Downloads/Doe-Public- Access-Plan)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Zerohack Zer0pwn Youranonnews Yevgeniy Anikin Yes Men
Zerohack Zer0Pwn YourAnonNews Yevgeniy Anikin Yes Men YamaTough Xtreme x-Leader xenu xen0nymous www.oem.com.mx www.nytimes.com/pages/world/asia/index.html www.informador.com.mx www.futuregov.asia www.cronica.com.mx www.asiapacificsecuritymagazine.com Worm Wolfy Withdrawal* WillyFoReal Wikileaks IRC 88.80.16.13/9999 IRC Channel WikiLeaks WiiSpellWhy whitekidney Wells Fargo weed WallRoad w0rmware Vulnerability Vladislav Khorokhorin Visa Inc. Virus Virgin Islands "Viewpointe Archive Services, LLC" Versability Verizon Venezuela Vegas Vatican City USB US Trust US Bankcorp Uruguay Uran0n unusedcrayon United Kingdom UnicormCr3w unfittoprint unelected.org UndisclosedAnon Ukraine UGNazi ua_musti_1905 U.S. Bankcorp TYLER Turkey trosec113 Trojan Horse Trojan Trivette TriCk Tribalzer0 Transnistria transaction Traitor traffic court Tradecraft Trade Secrets "Total System Services, Inc." Topiary Top Secret Tom Stracener TibitXimer Thumb Drive Thomson Reuters TheWikiBoat thepeoplescause the_infecti0n The Unknowns The UnderTaker The Syrian electronic army The Jokerhack Thailand ThaCosmo th3j35t3r testeux1 TEST Telecomix TehWongZ Teddy Bigglesworth TeaMp0isoN TeamHav0k Team Ghost Shell Team Digi7al tdl4 taxes TARP tango down Tampa Tammy Shapiro Taiwan Tabu T0x1c t0wN T.A.R.P. Syrian Electronic Army syndiv Symantec Corporation Switzerland Swingers Club SWIFT Sweden Swan SwaggSec Swagg Security "SunGard Data Systems, Inc." Stuxnet Stringer Streamroller Stole* Sterlok SteelAnne st0rm SQLi Spyware Spying Spydevilz Spy Camera Sposed Spook Spoofing Splendide -

Information Security Primer from Social Engineering to SQL Injection...And Everything Beginning with P
Information Security Primer From Social Engineering to SQL Injection...and Everything Beginning with P PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Tue, 18 Aug 2009 21:14:59 UTC Contents Articles It Begins with S 1 Social engineering (security) 1 Spyware 7 SQL injection 26 Bonus Material 34 Password cracking 34 References Article Sources and Contributors 41 Image Sources, Licenses and Contributors 43 Article Licenses License 44 1 It Begins with S Social engineering (security) Social engineering is the act of manipulating people into performing actions or divulging confidential information. While similar to a confidence trick or simple fraud, the term typically applies to trickery or deception for the purpose of information gathering, fraud, or computer system access; in most cases the attacker never comes face-to-face with the victim. Social engineering techniques and terms All social engineering techniques are based on specific attributes of human decision-making known as cognitive biases.[1] These biases, sometimes called "bugs in the human hardware," are exploited in various combinations to create attack techniques, some of which are listed here: Pretexting Pretexting is the act of creating and using an invented scenario (the pretext) to persuade a targeted victim to release information or perform an action and is typically done over the telephone. It is more than a simple lie as it most often involves some prior research or set up and the use of pieces of known information (e.g. for impersonation: date of birth, Social Security Number, last bill amount) to establish legitimacy in the mind of the target. -
The Malware Book 2016
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/305469492 Handbook of Malware 2016 - A Wikipedia Book Book · July 2016 DOI: 10.13140/RG.2.1.5039.5122 CITATIONS READS 0 13,014 2 authors, including: Reiner Creutzburg Brandenburg University of Applied Sciences 489 PUBLICATIONS 472 CITATIONS SEE PROFILE Some of the authors of this publication are also working on these related projects: NDT CE – Assessment of structures || ZfPBau – ZfPStatik View project 14. Nachwuchswissenschaftlerkonferenz Ost- und Mitteldeutscher Fachhochschulen (NWK 14) View project All content following this page was uploaded by Reiner Creutzburg on 20 July 2016. The user has requested enhancement of the downloaded file. Handbook of Malware 2016 A Wikipedia Book By Wikipedians Edited by: Reiner Creutzburg Technische Hochschule Brandenburg Fachbereich Informatik und Medien PF 2132 D-14737 Brandenburg Germany Email: [email protected] Contents 1 Malware - Introduction 1 1.1 Malware .................................................. 