Mule in Action
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Space Details
Space Details Key: MULE2USER Name: Mule 2.x User Guide Description: Mule Users Guide for the 2.x release line Creator (Creation Date): ross (Jan 30, 2008) Last Modifier (Mod. Date): tcarlson (Apr 15, 2008) Available Pages • Configuring a Mule Instance • Escape URI Credentials • Home • 3.x Features • Using JSON • Configuring Encoding • Hot Deploying Mule Applications • Deploying Mule as a Service to Tomcat • Starting Mule with the Configuration • About Mule Configuration • About Configuration Builders • Configuring Properties • Mule High Availability • Storing Objects in the Registry • About Transports • Available Transports • BPM Transport • CXF Transport • Building a CXF Web Service • CXF Transport Configuration Reference • Enabling WS-Addressing • Enabling WS-Security • Supported Web Service Standards • Using a Web Service Client as an Outbound Endpoint • Using a Web Service Client Directly • Using HTTP GET Requests • Using MTOM • EJB Transport • Email Transport • File Transport • FTP Transport • HTTPS Transport • HTTP Transport • IMAPS Transport Document generated by Confluence on Feb 07, 2010 23:59 Page 1 • IMAP Transport • JDBC Transport • JDBC Transport Configuration Reference • JDBC Transport Examples • JDBC Transport Performance Benchmark Results • Jetty Transport • Jetty SSL Transport • JMS Transport • Tibco EMS Integration • JBoss Jms Integration • Fiorano Integration • OpenJms Integration • SwiftMQ Integration • Sun JMS Grid Integration • SonicMQ Integration • SeeBeyond JMS Server Integration • Open MQ Integration • ActiveMQ -

Opening Plenary State of the Feather
Opening Plenary Lars Eilebrecht V.P., Conference Planning at ASF and Lead for ApacheCon Europe 2009 State of the Feather Jim Jagielski Chairman, The Apache Software Foundation Welcome to Amsterdam Presented by The Apache Software Foundation Produced by Stone Circle Productions, Inc. Conference Program • Detailed conference program guide available as a PDF from the ApacheCon Web site – www.eu.apachecon.com • Printed Conference-at-a- Glance program available at registration desk Presentations • 4 Tracks every day starting at 9:00 • Presentation slides provided by speakers will be made available on the ApacheCon Web site during the conference Wednesday Special Events • 9:15-9:30: Jim Jagielski “State of the Feather” • 9:30-10:30: Raghu Ramakrishnan “Data Management in the Cloud” • 10:30-11:30: Arjé Cahn, Ajay Anand, Steve Loughran, and Mark Brewer “Panel: The Business of Open Source”, moderated by Sally Khudairi • 13:00-14:00: Lars Eilebrecht “Behind the Scenes of The ASF” Wednesday Special Events • 18:30-20:00: Welcome Reception and ASF 10th Anniversary Party – Celebrating a Decade of Open Source Leadership • 19:30: OpenPGP Key Signing – [email protected] – moderated by Jean-Frederic Clere Thursday Special Events • 13:00-14:00: Jim Jagielski “Sponsoring the ASF at the Corporate and Individual Level” • 17:30-18:30: James Governor “Open Sourcing The Analyst Business – Turning Prop. Knowledge Inside Out” • 18:30-20:00: “Lightning Talks”, mod. by Danese Cooper and Rich Bowen Friday Special Events • 11:30-13:00: Lars Eilebrecht, Dirk- Willem van Gulik, Jim Jagielski, Sally Khudairi, Cliff Skolnick, “Apache Pioneer's Panel – 10 years of the ASF”, mod. -

Architecture of Mule and Servicemix 42 3 ■ Setting up the Mule and Servicemix Environments 72 4 ■ the Foundation of an Integration Solution 111
