D3.2 – Predictive Analytics and Recommendation Framework V2
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

FALLENS DAGAR I TROLLHÄTTAN Fri Entré!
60år! Molly Sandén Lördag 20 juli 20.00 Folkets park Timbuktu & Damn Lördag 20 juli 21.45 Linnea Henriksson Folkets park & N3 Symfoniorkester Söndag 21 juli 21.00 Folkets park LIAMOO HANNA FERM Malou Prytz Smith & Thell ERIC GADD Kaurna Cronin & Band BRÖDERNA NORBERG ...och många fler! Fri entré! fallensdagar.se Fallens Dagar ARTISTER 60år! STORA Trollhättans stora vatten festival SCENEN bjuder som vanligt på brusande fall, gratis familjeaktiviteter och många konserter med fri entré. Men innan vi presenterar årets höjdpunkter blickar vi tillbaka till 1959 då Trollhättefallens Dag för första gången presenterades… ”Somliga städer är bekanta för gurkor, andra för peppar rot och pepparkakor – men här i Trollhättan har vi Sommarens hetaste artister spelar något ännu finare: Vi har på Fallens Dagars stora utomhus- brusande vattenfall. Varje år, varje sommar, ska det bli en scen i Trollhättan, Folkets park. garanterad heldag då massor Fri entré till konserterna! av vatten ska forsa fram i de gamla fallfårorna och riktigt visa vad Trollhättan kan bjuda när den bjuder till.” (Okänd skribent, TT 12/5 1959) LIAMOO Ja, ursprungsnamnet var just 2016 rappade och sjöng Liam sig Trollhättefallens Dag som det var hela vägen till svenska folkets hjär- tänkt skulle pågå en enda dag men tan och vann tävlingen Idol. 2018 förhoppningsvis bli en återkom- medverkade han i Melodifestivalen mande tradition. Att så blev fallet Eriksson Rickard Foto: med ”Last Breath” som han själv vet ju alla vi som sitter med facit i varit med och skrivit och tog sig hand så här sextio år och sextioett direkt till final från sin deltäv- Fallens Dags-tillfällen senare. -

The Concert Hall As a Medium of Musical Culture: the Technical Mediation of Listening in the 19Th Century
The Concert Hall as a Medium of Musical Culture: The Technical Mediation of Listening in the 19th Century by Darryl Mark Cressman M.A. (Communication), University of Windsor, 2004 B.A (Hons.), University of Windsor, 2002 Dissertation Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy in the School of Communication Faculty of Communication, Art and Technology © Darryl Mark Cressman 2012 SIMON FRASER UNIVERSITY Fall 2012 All rights reserved. However, in accordance with the Copyright Act of Canada, this work may be reproduced, without authorization, under the conditions for “Fair Dealing.” Therefore, limited reproduction of this work for the purposes of private study, research, criticism, review and news reporting is likely to be in accordance with the law, particularly if cited appropriately. Approval Name: Darryl Mark Cressman Degree: Doctor of Philosophy (Communication) Title of Thesis: The Concert Hall as a Medium of Musical Culture: The Technical Mediation of Listening in the 19th Century Examining Committee: Chair: Martin Laba, Associate Professor Andrew Feenberg Senior Supervisor Professor Gary McCarron Supervisor Associate Professor Shane Gunster Supervisor Associate Professor Barry Truax Internal Examiner Professor School of Communication, Simon Fraser Universty Hans-Joachim Braun External Examiner Professor of Modern Social, Economic and Technical History Helmut-Schmidt University, Hamburg Date Defended: September 19, 2012 ii Partial Copyright License iii Abstract Taking the relationship -

