ECE/CS 757: Advanced Computer Architecture II Instructor:Mikko H Lipasti
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

AMD Ryzen 5 1600 Specifications
AMD Ryzen 5 1600 specifications General information Type CPU / Microprocessor Market segment Desktop Family AMD Ryzen 5 Model number 1600 CPU part numbers YD1600BBM6IAE is an OEM/tray microprocessor YD1600BBAEBOX is a boxed microprocessor with fan and heatsink Frequency 3200 MHz Turbo frequency 3600 MHz Package 1331-pin lidded micro-PGA package Socket Socket AM4 Introduction date March 15, 2017 (announcement) April 11, 2017 (launch) Price at introduction $219 Architecture / Microarchitecture Microarchitecture Zen Processor core Summit Ridge Core stepping B1 Manufacturing process 0.014 micron FinFET process 4.8 billion transistors Data width 64 bit The number of CPU cores 6 The number of threads 12 Floating Point Unit Integrated Level 1 cache size 6 x 64 KB 4-way set associative instruction caches 6 x 32 KB 8-way set associative data caches Level 2 cache size 6 x 512 KB inclusive 8-way set associative unified caches Level 3 cache size 2 x 8 MB exclusive 16-way set associative shared caches Multiprocessing Uniprocessor Features MMX instructions Extensions to MMX SSE / Streaming SIMD Extensions SSE2 / Streaming SIMD Extensions 2 SSE3 / Streaming SIMD Extensions 3 SSSE3 / Supplemental Streaming SIMD Extensions 3 SSE4 / SSE4.1 + SSE4.2 / Streaming SIMD Extensions 4 SSE4a AES / Advanced Encryption Standard instructions AVX / Advanced Vector Extensions AVX2 / Advanced Vector Extensions 2.0 BMI / BMI1 + BMI2 / Bit Manipulation instructions SHA / Secure Hash Algorithm extensions F16C / 16-bit Floating-Point conversion instructions -

X86 Intrinsics Cheat Sheet Jan Finis [email protected]
x86 Intrinsics Cheat Sheet Jan Finis [email protected] Bit Operations Conversions Boolean Logic Bit Shifting & Rotation Packed Conversions Convert all elements in a packed SSE register Reinterpet Casts Rounding Arithmetic Logic Shift Convert Float See also: Conversion to int Rotate Left/ Pack With S/D/I32 performs rounding implicitly Bool XOR Bool AND Bool NOT AND Bool OR Right Sign Extend Zero Extend 128bit Cast Shift Right Left/Right ≤64 16bit ↔ 32bit Saturation Conversion 128 SSE SSE SSE SSE Round up SSE2 xor SSE2 and SSE2 andnot SSE2 or SSE2 sra[i] SSE2 sl/rl[i] x86 _[l]rot[w]l/r CVT16 cvtX_Y SSE4.1 cvtX_Y SSE4.1 cvtX_Y SSE2 castX_Y si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd epi16-64 epi16-64 (u16-64) ph ↔ ps SSE2 pack[u]s epi8-32 epu8-32 → epi8-32 SSE2 cvt[t]X_Y si128,ps/d (ceiling) mi xor_si128(mi a,mi b) mi and_si128(mi a,mi b) mi andnot_si128(mi a,mi b) mi or_si128(mi a,mi b) NOTE: Shifts elements right NOTE: Shifts elements left/ NOTE: Rotates bits in a left/ NOTE: Converts between 4x epi16,epi32 NOTE: Sign extends each NOTE: Zero extends each epi32,ps/d NOTE: Reinterpret casts !a & b while shifting in sign bits. right while shifting in zeros. right by a number of bits 16 bit floats and 4x 32 bit element from X to Y. Y must element from X to Y. Y must from X to Y. No operation is SSE4.1 ceil NOTE: Packs ints from two NOTE: Converts packed generated. -
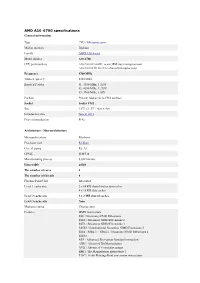
AMD A10-6700 Specifications General Information
AMD A10-6700 specifications General information Type CPU / Microprocessor Market segment Desktop Family AMD A10-Series Model number A10-6700 CPU part numbers AD6700OKA44HL is an OEM/tray microprocessor AD6700OKHLBOX is a boxed microprocessor Frequency 3700 MHz Turbo frequency 4300 MHz Boosted P states #1: 4300 MHz, 1.325V #2: 4200 MHz, 1.275V #3: 3900 MHz, 1.05V Package 904-pin lidded micro-PGA package Socket Socket FM2 Size 1.57" x 1.57" / 4cm x 4cm Introduction date June 4, 2013 Price at introduction $142 Architecture / Microarchitecture Microarchitecture Piledriver Processor core Richland Core stepping RL-A1 CPUID 610F31h Manufacturing process 0.032 micron Data width 64 bit The number of cores 4 The number of threads 4 Floating Point Unit Integrated Level 1 cache size 2 x 64 KB shared instruction caches 4 x 16 KB data caches Level 2 cache size 2 x 2 MB shared caches Level 3 cache size None Multiprocessing Uniprocessor Features MMX instructions SSE / Streaming SIMD Extensions SSE2 / Streaming SIMD Extensions 2 SSE3 / Streaming SIMD Extensions 3 SSSE3 / Supplemental Streaming SIMD Extensions 3 SSE4 / SSE4.1 + SSE4.2 / Streaming SIMD Extensions 4 SSE4a AES / Advanced Encryption Standard instructions ABM / Advanced Bit Manipulation AVX / Advanced Vector Extensions BMI1 / Bit Manipulation instructions 1 F16C / 16-bit Floating-Point conversion instructions FMA3 / 3-operand Fused Multiply-Add instructions FMA4 / 4-operand Fused Multiply-Add instructions TBM / Trailing Bit Manipulation instructions XOP / eXtended Operations instructions AMD64 -