Open Source ESBs in Action Open Source ESBs in Action EXAMPLE IMPLEMENTATIONS IN MULE AND SERVICEMIX TIJS RADEMAKERS JOS DIRKSEN MANNING Greenwich (74° w. long.) For online information and ordering of this and other Manning books, please visit www.manning.com. The publisher offers discounts on this book when ordered in quantity. For more information, please contact: Special Sales Department Manning Publications Co. Sound View Court 3B Fax: (609) 877-8256 Greenwich, CT 06830 Email: [email protected] ©2009 by Manning Publications Co. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the publisher. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in the book, and Manning Publications was aware of a trademark claim, the designations have been printed in initial caps or all caps. Recognizing the importance of preserving what has been written, it is Manning’s policy to have the books we publish printed on acid-free paper, and we exert our best efforts to that end. Recognizing also our responsibility to conserve the resources of our planet, Manning books are printed on paper that is at least 15% recycled and processed elemental chlorine-free Development Editor: Jeff Bleil Manning Publications Co. Copyeditors: Liz Welch, Tiffany Taylor Sound View Court 3B Typesetter: Denis -

Site Map - Apache HTTP Server 2.0
Site Map - Apache HTTP Server 2.0 Apache HTTP Server Version 2.0 Site Map ● Apache HTTP Server Version 2.0 Documentation ❍ Release Notes ■ Upgrading to 2.0 from 1.3 ■ New features with Apache 2.0 ❍ Using the Apache HTTP Server ■ Compiling and Installing Apache ■ Starting Apache ■ Stopping and Restarting the Server ■ Configuration Files ■ How Directory, Location and Files sections work ■ Server-Wide Configuration ■ Log Files ■ Mapping URLs to Filesystem Locations ■ Security Tips ■ Dynamic Shared Object (DSO) support ■ Content Negotiation ■ Custom error responses ■ Setting which addresses and ports Apache uses ■ Multi-Processing Modules (MPMs) ■ Environment Variables in Apache ■ Apache's Handler Use ■ Filters ■ suEXEC Support ■ Performance Hintes ■ URL Rewriting Guide ❍ Apache Virtual Host documentation ■ Name-based Virtual Hosts ■ IP-based Virtual Host Support ■ Dynamically configured mass virtual hosting ■ VirtualHost Examples ■ An In-Depth Discussion of Virtual Host Matching ■ File descriptor limitations ■ Issues Regarding DNS and Apache ❍ Apache Server Frequently Asked Questions http://httpd.apache.org/docs-2.0/sitemap.html (1 of 4) [5/03/2002 9:53:06 PM] Site Map - Apache HTTP Server 2.0 ■ Support ❍ Apache SSL/TLS Encryption ■ SSL/TLS Encryption: An Introduction ■ SSL/TLS Encryption: Compatibility ■ SSL/TLS Encryption: How-To ■ SSL/TLS Encryption: FAQ ■ SSL/TLS Encryption: Glossary ❍ Guides, Tutorials, and HowTos ■ Authentication ■ Apache Tutorial: Dynamic Content with CGI ■ Apache Tutorial: Introduction to Server Side Includes ■ Apache -

Hänninen, Arttu Enterprise Integration Patterns in Service Oriented Systems Master of Science Thesis
CORE Metadata, citation and similar papers at core.ac.uk Provided by Trepo - Institutional Repository of Tampere University Hänninen, Arttu Enterprise Integration Patterns in Service Oriented Systems Master of Science Thesis Examiner: Prof. Tommi Mikkonen Examiners and topic approved in the council meeting of Faculty of Information Technology on April 3rd, 2013. II TIIVISTELMÄ TAMPEREEN TEKNILLINEN YLIOPISTO Tietotekniikan koulutusohjelma Hänninen, Arttu: Enterprise Integration Patterns in Service Oriented Systems Diplomityö, 58 sivua Kesäkuu 2014 Pääaine: Ohjelmistotuotanto Tarkastajat: Prof. Tommi Mikkonen Avainsanat: Enterprise Integration Patterns, Palvelukeskeinen arkkitehtuuri (SOA), Viestipohjainen