Creating a Roadmap for the Future of Music at the Smithsonian
Creating a Roadmap for the Future of Music at the Smithsonian A summary of the main discussion points generated at a two-day conference organized by the Smithsonian Music group, a pan- Institutional committee, with the support of Grand Challenges Consortia Level One funding June 2012 Produced by the Office of Policy and Analysis (OP&A) Contents Acknowledgements .................................................................................................................................. 3 Introduction ................................................................................................................................................ 4 Background ............................................................................................................................................ 4 Conference Participants ..................................................................................................................... 5 Report Structure and Other Conference Records ............................................................................ 7 Key Takeaway ........................................................................................................................................... 8 Smithsonian Music: Locus of Leadership and an Integrated Approach .............................. 8 Conference Proceedings ...................................................................................................................... 10 Remarks from SI Leadership ........................................................................................................ -
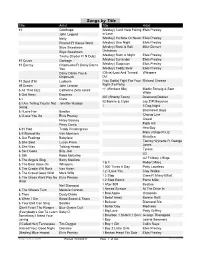
Songs by Title
Songs by Title Title Artist Title Artist #1 Goldfrapp (Medley) Can't Help Falling Elvis Presley John Legend In Love Nelly (Medley) It's Now Or Never Elvis Presley Pharrell Ft Kanye West (Medley) One Night Elvis Presley Skye Sweetnam (Medley) Rock & Roll Mike Denver Skye Sweetnam Christmas Tinchy Stryder Ft N Dubz (Medley) Such A Night Elvis Presley #1 Crush Garbage (Medley) Surrender Elvis Presley #1 Enemy Chipmunks Ft Daisy Dares (Medley) Suspicion Elvis Presley You (Medley) Teddy Bear Elvis Presley Daisy Dares You & (Olivia) Lost And Turned Whispers Chipmunk Out #1 Spot (TH) Ludacris (You Gotta) Fight For Your Richard Cheese #9 Dream John Lennon Right (To Party) & All That Jazz Catherine Zeta Jones +1 (Workout Mix) Martin Solveig & Sam White & Get Away Esquires 007 (Shanty Town) Desmond Dekker & I Ciara 03 Bonnie & Clyde Jay Z Ft Beyonce & I Am Telling You Im Not Jennifer Hudson Going 1 3 Dog Night & I Love Her Beatles Backstreet Boys & I Love You So Elvis Presley Chorus Line Hirley Bassey Creed Perry Como Faith Hill & If I Had Teddy Pendergrass HearSay & It Stoned Me Van Morrison Mary J Blige Ft U2 & Our Feelings Babyface Metallica & She Said Lucas Prata Tammy Wynette Ft George Jones & She Was Talking Heads Tyrese & So It Goes Billy Joel U2 & Still Reba McEntire U2 Ft Mary J Blige & The Angels Sing Barry Manilow 1 & 1 Robert Miles & The Beat Goes On Whispers 1 000 Times A Day Patty Loveless & The Cradle Will Rock Van Halen 1 2 I Love You Clay Walker & The Crowd Goes Wild Mark Wills 1 2 Step Ciara Ft Missy Elliott & The Grass Wont Pay -

Love & Wedding
651 LOVE & WEDDING THE O’NEILL PLANNING RODGERS BROTHERS – THE MUSIC & ROMANCE A DAY TO REMEMBER FOR YOUR WEDDING 35 songs, including: All at PIANO MUSIC FOR Book/CD Pack Once You Love Her • Do YOUR WEDDING DAY Cherry Lane Music I Love You Because You’re Book/CD Pack The difference between a Beautiful? • Hello, Young Minnesota brothers Tim & good wedding and a great Lovers • If I Loved You • Ryan O’Neill have made a wedding is the music. With Isn’t It Romantic? • My Funny name for themselves playing this informative book and Valentine • My Romance • together on two pianos. accompanying CD, you can People Will Say We’re in Love They’ve sold nearly a million copies of their 16 CDs, confidently select classical music for your wedding • We Kiss in a Shadow • With a Song in My Heart • performed for President Bush and provided music ceremony regardless of your musical background. Younger Than Springtime • and more. for the NBC, ESPN and HBO networks. This superb The book includes piano solo arrangements of each ______00313089 P/V/G...............................$16.99 songbook/CD pack features their original recordings piece, as well as great tips and tricks for planning the of 16 preludes, processionals, recessionals and music for your entire wedding day. The CD includes ROMANCE: ceremony and reception songs, plus intermediate to complete performances of each piece, so even if BOLEROS advanced piano solo arrangements for each. Includes: you’re not familiar with the titles, you can recognize FAVORITOS Air on the G String • Ave Maria • Canon in D • Jesu, your favorites with just one listen! The book is 48 songs in Spanish, Joy of Man’s Desiring • Ode to Joy • The Way You divided into selections for preludes, processionals, including: Adoro • Always Look Tonight • The Wedding Song • and more, with interludes, recessionals and postludes, and contains in My Heart • Bésame bios and photos of the O’Neill Brothers. -

