A Guide to Visual Multi-Level Interface Design from Synthesis of Empirical Study Evidence
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Spot-Tracking Lens: a Zoomable User Interface for Animated Bubble Charts
Spot-Tracking Lens: A Zoomable User Interface for Animated Bubble Charts Yueqi Hu, Tom Polk, Jing Yang ∗ Ye Zhao y Shixia Liu z University of North Carolina at Charlotte Kent State University Tshinghua University Figure 1: A screenshot of the spot-tracking lens. The lens is following Belarus in the year 1995. Egypt, Syria, and Tunisia are automatically labeled since they move faster than Belarus. Ukraine and Russia are tracked. They are visible even when they go out of the spotlight. The color coding of countries is the same as in Gapminder[1], in which countries from the same geographic region share the same color. The world map on the top right corner provides a legend of the colors. ABSTRACT thus see more details. Zooming brings many benefits to visualiza- Zoomable user interfaces are widely used in static visualizations tion: it allows users to examine the context of an interesting object and have many benefits. However, they are not well supported in by zooming in the area where the object resides; labels overcrowded animated visualizations due to problems such as change blindness in the original view can be displayed without overlaps after zoom- and information overload. We propose the spot-tracking lens, a new ing in; it allows users to focus on a local area and thus reduce their zoomable user interface for animated bubble charts, to tackle these cognitive load. problems. It couples zooming with automatic panning and provides In spite of these benefits, zooming is not as well supported in an- a rich set of auxiliary techniques to enhance its effectiveness. -

Organizing Windows Desktop/Workspace
Organizing Windows Desktop/Workspace Instructions Below are the different places in Windows that you may want to customize. On your lab computer, go ahead and set up the environment in different ways to see how you’d like to customize your work computer. Start Menu and Taskbar ● Size: Click on the Start Icon (bottom left). As you move your mouse to the edges of the Start Menu window, your mouse icon will change to the resize icons . Click and drag the mouse to the desired Start Menu size. ● Open Start Menu, and “Pin” apps to the Start Menu/Taskbar by finding them in the list, right-clicking the app, and select “Pin to Start” or “More-> “Pin to Taskbar” OR click and drag the icon to the Tiles section. ● Drop “Tiles” on top of each other to create folders of apps. ● Right-click on Tiles (for example the Weather Tile), and you can resize the Tile (maybe for apps you use more often), and also Turn On live tiles to get updates automatically in the Tile (not for all Tiles) ● Right-click applications in the Taskbar to view “jump lists” for certain applications, which can show recently used documents, visited websites, or other application options. ● If you prefer using the keyboard for opening apps, you probably won’t need to customize the start menu. Simply hit the Windows Key and start typing the name of the application to open, then hit enter when it is highlighted. As the same searches happen, the most used apps will show up as the first selection. -

Citrix VDI—Opening and Closing
How To: Citrix VDI—Opening and Closing In order to provide better and more efficient administration of the GIS Citrix environment, a new means of access is being implemented. Once this new process is in place, the current means of GIS Citrix access will no longer be available. Users can access multiple programs via the new Citrix VDI (Virtual Desktop Infrastructure). In this exercise, direction will be provided to: 1) access the new Citrix VDI environment, 2) login to ArcFM, 3) retrieve a stored display, and 4) properly exit the system. Access Citrix VDI 1. Open an Internet Explorer window. 2. Type the following URL: http://citrix.cpsenergy.com 3. Select Enter on your keyboard. Note: Consider saving the URL as a favorite, such as “ GIS Citrix Receiver.” 4. When the Citrix application opens, select DESKTOPS from the top menu bar. 5. Click on Details to create the Prod VDI—Corp icon as a Favorite. 6. Click “Add to Favorites” then click “Open” to continue. 7. Use your NT username and password to sign in. The Prod VDI-Corp Desktop will then open and resemble the following image. 2 Notes: If your mouse pointer is not showing in the VDI screen, simply click into the area and the pointer will appear. If an MSN.com website loads, close it out. At the top of the Desktop is the XenDesktop toolbar. 8. Select and review the XenDesktop toolbar. A variety of tool tasks will appear. Select “Home” to minimize the VDI and return to the local desktop home screen. 3 Note: An initial DPI screen resolution setting is required for first time users. -