Intel® Architecture Instruction Set Extensions and Future Features
Intel® Architecture Instruction Set Extensions and Future Features Programming Reference May 2021 319433-044 Intel technologies may require enabled hardware, software or service activation. No product or component can be absolutely secure. Your costs and results may vary. You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. All product plans and roadmaps are subject to change without notice. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. Code names are used by Intel to identify products, technologies, or services that are in development and not publicly available. These are not “commercial” names and not intended to function as trademarks. Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be ob- tained by calling 1-800-548-4725, or by visiting http://www.intel.com/design/literature.htm. Copyright © 2021, Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. -

Streaming SIMD Extension (SSE) SIMD Architectures
Streaming SIMD Extension (SSE) SIMD architectures • A data parallel architecture • Applying the same instruction to many data – Save control logic – A related architecture is the vector architecture – SIMD and vector architectures offer hhhigh performance for vector operations. Vector operations ⎛ x ⎞ ⎛ y ⎞ ⎛ x + y ⎞ • Vector addition Z = X + Y ⎜ 1 ⎟ ⎜ 1 ⎟ ⎜ 1 1 ⎟ ⎜ x2 ⎟ ⎜ y2 ⎟ ⎜ x2 + y2 ⎟ + = ⎜ ... ⎟ ⎜ ... ⎟ ⎜ ...... ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ for (i=0; i<n; i++) z[i] = x[i] + y[i]; ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎝ xn ⎠ ⎝ yn ⎠ ⎝ xn + yn ⎠ ⎛ x ⎞ ⎛ a* x ⎞ • Vector scaling Y = a * X ⎜ 1 ⎟ ⎜ 1 ⎟ ⎜ x2 ⎟ ⎜a* x2 ⎟ a* = ⎜ ... ⎟ ⎜ ...... ⎟ for(i=0; i<n; i++) y[i] = a*x[i]; ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎝ xn ⎠ ⎝a* xn ⎠ ⎛ x ⎞ ⎛ y ⎞ • Dot product ⎜ 1 ⎟ ⎜ 1 ⎟ ⎜ x2 ⎟ ⎜ y2 ⎟ • = x * y + x * y +......+ x * y ⎜ ... ⎟ ⎜ ... ⎟ 1 1 2 2 n n for(i=0; i<n; i++) r += x[i]*y[i]; ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎝ xn ⎠ ⎝ yn ⎠ SISD and SIMD vector operations • C = A + B – For (i=0;i<n; i++) c[][i] = a[][i] + b[i ] C A 909.0 808.0 707.0 606.0 505.0 404.0 303.0 202.0 101.0 SISD 10 9.0 8.0 7.0 6.0 5.0 4.0 3.0 2.0 + B 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 A 7.0 5.0 3.0 1.0 808.0 606.0 404.0 202.0 SIMD 8.0 6.0 4.0 2.0 + C 9.0 7.0 5.0 3.0 1.0 1.0 1.0 1.0 + B 1.0 1.0 1.0 1.0 x86 architecture SIMD support • Both current AMD and Intel’s x86 processors have ISA and microarchitecture support SIMD operations. -

