Flash Was Only the Begining Book | Pure Storage
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

New Directors of the A.P. Moller Holding Board
Copenhagen March 12 2020 New Directors of the A.P. Moller Holding Board Diane Greene and Claus V. Hemmingsen are expected to be elected as new members of the A.P. Moller Holding Board of Directors at the annual general meeting April 20, 2020. Diane Greene is an American national and holds an M.S. in Computer Science from UC, Berkeley, an M.S. in Naval Architecture from MIT and a B.S. in Mechanical Engineering. Diane is a Director of SAP and Stripe, and a lifetime member of the MIT Corporation, as well as co- Chair of UC Berkeley School of Engineering Advisory Board. She is also an investor and advisor to tech start ups. Diane has served as Director of Google/Alphabet from 2012 to 2019, Intuit from 2006 to 2017, and VMware from 1998 to 2008. Diane was in 2015 employed by Google/Alphabet as CEO of Google Cloud. Prior to this, Diane co- founded and was CEO of three companies: VXtreme, which was sold to Microsoft in 1995, VMware, which she ran for 11 years and took public to a USD19bn valuation in 2007, and Bebop, sold to Google in 2015. Before that, Diane worked as a software engineer and as a Naval Architect. Diane was the U.S. national sailing champion in 1976 and remains an avid sailor. Claus V. Hemmingsen has since 1981 held various positions in the A.P. Moller Group, including Deputy CEO of A.P. Moller – Maersk, CEO of the Maersk Energy division, CEO of Maersk Drilling, SVP of the Maersk Shared Service Centres, CEO of APM Terminals, as well as various management positions in Singapore and Hong Kong. -
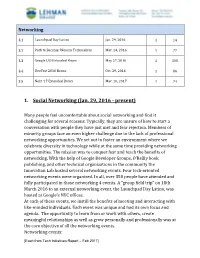
Networking Events
Networking 3.1 Launchpad Day Latino Jan. 29, 2016 1 14 3.2 Path to Success: Women Techmakers Mar. 24, 2016 1 77 3.3 Google I/O Extended Bronx May 27, 2016 1 100 3.4 DevFest 2016 Bronx Oct. 29, 2016 1 86 3.5 Next ‘17 Extended Bronx Mar. 10, 2017 1 74 1. Social Networking (Jan. 29, 2016 - present) Many people feel uncomfortable about social networking and find it challenging for several reasons. Typically, they are unsure of how to start a conversation with people they have just met and fear rejection. Members of minority groups face an even higher challenge due to the lack of professional networking opportunities. We set out to foster an environment where we celebrate diversity in technology while at the same time providing networking opportunities. The mission was to conquer fear and teach the benefits of networking. With the help of Google Developer Groups, O’Reilly book publishing, and other technical organizations in the community the Innovation Lab hosted several networking events. Four tech-oriented networking events were organized. In all, over 350 people have attended and fully participated in those networking 4 events. A “group field trip” on 18th March 2016 to an external networking event, the Launchpad Day Latino, was hosted at Google's NYC offices. At each of these events, we instill the benefits of meeting and interacting with like-minded individuals. Each event was unique and had its own focus and agenda. The opportunity to learn from or work with others, create meaningful relationships as well as grow personally and professionally was at the core objective of all the networking events. -

The Effectiveness of CEO Leadership Styles in the Technology Industry
The Effectiveness of CEO Leadership Styles in the Technology Industry Sean Dougherty, Andrew Drake Advisors: Dr. Jonathan Scott and Professor Katherine Nelson Temple University Explanation of research The purpose of this research is to determine the impact of leadership style on financial success. A great deal of research has been done on the factors that affect the financial success of a company, but leadership is one factor that tends to be overlooked. That is due to the nature of leadership; like other aspects of human resources management such as company culture, leadership is not easily quantifiable. In order to study leadership’s effect on company success, we needed to make leadership less abstract and more concrete. We needed a means of distinguishing the way one person leads in comparison to another person, and the solution was presented to us upon reading Primal Leadership. Authors Daniel Goleman, Richard Boyatzis, and Annie McKee make the detailed claim that the way a person leads can always be categorized into at least one of six distinct emotional leadership styles. We seek to build on the research of Goleman, Boyatzis, and McKee by analyzing the effectiveness of each of these styles in terms of driving financial success. To measure financial success, we looked at the behavior of stock price in the time following an initial public offering. For our data set, we chose to study 60 companies in the technology industry that have gone public since the year 2000. With each company, we researched the CEO who led the company during the IPO and assigned him or her one to two leadership styles that he or she exhibits. -

