Semantic Description of Services and Service Factories for Ambient Intelligence Rémi Emonet
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ioc Containers in Spring
301AA - Advanced Programming Lecturer: Andrea Corradini [email protected] http://pages.di.unipi.it/corradini/ AP-2018-11: Frameworks and Inversion of Control Frameworks and Inversion of Control • Recap: JavaBeans as Components • Frameworks, Component Frameworks and their features • Frameworks vs IDEs • Inversion of Control and Containers • Frameworks vs Libraries • Decoupling Components • Dependency Injection • IoC Containers in Spring 2 Components: a recap A software component is a unit of composition with contractually specified interfaces and explicit context dependencies only. A software component can be deployed independently and is subject to composition by third party. Clemens Szyperski, ECOOP 1996 • Examples: Java Beans, CLR Assemblies • Contractually specified interfaces: events, methods and properties • Explicit context dependencies: serializable, constructor with no argument • Subject to composition: connection to other beans – Using connection oriented programming (event source and listeners/delegates) 3 Towards Component Frameworks • Software Framework: A collection of common code providing generic functionality that can be selectively overridden or specialized by user code providing specific functionality • Application Framework: A software framework used to implement the standard structure of an application for a specific development environment. • Examples: – GUI Frameworks – Web Frameworks – Concurrency Frameworks 4 Examples of Frameworks Web Application Frameworks GUI Toolkits 5 Examples: General Software Frameworks – .NET – Windows platform. Provides language interoperability – Android SDK – Supports development of apps in Java (but does not use a JVM!) – Cocoa – Apple’s native OO API for macOS. Includes C standard library and the Objective-C runtime. – Eclipse – Cross-platform, easily extensible IDE with plugins 6 Examples: GUI Frameworks • Frameworks for Application with GUI – MFC - Microsoft Foundation Class Library. -

Design Pattern Interview Questions
DDEESSIIGGNN PPAATTTTEERRNN -- IINNTTEERRVVIIEEWW QQUUEESSTTIIOONNSS http://www.tutorialspoint.com/design_pattern/design_pattern_interview_questions.htm Copyright © tutorialspoint.com Dear readers, these Design Pattern Interview Questions have been designed specially to get you acquainted with the nature of questions you may encounter during your interview for the subject of Design Pattern. As per my experience good interviewers hardly plan to ask any particular question during your interview, normally questions start with some basic concept of the subject and later they continue based on further discussion and what you answer: What are Design Patterns? Design patterns represent the best practices used by experienced object-oriented software developers. Design patterns are solutions to general problems that software developers faced during software development. These solutions were obtained by trial and error by numerous software developers over quite a substantial period of time. What is Gang of Four GOF? In 1994, four authors Erich Gamma, Richard Helm, Ralph Johnson and John Vlissides published a book titled Design Patterns - Elements of Reusable Object-Oriented Software which initiated the concept of Design Pattern in Software development. These authors are collectively known as Gang of Four GOF. Name types of Design Patterns? Design patterns can be classified in three categories: Creational, Structural and Behavioral patterns. Creational Patterns - These design patterns provide a way to create objects while hiding the creation logic, rather than instantiating objects directly using new opreator. This gives program more flexibility in deciding which objects need to be created for a given use case. Structural Patterns - These design patterns concern class and object composition. Concept of inheritance is used to compose interfaces and define ways to compose objects to obtain new functionalities. -

Dependency Injection with Unity
D EPEN DEPENDENCY INJECTION WITH UNITY Over the years software systems have evolutionarily become more and more patterns & practices D ENCY complex. One of the techniques for dealing with this inherent complexity Proven practices for predictable results of software systems is dependency injection – a design pattern that I allows the removal of hard-coded dependencies and makes it possible to Save time and reduce risk on your NJECT assemble a service by changing dependencies easily, whether at run-time software development projects by or compile-time. It promotes code reuse and loosely-coupled design which incorporating patterns & practices, I leads to more easily maintainable and flexible code. Microsoft’s applied engineering ON guidance that includes both production The guide you are holding in your hands is a primer on using dependency quality source code and documentation. W I injection with Unity – a lightweight extensible dependency injection TH DEPENDENCY INJECTION container built by the Microsoft patterns & practices team. It covers The guidance is designed to help U software development teams: various styles of dependency injection and also additional capabilities N I of Unity container, such as object lifetime management, interception, Make critical design and technology TY and registration by convention. It also discusses the advanced topics of selection decisions by highlighting WITH UNITY enhancing Unity with your custom extensions. the appropriate solution architectures, technologies, and Microsoft products The guide contains plenty of trade-off discussions and tips and tricks for for common scenarios managing your application cross-cutting concerns and making the most out of both dependency injection and Unity. These are accompanied by a Understand the most important Dominic Betts real world example that will help you master the techniques. -

