Modelling Binding Preferences of RNA-Binding Proteins
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Large-Scale Analysis of Genome and Transcriptome Alterations in Multiple Tumors Unveils Novel Cancer-Relevant Splicing Networks
Downloaded from genome.cshlp.org on September 28, 2021 - Published by Cold Spring Harbor Laboratory Press Research Large-scale analysis of genome and transcriptome alterations in multiple tumors unveils novel cancer-relevant splicing networks Endre Sebestyén,1,5 Babita Singh,1,5 Belén Miñana,1,2 Amadís Pagès,1 Francesca Mateo,3 Miguel Angel Pujana,3 Juan Valcárcel,1,2,4 and Eduardo Eyras1,4 1Universitat Pompeu Fabra, E08003 Barcelona, Spain; 2Centre for Genomic Regulation, E08003 Barcelona, Spain; 3Program Against Cancer Therapeutic Resistance (ProCURE), Catalan Institute of Oncology (ICO), Bellvitge Institute for Biomedical Research (IDIBELL), E08908 L’Hospitalet del Llobregat, Spain; 4Catalan Institution for Research and Advanced Studies, E08010 Barcelona, Spain Alternative splicing is regulated by multiple RNA-binding proteins and influences the expression of most eukaryotic genes. However, the role of this process in human disease, and particularly in cancer, is only starting to be unveiled. We system- atically analyzed mutation, copy number, and gene expression patterns of 1348 RNA-binding protein (RBP) genes in 11 solid tumor types, together with alternative splicing changes in these tumors and the enrichment of binding motifs in the alter- natively spliced sequences. Our comprehensive study reveals widespread alterations in the expression of RBP genes, as well as novel mutations and copy number variations in association with multiple alternative splicing changes in cancer drivers and oncogenic pathways. Remarkably, the altered splicing patterns in several tumor types recapitulate those of undifferen- tiated cells. These patterns are predicted to be mainly controlled by MBNL1 and involve multiple cancer drivers, including the mitotic gene NUMA1. We show that NUMA1 alternative splicing induces enhanced cell proliferation and centrosome am- plification in nontumorigenic mammary epithelial cells. -

FUSIP1 Polyclonal Antibody Catalog Number PA5-41929 Product Data Sheet
Lot Number: A9C701N Website: thermofisher.com Customer Service (US): 1 800 955 6288 ext. 1 Technical Support (US): 1 800 955 6288 ext. 441 thermofisher.com/contactus FUSIP1 Polyclonal Antibody Catalog Number PA5-41929 Product Data Sheet Details Species Reactivity Size 100 µl Tested species reactivity Equine, Guinea Pig, Human, Mouse, Host / Isotype Rabbit IgG Rabbit, Rat Class Polyclonal Tested Applications Dilution * Type Antibody Immunohistochemistry (Paraffin) 4-8 µg/mL (IHC (P)) Immunogen Synthetic peptide directed towards the C-terminal of human FUSIP1 Western Blot (WB) 0.2-1 µg/mL Conjugate Unconjugated * Suggested working dilutions are given as a guide only. It is recommended that the user titrate the product for use in their own experiment using appropriate negative and positive controls. Form Liquid Concentration 0.5mg/mL Purification Affinity Chromatography Storage Buffer PBS with 2% sucrose Contains 0.09% sodium azide Storage Conditions -20° C, Avoid Freeze/Thaw Cycles Product Specific Information Peptide sequence: TDSKTHYKSG SRYEKESRKK EPPRSKSQSR SQSRSRSKSR SRSWTSPKSS Sequence homology: Guinea Pig: 100%; Horse: 100%; Human: 100%; Mouse: 100%; Rabbit: 100%; Rat: 100% Background/Target Information FUSIP1 is a member of the serine-arginine (SR) family of proteins, which is involved in constitutive and regulated RNA splicing. Members of this family are characterized by N-terminal RNP1 and RNP2 motifs, which are required for binding to RNA, and multiple C-terminal SR/RS repeats, which are important in mediating association with other cellular proteins. This protein can influence splice site selection of adenovirus E1A pre-mRNA. It interacts with the oncoprotein TLS, and abrogates the influence of TLS on E1A pre-mRNA splicing.This gene product is a member of the serine-arginine (SR) family of proteins, which is involved in constitutive and regulated RNA splicing. -