Amendment No. 1 to Form 10-K
Alphabet Inc. Annual Report 2016 Form 10-K (NASDAQ:GOOG) Published: March 29th, 2016 PDF generated by stocklight.com UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 FORM 10-K/A (Amendment No. 1) (Mark One) x ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the fiscal year ended December 31, 2015 OR ¨ TRANSITION REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the transition period from ______ to ______. State or Other Jurisdiction Exact Name of Registrant as specified in its Charter, Address of Principal Commission IRS Employer of Incorporation Executive Offices, Zip Code and Telephone Number (Including Area Code ) File Number Identification No. Delaware Alphabet Inc. 001-37580 61-1767919 1600 Amphitheatre Parkway Mountain View, CA 94043 (650) 253-0000 Delaware Google Inc. 001-36380 77-0493581 1600 Amphitheatre Parkway Mountain View, CA 94043 (650) 253-0000 Securities registered pursuant to Section 12(b) of the Act: Title of each class Name of each exchange on which registered Alphabet Inc.: Class A Common Stock Nasdaq Stock Market LLC $0.001 par value (Nasdaq Global Select Market) Class C Capital Stock Nasdaq Stock Market LLC $0.001 par value (Nasdaq Global Select Market) Google Inc.: None Securities registered pursuant to Section 12(g) of the Act: Title of each class Alphabet Inc.: None Google Inc.: None Indicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act. Alphabet Inc. Alphabet Inc. -
August 31, 2008
55¾^ Campaign draws Hollywood stars in women Stand Up to Cancer Inside today's Newspaper August 31,2008 75 cents WINNERS OF STATE AND NATIONAL AWARDS OF EXCELLENCE www.hometownlife.com men face trial in drug shootout BY DARRELL CLEM OBSERVER STAFF WRITER Wayne-Westland Education Association Nancy Strachan talks to teachers about A court hearing that brought contract talks during a rally Thursday. gripping testimony from a drug informant caught up in a gun- Kyle Olson of the Education Action Group and fight ended Thursday with four Nancy Strachan of the Wayne-Westland Education defendants facing trial for an Association express their views about negotiations alleged cocaine deal that left Boldizar Sanders in the Wayne-Westland Community Schools on Page a fifth suspect dead outside a A2. Westland shopping center. The informant, whose iden BY SUE MASON tity police didn't want pub STAFF WRITER • lished, gave harrpwing details of how he was nearly shot when A state mediator has become involved in two of the suspects — one in contract talks between Wayne-Westland the back seat of his car and one school officials and it? teachers union. standing outside his window The Wayne-Westland Education — drew guns as bullets started Reed Pringle Association requested the help of the medi flying during an Aug. 12 drug ator through the Michigan Employment sting that turned sour outside the informant described as a Relations Commission Wednesday in the Bob's of Canton-Westland long pistol that "looked like a hopes of avoiding a strike by the district's market. machine gun." The informant 900 teachers on Tuesday, the opening day "I heard bullets and a lot of said Thomas produced another of school. -

Minnesota WSCA-NASPO Master Agreement Request for Proposal | Pure Storage
! Pure Storage, Inc. Response to the State of Minnesota REQUEST FOR PROPOSAL ! ! ! MINNESOTA WSCA-NASPO Master Agreement for: Computer Equipment (Desktops, Laptops, Tablets, Servers, Storage and Ruggedized Devices including Related Peripherals & Services) ! The State of Minnesota REQUEST FOR PROPOSAL MINNESOTA WSCA-NASPO Master Agreement for: Computer Equipment (Desktops, Laptops, Tablets, Servers, Storage and Ruggedized Devices including Related Peripherals & Services) 1 | 2013_0916 Materials Management Division 112 Administration Building 50 Sherburne Avenue St. Paul, MN 55155 Voice: 651.296.2600 Fax: 651.297.3996 STATE OF MINNESOTA REQUEST FOR PROPOSAL (RFP) COMPUTER EQUIPMENT: (DESKTOPS, LAPTOPS, TABLETS, SERVERS, STORAGE, RUGGEDIZED DEVICES INCLUDING RELATED PERIPHERALS & SERVICES) DUE DATE: November 18, 2013 TIME: 3:00 P.M., CENTRAL TIME 2 | 2013_0916 TABLE OF CONTENTS SECTION 1: SCOPE OF WORK ........................................................................................................................................................... 4! A. INTRODUCTION .............................................................................................................................................................................. 4! B. OBJECTIVE ....................................................................................................................................................................................... 5! C. WSCA-NASPO BACKGROUND INFORMATION ....................................................................................................................... -