1 1.1.1 Purposes ............................................. 1 1.1.2 Proliferation ........................................... 2 1.1.3 Infectious malware: viruses and worms ............................. 3 1.1.4 Concealment: Viruses, trojan horses, rootkits, backdoors and evasion .............. 3 1.1.5 Vulnerability to malware ..................................... 4 1.1.6 Anti-malware strategies ..................................... 5 1.1.7 Grayware ............................................ -

Applied Network Security Monitoring 1St Edition Pdf, Epub, Ebook
APPLIED NETWORK SECURITY MONITORING 1ST EDITION PDF, EPUB, EBOOK Chris Sanders | 9780124172166 | | | | | Applied Network Security Monitoring 1st edition PDF Book Network security monitoring is based on the principle that prevention eventually fails. Skip to main content. Your review was sent successfully and is now waiting for our team to publish it. Institutional Subscription. Handling time. Great book on important subject. Packet Headers Appendix 4. Additional Data Analysis. Three basic actions regarding the packet consist of a silent discard, discard with Internet Control Message Protocol or TCP reset response to the sender, and forward to the next hop. Payment details. Building an Intelligence-Led Security Program. Making Decisions with Sguil. Suspicious Port 53 Traffic. Sensor Management. SKU: khvqs Category: Ebook. Buy only this item Close this window. Refer to eBay Return policy for more details. Anti-keylogger Antivirus software Browser security Data loss prevention software Defensive computing Firewall Internet security Intrusion detection system Mobile security Network security. So What Is Sguil? Please enter a valid ZIP Code. As of , the next- generation firewall provides a wider range of inspection at the application layer, extending deep packet inspection functionality to include, but is not limited to:. Alert Data: Bro and Prelude. Interest will be charged to your account from the purchase date if the balance is not paid in full within 6 months. Shipping help - opens a layer International Shipping - items may be subject to customs processing depending on the item's customs value. Retrieved Network security monitoring NSM equips security staff to deal with the inevitable consequences of too few resources and too many responsibilities. -

Hacking the Abacus: an Undergraduate Guide to Programming Weird Machines
Hacking the Abacus: An Undergraduate Guide to Programming Weird Machines by Michael E. Locasto and Sergey Bratus version 1.0 c 2008-2014 Michael E. Locasto and Sergey Bratus All rights reserved. i WHEN I HEARD THE LEARN’D ASTRONOMER; WHEN THE PROOFS, THE FIGURES, WERE RANGED IN COLUMNS BEFORE ME; WHEN I WAS SHOWN THE CHARTS AND THE DIAGRAMS, TO ADD, DIVIDE, AND MEASURE THEM; WHEN I, SITTING, HEARD THE ASTRONOMER, WHERE HE LECTURED WITH MUCH APPLAUSE IN THE LECTURE–ROOM, HOW SOON, UNACCOUNTABLE,I BECAME TIRED AND SICK; TILL RISING AND GLIDING OUT,I WANDER’D OFF BY MYSELF, IN THE MYSTICAL MOIST NIGHT–AIR, AND FROM TIME TO TIME, LOOK’D UP IN PERFECT SILENCE AT THE STARS. When I heard the Learn’d Astronomer, from “Leaves of Grass”, by Walt Whitman. ii Contents I Overview 1 1 Introduction 5 1.1 Target Audience . 5 1.2 The “Hacker Curriculum” . 6 1.2.1 A Definition of “Hacking” . 6 1.2.2 Trust . 6 1.3 Structure of the Book . 7 1.4 Chapter Organization . 7 1.5 Stuff You Should Know . 8 1.5.1 General Motivation About SISMAT . 8 1.5.2 Security Mindset . 9 1.5.3 Driving a Command Line . 10 II Exercises 11 2 Ethics 13 2.1 Background . 14 2.1.1 Capt. Oates . 14 2.2 Moral Philosophies . 14 2.3 Reading . 14 2.4 Ethical Scenarios for Discussion . 15 2.5 Lab 1: Warmup . 16 2.5.1 Downloading Music . 16 2.5.2 Shoulder-surfing . 16 2.5.3 Not Obeying EULA Provisions . -