Tracking Menus
Tracking Menus George Fitzmaurice, Azam Khan, Robert Pieké, Bill Buxton, Gordon Kurtenbach Alias|wavefront 210 King Street East Toronto, Ontario M5A 1J7, Canada E-mail: {gf | akhan | rpieke | gordo}@aw.sgi.com; [email protected] ABSTRACT We describe a new type of graphical user interface widget, In keyboard-based systems, alternate ways of switching known as a “tracking menu.” A tracking menu consists of a between tools (keyboard accelerator techniques) are cluster of graphical buttons, and as with traditional menus, typically provided to reduce travel time. For example, in the cursor can be moved within the menu to select and Adobe Photoshop, a very popular feature is an accelerator interact with items. However, unlike traditional menus, technique in which the system switches from the current when the cursor hits the edge of the menu, the menu moves tool to the pan tool when the user depresses the space bar to continue tracking the cursor. Thus, the menu always key. Thus, trips to and from the tool palette are not stays under the cursor and close at hand. necessary to use the panning tool. In this paper we define the behavior of tracking menus, In pen-only systems, there is no keyboard available and show unique affordances of the widget, present a variety of therefore other techniques are required to reduce travel examples, and discuss design characteristics. We examine time. A pen-barrel button could be used to switch tools but one tracking menu design in detail, reporting on usability these buttons are often mistakenly pressed, causing an studies and our experience integrating the technique into a error, or are very awkward to press. -

A Stochastic Approach to “Dynamic-Demand” Refrigerator Control David Angeli, Senior Member, IEEE, and Panagiotis-Aristidis Kountouriotis
IEEE TRANSACTIONS ON CONTROL SYSTEMS TECHNOLOGY, VOL. 20, NO. 3, MAY 2012 581 A Stochastic Approach to “Dynamic-Demand” Refrigerator Control David Angeli, Senior Member, IEEE, and Panagiotis-Aristidis Kountouriotis Abstract—Dynamic demand management is a very promising In order for such (supply) regulation to be possible, however, research direction for improving power system resilience. This it is required that “frequency response services”, as well as suffi- paper considers the problem of managing power consumption by cient reserves, are included in the system.1 This is essential not means of “smart” thermostatic control of domestic refrigerators. In this approach, the operating temperature of these appliances only for instantaneous frequency balancing, but, more impor- and thus their energy consumption, is modified dynamically, tantly, for the ability to respond to sudden power plant failures, within a safe range, in response to mains frequency fluctuations. which would otherwise lead to severe blackouts. Previous research has highlighted the potential of this idea for From an economic perspective, frequency response services responding to sudden power plant outages. However, deterministic and reserve power are costly and any method which manages control schemes have proved inadequate as individual appliances tend to “synchronize” with each other, leading to unacceptable to reduce the magnitude of these services, without sacrificing levels of overshoot in energy demand, when they “recover” their system stability, is of significant importance [16]. In recent steady-state operating cycles. In this paper we design decentral- years, research has been initiated on the possibility of using ized random controllers that are able to respond to sudden plant frequency responsive loads, commonly referred to as “dynamic outages and which avoid the instability phenomena associated demand control”, so as to reduce the amount of frequency with other feedback strategies. -

Maplex Tutorial
Maplex Tutorial Copyright © 1995-2010 Esri All rights reserved. Maplex Tutorial Table of Contents Introduction to the Maplex tutorial . 3 Exercise 1: Enabling Maplex for ArcGIS and adding the Labeling toolbar . 4 Exercise 2: Labeling the parcels with their serial and parcel numbers . 9 Exercise 3: Labeling the parcel boundaries with their length . 17 Exercise 4: Labeling the streets with their names . 24 Copyright © 1995-2010 Esri. All rights reserved. 2 Maplex Tutorial Introduction to the Maplex tutorial Introducing the Maplex tutorial A good way to learn how to use ESRI's Maplex for ArcGIS is to work through the process of labeling a map. This tutorial introduces you to some labeling techniques in the context of mapping land parcels and streets. In this tutorial, you will use Maplex for ArcGIS to do the following: • Improve labels for parcel features by stacking and reducing the size of the labels. • Place labels for parcel boundary features by aligning them to their features and reducing their size. • Improve label placements for street features by applying a labeling style and an abbreviation dictionary. Tutorial data The exercises in this tutorial use the tutorial data distributed with Maplex for ArcGIS. The default installation location of the data is C:\ArcGIS\ArcTutor\Maplex. In this tutorial • Exercise 1: Enabling Maplex for ArcGIS and adding the Labeling toolbar • Exercise 2: Labeling the parcels with their serial and parcel numbers • Exercise 3: Labeling the parcel boundaries with their length • Exercise 4: Labeling the streets with their names Copyright © 1995-2010 Esri. All rights reserved. 3 Maplex Tutorial Exercise 1: Enabling Maplex for ArcGIS and adding the Labeling toolbar Imagine that you work for a small city and you need to make a map for the Complexity: Beginner assessor. -

