Cranfield University Assessing the Reliability Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cryptographic File Systems Performance: What You Don't Know Can Hurt You Charles P
Cryptographic File Systems Performance: What You Don't Know Can Hurt You Charles P. Wright, Jay Dave, and Erez Zadok Stony Brook University Appears in the proceedings of the 2003 IEEE Security In Storage Workshop (SISW 2003) Abstract interact with disks, caches, and a variety of other com- plex system components — all having a dramatic effect Securing data is more important than ever, yet cryp- on performance. tographic file systems still have not received wide use. In this paper we perform a real world performance One barrier to the adoption of cryptographic file systems comparison between several systems that are used is that the performance impact is assumed to be too high, to secure file systems on laptops, workstations, and but in fact is largely unknown. In this paper we first moderately-sized file servers. We also emphasize multi- survey available cryptographic file systems. Second, programming workloads, which are not often inves- we perform a performance comparison of a representa- tigated. Multi-programmed workloads are becoming tive set of the systems, emphasizing multiprogrammed more important even for single user machines, in which workloads. Third, we discuss interesting and counterin- Windowing systems are often used to run multiple appli- tuitive results. We show the overhead of cryptographic cations concurrently. We expect cryptographic file sys- file systems can be minimal for many real-world work- tems to become a commodity component of future oper- loads, and suggest potential improvements to existing ating systems. systems. We have observed not only general trends with We present results from a variety of benchmarks, an- each of the cryptographic file systems we compared but alyzing the behavior of file systems for metadata op- also anomalies based on complex interactions with the erations, raw I/O operations, and combined with CPU operating system, disks, CPUs, and ciphers. -
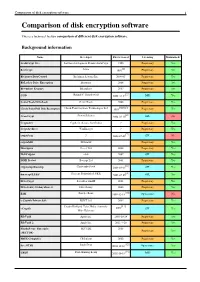
Comparison of Disk Encryption Software 1 Comparison of Disk Encryption Software
Comparison of disk encryption software 1 Comparison of disk encryption software This is a technical feature comparison of different disk encryption software. Background information Name Developer First released Licensing Maintained? ArchiCrypt Live Softwaredevelopment Remus ArchiCrypt 1998 Proprietary Yes [1] BestCrypt Jetico 1993 Proprietary Yes BitArmor DataControl BitArmor Systems Inc. 2008-05 Proprietary Yes BitLocker Drive Encryption Microsoft 2006 Proprietary Yes Bloombase Keyparc Bloombase 2007 Proprietary Yes [2] CGD Roland C. Dowdeswell 2002-10-04 BSD Yes CenterTools DriveLock CenterTools 2008 Proprietary Yes [3][4][5] Check Point Full Disk Encryption Check Point Software Technologies Ltd 1999 Proprietary Yes [6] CrossCrypt Steven Scherrer 2004-02-10 GPL No Cryptainer Cypherix (Secure-Soft India) ? Proprietary Yes CryptArchiver WinEncrypt ? Proprietary Yes [7] cryptoloop ? 2003-07-02 GPL No cryptoMill SEAhawk Proprietary Yes Discryptor Cosect Ltd. 2008 Proprietary Yes DiskCryptor ntldr 2007 GPL Yes DISK Protect Becrypt Ltd 2001 Proprietary Yes [8] cryptsetup/dmsetup Christophe Saout 2004-03-11 GPL Yes [9] dm-crypt/LUKS Clemens Fruhwirth (LUKS) 2005-02-05 GPL Yes DriveCrypt SecurStar GmbH 2001 Proprietary Yes DriveSentry GoAnywhere 2 DriveSentry 2008 Proprietary Yes [10] E4M Paul Le Roux 1998-12-18 Open source No e-Capsule Private Safe EISST Ltd. 2005 Proprietary Yes Dustin Kirkland, Tyler Hicks, (formerly [11] eCryptfs 2005 GPL Yes Mike Halcrow) FileVault Apple Inc. 2003-10-24 Proprietary Yes FileVault 2 Apple Inc. 2011-7-20 Proprietary -