Braids and Juggling Patterns Matthew Am Cauley Harvey Mudd College
Claremont Colleges Scholarship @ Claremont HMC Senior Theses HMC Student Scholarship 2003 Braids and Juggling Patterns Matthew aM cauley Harvey Mudd College Recommended Citation Macauley, Matthew, "Braids and Juggling Patterns" (2003). HMC Senior Theses. 151. https://scholarship.claremont.edu/hmc_theses/151 This Open Access Senior Thesis is brought to you for free and open access by the HMC Student Scholarship at Scholarship @ Claremont. It has been accepted for inclusion in HMC Senior Theses by an authorized administrator of Scholarship @ Claremont. For more information, please contact [email protected]. Braids and Juggling Patterns by Matthew Macauley Michael Orrison, Advisor Advisor: Second Reader: (Jim Hoste) May 2003 Department of Mathematics Abstract Braids and Juggling Patterns by Matthew Macauley May 2003 There are several ways to describe juggling patterns mathematically using com- binatorics and algebra. In my thesis I use these ideas to build a new system using braid groups. A new kind of graph arises that helps describe all braids that can be juggled. Table of Contents List of Figures iii Chapter 1: Introduction 1 Chapter 2: Siteswap Notation 4 Chapter 3: Symmetric Groups 8 3.1 Siteswap Permutations . 8 3.2 Interesting Questions . 9 Chapter 4: Stack Notation 10 Chapter 5: Profile Braids 13 5.1 Polya Theory . 14 5.2 Interesting Questions . 17 Chapter 6: Braids and Juggling 19 6.1 The Braid Group . 19 6.2 Braids of Juggling Patterns . 22 6.3 Counting Jugglable Braids . 24 6.4 Determining Unbraids . 27 6.4.1 Setting the crossing numbers to zero. 32 6.4.2 The complete system of equations . -

Alphabet's Future Growth
ALPHABET’S FUTURE GROWTH SCOTTISH MORTGAGE INVESTMENT TRUST Tom Slater, Investment Manager. Fourth Quarter 2018 – Alphabet’s Future Growth Baillie Gifford IMPORTANT INFORMATION AND RISK FACTORS The views expressed in this article are those of Tom Market values for securities which have become difficult Slater and should not be considered as advice or to trade may not be readily available and there can be no a recommendation to buy, sell or hold a particular assurance that any value assigned to such securities will investment. They reflect personal opinion and should not accurately reflect the price the trust might receive upon be taken as statements of fact nor should any reliance be their sale. The trust can make use of derivatives which may placed on them when making investment decisions. impact on its performance. Baillie Gifford & Co and Baillie Gifford & Co Limited This document contains information on investments which are authorised and regulated by the Financial Conduct does not constitute independent research. Accordingly, it Authority (FCA). The investment trusts managed by Baillie is not subject to the protections afforded to independent Gifford & Co Limited are listed UK companies. Scottish research and Baillie Gifford and its staff may have dealt in Mortgage Investment Trust PLC (Scottish Mortgage) is the investments concerned. listed on the London Stock Exchange and is not authorised or regulated by the FCA. The value of its shares, and any All information is sourced from Baillie Gifford & Co and income from them, can fall as well as rise and investors is current unless otherwise stated. may not get back the amount invested. -

Addicted to Ball and Club Juggling
Addicted to Ball and Club Juggling -A guide to improve your juggling- Addicted to Ball and Club Juggling Book 1: Two hands 2 Preface................................................................................................... Fout! Bladwijzer niet gedefinieerd. Structure of the book ............................................................................. Fout! Bladwijzer niet gedefinieerd. Part 1: A juggling course...................................................Fout! Bladwijzer niet gedefinieerd. Topic 1: General stuff ........................................................Fout! Bladwijzer niet gedefinieerd. General working advise.......................................................................... Fout! Bladwijzer niet gedefinieerd. Practical training advise ......................................................................... Fout! Bladwijzer niet gedefinieerd. Advise on buying and using juggling props........................................... Fout! Bladwijzer niet gedefinieerd. Conventions ........................................................................................... Fout! Bladwijzer niet gedefinieerd. Games .................................................................................................... Fout! Bladwijzer niet gedefinieerd. Topic 2: Enlarge your skill, improve your technique .....Fout! Bladwijzer niet gedefinieerd. Training advise ..................................................................................... Fout! Bladwijzer niet gedefinieerd. -

