HIERARCHY in MERITOCRACY – Community Building and Code Production in the Apache Software Foundation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Microsoft Powerpoint
FraSCAti ««Open SCA Platform »» Outline • From SOA to SCA • FraSCAti • SCOrWare • Conclusion 2 2 From SOA to SCA From SOA challenges… • IT architectures • Complexity • Managing 10 n lines of code • Monolithic • Breaking application «silos» • Seldom evolvable • Freeing systems from immutable dependencies Source: oasis-open.org 4 4 …to existing SOA, but… SOA leverages complexity and promotes flexibility • Loose coupling • Service composition and orchestration • Well defined and contractualized interfaces • Standard tools and technologies Source: oasis-open.org 5 5 …Still a partial solution Today's SOA need to be… • Deployable in different environments • Ensure security and reliability • Adaptable to changing business needs …and thus, SOA lack… • Structured architectures – What is behind the scene? • Reuse capabilities – Reuse the wheel when possible… • Flexibility support You want SCA! – …Or tune it if not! for your business 6 6 SCA in a Nutshell SCA (Service Component Architecture) • Aka a « Component Model for SOA » • Since 11/2005 Hosted by the Open SOA consortium • http://www.osoa.org Community connected to OASIS • http://www.oasis-opencsa.org Existing platform providers • Open Source (4) : Apache Tuscany, Newton, Fabric3, FraSCAti • Vendors (7) : IBM WebSphere FP for SOA, TIBCO ActiveMatrix, Covansys SCA Framework, Paremus, Rogue Wave HydraSCA, Oracle Fusion Middleware 7 7 SCA in a Nutshell 15 focused specifications (09/2008) + SDO to access data sources Assembly model specification (structured architectures ☺) • How to structure composite -

Space Details
Space Details Key: MULE2USER Name: Mule 2.x User Guide Description: Mule Users Guide for the 2.x release line Creator (Creation Date): ross (Jan 30, 2008) Last Modifier (Mod. Date): tcarlson (Apr 15, 2008) Available Pages • Configuring a Mule Instance • Escape URI Credentials • Home • 3.x Features • Using JSON • Configuring Encoding • Hot Deploying Mule Applications • Deploying Mule as a Service to Tomcat • Starting Mule with the Configuration • About Mule Configuration • About Configuration Builders • Configuring Properties • Mule High Availability • Storing Objects in the Registry • About Transports • Available Transports • BPM Transport • CXF Transport • Building a CXF Web Service • CXF Transport Configuration Reference • Enabling WS-Addressing • Enabling WS-Security • Supported Web Service Standards • Using a Web Service Client as an Outbound Endpoint • Using a Web Service Client Directly • Using HTTP GET Requests • Using MTOM • EJB Transport • Email Transport • File Transport • FTP Transport • HTTPS Transport • HTTP Transport • IMAPS Transport Document generated by Confluence on Feb 07, 2010 23:59 Page 1 • IMAP Transport • JDBC Transport • JDBC Transport Configuration Reference • JDBC Transport Examples • JDBC Transport Performance Benchmark Results • Jetty Transport • Jetty SSL Transport • JMS Transport • Tibco EMS Integration • JBoss Jms Integration • Fiorano Integration • OpenJms Integration • SwiftMQ Integration • Sun JMS Grid Integration • SonicMQ Integration • SeeBeyond JMS Server Integration • Open MQ Integration • ActiveMQ -

Opening Plenary State of the Feather
Opening Plenary Lars Eilebrecht V.P., Conference Planning at ASF and Lead for ApacheCon Europe 2009 State of the Feather Jim Jagielski Chairman, The Apache Software Foundation Welcome to Amsterdam Presented by The Apache Software Foundation Produced by Stone Circle Productions, Inc. Conference Program • Detailed conference program guide available as a PDF from the ApacheCon Web site – www.eu.apachecon.com • Printed Conference-at-a- Glance program available at registration desk Presentations • 4 Tracks every day starting at 9:00 • Presentation slides provided by speakers will be made available on the ApacheCon Web site during the