Augmented Reality In-Situation Menu of 3D Models
17 Augmented Reality In-Situation Menu of 3D Models Thuong N. Hoang Wearable Computer Lab – University of South Australia [email protected] Abstract range of innovative 3D modeling techniques, including construction of 3D geometry using carving We present a design and implementation of an in- planes [2] and constructive solid geometry with situation menu system for loading and visualizing 3D boolean operators for creating complex 3D objects [3]. models in the physical world context. The menu Pinch gloves are the main input devices for system uses 3D objects as menu items, and is directly Tinmith, with fiducial markers placed on the thumbs placed within the context of the augmented for the control of two cursors. Tinmith hand cursors environment, to support visualizing and placing 3D are detected if the user brings the markers into view of models into the augmented world. The menu system the video camera, located on top of the HMD helmet. employs a collection of techniques for the placement The conductive pads on the fingers and palms of the of 3D models in one of three relative coordinate pinch gloves are used for menu command execution. systems: head, body, and world. The in-situ menu also The command menu system is located on both left and serves as a 3D model selection/placement tool and a right lower corners of the display with 10 options collaborative feature between an outdoor AR user and available at any time, each of which is mapped a desktop user. The insitu menu system extends the directly to the fingers on the corresponding pinch current Tinmith menu and modeling system. -

Supply Chain Packaging Guide
Secondary Packaging Supply Chain Standards July 7, 2021 Business Confidential | ©2021 Walmart Stores, Inc. 177 // 338 Secondary Packaging Supply Chain Standards - Update Summary These standards have included multiple clarifications of what is required and what is NOT ALLOWED. These changes have been updated throughout the published standards to provide clarity to suppliers. The pages have been reorganized to provide a better flow. PAGE 2021 UPDATES Changes to Supply Chain Standards 185 SQEP Phase 2 and Phase 3 Defect Description/Definitions Added 202 General Case Markings Updated for Dates, Unprocessed Meats, and Cylindrical Items 210-213 Updated Pallet Standards 218 Update "Palletized Shipments" to "Unitized Shipments" 227 Add Inbound Appointment Scheduling Standard 228 Update TV Test Standards 235-237 Add Direct Store Delivery (DSD) aka Direct To Store (DTS) Standards 239 Update SIOC Standards 240 Add eCommerce Product Specific Requirement Standards 241-244 Add Drop Ship Vendor (DSV) Standards 268 Add Jewelry Distribution Center Standards 269-271 Add Optical Distribution Center Standards 275 Add Goods Not For Resale (GNFR) Standards 277-278 Update Meat/Poultry/Seafood Case and Pallet Label Standards 284 Add HACCP Pallet Placard for GCC Shipments 311-312 Add Frozen Seafood Carton Marking Requirements Appendix D Update Receiving Pulp Temperature Range Business Confidential | © 2021 Walmart Stores, Inc. The examples shown are for reference only. Supply Chain Standards 178 // 338 Table of Contents Supply Chain Stretch Wrap . 219 Produce Shipments . 280 Contact Information . 179 Trailer Loading . 220 Automated Grocery Handling . 281 Walmart Retail Link Resources . 180 Trailer Measurements. 221 Grocery Import Distribution Center (GIDC) . 282 Walmart Distribution Center Overview . -

Getting Started with Arcgis: Labeling Features in Arcmap
Getting Started with ArcGIS Labeling Features in ArcMap By Monica Pratt, ArcUser Editor A label is any text that identifies a feature on a map and helps the map reader interpret a map. In ArcMap, you can use labeling or annota- tion to identify features. The choice of annota- tion or labeling depends on how much control you need over text display and how you would like to store text in ArcMap. See “Labeling Options in ArcMap,” another article in this issue, for a discussion of the pros and cons of each method for identifying features. If you are using labeling, the features you will label will depend on the type of data being displayed and how the map will be used. These considerations will help you decide which labeling method to use in a given sit- uation. You can use the Text tool to label a few features, or you can take advantage of the functionality built into ArcMap to label fea- tures—interactively or dynamically—based on attribute data associated with a layer. Labels can be added without referencing an attribute table by using the Text tool. One by One 7. To adjust the position of a label, place Although a value stored in an attribute table the cursor over the label, hold down the field typically supplies the information for a left mouse key, and drag the label to a new label (e.g., the name Angola could be a value location. for a field that contains the names of coun- tries), labels can be added without referencing Label Specific Features an attribute table by using the Text tool. -
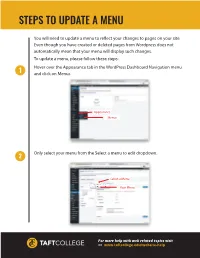
Steps to Update a Menu
STEPS TO UPDATE A MENU You will need to update a menu to reect your changes to pages on your site. Even though you have created or deleted pages from Wordpress does not automatically mean that your menu will display such changes. To update a menu, please follow these steps: Hover over the Appearance tab in the WordPress Dashboard Navigation menu and click on Menus Appearance Menus Only select your menu from the Select a menu to edit dropdown. 2 Select a Menu Your Menu For more help with web related topics visit >> www.taftcollege.edu/website-help STEPS TO UPDATE A MENU Locate the pane entitled Pages. Within this pane, select the View All link to 3 bring up a list of all the currently published Pages on your site. Select the Pages that you want to add by clicking the checkbox next to each Page's title. Click the Add to Menu button located at the bottom of this pane to add your selection(s). Pages Pane New Page Add to Menu Once your page has been added to the menu, you can create multi-levels. To 4 do create multi-levels, position the mouse over the 'child' page, whilst holding the left mouse button, drag it to the right adn underneath the ‘parent’ page. Release the mouse button. Menu Multi-level { Child Page For more help with web related topics visit >> www.taftcollege.edu/website-help STEPS TO UPDATE A MENU Click Save Menu 6 Save Menu How To Delete A Menu Item Locate the menu item that you want to remove in the menu editor window 6 Click on the arrow icon in the top right-hand corner of the menu item/box to expand it. -