Intel(R) Advanced Vector Extensions Programming Reference
Intel® Advanced Vector Extensions Programming Reference 319433-011 JUNE 2011 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANT- ED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL’S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. INTEL PRODUCTS ARE NOT INTENDED FOR USE IN MEDICAL, LIFE SAVING, OR LIFE SUSTAINING APPLICATIONS. Intel may make changes to specifications and product descriptions at any time, without notice. Developers must not rely on the absence or characteristics of any features or instructions marked “re- served” or “undefined.” Improper use of reserved or undefined features or instructions may cause unpre- dictable behavior or failure in developer's software code when running on an Intel processor. Intel reserves these features or instructions for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from their unauthorized use. The Intel® 64 architecture processors may contain design defects or errors known as errata. Current char- acterized errata are available on request. Hyper-Threading Technology requires a computer system with an Intel® processor supporting Hyper- Threading Technology and an HT Technology enabled chipset, BIOS and operating system. Performance will vary depending on the specific hardware and software you use. For more information, see http://www.in- tel.com/technology/hyperthread/index.htm; including details on which processors support HT Technology. -

The Microarchitecture of Intel and AMD Cpus
3. The microarchitecture of Intel, AMD and VIA CPUs An optimization guide for assembly programmers and compiler makers By Agner Fog. Copenhagen University College of Engineering. Copyright © 1996 - 2012. Last updated 2012-02-29. Contents 1 Introduction ....................................................................................................................... 4 1.1 About this manual ....................................................................................................... 4 1.2 Microprocessor versions covered by this manual........................................................ 6 2 Out-of-order execution (All processors except P1, PMMX)................................................ 8 2.1 Instructions are split into µops..................................................................................... 8 2.2 Register renaming ...................................................................................................... 9 3 Branch prediction (all processors) ................................................................................... 11 3.1 Prediction methods for conditional jumps.................................................................. 11 3.2 Branch prediction in P1............................................................................................. 16 3.3 Branch prediction in PMMX, PPro, P2, and P3 ......................................................... 20 3.4 Branch prediction in P4 and P4E .............................................................................. 21 -

Sok: a Performance Evaluation of Cryptographic Instruction Sets on Modern Architectures Armando Faz-Hernández Julio López Ana Karina D
Session: Card-based Protocol, Implementation, and Authentication for IoT APKC’18, June 4, 2018, Incheon, Republic of Korea SoK: A Performance Evaluation of Cryptographic Instruction Sets on Modern Architectures Armando Faz-Hernández Julio López Ana Karina D. S. de Oliveira Institute of Computing Institute of Computing Federal University of Mato Grosso Do University of Campinas University of Campinas Sul (FACOM-UFMS) Campinas, São Paulo, Brazil Campinas, São Paulo, Brazil Campo Grande MS, Brazil [email protected] [email protected] [email protected] ABSTRACT 1 INTRODUCTION The latest processors have included extensions to the instruction The omnipresence of cryptographic services has influenced modern set architecture tailored to speed up the execution of cryptographic processor’s designs. One proof of that is the support given to the algorithms. Like the AES New Instructions (AES-NI) that target the Advanced Encryption Standard (AES) [29] employing extensions to AES encryption algorithm, the release of the SHA New Instructions the instruction set architecture known as the AES New Instructions (SHA-NI), designed to support the SHA-256 hash function, intro- (AES-NI) [15]. Other examples in the same vein are the CRC32 duces a new scenario for optimizing cryptographic software. In instructions, which aid on error-detection codes, and the carry- this work, we present a performance evaluation of several crypto- less multiplier (CLMUL), which is used to accelerate the AES-GCM graphic algorithms, hash-based signatures and data encryption, on authenticated encryption algorithm [16]. All of these extensions platforms that support AES-NI and/or SHA-NI. In particular, we re- enhance the performance of cryptographic implementations. -

Lecture 26: “Parallel Programming”
18-600 Foundations of Computer Systems Lecture 26: “Parallel Programming” John P. Shen & Zhiyi Yu December 5, 2016 Required Reading Assignment: • Chapter 12 of CS:APP (3rd edition) by Randy Bryant & Dave O’Hallaron. Recommended Reference: “Parallel Computer Organization and Design,” by Michel Dubois, Murali Annavaram, Per Stenstrom, Chapters 5 and 7, 2012. 12/05/2016 (©J.P. Shen & Zhiyi Yu) 18-600 Lecture #26 1 18-600 Foundations of Computer Systems Lecture 26: “Parallel Programming” A. Parallel Programs for Parallel Architectures B. Parallel Programming Models C. Shared Memory Model D. Message Passing Model E. Thread Level Parallelism Examples 12/05/2016 (©J.P. Shen & Zhiyi Yu) 18-600 Lecture #26 2 Parallel Architectures: MCP & MCC MULTIPROCESSING CLUSTER COMPUTING Shared Memory Multicore Shared File System & LAN Processors (MCP) or Chip Connected Multi-Computer Multiprocessors (CMP) Clusters (MCC) 12/05/2016 (©J.P. Shen & Zhiyi Yu) 18-600 Lecture #26 3 [Jim Smith, Mikko Lipasti, Mark Hill, et al. , University of Wisconsin, ECE/CS 757, 2007-2013] A. Parallel Programs for Parallel Architectures . Why is Parallel Programming so hard? • Conscious mind is inherently sequential • (sub-conscious mind is extremely parallel) . Identifying parallelism in the problem . Expressing parallelism to the parallel hardware . Effectively utilizing parallel hardware (MCP or MCC) • MCP: OpenMP (Shared Memory) • MCC: Open MPI (Message Passing) . Debugging parallel algorithms 12/05/2016 (©J.P. Shen & Zhiyi Yu) 18-600 Lecture #26 4 [Jim Smith, Mikko Lipasti, Mark Hill, et al. , University of Wisconsin, ECE/CS 757, 2007-2013] Finding Parallelism 1. Functional parallelism • Car: {engine, brakes, entertain, nav, …} • Game: {physics, logic, UI, render, …} • Signal processing: {transform, filter, scaling, …} 2. -