FUSIP1 (SRSF10) (NM 006625) Human Tagged ORF Clone Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for RC221759 FUSIP1 (SRSF10) (NM_006625) Human Tagged ORF Clone Product data: Product Type: Expression Plasmids Product Name: FUSIP1 (SRSF10) (NM_006625) Human Tagged ORF Clone Tag: Myc-DDK Symbol: SRSF10 Synonyms: FUSIP1; FUSIP2; NSSR; PPP1R149; SFRS13; SFRS13A; SRp38; SRrp40; TASR; TASR1; TASR2 Vector: pCMV6-Entry (PS100001) E. coli Selection: Kanamycin (25 ug/mL) Cell Selection: Neomycin ORF Nucleotide >RC221759 ORF sequence Sequence: Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGTCCCGCTACCTGCGTCCCCCCAACACGTCTCTGTTCGTCAGGAACGTGGCCGACGACACCAGGTCTG AAGACTTGCGGCGTGAATTTGGTCGTTATGGTCCTATAGTTGATGTGTATGTTCCACTTGATTTCTACAC TCGCCGTCCAAGAGGATTTGCTTATGTTCAATTTGAGGATGTTCGTGATGCTGAAGACGCTTTACATAAT TTGGACAGAAAGTGGATTTGTGGACGGCAGATTGAAATACAGTTTGCCCAGGGGGATCGAAAGACACCAA ATCAGATGAAAGCCAAGGAAGGGAGGAATGTGTACAGTTCTTCACGCTATGATGATTATGACAGATACAG ACGTTCTAGAAGCCGAAGTTATGAAAGGAGGAGATCAAGAAGTCGGTCTTTTGATTACAACTATAGAAGA TCGTATAGTCCTAGAAACAGTAGACCGACTGGAAGACCACGGCGTAGCAGAAGCCATTCCGACAATGATA GACCAAACTGCAGCTGGAATACCCAGTACAGTTCTGCTTACTACACTTCAAGAAAGATC ACGCGTACGCGGCCGCTCGAGCAGAAACTCATCTCAGAAGAGGATCTGGCAGCAAATGATATCCTGGATT ACAAGGATGACGACGATAAGGTTTAA Protein Sequence: >RC221759 protein sequence Red=Cloning site Green=Tags(s) MSRYLRPPNTSLFVRNVADDTRSEDLRREFGRYGPIVDVYVPLDFYTRRPRGFAYVQFEDVRDAEDALHN -

Overlap of Quantitative Trait Loci for Early Growth Rate, and for Body
REPRODUCTIONRESEARCH Functional reconstruction of NANOS3 expression in the germ cell lineage by a novel transgenic reporter reveals distinct subcellular localizations of NANOS3 Masashi Yamaji1, Takashi Tanaka2, Mayo Shigeta1, Shinichiro Chuma2, Yumiko Saga3 and Mitinori Saitou1,4,5 1Laboratory for Mammalian Germ Cell Biology, RIKEN Center for Developmental Biology, 2-2-3 Minatojima- Minamimachi, Chuo-ku, Kobe 650-0047, Japan, 2Department of Development and Differentiation, Institute for Frontier Medical Sciences, Kyoto University, Shogoin, Sakyo-ku, Kyoto 606-8507, Japan, 3Department of Genetics and Division of Mammalian Development, National Institute of Genetics, SOKENDAI, 1111 Yata, Mishima, Shizuoka 411-8540, Japan, 4Department of Anatomy and Cell Biology, Graduate School of Medicine, Kyoto University, Yoshida- Konoe-cho, Sakyo-ku, Kyoto 606-8501, Japan and 5JST, CREST, Yoshida-Konoe-cho, Sakyo-ku, Kyoto 606-8501, Japan Correspondence should be addressed to M Saitou at Department of Anatomy and Cell Biology, Graduate School of Medicine, Kyoto University; Email: [email protected] Abstract Mutations of RNA-binding proteins such as NANOS3, TIAL1, and DND1 in mice have been known to result in the failure of survival and/or proliferation of primordial germ cells (PGCs) soon after their fate is specified (around embryonic day (E) 8.0), leading to the infertility of these animals. However, the mechanisms of actions of these RNA-binding proteins remain largely unresolved. As a foundation to explore the role of these RNA-binding proteins in germ cells, we established a novel transgenic reporter strain that expresses NANOS3 fused with EGFP under the control of Nanos3 regulatory elements. NANOS3–EGFP exhibited exclusive expression in PGCs as early as E7.25, and continued to be expressed in female germ cells until around E14.5 and in male germ cells throughout the fetal period with declining expression levels after E16.5. -