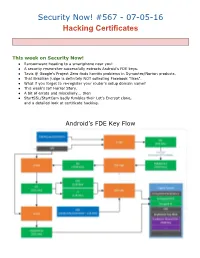
Security Now! #567Ана070516 Hacking Certificates
Security Now! #567 070516 Hacking Certificates This week on Security Now! ● Ransomware heading to a smartphone near you! ● A security researcher successfully extracts Android's FDE keys. ● Tavis @ Google's Project Zero finds horrific problems in Symantec/Norton products. ● That Brazilian judge is definitely NOT collecting Facebook "likes". ● What if you forget to reregister your router's setup domain name? ● This week's IoT Horror Story. ● A bit of errata and miscellany... then ● StartSSL/StartCom badly fumbles their Let's Encrypt clone, and a detailed look at certificate hacking. Android’s FDE Key Flow Security News Ransomware on mobile devices: knockknock & block https://usblog.kaspersky.com/mobileransomware2016/7346/ ● Android customers infected with mobile ransomware hit 136K in April 2016, nearly quadrupling from March 2015 ● Encrypt files or Block browser or the OS from working? ● Desktops favor file encryption, whereas mobile devices, which are typically backed up to the cloud, and could thereby have their files recovered and may also not contain any irreplaceable files are favoring the "Blocker"style ransomware. ● Kaspersky writes: Blockers are the much more popular means to infect Android devices. On mobiles, they act simply by overlaying the interface of every app with their own, so a victim can’t use any application at all. PC owners can get rid of a blocker with relative ease — all they need to do is remove the hard drive, plug it into another computer, and wipe out the blocker’s files. But you can’t simply remove the main storage from your phone — it’s soldered onto the motherboard. -

Kevin Mitnick and I Were Intensely Curious About the World and Eager to Prove Ourselves
Scanned by kineticstomp THE ART OF DECEPTION Controlling the Human Element of Security KEVIN D. MITNICK & William L. Simon Foreword by Steve Wozniak For Reba Vartanian, Shelly Jaffe, Chickie Leventhal, and Mitchell Mitnick, and for the late Alan Mitnick, Adam Mitnick, and Jack Biello For Arynne, Victoria, and David, Sheldon,Vincent, and Elena. Social Engineering Social Engineering uses influence and persuasion to deceive people by convincing them that the social engineer is someone he is not, or by manipulation. As a result, the social engineer is able to take advantage of people to obtain information with or without the use of technology. Contents Foreword Preface Introduction Part 1 Behind the Scenes Chapter 1 Security's Weakest Link Part 2 The Art of the Attacker Chapter 2 When Innocuous Information Isn't Chapter 3 The Direct Attack: Just Asking for it Chapter 4 Building Trust Chapter 5 "Let Me Help You" Chapter 6 "Can You Help Me?" Chapter 7 Phony Sites and Dangerous Attachments Chapter 8 Using Sympathy, Guilt and Intimidation Chapter 9 The Reverse Sting Part 3 Intruder Alert Chapter 10 Entering the Premises Chapter 11 Combining Technology and Social Engineering Chapter 12 Attacks on the Entry-Level Employee Chapter 13 Clever Cons Chapter 14 Industrial Espionage Part 4 Raising the Bar Chapter 15 Information Security Awareness and Training Chapter 16 Recommended Corporate Information Security Policies Security at a Glance Sources Acknowledgments Foreword We humans are born with an inner drive to explore the nature of our surroundings. As young men, both Kevin Mitnick and I were intensely curious about the world and eager to prove ourselves. -

Building Management System (In) Security
BUILDING MANAGEMENT SYSTEM (IN) SECURITY HVAC building management systems are not immune from the need for computer security and defensive computing. A Visible Example In 2010, a computer virus dubbed Stuxnet was used to attack nuclear enrichment centrifuges at Iran’s Natanz nuclear facility. Widely speculated to be a joint project of the US and Israeli intelligence services, the virus spread worldwide but was designed to only target specific process controllers used to control centrifuges at Iran’s nuclear facility. The process controllers had a simple (and previously known) security vulnerability that allowed them to be