Joseph Migga Kizza Fourth Edition
Computer Communications and Networks Joseph Migga Kizza Guide to Computer Network Security Fourth Edition Computer Communications and Networks Series editor A.J. Sammes Centre for Forensic Computing Cranfield University, Shrivenham Campus Swindon, UK The Computer Communications and Networks series is a range of textbooks, monographs and handbooks. It sets out to provide students, researchers, and nonspecialists alike with a sure grounding in current knowledge, together with comprehensible access to the latest developments in computer communications and networking. Emphasis is placed on clear and explanatory styles that support a tutorial approach, so that even the most complex of topics is presented in a lucid and intelligible manner. More information about this series at http://www.springer.com/series/4198 Joseph Migga Kizza Guide to Computer Network Security Fourth Edition Joseph Migga Kizza University of Tennessee Chattanooga, TN, USA ISSN 1617-7975 ISSN 2197-8433 (electronic) Computer Communications and Networks ISBN 978-3-319-55605-5 ISBN 978-3-319-55606-2 (eBook) DOI 10.1007/978-3-319-55606-2 Library of Congress Control Number: 2017939601 # Springer-Verlag London 2009, 2013, 2015 # Springer International Publishing AG 2017 This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. The use of general descriptive names, registered names, trademarks, service marks, etc. -

Safezone Browser Download Cent Safezone Browser Download Cent
safezone browser download cent Safezone browser download cent. NOT REGISTERED YET? RETRIEVE YOUR PERNUM FOR BETA TESTERS--> PLEASE ENTER YOUR REGISTERED EMAIL. Your PERNUM will be sent to your registered email account. REQUEST PASSWORD FOR BETA TESTERS--> PLEASE ENTER YOUR PERNUM. Your temporary password will be sent to your registered email account. RESET YOUR MASTER PIN FOR BETA TESTERS--> PLEASE ENTER YOUR REGISTERED EMAIL AND SAFEZONE PASSWORD. RESET YOUR MASTER PIN FOR BETA TESTERS--> YOUR REQUEST HAS BEEN RECEIVED. An email has been sent to our Support Team and they will contact you at your registered email for assistance. Please allow up to 48 hours for a response, emails are processed in the order they are received. SET UP YOUR MASTER PIN FOR BETA TESTERS--> PLEASE ENTER YOUR REGISTERED EMAIL AND SAFEZONE PASSWORD. SET UP YOUR MASTER PIN FOR BETA TESTERS--> Your SafeZone Pass is protected by two-step authentication. For every login process, or if you need to change your profile data, you need a one- time pin which has been randomly generated from your 6-digit Master Pin. SET UP YOUR MASTER PIN FOR BETA TESTERS--> Oops! There is already a Master PIN set up for this account. Please either login using your existing Master PIN or you may reset your Master PIN. SET UP YOUR MASTER PIN FOR BETA TESTERS--> Your Master Pin has been set up successfully! Let us test your first One-Time Pin, which is randomly generated from your Master Pin. Please enter the matching digits of your Master Pin: SafeZone APK. SafeZone app is only available at organizations using the SafeZone solution . -

Bestcrypt Base User Manual
BestCrypt Base User Manual Introduction • Introduction • BestCrypt Base Overview • HIPAA Compliance • Main Features 2 Introduction BestCrypt Base is an encryption software developed for small offices with local networks. Most offices do not usually have specially educated administrators to configure network, nor employees have experience of working with security software. BestCrypt Base has been designed to make the encryption process easy for everyone. Getting computers encrypted in a small business local network often becomes a challenge. On the one hand it is good if the encryption software has features of enterprise products such as central storage of recovery data and transparent encryption on users' computers. On the other hand, it would be better if central administration of encryption software for small offices were as simplified as possible. Ideally, a server should not be an expensive upmarket hardware, deployment should be simple, admin's console should be easy to use and require minimum attention. BestCrypt Base software combines features of encryption solutions for enterprise networks with interface simplicity of home software. There is a Key Server in the local network that helps in case of emergency and provides many of the functions proper to enterprise software. The Key Server may be a regular Windows computer or a cheap old computer without hard drive or/ and an operating system. How is it possible? Take a look at BestCrypt Base. It is a user-friendly software made to gurantee the security of your small business. See also: BestCrypt Base overview Main features 3 BestCrypt Base Overview The Introduction article states that BestCrypt Base is designed for small networks with computer users who are not specially trained as Network Administrators. -