conference Wednesday Special Events • 9:15-9:30: Jim Jagielski “State of the Feather” • 9:30-10:30: Raghu Ramakrishnan “Data Management in the Cloud” • 10:30-11:30: Arjé Cahn, Ajay Anand, Steve Loughran, and Mark Brewer “Panel: The Business of Open Source”, moderated by Sally Khudairi • 13:00-14:00: Lars Eilebrecht “Behind the Scenes of The ASF” Wednesday Special Events • 18:30-20:00: Welcome Reception and ASF 10th Anniversary Party – Celebrating a Decade of Open Source Leadership • 19:30: OpenPGP Key Signing – [email protected] – moderated by Jean-Frederic Clere Thursday Special Events • 13:00-14:00: Jim Jagielski “Sponsoring the ASF at the Corporate and Individual Level” • 17:30-18:30: James Governor “Open Sourcing The Analyst Business – Turning Prop. Knowledge Inside Out” • 18:30-20:00: “Lightning Talks”, mod. by Danese Cooper and Rich Bowen Friday Special Events • 11:30-13:00: Lars Eilebrecht, Dirk- Willem van Gulik, Jim Jagielski, Sally Khudairi, Cliff Skolnick, “Apache Pioneer's Panel – 10 years of the ASF”, mod. -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Apache Harmony Project Tim Ellison Geir Magnusson Jr
The Apache Harmony Project Tim Ellison Geir Magnusson Jr. Apache Harmony Project http://harmony.apache.org TS-7820 2007 JavaOneSM Conference | Session TS-7820 | Goal of This Talk In the next 45 minutes you will... Learn about the motivations, current status, and future plans of the Apache Harmony project 2007 JavaOneSM Conference | Session TS-7820 | 2 Agenda Project History Development Model Modularity VM Interface How Are We Doing? Relevance in the Age of OpenJDK Summary 2007 JavaOneSM Conference | Session TS-7820 | 3 Agenda Project History Development Model Modularity VM Interface How Are We Doing? Relevance in the Age of OpenJDK Summary 2007 JavaOneSM Conference | Session TS-7820 | 4 Apache Harmony In the Beginning May 2005—founded in the Apache Incubator Primary Goals 1. Compatible, independent implementation of Java™ Platform, Standard Edition (Java SE platform) under the Apache License 2. Community-developed, modular architecture allowing sharing and independent innovation 3. Protect IP rights of ecosystem 2007 JavaOneSM Conference | Session TS-7820 | 5 Apache Harmony Early history: 2005 Broad community discussion • Technical issues • Legal and IP issues • Project governance issues Goal: Consolidation and Consensus 2007 JavaOneSM Conference | Session TS-7820 | 6 Early History Early history: 2005/2006 Initial Code Contributions • Three Virtual machines ● JCHEVM, BootVM, DRLVM • Class Libraries ● Core classes, VM interface, test cases ● Security, beans, regex, Swing, AWT ● RMI and math 2007 JavaOneSM Conference | Session TS-7820 | -

Avaliando a Dívida Técnica Em Produtos De Código Aberto Por Meio De Estudos Experimentais
UNIVERSIDADE FEDERAL DE GOIÁS INSTITUTO DE INFORMÁTICA IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Goiânia 2014 IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Dissertação apresentada ao Programa de Pós–Graduação do Instituto de Informática da Universidade Federal de Goiás, como requisito parcial para obtenção do título de Mestre em Ciência da Computação. Área de concentração: Ciência da Computação. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi Goiânia 2014 Ficha catalográfica elaborada automaticamente com os dados fornecidos pelo(a) autor(a), sob orientação do Sibi/UFG. Vieira, Igor Rodrigues Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais [manuscrito] / Igor Rodrigues Vieira. - 2014. 100 f.: il. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi. Dissertação (Mestrado) - Universidade Federal de Goiás, Instituto de Informática (INF) , Programa de Pós-Graduação em Ciência da Computação, Goiânia, 2014. Bibliografia. Apêndice. Inclui algoritmos, lista de figuras, lista de tabelas. 1. Dívida técnica. 2. Qualidade de software. 3. Análise estática. 4. Produto de código aberto. 5. Estudo experimental. I. Vincenzi, Auri Marcelo Rizzo, orient. II. Título. Todos os direitos reservados. É proibida a reprodução total ou parcial do trabalho sem autorização da universidade, do autor e do orientador(a). Igor Rodrigues Vieira Graduado em Sistemas de Informação, pela Universidade Estadual de Goiás – UEG, com pós-graduação lato sensu em Desenvolvimento de Aplicações Web com Interfaces Ricas, pela Universidade Federal de Goiás – UFG. Foi Coordenador da Ouvidoria da UFG e, atualmente, é Analista de Tecnologia da Informação do Centro de Recursos Computacionais – CERCOMP/UFG. -