reprogrammed by the virus to behave differently than intended–without anyone knowing. The ultimate effect was that a portion of the centrifuges were physically spun out of control causing irreparable damage. The estimated impact of this attack on Iran’s nuclear program varies widely, but some reports state that the damage may have set back progress by up to 18 months. One amazing part of this story is that the equipment was not simply connected to the internet and targeted remotely–the servers were “air-gapped” for security against these exact kinds of threats. Instead, the virus was designed to piggyback on a USB thumb drive from a computer connected to the internet, to one of the secure control servers. English: Symbolic image depicting the computer virus Stuxnet (Photo credit: Wikipedia) The HVAC Connection What does this have to do with HVAC and Energy Efficiency, you may ask? Well, the control systems we use to automate control of commercial buildings (aka BMS or DDC systems) are functionally equivalent (though HVAC-application-specific) versions of these industrial process control systems. -
The Best Way to Disable Autorun for Protection from Infected USB Flash Drives - Computerworld Blogs
The best way to disable Autorun for protection from infected USB flash drives - Computerworld Blogs Virtual Print Subscriptions Ads by TechWords See your link here Subscribe to our e-mail newsletters For more info on a specific newsletter, click the title. Details will be displayed in a new window. Computerworld Daily News (First Look and Wrap-Up) Computerworld Blogs Newsletter The Weekly Top 10 More E-Mail Newsletters Michael Horowitz Defensive Computing More posts | Read bio January 30, 2009 - 3:50 P.M. The best way to disable Autorun for protection from infected USB flash drives 6 comments http://blogs.computerworld.com/the_best_way_to_dis...run_to_be_protected_from_infected_usb_flash_drives (2 of 16) [2/8/2009 1:17:13 AM] The best way to disable Autorun for protection from infected USB flash drives - Computerworld Blogs ● TAGS:Autoplay, autorun, Microsoft, security, Windows ● IT TOPICS:Cybercrime & Hacking, Security Hardware & Software, Software, Windows & Microsoft My first posting on the topic of Autorun/Autoplay, Test your defenses against malicious USB flash drives, described three ways that bad guys trick people into running malicious software that resides on an infected USB flash drive. Although, at times, flash drive resident software can run by itself (think U3 flash drives) without any action on the part of the computer user (other than inserting the USB flash drive) the more normal case is that a person has to be tricked. My first posting on this topic has a sample autorun.inf file that safely illustrates three of these tricks, and you can download this file to test how well your PC is defended from inadvertently running software off the flash drive. -
NYS Senate Public Hearing Cyber Security
NYS Senate Public Hearing Cyber Security: Defending New York from Cyber Attacks Testimony of Benjamin M. Lawsky, Superintendent of Financial Services The Griffiss Institute, Rome, New York November 18, 2013 My name is Benjamin M. Lawskyand I am Superintendent of Financial Services. I also serve as Co-Chair of Governor Cuomo's Cyber Advisory Board. I appreciate the opportunity to present testimony today and thank Senator Griffo and the members of the committee for inviting me and for shining a light on an issue that we all need to focus on to ensure the security of our state and nation. I also want to thank the Chairs of the other committees represented here today, Senators Ball, Gallivan, Golden, Seward and Valesky. Cyber security is a critical issue for all of us as public officials and particularly by virtue of New York's status in the world. New York City is a global and national center of finance and commerce. We are the home of Wall Street and hundreds of corporations with interests in banking, insurance, securities and countless other sectors of the economy. Obviously, New York presents tempting targets for cyber criminals intent on disrupting or even destroying our institutions, or stealing the confidential information of those institutions and their customers. Major New York City-based institutions have already been targeted. Within the past year, the web sites of American Express, JPMorgan Chase, The New York Times, and Citigroup were disrupted in well-publicized cyber-attacks. Today, I will discuss the Cyber Advisory Board appointed by Governor Cuomo last May and the work of the Department of Financial Services (DFS) related to strengthening cyber security in New York's financial services community. -