Designpatternsphp Documentation Release 1.0
DesignPatternsPHP Documentation Release 1.0 Dominik Liebler and contributors Jul 18, 2021 Contents 1 Patterns 3 1.1 Creational................................................3 1.1.1 Abstract Factory........................................3 1.1.2 Builder.............................................8 1.1.3 Factory Method......................................... 13 1.1.4 Pool............................................... 18 1.1.5 Prototype............................................ 21 1.1.6 Simple Factory......................................... 24 1.1.7 Singleton............................................ 26 1.1.8 Static Factory.......................................... 28 1.2 Structural................................................. 30 1.2.1 Adapter / Wrapper....................................... 31 1.2.2 Bridge.............................................. 35 1.2.3 Composite............................................ 39 1.2.4 Data Mapper.......................................... 42 1.2.5 Decorator............................................ 46 1.2.6 Dependency Injection...................................... 50 1.2.7 Facade.............................................. 53 1.2.8 Fluent Interface......................................... 56 1.2.9 Flyweight............................................ 59 1.2.10 Proxy.............................................. 62 1.2.11 Registry............................................. 66 1.3 Behavioral................................................ 69 1.3.1 Chain Of Responsibilities................................... -
JAVA CONCURRENCY ONLINE TRAINING – Java2aspire
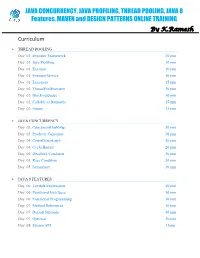
JAVA CONCURRENCY, JAVA PROFILING, THREAD POOLING, JAVA 8 Features, MAVEN and DESIGN PATTERNS ONLINE TRAINING By K.Ramesh Curriculum THREAD POOLING Day 01: Executor Framework 20 min Day 01: Java Profiling 10 min Day 01: Executor 10 min Day 01: ExecutorService 10 min Day 01: Executors 15 min Day 02: ThreadPoolExecutor 20 min Day 02: BlockingQueue 10 min Day 02: Callable vs Runnable 15 min Day 02: Future 15 min JAVA CONCURRENCY Day 03: ConcurrentHashMap 30 min Day 03: Producer Consumer 30 min Day 04: CountDownLatch 20 min Day 04: CyclicBarrier 20 min Day 04: Deadlock Condition 20 min Day 05: Race Condition 30 min Day 05: Semaphore 30 min JAVA 8 FEATURES Day 06: Lambda Expressions 40 min Day 06: Functional Interfaces 10 min Day 06: Functional Programming 10 min Day 07: Method References 10 min Day 07: Default Methods 40 min Day 07: Optional 10 min Day 08: Stream API 1 hour MAVEN Day 09: Project Object Model (POM) 20 min Day 09: Project Description 10 min Day 09: Public Repository 10 min Day 09: Dependency Management 10 min Day 09: Build Configuration 10 min Day 10: Installation 15 min Day 10: Dependency Scope 15 min Day 10: Proprietary Dependencies 15 min Day 10: Project Inheritance 15 min Day 11: Maven life cycle 20 min Day 11: Maven Directory Structure 20 min Day 11: Archetypes 20 min Day 12: Applications 1 hour DESIGN PATTERNS Day 13: Factory Pattern 20 min Day 13: Abstract Factory Pattern 10 min Day 13: Single Pattern 20 min Day 13: Prototype Pattern 10 min Day 14: Composite Pattern 10 min Day 14: Facade Pattern 15 min Day 14: DAO -

Sun Certified Enterprise Architect for Java EE Study Guide / Mark Cade, Humphrey Sheil
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trademark claim, the designations have been printed with initial capital letters or in all capitals. Sun Microsystems, Inc. has intellectual property rights relating to implementations of the technology described in this publication. In particular, and without limitation, these intellectual property rights may include one or more U.S. patents, foreign patents, or pending applications. Sun, Sun Microsystems, the Sun logo, J2ME, J2EE, Java Card, and all Sun and Java based trademarks and logos are trademarks or registered trademarks of Sun Microsystems, Inc., in the United States and other countries. UNIX is a registered trademark in the United States and other countries, exclusively licensed through X/Open Company, Ltd. This publication is provided “as is” without warranty of any kind, either express or implied, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, or non-infringement. This publication could include technical inaccuracies or typographical errors. Changes are periodically added to the information herein; these changes will be incorporated in new editions of the publication. Sun Microsystems, Inc. may make improvements and/or changes in the product(s) and/or the program(s) described in this publication at any time. The authors and publisher have taken care in the preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. -