Bestcrypt Container Encryption User Manual
BestCrypt Container Encryption User Manual Introduction • Why do you need BestCrypt? • Benefits of BestCrypt • BestCrypt Requirements • BestCrypt Specifications and Limitations 2 Why do you need BestCrypt? BestCrypt is oriented to a wide range of users. Whether you are in business and work with an accounts database, or you are a developer who is designing a new product, or you keep your private correspondence on your computer, you will appreciate a security system that restricts access to your data. With the advent of mass storage systems, a tremendous amount of information can be carried conveniently on even a small notebook computer. What happens to all this information if the computer is stolen at an airport? Suppose someone gains access to your computer without your knowledge. Do you know if your data has been copied and given to someone else? The main advantage of BestCrypt is that it is the most powerful, proven protection tool, based on cutting-edge technology, and available now for public use. Its mathematical basis was developed by outstanding scientists to keep all kinds of classified governmental documents and letters in deep secrecy. BestCrypt has a strong, built-in encryption scheme and contains no "backdoor". A "backdoor" is a feature that allows authorities with legal permission to bypass protection and to access data without the permission of the owner. Many commercial and government-certified systems contain backdoors, but not BestCrypt. The only way to access the data secured by BestCrypt is to have the correct password. 3 Benefits of BestCrypt Strong Security Once written to a BestCrypt file (container), data is never stored in an ‘open’ condition. -

Guide to Computer Forensics and Investigations Fourth Edition
Guide to Computer Forensics and Investigations Fourth Edition Chapter 6 Working with Windows and DOS Systems Objectives • Explain the purpose and structure of file systems • Describe Microsoft file structures • Explain the structure of New Technology File System (NTFS) disks • List some options for decrypting drives encrypted with whole disk encryption Guide to Computer Forensics and Investigations 2 Objectives (continued) • Explain how the Windows Registry works • Describe Microsoft startup tasks • Describe MS-DOS startup tasks • Explain the purpose of a virtual machine Guide to Computer Forensics and Investigations 3 Understanding File Systems • File system – Gives OS a road map to data on a disk • Type of file system an OS uses determines how data is stored on the disk • A file system is usually directly related to an OS • When you need to access a suspect’s computer to acquire or inspect data – You should be familiar with the computer’s platform Guide to Computer Forensics and Investigations 4 Understanding the Boot Sequence • Complementary Metal Oxide Semiconductor (CMOS) – Computer stores system configuration and date and time information in the CMOS • When power to the system is off • Basic Input/Output System (BIOS) – Contains programs that perform input and output at the hardware level Guide to Computer Forensics and Investigations 5 Understanding the Boot Sequence (continued) • Bootstrap process – Contained in ROM, tells the computer how to proceed – Displays the key or keys you press to open the CMOS setup screen • CMOS should -