Design of a Graphical User Inter- Face Decision Support System for a Vegetated Treatment System 1S.R
DESIGN OF A GRAPHICAL USER INTER- FACE DECISION SUPPORT SYSTEM FOR A VEGETATED TREATMENT SYSTEM 1S.R. Burckhard, 2M. Narayanan, 1V.R. Schaefer, 3P.A. Kulakow, and 4B.A. Leven 1Department of Civil and Environmental Engineering, South Dakota State University, Brookings, SD 57007; Phone: (605)688-5316; Fax: (605)688-5878. 2Department of Comput- ing and Information Sciences, Kansas State University, Manhattan, KS 66506; Phone: (785)532-6350; Fax: (785)532-5985. 3Agronomy Department, Kansas State University, Manhattan, KS 66506; Phone: (785)532-7239; Fax: (785)532-6094. 4Great Plains/Rocky Mountain Hazardous Substance Research Center, Kansas State University, Manhattan, KS 66506; Phone: (785)532-0780; Fax: (785)532-5985. ABSTRACT The use of vegetation in remediating contaminated soils and sediments has been researched for a number of years. Positive laboratory results have lead to the use of vegetation at field sites. The design process involved with field sites and the associated decision processes are being developed. As part of this develop- ment, a computer-based graphical user interface decision support system was designed for use by practicing environmental professionals. The steps involved in designing the graphical user interface, incorporation of the contaminant degradation model, and development of the decision support system are presented. Key words: phytoremediation, simulation INTRODUCTION Vegetation has been shown to increase the degradation of petroleum and organic contaminants in contaminated soils. Laboratory experiments have shown promising results which has led to the deployment of vegetation in field trials. The design of field trials is different than the design of a treatment system. In a field trial, the type of vegetation, use of amendments, placement and division of plots, and monitoring requirements are geared toward producing statistically measurable results. -

1 Lecture 15: Animation
Lecture 15: Animation Fall 2005 6.831 UI Design and Implementation 1 1 UI Hall of Fame or Shame? Suggested by Ryan Damico Fall 2005 6.831 UI Design and Implementation 2 Today’s candidate for the Hall of Shame is this entry form from the 1800Flowers web site. The purpose of the form is to enter a message for a greeting card that will accompany a delivered flower arrangement. Let’s do a little heuristic evaluation of this form: Major: The 210 character limit is well justified, but hard for a user to check. Suggest a dynamic %-done bar showing how much of the quota you’ve used. (error prevention, flexibility & efficiency) Major: special symbols like & is vague. What about asterisk and hyphen – are those special too? What am I allowed to use, exactly? Suggest highlighting illegal characters, or beeping and not allowing them to be inserted. (error prevention) Cosmetic: the underscores in the Greeting Type drop-down menu look like technical identifiers, and some even look mispelled because they’ve omitted other punctuation. Bosss_Day? (Heuristic: match the real world) Major: how does Greeting Type affect card? (visibility, help & documentation) Cosmetic: the To:, Message,: and From: captions are not likely to align with what the user types (aesthetic & minimalist design) 2 Today’s Topics • Design principles • Frame animation • Palette animation • Property animation • Pacing & path Fall 2005 6.831 UI Design and Implementation 3 Today we’re going to talk about using animation in graphical user interfaces. Some might say, based on bad experiences with the Web, that animation has no place in a usable interface.