integraatio Palvelupohjaisen integraation toteuttaminen mihin tahansa tietojärjestelmään on haas- tavaa, sillä integraatioon liittyvät järjestelmät voivat muuttua jatkuvasti. Integraatiototeu- tusten tulee olla tarpeeksi joustavia, jotta ne pystyvät mukautumaan mahdollisiin muu- toksiin. Toteutukseen voidaan käyttää apuna eri sovelluskehyksiä, mutta ne eivät vält- tämättä takaa mitään standardoitua tapaa tehdä integraatio. Tätä varten on luotu joukko ohjeita (Enterprise Integration Patterns, EIP), jotka kuvaavat hyväksi havaittuja tapoja tehdä integraatioita. Tässä työssä keskitytään näiden mallien tutkimiseen ja siihen, miten niitä voidaan hyödyntää yritysjärjestelmissä. Jotta tutkimukseen saadaan konkreettinen vertailutulos, erään järjestelmän integraatioratkaisu tullaan päivittämään uuteen. Uusi ratkaisu hyödyntää sovelluskehystä, -
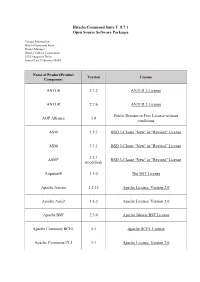
Hitachi Command Suite V.8.7.1
Hitachi Command Suite V. 8.7.1 Open Source Software Packages Contact Information: Hitachi Command Suite Project Manager Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component ANTLR 2.7.2 ANTLR 2 License ANTLR 2.7.6 ANTLR 2 License Public Domain or Free License without AOP Alliance 1.0 conditions ASM 1.5.3 BSD 3-Clause "New" or "Revised" License ASM 3.3.1 BSD 3-Clause "New" or "Revised" License 3.3.1 ASM* BSD 3-Clause "New" or "Revised" License (modified) AngularJS 1.3.0 The MIT License Apache Axiom 1.2.13 Apache License, Version 2.0 Apache Axis2 1.6.2 Apache License, Version 2.0 Apache BSF 2.3.0 Apache Jakarta BSF License Apache Commons BCEL 5.1 Apache BCEL License Apache Commons CLI 1.1 Apache License, Version 2.0 Name of Product/Product Version License Component Apache Commons Codec 1.11 Apache License, Version 2.0 Apache Commons Codec 1.3 Apache License, Version 2.0 Apache Commons Collections 2.1 Apache Jakarta Commons License Apache Commons Collections 3.2.2 Apache License, Version 2.0 Apache Commons Digester 1.5 Apache Jakarta Commons License Apache Commons Digester 1.8 Apache License, Version 2.0 Apache Commons XMLSchema 1.4.7 Apache License, Version 2.0 Apache FOP 1.0 Apache License, Version 2.0 Apache License, Version 2.0 ISC License PCRE LICENCE (PCRE 4.5 and earlier) The License by "Bell Communications 2.0.59 Apache HTTP Server* Research, Inc. -
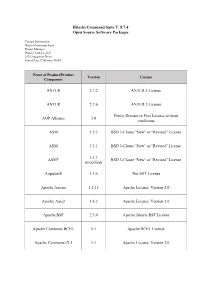
Hitachi Command Suite V. 8.7.4 Open Source Software Packages
Hitachi Command Suite V. 8.7.4 Open Source Software Packages Contact Information: Hitachi Command Suite Project Manager Hitachi Vantara, LLC 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component ANTLR 2.7.2 ANTLR 2 License ANTLR 2.7.6 ANTLR 2 License Public Domain or Free License without AOP Alliance 1.0 conditions ASM 1.5.3 BSD 3-Clause "New" or "Revised" License ASM 3.3.1 BSD 3-Clause "New" or "Revised" License 3.3.1 ASM* BSD 3-Clause "New" or "Revised" License (modified) AngularJS 1.3.0 The MIT License Apache Axiom 1.2.13 Apache License, Version 2.0 Apache Axis2 1.6.2 Apache License, Version 2.0 Apache BSF 2.3.0 Apache Jakarta BSF License Apache Commons BCEL 5.1 Apache BCEL License Apache Commons CLI 1.1 Apache License, Version 2.0 Name of Product/Product Version License Component Apache Commons Codec 1.11 Apache License, Version 2.0 Apache Commons Codec 1.3 Apache License, Version 2.0 Apache Commons Collections 2.1 Apache Jakarta Commons License Apache Commons Collections 3.2.2 Apache License, Version 2.0 Apache Commons Digester 1.5 Apache Jakarta Commons License Apache Commons Digester 1.8 Apache License, Version 2.0 Apache Commons XMLSchema 1.4.7 Apache License, Version 2.0 Apache FOP 1.0 Apache License, Version 2.0 Apache License, Version 2.0 ISC License PCRE LICENCE (PCRE 4.5 and earlier) The License by "Bell Communications 2.0.59 Apache HTTP Server* Research, Inc. -