Site Map - Apache HTTP Server 2.0
Site Map - Apache HTTP Server 2.0 Apache HTTP Server Version 2.0 Site Map ● Apache HTTP Server Version 2.0 Documentation ❍ Release Notes ■ Upgrading to 2.0 from 1.3 ■ New features with Apache 2.0 ❍ Using the Apache HTTP Server ■ Compiling and Installing Apache ■ Starting Apache ■ Stopping and Restarting the Server ■ Configuration Files ■ How Directory, Location and Files sections work ■ Server-Wide Configuration ■ Log Files ■ Mapping URLs to Filesystem Locations ■ Security Tips ■ Dynamic Shared Object (DSO) support ■ Content Negotiation ■ Custom error responses ■ Setting which addresses and ports Apache uses ■ Multi-Processing Modules (MPMs) ■ Environment Variables in Apache ■ Apache's Handler Use ■ Filters ■ suEXEC Support ■ Performance Hintes ■ URL Rewriting Guide ❍ Apache Virtual Host documentation ■ Name-based Virtual Hosts ■ IP-based Virtual Host Support ■ Dynamically configured mass virtual hosting ■ VirtualHost Examples ■ An In-Depth Discussion of Virtual Host Matching ■ File descriptor limitations ■ Issues Regarding DNS and Apache ❍ Apache Server Frequently Asked Questions http://httpd.apache.org/docs-2.0/sitemap.html (1 of 4) [5/03/2002 9:53:06 PM] Site Map - Apache HTTP Server 2.0 ■ Support ❍ Apache SSL/TLS Encryption ■ SSL/TLS Encryption: An Introduction ■ SSL/TLS Encryption: Compatibility ■ SSL/TLS Encryption: How-To ■ SSL/TLS Encryption: FAQ ■ SSL/TLS Encryption: Glossary ❍ Guides, Tutorials, and HowTos ■ Authentication ■ Apache Tutorial: Dynamic Content with CGI ■ Apache Tutorial: Introduction to Server Side Includes ■ Apache -

How SOA… 26 Summary 31 Table of Contents
Service Oriented Architecture with Java Using SOA and web services to build powerful Java applications Binildas CA Malhar Barai Vincenzo Caselli BIRMINGHAM - MUMBAI Service Oriented Architecture with Java Copyright © 2008 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the authors, Packt Publishing, nor its dealers or distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: June 2008 Production Reference: 1180608 Published by Packt Publishing Ltd. 32 Lincoln Road Olton Birmingham, B27 6PA, UK. ISBN 978-1-847193-21-6 www.packtpub.com Cover Image by Nik Lawrence ([email protected]) Credits Authors Project Manager Binildas CA Abhijeet Deobhakta Malhar Barai Vincenzo Caselli Project Coordinator Abhijeet Deobhakta Reviewer Shyam Sankar S Indexer Monica Ajmera Acquisition Editor Bansari Barot Proofreader Petula Wright Technical Editor Dhiraj Chandiramani Production Coordinator Shantanu Zagade Editorial Team Leader Akshara Aware Cover Work Shantanu Zagade About the Authors Malhar Barai is a senior systems analyst with Satyam Computer Services Ltd., one of India's leading IT services organizations. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -
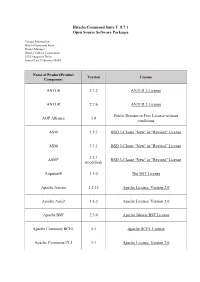
Hitachi Command Suite V.8.7.1
Hitachi Command Suite V. 8.7.1 Open Source Software Packages Contact Information: Hitachi Command Suite Project Manager Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component ANTLR 2.7.2 ANTLR 2 License ANTLR 2.7.6 ANTLR 2 License Public Domain or Free License without AOP Alliance 1.0 conditions ASM 1.5.3 BSD 3-Clause "New" or "Revised" License ASM 3.3.1 BSD 3-Clause "New" or "Revised" License 3.3.1 ASM* BSD 3-Clause "New" or "Revised" License (modified) AngularJS 1.3.0 The MIT License Apache Axiom 1.2.13 Apache License, Version 2.0 Apache Axis2 1.6.2 Apache License, Version 2.0 Apache BSF 