Intel Integrated Performance Primitives in Intel® SGX Applications
White Paper Intel® Software Guard Extensions (Intel® SGX) Intel Integrated Performance Primitives in Intel® SGX Applications Introduction The Intel® Software Guard Extensions (Intel® SGX) SDK incorporates the Intel® Integrated Performance Primitives (Intel® IPP) Cryptography library. This article provides basic information on this Intel IPP Cryptography library and how to get set up to use it with Windows* Visual Studio* and the Linux* OS. In the Intel SGX SDK, the sgx_tcrypto library is linked to Intel’s IPP Cryptography library. For Windows, the header files are also included in the SDK, which allows direct access to the Intel IPP Cryptography library API. (For Linux, the header files are downloaded and installed manually.) Figure 1 shows the relationship of the Intel IPP Cryptography library to the sgx_tcrypto library. Figure 1. Intel IPP Cryptography library used in Intel SGX enclave Notes: The Intel IPP Cryptography library included in the Intel SGX SDK supports 2 optimization levels only to reduce enclave size and minimize EPC consumption: o Intel® Streaming SIMD Extensions 4.1 (Intel SSE4.1)/Intel® Streaming SIMD Extensions 4.2 (Intel SSE4.2)/Intel® Advanced Encryption Standard–New Instructions (Intel AES-NI) o Intel® Advanced Vector Extensions 2 (Intel AVX2) All processors that support Intel SGX also support Intel SSE4.1/Intel SSE4.2/Intel AES-NI, which support constant timing. Some processors that support Intel SGX also support Intel 1 White Paper Intel® Software Guard Extensions (Intel® SGX) AVX2. If Intel AVX 2 is not supported by a processor, the Intel IPP Cryptography library defaults to the Intel SSE4.1/Intel SSE4.2/Intel AES-NI implementation. -

Intel MMX, SSE, SSE2, SSE3/SSSE3/SSE4 Architectures
10/11/2008 Intel MMX, SSE, SSE2, SSE3/SSSE3/SSE4 Architectures Baha Guclu Dundar SALUC Lab Computer Science and Engineering Department University of Connecticut Slides 1-33 are modified from Computer Organization and Assembly Languages Course By Yung-Yu Chuang Overview • SIMD • MMX architectures • MMX instructions • examples • SSE/SSE2/SSE3 • SIMD instructions are probably the best place to use assembly since compilers usually do not do a good job on using these instructions 2 1 10/11/2008 Performance boost • Increasing clock rate is not fast enough for boosting performance • Architecture improvements (such as pipeline/cache/SIMD) are more significant • Intel analyzed multimedia applications and found they share the following characteristics: – Small native data types (8-bit pixel, 16-bit audio) – Recurring operations – Inherent parallelism 3 SIMD • SIMD (single instruction multiple data) architecture performs the same operation on multiple data elements in parallel • PADDW MM0, MM1 4 2 10/11/2008 SISD/SIMD 5 IA-32 SIMD development • MMX (Multimedia Extension) was introduced in 1996 (Pentium with MMX and Pentium II). • SSE (Streaming SIMD Extension) was introduced in 1999 with Pentium III. • SSE2 was introduced with Pentium 4 in 2001. • SSE3 was introduced in 2004 with Pentium 4 supporting hyper-threading technology. SSE3 adds 13 more instructions. 6 3 10/11/2008 MMX • After analyzing a lot of existing applications such as graphics, MPEG, music, speech recognition, game, image processing, they found that many multimedia algorithms execute the same instructions on many pieces of data in a large data set. • Typical elements are small, 8 bits for pixels, 16 bits for audio, 32 bits for graphics and general computing.