THEY CAME to PLAY 100 Years of the Toy Industry Association
THEY CAME TO PLAY 100 Years of the Toy Industry Association By Christopher Byrne The Hotel McAlpin in New York was the site of the Association’s inaugural meeting in 1916. Contents 4 6 Foreword Introduction 8 100 Years of the Toy Industry Association Graphic Timeline 30 12 Chapter 2: Policy and Politics Chapter 1: Beginnings • Shirley Temple: The Bright Spot 32 and Early Days in the Great Depression • World War II and the Korean War: 33 • A Vision Realized, An Association Formed 12 Preserving an Industry • Early Years, Early Efforts 20 • Mr. Potato Head: Unlikely Cold War Hero 38 • Playing Safe: The Evolution of Safety Standards 39 • Creepy Crawlers: Rethinking a Classic 46 • TV Transforms the Industry 47 • Tickle Me Elmo and His TV Moment 51 2 64 Chapter 4: A Century of Growth and Evolution • A Century of Expansion: From TMUSA to TIA 65 • Supporting the Business of Toys 68 • Educating an Industry 73 • Creating Future Toy Designers 74 82 • Rewarding the Industry 75 Conclusion: • Worldwide Reach and Global Impact 76 Looking to the Future • Government Affairs 78 • Philanthropy 80 52 Chapter 3: Promoting Play– 84 A Consistent Message Appendix I: For 100 Years Toy Industry Hall 12 2 of Fame Inductees Appendix II: Toy Industry Association Chairmen 3 Foreword In the spring of 1916, a small group of toy manufacturers gathered in the heart of New York City to discuss the need to form an association. Their vision was to establish an organization that would serve to promote American-made products, encourage year-round sales of toys, and protect the general interests of the burgeoning U.S. -

Siteswap Ben's Guide to Juggling Patterns
Siteswap Ben’s Benjamin Beever ([email protected]) AD2000 Writings on juggling, for: 1) Jugglers 2) Mathematicians 3) Other curious people ABOUT THE BOOK The scientific understanding of ‘air-juggling’ has improved dramatically over the last 2 decades. This book aims to bring the reader right up to the forefront of current knowledge (or pretty close anyway). There are 3 kinds of people who might be reading this (see cover). As far as possible, I wanted to cater for everyone in the same book. Maybe this would help jugglers to appreciate maths, mathematicians to get into juggling, or even non-juggling, non-mathematicians to develop a favourable perception of the juggling game. In order to fulfil this ambition, I have indicated which parts of the text are aimed at a specific kind of reader. Different fonts have been used to indicate the main intended audience. Everyone (with many exceptions) should be able to understand most of the writings for the curious. However, non-jugglers may not be able to envisage the patterns discussed in the jugglers text, and non-mathematicians may find some of the concepts in the technical sections hard to get their grey matter around. I must point out however, that juggling is a fairly complicated business. It can be very hard to understand what’s going on in a juggling pattern when it’s being juggled in front of you, and it’s not always easy to understand on paper. This book introduces ‘Generalised siteswap’ (GS) notation, and shows how most air-juggling patterns can be formalised within the GS framework. -

DCIG 2018-19 All-Flash Array Buyer's Guide
The Insider’s Guide to Evaluating All-Flash Arrays 2018-19 ALL-FLASH ARRAY BUYER’S GUIDE By Jerome Wendt & Ken Clipperton EMPOWERING THE IT INDUSTRY WITH ACTIONABLE ANALYSIS · WWW.DCIG.COM 2018-19 ALL-FLASH ARRAY BUYER’S GUIDE The Insider’s Guide to Evaluating All-Flash Arrays Table of Contents 1 Introduction 22 All-Flash Array Products 23 Dell EMC Unity 550F All-Flash 3 Executive Summary 24 Dell EMC Unity 650F All-Flash 25 Dell EMC VMAX 250FX AFA 5 How to Use this Buyer’s Guide 26 Dell EMC VMAX 450FX AFA 27 Hitachi Vantara VSP F400 5 Disclosures 28 Hitachi Vantara VSP F600 6 Inclusion Criteria 29 Hitachi Vantara VSP F800 30 Hitachi Vantara VSP F1500 6 The Eight-Step Process Used 31 HPE 3PAR StoreServ 9450 to Rank the Products 32 HPE 3PAR StoreServ 20450 33 HPE Nimble Storage AF5000 All Flash Array 7 DCIG Thoughts and Comments on … 34 HPE Nimble Storage AF7000 All Flash Array 7 Compression and Deduplication 35 HPE Nimble Storage AF9000 All Flash Array 7 Breadth of VMware vSphere API Support 36 Huawei OceanStor 5300F V5 8 Non-volatile Memory Express Interface 37 Huawei OceanStor 5500F V5 9 Scale-up versus Scale-out AFA Architectures 38 Huawei OceanStor 5600F V5 10 Capacity, Density, and Power Consumption 39 Huawei OceanStor 5800F V5 10 Predictive Analytics 40 Huawei OceanStor 6800F V5 12 Non-disruptive Upgrades (NDU) 41 Huawei OceanStor Dorado5000 V3 (NVMe) 12 Performance and Pricing 42 Huawei OceanStor Dorado5000 V3 (SAS) 13 Best Practices 43 Huawei OceanStor Dorado6000 V3 13 DCIG Observations 44 NetApp AFF A200 13 Recommended Ranking