ARCHIVE 2823.Pdf
ComputorEdge 6/4/10 ComputorEdge™ Online — 06/04/10 This issue: Is Someone Watching with Spyware Software? Stop spyware from "phoning home" to the mothership with your data! Use anti-spyware protection. Table of Contents: Digital Dave by Digital Dave Digital Dave answers your tech questions. Is copying and pasting files to a new hard drive an easy way to defragment files? Also, a primer on the Apple iPad's battery life and instructions on prolonging its use. What Is Spyware and How to Remove It? by Pete Choppin Common sense plus technology can keep your computer safe. Why has the spyware problem gotten so out of hand? And more importantly, what you can do about it to protect your vital data? Spybot Search & Destroy by Michael J. Ross (Click Banner) Cure your PC of nasty malware—for free. To cure your PC of what ails it, you can turn to one of several anti- spyware applications available on the market. One of the most popular and highly regarded freeware alternatives is Spybot Search & Destroy. Windows Tips and Tricks by Jack Dunning The Windows Address Toolbar If you prefer to use the keyboard to directly access Web sites and programs, then the Windows Address toolbar may interest you. 1 of 44 ComputorEdge 6/4/10 Wally Wang's Apple Farm by Wally Wang Spyware on the Macintosh Although the threat of spyware infecting a Macintosh is low, those still worried about Macintosh spyware should consider MacScan. Also, the rise of electronic self-publishing; what will Apple reveal at its annual developers conference?; the iPhone/iPad market seems to be exploding for developers; the multiple technical limitations of Flash; and a tip on switching to Internet radio stations for your listening pleasure. -

Intel's Hyper-Threading So You Bought a New
On the Docket for the General Meeting Thursday, November 18, 2004 Intel’s Hyper-Threading Technology So You Bought a New PC: Now What? yper-Threading Technology is a and get more work done in the same Hgroundbreaking innovation that amount of time. significantly improves processor per- The November general meeting of formance. Pioneered by Intel, Hyper- the New York PC Users Group (NYPC) Threading Technology provides a signif- will feature a presentation about Intel’s Volume 11 Issue 10 icant performance boost which is Hyper-Threading Technology and how it November 2004 particularly suited to today’s business will affect your future computer purchas- computing climate, applications, and ing decisions. Using materials provided operating systems. by Intel, NYPC education chair Fred Kahn will describe the benefits and oper- How Hyper-Threading Works ation of Hyper-Threading technology. Faster clock speeds are an important As a special treat, Intel has provided way to deliver more computing power, NYPC with handouts and a limited num- and Intel has led the way with industry- ber of gifts for those attending this General Meeting Info leading processor frequency. But clock lecture. As always this meeting is free speed is only half the story. The other and open to the general public; all are When: Thursday, November 18, 2004 route to higher performance is to welcome. accomplish more work on each clock Where: PS 41, 116 W 11th Street, cycle, and that’s where Hyper-Threading Thanks to Intel west of 6th Avenue Technology comes in. A single processor We are grateful to Dave and Kathy Whit- Schedule: 6:00pm Doors open supporting Hyper-Threading Technology tle, who work with user groups for Intel, Cafeteria: Networking presents itself to modern operating sys- for arranging this informative meeting.