J2EE Architecture and Patterns in Enterprise Systems
J2EE Architecture and Patterns in Enterprise Systems Zhiguo Guo University of Tampere Department of Computer and Information Science Master’s Thesis May 2004 i University of Tampere Department of Computer and Information Science Zhiguo Guo: J2EE Architecture and Patterns in Enterprise Systems Master’s Thesis, 60 pages May 2004 The purpose of this thesis is to illustrate an enterprise project named HUVA, in which Java Platform 2, Enterprise Edition (J2EE) architecture and patterns are applied. This study took a constructive research approach: It starts from the application domain including the initial plan and business model, then moves to the system architecture covering the architecturally significant requirements and the system structure compliant with J2EE architecture, finally ends at the application design elaborated by applying the J2EE patterns at a high level. As a result the architectural and application design satisfied the project needs and requirements; and the HUVA software has been implemented in practice according to the design. Keywords: J2EE, architecture, pattern, enterprise system. ii Acknowledgements I would like to thank Professor Roope Raisamo and Professor Isto Aho from the University of Tampere for being my encouraging, patient and responsible supervisors during the master’s thesis project. I would like to thank Mr. Mika Miettinen from Solteq Oyj and Mr. Timo Westkämper for supporting the technical aspects of this thesis. Finally, I would like to use this opportunity to express huge thanks to my dear wife, Chongliang Tang for always being the invaluable person behind my success. Tampere - Finland, June 1st, 2004 Zhiguo Guo iii Contents 1. Introduction.............................................................................................................1 2. Application domain ...............................................................................................3 2.1. -

How to Reduce Costs of Business Logic Maintenance
How to reduce costs of business logic maintenance Tomas Cerny Michael J. Donahoo Department of Computer Science and Engineering Department of Computer Science, Czech Technical University, Baylor University, Charles Square 13, Prague, Czech Republic Waco, TX, USA Email: [email protected] Email: jeff [email protected] Abstract—Three tier enterprise applications introduce multiple patterns has grown to multiple categories and spread from challenges for software engineers. Although we can divide the analyzes over design to coding. application into three tiers, we still need to design properly each Besides multiple patterns simplifying designers decisions tier internally to achieve multiple design qualities. The middle business tier captures logic in which we associate objects, validate another innovative contribution and complement to the OOP business rules, etc. Often multiple cross-cutting concerns are appeared known aspect oriented programming (AOP) [9]. mixed in the services which results in bloated, highly coupled de- AOP that introduces the idea of cross-cutting concerns in sign with very low cohesion. In this paper we present a case study objects. These concerns then spread through multiple architec- that we develop based on our four year experience with enterprise tural layers and cannot be isolated with the sole use of OOP. application that struggled from multiple weak design decisions. We emphasize multiple aspects that should be decoupled from AOP defines the location where multiple concerns cross as the rest of the services which increase service cohesion and results a pointcut. This pointcut as reached by the program can use in better readability, maintenance, testability, reuse and error- an additional code (separately defined) known as an advice avoidance. -