Youth Guide to the Department of Youth and Community Development Will Be Updating This Guide Regularly
NYC2015 Youth Guide to The Department of Youth and Community Development will be updating this guide regularly. Please check back with us to see the latest additions. Have a safe and fun Summer! For additional information please call Youth Connect at 1.800.246.4646 T H E C I T Y O F N EW Y O RK O FFI CE O F T H E M AYOR N EW Y O RK , NY 10007 Summer 2015 Dear Friends: I am delighted to share with you the 2015 edition of the New York City Youth Guide to Summer Fun. There is no season quite like summer in the City! Across the five boroughs, there are endless opportunities for creation, relaxation and learning, and thanks to the efforts of the Department of Youth and Community Development and its partners, this guide will help neighbors and visitors from all walks of life savor the full flavor of the city and plan their family’s fun in the sun. Whether hitting the beach or watching an outdoor movie, dancing under the stars or enjoying a puppet show, exploring the zoo or sketching the skyline, attending library read-alouds or playing chess, New Yorkers are sure to make lasting memories this July and August as they discover a newfound appreciation for their diverse and vibrant home. My administration is committed to ensuring that all 8.5 million New Yorkers can enjoy and contribute to the creative energy of our city. This terrific resource not only helps us achieve that important goal, but also sustains our status as a hub of culture and entertainment. -

Marygold Manor DJ List
Page 1 of 143 Marygold Manor 4974 songs, 12.9 days, 31.82 GB Name Artist Time Genre Take On Me A-ah 3:52 Pop (fast) Take On Me a-Ha 3:51 Rock Twenty Years Later Aaron Lines 4:46 Country Dancing Queen Abba 3:52 Disco Dancing Queen Abba 3:51 Disco Fernando ABBA 4:15 Rock/Pop Mamma Mia ABBA 3:29 Rock/Pop You Shook Me All Night Long AC/DC 3:30 Rock You Shook Me All Night Long AC/DC 3:30 Rock You Shook Me All Night Long AC/DC 3:31 Rock AC/DC Mix AC/DC 5:35 Dirty Deeds Done Dirt Cheap ACDC 3:51 Rock/Pop Thunderstruck ACDC 4:52 Rock Jailbreak ACDC 4:42 Rock/Pop New York Groove Ace Frehley 3:04 Rock/Pop All That She Wants (start @ :08) Ace Of Base 3:27 Dance (fast) Beautiful Life Ace Of Base 3:41 Dance (fast) The Sign Ace Of Base 3:09 Pop (fast) Wonderful Adam Ant 4:23 Rock Theme from Mission Impossible Adam Clayton/Larry Mull… 3:27 Soundtrack Ghost Town Adam Lambert 3:28 Pop (slow) Mad World Adam Lambert 3:04 Pop For Your Entertainment Adam Lambert 3:35 Dance (fast) Nirvana Adam Lambert 4:23 I Wanna Grow Old With You (edit) Adam Sandler 2:05 Pop (slow) I Wanna Grow Old With You (start @ 0:28) Adam Sandler 2:44 Pop (slow) Hello Adele 4:56 Pop Make You Feel My Love Adele 3:32 Pop (slow) Chasing Pavements Adele 3:34 Make You Feel My Love Adele 3:32 Pop Make You Feel My Love Adele 3:32 Pop Rolling in the Deep Adele 3:48 Blue-eyed soul Marygold Manor Page 2 of 143 Name Artist Time Genre Someone Like You Adele 4:45 Blue-eyed soul Rumour Has It Adele 3:44 Pop (fast) Sweet Emotion Aerosmith 5:09 Rock (slow) I Don't Want To Miss A Thing (Cold Start) -