Open Source Used in Call Analyzer 1.2
Open Source Used In call analyzer 1.2 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-145264460 Open Source Used In call analyzer 1.2 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-145264460 Contents 1.1 aiohttp 2.3.8 1.1.1 Available under license 1.2 aiohttp 1.3.1 1.2.1 Available under license 1.3 ANTLR 2.7.6 1.3.1 Available under license 1.4 asn1crypto 0.22.0 1.4.1 Available under license 1.5 asn1crypto 0.24.0 1.5.1 Available under license 1.6 bandit 1.4.0 1.6.1 Available under license 1.7 BCEL 5.1 1.7.1 Notifications 1.7.2 Available under license 1.8 BSF (Bean Scripting Framework) 2.4.0 1.8.1 Available under license 1.9 cffi 1.11.4 1.9.1 Available under license 1.10 CGLIB (Code Generation Library) 2.1.3 1.10.1 Available under license 1.11 confluent-kafka 0.10.2.1 1.11.1 Available under license 1.12 cryptography 2.2.2 1.12.1 Available under license 1.13 cryptography 2.2.2 Open Source Used In call analyzer 1.2 2 1.13.1 Available under -

HIERARCHY in MERITOCRACY – Community Building and Code Production in the Apache Software Foundation
HIERARCHY IN MERITOCRACY { Community Building and Code Production in The Apache Software Foundation Master's Thesis Oscar Casta~neda HIERARCHY IN MERITOCRACY { Community Building and Code Production in The Apache Software Foundation THESIS submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in MANAGEMENT OF TECHNOLOGY by Oscar Casta~neda born in Guatemala City, Guatemala Policy, Organization, Law and Gaming (POLG) Faculty Technology Policy and Management (TPM) Delft University of Technology (TU Delft) Delft, the Netherlands tbm.tudelft.nl c 2010 Oscar Casta~neda. HIERARCHY IN MERITOCRACY { Community Building and Code Production in The Apache Software Foundation Author: Oscar Casta~neda Student id: 1398946 Email: [email protected] Graduation Date: December 2010 Graduation Section: Policy, Organization, Law and Gaming (POLG) Abstract This research is about code production in top-level open source com- munities of The Apache Software Foundation (ASF). We extensively an- alyzed Subversion repository logs from 70 top-level Apache open source projects in the ASF from 2004 to 2009. Based on interactions in code production during one-year periods we constructed networks of file co- authorship that gave us access to the organization of Apache open source communities. This allowed us to measure graph level properties, like hier- archy and clustering, and their influence on the outputs of code production. Apache communities are groups of individuals that organize their code production efforts in order to develop enterprise-grade open source soft- ware. The ASF explains the success of its communities and the software they produce by claiming to have instituted a meritocracy that brings contributors together in a way that significantly influences code produc- tion, namely by building communities instead of only focusing on technical properties of the source code like modularity. -

Storagetek Tape Analytics Licensing Information User Manual, Release 2.1 E59803-02 Copyright © 2015, Oracle And/Or Its Affiliates
1[StorageTek] Tape Analytics Licensing Information User Manual Release 2.1 E59803-02 June 2015 StorageTek Tape Analytics Licensing Information User Manual, Release 2.1 E59803-02 Copyright © 2015, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -

Rester En Sécurité !