Web Applications Engineering: Web Design Patterns and Guideline
Web Applications Engineering: Web Design Patterns and Guideline Service Oriented Computing Group, CSE, UNSW Week 6 References used for the Lecture: http://java.sun.com/blueprints/patterns/index.html Core J2EE patterns, Deepak Alur, John Crupi and Dan Marlks, Prentice Hall Patterns of Enterprise Application Architecture, Martin Fowler, Addison-Wesley H. Paik, S. Venugopal (CSE, UNSW) COMP9321, 14s2 Week 6 1 / 65 J2EE Design Patterns What is a design pattern? Patterns in software were popularised by the book Design Patterns: Elements of Reusable Object-Oriented Software by Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides (aka Gang of Four) They observed and recognised recurring designs in numerous projects and documented this collection Since then many other design patterns are published covering patterns for various domains and purposes J2EE patterns: J2EE patterns represent best practice design based on collective experience of working with J2EE projects Patterns aim to provide and document a solution to a known, recurring problem in building J2EE applications http://java.sun.com/blueprints/patterns/index.html H. Paik, S. Venugopal (CSE, UNSW) COMP9321, 14s2 Week 6 2 / 65 J2EE Design Patterns There are over 20 patterns (and growing). We look at a few patterns that are highly relevant to COMP9321 ... Model View Controller: MVC is the J2EE BluePrints recommended architectural design pattern for interactive applications. Front Controller (Command): For providing a central dispatch point to handle all incoming requests. Service Locator: Typically used in business layer for locating resources (such as database connection) Data Access Object: typical pattern for data access layer (linking the data storage layer with the application) Business Delegate: in business layer H. -
![[ Team Lib ] Crawford and Kaplan's J2EE Design Patterns Approaches](https://docslib.b-cdn.net/cover/3392/team-lib-crawford-and-kaplans-j2ee-design-patterns-approaches-1793392.webp)
[ Team Lib ] Crawford and Kaplan's J2EE Design Patterns Approaches
[ Team LiB ] • Table of Contents • Index • Reviews • Reader Reviews • Errata J2EE Design Patterns By William Crawford, Jonathan Kaplan Publisher: O'Reilly Pub Date: September 2003 ISBN: 0-596-00427-3 Pages: 368 Crawford and Kaplan's J2EE Design Patterns approaches the subject in a unique, highly practical and pragmatic way. Rather than simply present another catalog of design patterns, the authors broaden the scope by discussing ways to choose design patterns when building an enterprise application from scratch, looking closely at the real world tradeoffs that Java developers must weigh when architecting their applications. Then they go on to show how to apply the patterns when writing realworld software. They also extend design patterns into areas not covered in other books, presenting original patterns for data modeling, transaction / process modeling, and interoperability. [ Team LiB ] [ Team LiB ] • Table of Contents • Index • Reviews • Reader Reviews • Errata J2EE Design Patterns By William Crawford, Jonathan Kaplan Publisher: O'Reilly Pub Date: September 2003 ISBN: 0-596-00427-3 Pages: 368 Copyright Preface Audience Organization of This Book For Further Reading Conventions Used in This Book Comments and Questions Acknowledgments Chapter 1. Java Enterprise Design Section 1.1. Design Patterns Section 1.2. J2EE Section 1.3. Application Tiers Section 1.4. Core Development Concepts Section 1.5. Looking Ahead Chapter 2. The Unified Modeling Language Section 2.1. Origins of UML Section 2.2. The Magnificent Seven Section 2.3. UML and Software Development Lifecycles Section 2.4. Use Case Diagrams Section 2.5. Class Diagrams Section 2.6. Interaction Diagrams Section 2.7. -

Autofac Documentation Release 6.0.0
Autofac Documentation Release 6.0.0 Autofac Project Jul 11, 2021 Contents 1 Getting Started 3 1.1 Structuring the Application.......................................3 1.2 Add Autofac References.........................................5 1.3 Application Startup............................................5 1.4 Application Execution..........................................6 1.5 Going Further..............................................8 1.6 Need Help?................................................8 1.7 Building from Source..........................................8 2 What’s New 9 2.1 Release Notes..............................................9 2.2 Upgrading from Autofac 5.x to 6.x................................... 10 2.3 Upgrading from Autofac 3.x to 4.x................................... 12 3 Registering Components 15 3.1 Registration Concepts.......................................... 15 3.1.1 Reflection Components..................................... 16 3.1.2 Instance Components...................................... 17 3.1.3 Lambda Expression Components................................ 17 3.1.4 Open Generic Components................................... 19 3.1.5 Services vs. Components.................................... 19 3.1.6 Default Registrations...................................... 20 3.1.7 Conditional Registration.................................... 20 3.1.8 Configuration of Registrations................................. 22 3.1.9 Dynamically-Provided Registrations.............................. 22 3.2 Passing Parameters to Register..................................... -

1 Layered Architecture
e-gov Architecture Application Architecture 1 Layered Architecture ................................................................................. 3 1.1 Introduction ..................................................................................... 3 1.2 Best practices................................................................................... 3 1.2.1 Choose a layered architecture ......................................................... 3 1.2.2 Apply design patterns to layer the architeture.................................... 6 2 Domain Layer .......................................................................................... 8 2.1 Introduction ..................................................................................... 8 2.2 Best practices................................................................................... 8 2.2.1 Introduce a domain layer in the architecture...................................... 8 2.2.2 Apply design patterns on the domain layer ........................................ 9 2.2.3 Utilize the full power of OO ............................................................10 2.2.4 Avoid the anemic domain model .....................................................10 2.2.5 Minimize the dependencies with other layers ....................................10 2.2.6 Unit test the domain layer..............................................................10 3 Service Layer..........................................................................................11 3.1 Introduction ....................................................................................11