Key Management for Transcrypt
Key Management for Transcrypt by Abhijit Bagri DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING INDIAN INSTITUTE OF TECHNOLOGY, KANPUR May 2007 i Key Management for TransCrypt A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Technology by Abhijit Bagri to the DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING INDIAN INSTITUTE OF TECHNOLOGY,KANPUR May 2007 ii CERTIFICATE It is certified that the work contained in the thesis entitled " Key Management for 1ran- sCrypt" by Abhijit Bagri has been carried out under my supervision and that this work has not been submitted elsewhere for a degree. Dr. Rajat Moona Dr. Dheeraj Sanghi Department of Computer Science Department of Computer Science & Engineering, & Engineering, Indian Institute of Technology Kanpur, Indian Institute of Technology Kanpur, Kanpur-208016. Kanpur-208016. iii Abstract With data storage and processing snowballing into a necessity from being an efficient part of any business process or organization, the need for securing storage at various degrees of granularity is gaining considerable interest. The challenge in designing an encrypted filesys- tem stems from balancing performance, security perception, ease of usage and enterprise level deployability. Often, the most secure solutions may not even be the best solution either due to hit on performance or due to decreased usability. Further, narrowing the trust circle to exclude even hitherto trusted system administrators makes creating an encrypted filesystem a huge engineering exercise. In this thesis, we talk about key management issues in TransCrypt[21], an encrypted file system design with smallest trust circle to the best of our knowledge. We provide an entire architecture with utilities like secure key stores, and their management through libraries in- side and outside the kernel space. -

Bestcrypt Container Encryption Help File
BestCrypt Container Encryption Help File Introduction Introduction Why do you need BestCrypt? Benefits of BestCrypt BestCrypt Requirements BestCrypt Specifications and Limitations 2 Introduction The BestCrypt Data Encryption system provides the most comprehensive and easy-to-use secure data storage and access control facilities available. BestCrypt’s data encryption method uses encryption algorithms known world-wide and provides unparalleled protection against unauthorized data access. BestCrypt is easy to install, easy to use and totally transparent for application programs. Your data is BestCrypt’s only concern, and it enhances your basic right to keep documents, commercial proprietary knowledge, and private information, in a confidential fashion. See also: Benefits of BestCrypt BestCrypt Requirements BestCrypt Specifications and Limitations 3 Why do you need BestCrypt? BestCrypt is oriented to a wide range of users. Whether you are in business and work with an accounts database, or you are a developer who is designing a new product, or you keep your private correspondence on your computer, you will appreciate a security system that restricts access to your data. With the advent of mass storage systems, a tremendous amount of information can be carried conveniently on even a small notebook computer. What happens to all this information if the computer is stolen at an airport? Suppose someone gains access to your computer without your knowledge. Do you know if your data has been copied and given to someone else? What about the information retained on floppy disks? On portable hard drives? On network drives, where administrators and maybe others can read all unencrypted files? Of course, there are a number of security systems offered for computers, but here is the most important point: The main advantage of BestCrypt is that it is the most powerful, proven protection tool, based on cutting-edge technology, and available now for public use. -

Genian-Nac-Admin-Guide.Pdf
Genian NAC GENIANS, INC. Sep 08, 2021 DEPLOYMENT GUIDE 1 Deployment Overview 3 2 Phase 1 - Network Surveillance / Visibility 5 3 Phase 2 - Plan / Design 7 4 Phase 3 - Configure 9 5 Phase 4 - Test / Validate 11 6 Phase 5 - Expand Deployment 13 7 Understanding Network Access Control 15 8 Deploying Genian NAC 21 9 Installing Genian NAC 47 10 Monitoring Network Assets 71 11 Controlling Network Access 111 12 Managing On-boarding Process 175 13 Managing User Authentication 187 14 Controlling Endpoints with Agent 215 15 Detecting Anomalies 287 16 Managing Logs and Events 303 17 Managing Systems 317 18 API Guide 361 19 Log Format 363 20 Node Group Templates 365 21 Frequently Asked Questions 367 22 Troubleshooting 369 i 23 Release Notes 405 24 Security Advisories 459 25 Service Level Agreement 461 ii Genian NAC DEPLOYMENT GUIDE 1 Genian NAC 2 DEPLOYMENT GUIDE CHAPTER ONE DEPLOYMENT OVERVIEW There are 5 recommended phases for Network Access Control (NAC) deployment. • Phase 1 - Network Surveillance / Visibility • Phase 2 - Plan / Design • Phase 3 - Configure • Phase 4 - Test / Validate • Phase 5 - Expand Deployment Following the steps documented in the various phases will allow Administrators with any level of experience with NAC to successfully deploy the Genian NAC Solution. While not every specific use case or edge condition is addressed, the steps outlined in each phase cover the most common deployment scenarios and use cases for NAC. 3 Genian NAC 4 Chapter 1. Deployment Overview CHAPTER TWO PHASE 1 - NETWORK SURVEILLANCE / VISIBILITY Gaining visibility into the network will allow Administrators to understand what nodes are active on the network by various information including IP, MAC, Platform Type, Location, Ownership and Status. -