Molecular and Cellular Mechanisms of the Angiogenic Effect of Poly(Methacrylic Acid-Co-Methyl Methacrylate) Beads
Molecular and Cellular Mechanisms of the Angiogenic Effect of Poly(methacrylic acid-co-methyl methacrylate) Beads by Lindsay Elizabeth Fitzpatrick A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Institute of Biomaterials and Biomedical Engineering University of Toronto © Copyright by Lindsay Elizabeth Fitzpatrick 2012 Molecular and Cellular Mechanisms of the Angiogenic Effect of Poly(methacrylic acid-co-methyl methacrylate) Beads Lindsay Elizabeth Fitzpatrick Doctorate of Philosophy Institute of Biomaterials and Biomedical Engineering University of Toronto 2012 Abstract Poly(methacrylic acid -co- methyl methacrylate) beads were previously shown to have a therapeutic effect on wound closure through the promotion of angiogenesis. However, it was unclear how this polymer elicited its beneficial properties. The goal of this thesis was to characterize the host response to MAA beads by identifying molecules of interest involved in MAA-mediated angiogenesis (in comparison to poly(methyl methacrylate) beads, PMMA). Using a model of diabetic wound healing and a macrophage-like cell line (dTHP-1), eight molecules of interest were identified in the host response to MAA beads. Gene and/or protein expression analysis showed that MAA beads increased the expression of Shh, IL-1β, IL-6, TNF- α and Spry2, but decreased the expression of CXCL10 and CXCL12, compared to PMMA and no beads. MAA beads also appeared to modulate the expression of OPN. In vivo, the global gene expression of OPN was increased in wounds treated with MAA beads, compared to PMMA and no beads. In contrast, dTHP-1 decreased OPN gene expression compared to PMMA and no beads, but expressed the same amount of secreted OPN, suggesting that the cells decreased the expression of the intracellular isoform of OPN. -

A Comprehensive Analysis of 3' End Sequencing Data Sets Reveals Novel
bioRxiv preprint doi: https://doi.org/10.1101/033001; this version posted November 26, 2015. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. A comprehensive analysis of 3’ end sequencing data sets reveals novel polyadenylation signals and the repressive role of heterogenous ribonucleoprotein C on cleavage and polyadenylation 1 1 1 1 1 Andreas J. Gruber , Ralf Schmidt , Andreas R. Gruber , Georges Martin , Souvik Ghosh , 1,2 1 1,§ Manuel Belmadani , Walter Keller , Mihaela Zavolan 1 Computational and Systems Biology, Biozentrum, University of Basel, Klingelbergstrasse 5070, 4056 Basel, Switzerland 2 Current address: University of British Columbia, 177 Michael Smith Laboratories, 2185 East Mall Vancouver BC V6T 1Z4 § To whom correspondence should be addressed ([email protected]) Abstract Alternative polyadenylation (APA) is a general mechanism of transcript diversification in mammals, which has been recently linked to proliferative states and cancer. Different 3’ untranslated region (3’ UTR) isoforms interact with different RNA binding proteins (RBPs), which modify the stability, translation, and subcellular localization of the corresponding transcripts. Although the heterogeneity of premRNA 3’ end processing has been established with highthroughput approaches, the mechanisms that underlie systematic changes in 3’ UTR lengths remain to be characterized. Through a uniform analysis of a large number of 3’ end sequencing data sets we have uncovered 18 signals, 6 of which novel, whose positioning with respect to premRNA cleavage sites indicates a role in premRNA 3’ end processing in both mouse and human. -