2.3.0 Apache Jakarta BSF License Apache Commons BCEL 5.1 Apache BCEL License Apache Commons CLI 1.1 Apache License, Version 2.0 Name of Product/Product Version License Component Apache Commons Codec 1.11 Apache License, Version 2.0 Apache Commons Codec 1.3 Apache License, Version 2.0 Apache Commons Collections 2.1 Apache Jakarta Commons License Apache Commons Collections 3.2.2 Apache License, Version 2.0 Apache Commons Digester 1.5 Apache Jakarta Commons License Apache Commons Digester 1.8 Apache License, Version 2.0 Apache Commons XMLSchema 1.4.7 Apache License, Version 2.0 Apache FOP 1.0 Apache License, Version 2.0 Apache License, Version 2.0 ISC License PCRE LICENCE (PCRE 4.5 and earlier) The License by "Bell Communications 2.0.59 Apache HTTP Server* Research, Inc. -
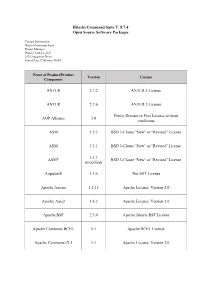
Hitachi Command Suite V. 8.7.4 Open Source Software Packages
Hitachi Command Suite V. 8.7.4 Open Source Software Packages Contact Information: Hitachi Command Suite Project Manager Hitachi Vantara, LLC 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component ANTLR 2.7.2 ANTLR 2 License ANTLR 2.7.6 ANTLR 2 License Public Domain or Free License without AOP Alliance 1.0 conditions ASM 1.5.3 BSD 3-Clause "New" or "Revised" License ASM 3.3.1 BSD 3-Clause "New" or "Revised" License 3.3.1 ASM* BSD 3-Clause "New" or "Revised" License (modified) AngularJS 1.3.0 The MIT License Apache Axiom 1.2.13 Apache License, Version 2.0 Apache Axis2 1.6.2 Apache License, Version 2.0 Apache BSF 2.3.0 Apache Jakarta BSF License Apache Commons BCEL 5.1 Apache BCEL License Apache Commons CLI 1.1 Apache License, Version 2.0 Name of Product/Product Version License Component Apache Commons Codec 1.11 Apache License, Version 2.0 Apache Commons Codec 1.3 Apache License, Version 2.0 Apache Commons Collections 2.1 Apache Jakarta Commons License Apache Commons Collections 3.2.2 Apache License, Version 2.0 Apache Commons Digester 1.5 Apache Jakarta Commons License Apache Commons Digester 1.8 Apache License, Version 2.0 Apache Commons XMLSchema 1.4.7 Apache License, Version 2.0 Apache FOP 1.0 Apache License, Version 2.0 Apache License, Version 2.0 ISC License PCRE LICENCE (PCRE 4.5 and earlier) The License by "Bell Communications 2.0.59 Apache HTTP Server* Research, Inc. -

Open Source SOA
Jeff Davis MANNING Open Source SOA Licensed to Venkataramanan Tharagam <[email protected]> Licensed to Venkataramanan Tharagam <[email protected]> Open Source SOA JEFF DAVIS MANNING Greenwich (74° w. long.) Licensed to Venkataramanan Tharagam <[email protected]> For online information and ordering of this and other Manning books, please visit www.manning.com. The publisher offers discounts on this book when ordered in quantity. For more information, please contact Special Sales Department Manning Publications Co. Sound View Court 3B fax: (609) 877-8256 Greenwick, CT 06830 email: [email protected] ©2009 by Manning Publications Co. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the publisher. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in the book, and Manning Publications was aware of a trademark claim, the designations have been printed in initial caps or all caps. Recognizing the importance of preserving what has been written, it is Manning’s policy to have the books we publish printed on acid-free paper, and we exert our best efforts to that end. Recognizing also our responsibility to conserve the resources of our planet, Manning books are printed on paper that is at least 15 percent recycled and processed without the use of elemental chlorine. Development Editor: Cynthia Kane Manning Publications Co. Copyeditor: Liz Welch Sound View Court 3B Typesetter: Krzysztof Anton Greenwich, CT 06830 Cover designer: Leslie Haimes ISBN 978-1-933988-54-2 Printed in the United States of America 12345678910–MAL–16151413111009 Licensed to Venkataramanan Tharagam <[email protected]> brief contents PART 1HISTORY AND PRINCIPLES ...........................................