. Neither the United States Government nor any agency thereof, nor any of their employees or officers, makes any warranty, express or implied, or assumes any legal liability or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or represents that its use would not infringe privately owned rights. Reference herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise, does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States Government or any agency thereof. The views and opinions of document authors expressed herein do not necessarily state or reflect those of the United States Government or any agency thereof. Copyrights to portions of this report (including graphics) are reserved by original copyright holders or their assignees, and are used by the Government’s license and by permission. Requests to use any images must be made to the provider identified in the image credits. On the cover: Argonne National Laboratory’s IBM Blue Gene/P supercomputer Inset visualization of ALG13 courtesy of David Baker, University of Washington AUTHORS AND CONTRIBUTORS Sponsors and representatives Susan Gregurick, DOE/Office of Biological and Environmental Science Daniel Drell, DOE/Office of Biological and Environmental Science Christine Chalk, DOE/Office of Advanced Scientific -

Metagenome-Scale Analysis Yields Insights Into the Structure And
Zhang et al. BMC Genetics (2016) 17:21 DOI 10.1186/s12863-016-0330-4 RESEARCH ARTICLE Open Access Metagenome-scale analysis yields insights into the structure and function of microbial communities in a copper bioleaching heap Xian Zhang1,2, Jiaojiao Niu1,2, Yili Liang1,2, Xueduan Liu1,2 and Huaqun Yin1,2* Abstract Background: Metagenomics allows us to acquire the potential resources from both cultivatable and uncultivable microorganisms in the environment. Here, shotgun metagenome sequencing was used to investigate microbial communities from the surface layer of low grade copper tailings that were industrially bioleached at the Dexing Copper Mine, China. A bioinformatics analysis was further performed to elucidate structural and functional properties of the microbial communities in a copper bioleaching heap. Results: Taxonomic analysis revealed unexpectedly high microbial biodiversity of this extremely acidic environment, as most sequences were phylogenetically assigned to Proteobacteria,whileEuryarchaeota-related sequences occupied little proportion in this system, assuming that Archaea probably played little role in the bioleaching systems. At the genus level, the microbial community in mineral surface-layer was dominated by the sulfur- and iron-oxidizing acidophiles such as Acidithiobacillus-like populations, most of which were A. ferrivorans-like and A. ferrooxidans-like groups. In addition, Caudovirales were the dominant viral type observed in this extremely environment. Functional analysis illustrated that the principal participants related to the key metabolic pathways (carbon fixation, nitrogen metabolism, Fe(II) oxidation and sulfur metabolism) were mainly identified to be Acidithiobacillus-like, Thiobacillus-like and Leptospirillum-like microorganisms, indicating their vital roles. Also, microbial community harbored certain adaptive mechanisms (heavy metal resistance, low pH adaption, organic solvents tolerance and detoxification of hydroxyl radicals) as they performed their functions in the bioleaching system. -

Profile of Edward Delong Paul Gabrielsen Enzymes Among Four Genera of Marine Bac- Science Writer Teria and Infer Evolutionary Relationships
PROFILE PROFILE Profile of Edward DeLong Paul Gabrielsen enzymes among four genera of marine bac- Science Writer teria and infer evolutionary relationships. “That’s where the inkling started that I Every year, gray whales travel up and down Finding Himself could combine my interests in biology and my passion for the ocean,” DeLong says. “I the Pacific coast, migrating between the Born in 1958, the third of six children, hadn’t even realized up until that point that Bering Sea and Baja California. In the mid- DeLong grew up in Sonoma, California on an research was an option.” The findings were 1970s, Northern California amateur skin “overdose of Jacques Cousteau,” he says. As diver Edward DeLong tried to swim out to published in the Archives of Microbiology a teenager, he encountered sea lions and sea with DeLong as first author (1). meet them. With his sights set on some of otters on skin diving expeditions with friends, ’ the ocean s largest creatures, DeLong was and attempted to reach gray whales. “We Setting His Compass oblivious to the microecosystem swirling never actually met them face to face,” he says. DeLong arrived at the Scripps Institution of around him in the cool water. Instead, his DeLong’s father, a high school English Oceanography in 1982 to begin graduate fascination for the vast and mysterious ocean teacher, encouraged his children in academ- school. Under biophysicist Art Yayanos, impelled him to reach for the huge, shadowy ics, but 18-year-old DeLong did not feel DeLong studied pressure-adapted micro- whales in the distance. -

Maximum Likelihood Placement of Environmental DNA Sequence Reads Into Curated Reference Phylogenies
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2011 MLTreeMap - maximum likelihood placement of environmental DNA sequence reads into curated reference phylogenies Stark, Manuel Abstract: Bei der Erforschung von mikrobiellen Gemeinschaften in situ stösst die traditionelle Mikrobi- ologie an ihre Grenzen, weil nur ein verschwindend kleiner Teil der Mikroben in Reinkultur gezu! chtet werden kann. Die Idee diesen Engpass zu umgehen, indem man DNA direkt aus aus der Umwelt extrahiert und daraufhin sequenziert, fu! hrte zur Entstehung eines neuen Forschungsfeldes, der Metagenomik. Mit Hilfe des metagenomischen Ansatzes ist es möglich, objektive Informationen u! ber alle in einer Probe präsenten Mikroben zu erhalten. Ein gewichtiger Nachteil ist allerdings, dass die gewonnenen Sequenz- daten nur fragmentiert vorliegen. MLTreeMap, das in dieser Dissertation vorgestellt wird, ist ein Soft- warepaket, welches in der Metagenomik Anwendung findet. Es wurde entwickelt, um Einblicke indie phylogenetischen und funktionellen Eigenschaften von Metagenomen und den ihnen zugrundeliegenden mikrobiellen Gemeinschaften zu gewinnen. Hierfür werden die zur Diskussion stehenden DNA Sequenzen auf eine Reihe von relevanten Markergenen hin durchsucht und deren wahrscheinlichste phylogenetische Herkunft ermittelt. Zu diesen Genen gehören proteinkodierende phylogenetische Marker, 16S und 18S rRNA Gene und Marker für wichtige Stoffwechselwege. Beispiele für letztere sind die Gene der Schlüsse- lenzyme der Photosynthese, Stickstofffixierung, Methanfixierung und Ammoniakoxidation. MLTreeMap kann entweder direkt über das Web benutzt werden (http://mltreemap.org) oder aber auf einem lokalen Computer installiert werden. Wir veröffentlichten MLTreeMap im Jahr 2010 im Journal BMC Genomics. Traditional microbiology has proven to be insufficient for studying entire microbial communities in situ, because only a small fraction of microbes can be grown in pure culture.