Jetico User Manual
BestCrypt Container Encryption Enterprise Edition Administrator Guide Introduction • Introduction • Why do you need BestCrypt Container Encryption? • Benefits of BestCrypt • BestCrypt Container Encryption Enterprise Requirements • BestCrypt Container Encryption Specifications and Limitations 2 Introduction BestCrypt Container Encryption Enterprise is a set of utilities and software modules that provides a central administrating of the BestCrypt Container Encryption software, installed on remote client computers. BestCrypt Container Encryption Enterprise includes Jetico Central Manager (Database and Console) and BestCrypt Container Encryption client software. BestCrypt Container Encryption data encryption software can be installed on Windows client computers. It allows the user to keep any form of data (files, letters, pictures, databases) in encrypted form on the hard disk, networks disks, removable disks, CD-ROM’s and floppies. BestCrypt Container Encryption then lets the user to access it from any application. Main features of the BestCrypt Container Encryption Enterprise software: • Provides automatic installation of BestCrypt Container Encryption on remote client computers • Automatic update of the software on remote client computers • Automatic uninstallation of the software from client computers • Access Jetico Central Manager Database from local or remote Windows computer • Jetico Central Manager does not require installation of additional Microsoft® products, like database servers, Internet Information Server or others • Control -

Encase Forensic & Tableau V20.2 Release
EnCase Forensic & Tableau v20.2 Release OpenText commitment to Digital Forensics May 2020 OpenText Confidential. ©2020 All Rights Reserved. 1 Today’s Speakers Ashley Page Stephen Gregory Forensic Account Executive Sr. Principal Solutions Consultant [email protected] [email protected] OpenText Confidential. ©2020 All Rights Reserved. 2 EnCase v8 Releases – Quick Recap 8.05 8.06 • Mobile acquisition * • Lucene® index and search technology * 25,000 different device types, including • Search using standard Lucene syntax mobile phones, drones and smart devices • Enhanced Indexing performance • Bookmarking a document as an image • Index and search in multiple languages (20) 8.07 8.08 ® • Mac APFS Support * • Office 365® email and Exchange connectors* • Encryption/decryption updates • Encryption/decryption updates • Windows Volume Shadow Copy support * • MS Edge® internet artifacts • Add word delimiters to Search Index • Mac OS X ram and process acquisition • APFS encryption support (APFS, FileVault2)* OpenText Confidential. ©2020 All Rights Reserved. 3 EnCase v8 Releases – Quick Recap 8.09 8.10 • Improved –logging and auditing * • Performance Improvements * • Microsoft® PST 2013, 2016, 365 support * • Lucene Indexing & stability improvements • Firefox® artifact update • Parse OST files • Linux ram and process acquisition • Analyze Apple Time APFS Snapshot * • Enhanced Help file options • Direct access to App Central from UI • EnCase Mobile Acquisition enhancements * 8.11 • OpenText Media Analyzer module * • Bug Fixes • Performance improvements • OS Support OpenText Confidential. ©2020 All Rights Reserved. 4 Global Internet adoption and devices and connection Nearly two-thirds of the global Devices connected to IP networks Over 70 % of the global population population will have Internet access will be more than three times the will have mobile connectivity by by 2023.