Full Circle LE MAGAZINE INDÉPENDANT DE LA COMMUNAUTÉ UBUNTU LINUX NUMÉRO 67 - Novembre 2012 Photo : Infidelic (Flickr.com) CRITIQUE LITTÉRAIRE : Think like a programmer RREESSTTEERR EENN SSÉÉCCUURRIITTÉÉ !! CRÉER UN ORDINATEUR À L'ÉPREUVE DES VOLEURS full circle magazine n° 67 1 sommaire ^ Full Circle Magazine n'est affilié en aucune manière à Canonical Ltd. Tutoriels Full Circle Opinions LE MAGAZINE INDÉPENDANT DE LA COMMUNAUTÉ UBUNTU LINUX Programmer en Python p.08 Rubriques Mon histoire p.44 LibreOffice - Partie 20 p.09 Command & Conquer p.06 Actus Ubuntu p.04 Qu'est-ce... p.47 DE RETOUR LE MOIS PROCHAIN Créer un ordinateur à l'épreuve Demandezaupetitnouveau p.35 Critique p.55 des voleurs p.12 Jeux Ubuntu p.XX Courriers p.60 Kdenlive - Partie 4 p.26 Labo Linux p.39 Q&R p.62 DE RETOUR LE MOIS PROCHAIN Inkscape - Partie 7 p.28 Femmes d'Ubuntu p.XX Fermeturedesfenêtres p.41 Développement Web p.31 Graphismes Dév. Web Les articles contenus dans ce magazine sont publiés sous la licence Creative Commons Attribution-Share Alike 3.0 Unported license. Cela signifie que vous pouvez adapter, copier, distribuer et transmettre les articles mais uniquement sous les conditions suivantes : vous devez citer le nom de l'auteur d'une certaine manière (au moins un nom, une adresse e-mail ou une URL) et le nom du magazine (« Full Circle Magazine ») ainsi que l'URL www.fullcirclemagazine.org (sans pour autant suggérer qu'ils approuvent votre utilisation de l'œuvre). Si vous modifiez, transformez ou adaptez cette création, vous devez distribuer la création qui en résulte sous la même licence ou une similaire. -
Framework De Gestión De Consumo De Servicios
UNIVERSIDAD DE VALLADOLID E.T.S.I. TELECOMUNICACIÓN TRABAJO FIN DE GRADO GRADO EN INGENIERÍA DE TECNOLOGÍAS ESPECÍFICAS DE TELECOMUNICACIÓN – MENCIÓN EN INGENIERÍA DE SISTEMAS DE TELECOMUNICACIÓN Framework de gestión de consumo de servicios Autora: Henar García Sánchez Tutora: Míriam Antón Rodríguez Valladolid, 16 de Noviembre de 2016 Henar García Sánchez Framework de gestión de consumo de servicios TÍTULO: Framework de gestión de consumo de servicios AUTORA: Henar García Sánchez TUTORA: Míriam Antón Rodríguez DEPARTAMENTO: Teoría de la Señal y Comunicaciones e Ingeniería Telemática TRIBUNAL PRESIDENTA: Míriam Antón Rodríguez VOCAL: Mario Martínez Zarzuela SECRETARIO: David González Ortega SUPLENTE: Francisco Javier Díaz Pernas SUPLENTE: Mª Ángeles Pérez Juárez FECHA: 16 de Noviembre de 2016 CALIFICACIÓN: 2 Henar García Sánchez Framework de gestión de consumo de servicios 3 Henar García Sánchez Framework de gestión de consumo de servicios RESUMEN En la sociedad actual, el uso de las tecnologías es algo que forma parte de nuestra vida cotidiana. Para usar la mayoría de las tecnologías actuales, estas tecnologías poseen aplicaciones para hacer más fácil su uso a los usuarios, y estas aplicaciones normalmente necesitan conectarse con otras. El objetivo de este TFG surge en este punto, en la comunicación de unas aplicaciones con otras. A través de un ESB (Enterprise Service Bus) estas comunicaciones se pueden realizar de forma simple, abstrayendo cada una de las partes de la aplicación. En estos ESB se pueden realizar muchas funciones, la aplicación desarrollada en este TFG va a comprobar que no se produzcan errores en esta comunicación a través del ESB y en caso de que se produzca se realizará una política de errores, previamente configurada.