Rca Records to Release American Idol: Greatest Moments on October 1
THE RCA RECORDS LABEL ___________________________________________ RCA RECORDS TO RELEASE AMERICAN IDOL: GREATEST MOMENTS ON OCTOBER 1 On the heels of crowning Kelly Clarkson as America's newest pop superstar, RCA Records is proud to announce the release of American Idol: Greatest Moments on Oct. 1. The first full-length album of material from Fox's smash summer television hit, "American Idol," will include four songs by Clarkson, two by runner-up Justin Guarini, a song each by the remaining eight finalists, and “California Dreamin’” performed by all ten. All 14 tracks on American Idol: Greatest Moments, produced by Steve Lipson (Backstreet Boys, Annie Lennox), were performed on "American Idol" during the final weeks of the reality-based television barnburner. In addition to Kelly and Justin, the show's remaining eight finalists featured on the album include Nikki McKibbon, Tamyra Gray, EJay Day, RJ Helton, AJ Gil, Ryan Starr, Christina Christian, and Jim Verraros. Producer Steve Lipson, who put the compilation together in an unprecedented two-weeks time, finds a range of pop gems on the album. "I think Kelly's version of ‘Natural Woman' is really strong. Her vocals are brilliant. She sold me on the song completely. I like Christina's 'Ain't No Sunshine.' I think she got the emotion of it across well. Nikki is very good as well -- very underestimated. And Tamyra is brilliant too so there's not much more to say about her." RCA Records will follow American Idol: Greatest Moments with the debut album from “American Idol” champion Kelly Clarkson in the first quarter of 2003. -

Music Industry Report 2020 Includes the Work of Talented Student Interns Who Went Through a Competitive Selection Process to Become a Part of the Research Team
2O2O THE RESEARCH TEAM This study is a product of the collaboration and vision of multiple people. Led by researchers from the Nashville Area Chamber of Commerce and Exploration Group: Joanna McCall Coordinator of Applied Research, Nashville Area Chamber of Commerce Barrett Smith Coordinator of Applied Research, Nashville Area Chamber of Commerce Jacob Wunderlich Director, Business Development and Applied Research, Exploration Group The Music Industry Report 2020 includes the work of talented student interns who went through a competitive selection process to become a part of the research team: Alexander Baynum Shruthi Kumar Belmont University DePaul University Kate Cosentino Isabel Smith Belmont University Elon University Patrick Croke University of Virginia In addition, Aaron Davis of Exploration Group and Rupa DeLoach of the Nashville Area Chamber of Commerce contributed invaluable input and analysis. Cluster Analysis and Economic Impact Analysis were conducted by Alexander Baynum and Rupa DeLoach. 2 TABLE OF CONTENTS 5 - 6 Letter of Intent Aaron Davis, Exploration Group and Rupa DeLoach, The Research Center 7 - 23 Executive Summary 25 - 27 Introduction 29 - 34 How the Music Industry Works Creator’s Side Listener’s Side 36 - 78 Facets of the Music Industry Today Traditional Small Business Models, Startups, Venture Capitalism Software, Technology and New Media Collective Management Organizations Songwriters, Recording Artists, Music Publishers and Record Labels Brick and Mortar Retail Storefronts Digital Streaming Platforms Non-interactive -

Genre, De Muziekstijl, Stemming Van De Muziek En De Instrumentatie Die Een Bepaalde Artiest Uitoefende
Een Sociaal Netwerk Onder Muziekartiesten: Een analyse van het sociaal netwerk van muzikanten en daaraan verbonden muzikale kenmerken Gegevens student B.J.G.M. Kuppens Corporate Communication & Digital Media Universiteit van Tilburg [email protected] Begeleiding dr. J. J. Paijmans Faculteit Geesteswetenschappen dpt. Comm.‐ Infor.wetensch [email protected] 1 Abstract Dit onderzoek verdiept zich in de structuur van het sociaal netwerk van muziekartiesten. Wat onderzocht wordt, is of er binnen dit sociaal netwerk een zogenaamde power law verdeling te ontdekken valt. Dit is interessant vanwege de maatschappelijke relevantie van power law structuren in de samenleving. Om dit vast te stellen is er gekeken naar wie de meest invloedrijke artiesten zijn en van wie er de meeste nummers gecoverd zijn. De verwachting is dat er relatief weinig artiesten zijn met relatief veel invloed op medeartiesten, en overeenkomstig staan veel artiesten die weinig invloed hebben op hun medeartiesten. Hetzelfde fenomeen wordt verwacht bevestigd te worden voor gecoverde nummers. Nadat is gebleken dat de structuur van het sociaal netwerk onder muziekartiesten daadwerkelijk de kenmerken vertoont van een power law verdeling, is er vervolgens nog gekeken naar een viertal muzikale kenmerken van de meest invloedrijke artiesten gevonden tijdens dit onderzoek. Het betreft het genre, de muziekstijl, stemming van de muziek en de instrumentatie die een bepaalde artiest uitoefende. Ook van deze variabelen is er een frequentieverdeling gemaakt en is er gekeken of er op een power law gelijkende verdeling is. Dit bleek alleen bij de variabelen genre en instrumentatie het geval te zijn. Muziekstijl in mindere mate en wat stemming betreft zijn er geen dominante items gevonden. -

Idioms-And-Expressions.Pdf
Idioms and Expressions by David Holmes A method for learning and remembering idioms and expressions I wrote this model as a teaching device during the time I was working in Bangkok, Thai- land, as a legal editor and language consultant, with one of the Big Four Legal and Tax companies, KPMG (during my afternoon job) after teaching at the university. When I had no legal documents to edit and no individual advising to do (which was quite frequently) I would sit at my desk, (like some old character out of a Charles Dickens’ novel) and prepare language materials to be used for helping professionals who had learned English as a second language—for even up to fifteen years in school—but who were still unable to follow a movie in English, understand the World News on TV, or converse in a colloquial style, because they’d never had a chance to hear and learn com- mon, everyday expressions such as, “It’s a done deal!” or “Drop whatever you’re doing.” Because misunderstandings of such idioms and expressions frequently caused miscom- munication between our management teams and foreign clients, I was asked to try to as- sist. I am happy to be able to share the materials that follow, such as they are, in the hope that they may be of some use and benefit to others. The simple teaching device I used was three-fold: 1. Make a note of an idiom/expression 2. Define and explain it in understandable words (including synonyms.) 3. Give at least three sample sentences to illustrate how the expression is used in context. -

Musikstile Quelle: Alphabetisch Geordnet Von Mukerbude
MusikStile Quelle: www.recordsale.de Alphabetisch geordnet von MukerBude - 2-Step/BritishGarage - AcidHouse - AcidJazz - AcidRock - AcidTechno - Acappella - AcousticBlues - AcousticChicagoBlues - AdultAlternative - AdultAlternativePop/Rock - AdultContemporary -Africa - AfricanJazz - Afro - Afro-Pop -AlbumRock - Alternative - AlternativeCountry - AlternativeDance - AlternativeFolk - AlternativeMetal - AlternativePop/Rock - AlternativeRap - Ambient - AmbientBreakbeat - AmbientDub - AmbientHouse - AmbientPop - AmbientTechno - Americana - AmericanPopularSong - AmericanPunk - AmericanTradRock - AmericanUnderground - AMPop Orchestral - ArenaRock - Argentina - Asia -AussieRock - Australia - Avant -Avant-Garde - Avntg - Ballads - Baroque - BaroquePop - BassMusic - Beach - BeatPoetry - BigBand - BigBeat - BlackGospel - Blaxploitation - Blue-EyedSoul -Blues - Blues-Rock - BluesRevival - Blues - Spain - Boogie Woogie - Bop - Bolero -Boogaloo - BoogieRock - BossaNova - Brazil - BrazilianJazz - BrazilianPop - BrillBuildingPop - Britain - BritishBlues - BritishDanceBands - BritishFolk - BritishFolk Rock - BritishInvasion - BritishMetal - BritishPsychedelia - BritishPunk - BritishRap - BritishTradRock - Britpop - BrokenBeat - Bubblegum - C -86 - Cabaret -Cajun - Calypso - Canada - CanterburyScene - Caribbean - CaribbeanFolk - CastRecordings -CCM -CCM - Celebrity - Celtic - Celtic - CelticFolk - CelticFusion - CelticPop - CelticRock - ChamberJazz - ChamberMusic - ChamberPop - Chile - Choral - ChicagoBlues - ChicagoSoul - Child - Children'sFolk - Christmas