Genetic Variant in 3' Untranslated Region of the Mouse Pycard Gene
bioRxiv preprint doi: https://doi.org/10.1101/2021.03.26.437184; this version posted March 26, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 1 2 3 Title: 4 Genetic Variant in 3’ Untranslated Region of the Mouse Pycard Gene Regulates Inflammasome 5 Activity 6 Running Title: 7 3’UTR SNP in Pycard regulates inflammasome activity 8 Authors: 9 Brian Ritchey1*, Qimin Hai1*, Juying Han1, John Barnard2, Jonathan D. Smith1,3 10 1Department of Cardiovascular & Metabolic Sciences, Lerner Research Institute, Cleveland Clinic, 11 Cleveland, OH 44195 12 2Department of Quantitative Health Sciences, Lerner Research Institute, Cleveland Clinic, Cleveland, OH 13 44195 14 3Department of Molecular Medicine, Cleveland Clinic Lerner College of Medicine of Case Western 15 Reserve University, Cleveland, OH 44195 16 *, These authors contributed equally to this study. 17 Address correspondence to Jonathan D. Smith: email [email protected]; ORCID ID 0000-0002-0415-386X; 18 mailing address: Cleveland Clinic, Box NC-10, 9500 Euclid Avenue, Cleveland, OH 44195, USA. 19 1 bioRxiv preprint doi: https://doi.org/10.1101/2021.03.26.437184; this version posted March 26, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 20 Abstract 21 Quantitative trait locus mapping for interleukin-1 release after inflammasome priming and activation 22 was performed on bone marrow-derived macrophages (BMDM) from an AKRxDBA/2 strain intercross. -
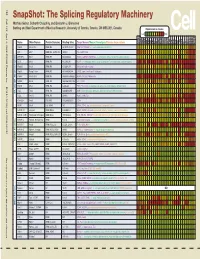
Snapshot: the Splicing Regulatory Machinery Mathieu Gabut, Sidharth Chaudhry, and Benjamin J
192 Cell SnapShot: The Splicing Regulatory Machinery Mathieu Gabut, Sidharth Chaudhry, and Benjamin J. Blencowe 133 Banting and Best Department of Medical Research, University of Toronto, Toronto, ON M5S 3E1, Canada Expression in mouse , April4, 2008©2008Elsevier Inc. Low High Name Other Names Protein Domains Binding Sites Target Genes/Mouse Phenotypes/Disease Associations Amy Ceb Hip Hyp OB Eye SC BM Bo Ht SM Epd Kd Liv Lu Pan Pla Pro Sto Spl Thy Thd Te Ut Ov E6.5 E8.5 E10.5 SRp20 Sfrs3, X16 RRM, RS GCUCCUCUUC SRp20, CT/CGRP; −/− early embryonic lethal E3.5 9G8 Sfrs7 RRM, RS, C2HC Znf (GAC)n Tau, GnRH, 9G8 ASF/SF2 Sfrs1 RRM, RS RGAAGAAC HipK3, CaMKIIδ, HIV RNAs; −/− embryonic lethal, cond. KO cardiomyopathy SC35 Sfrs2 RRM, RS UGCUGUU AChE; −/− embryonic lethal, cond. KO deficient T-cell maturation, cardiomyopathy; LS SRp30c Sfrs9 RRM, RS CUGGAUU Glucocorticoid receptor SRp38 Fusip1, Nssr RRM, RS ACAAAGACAA CREB, type II and type XI collagens SRp40 Sfrs5, HRS RRM, RS AGGAGAAGGGA HipK3, PKCβ-II, Fibronectin SRp55 Sfrs6 RRM, RS GGCAGCACCUG cTnT, CD44 DOI 10.1016/j.cell.2008.03.010 SRp75 Sfrs4 RRM, RS GAAGGA FN1, E1A, CD45; overexpression enhances chondrogenic differentiation Tra2α Tra2a RRM, RS GAAARGARR GnRH; overexpression promotes RA-induced neural differentiation SR and SR-Related Proteins Tra2β Sfrs10 RRM, RS (GAA)n HipK3, SMN, Tau SRm160 Srrm1 RS, PWI AUGAAGAGGA CD44 SWAP Sfrs8 RS, SWAP ND SWAP, CD45, Tau; possible asthma susceptibility gene hnRNP A1 Hnrnpa1 RRM, RGG UAGGGA/U HipK3, SMN2, c-H-ras; rheumatoid arthritis, systemic lupus -

Discovering Protein-Binding RNA Motifs with a Generative Model of RNA Sequences T
Computational Biology and Chemistry 84 (2020) 107171 Contents lists available at ScienceDirect Computational Biology and Chemistry journal homepage: www.elsevier.com/locate/cbac Research Article Discovering protein-binding RNA motifs with a generative model of RNA sequences T Byungkyu Park, Kyungsook Han* Department of Computer Engineering, Inha University, 22212 Incheon, South Korea ARTICLE INFO ABSTRACT Keywords: Recent advances in high-throughput experimental technologies have generated a huge amount of data on in- Protein-RNA interaction teractions between proteins and nucleic acids. Motivated by the big experimental data, several computational Binding motif methods have been developed either to predict binding sites in a sequence or to determine if an interaction exists Generator between protein and nucleic acid sequences. However, most of the methods cannot be used to discover new Long short-term memory network nucleic acid sequences that bind to a target protein because they are classifiers rather than generators. In this paper we propose a generative model for constructing protein-binding RNA sequences and motifs using a long short-term memory (LSTM) neural network. Testing the model for several target proteins showed that RNA sequences generated by the model have high binding affinity and specificity for their target proteins and that the protein-binding motifs derived from the generated RNA sequences are comparable to the motifs from experi- mentally validated protein-binding RNA sequences. The results are promising and we believe this approach will help design more efficient in vitro or in vivo experiments by suggesting potential RNA aptamers for a target protein. 1. Introduction protein-binding sites in the input nucleic sequence. -

Literature Mining Sustains and Enhances Knowledge Discovery from Omic Studies
LITERATURE MINING SUSTAINS AND ENHANCES KNOWLEDGE DISCOVERY FROM OMIC STUDIES by Rick Matthew Jordan B.S. Biology, University of Pittsburgh, 1996 M.S. Molecular Biology/Biotechnology, East Carolina University, 2001 M.S. Biomedical Informatics, University of Pittsburgh, 2005 Submitted to the Graduate Faculty of School of Medicine in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Pittsburgh 2016 UNIVERSITY OF PITTSBURGH SCHOOL OF MEDICINE This dissertation was presented by Rick Matthew Jordan It was defended on December 2, 2015 and approved by Shyam Visweswaran, M.D., Ph.D., Associate Professor Rebecca Jacobson, M.D., M.S., Professor Songjian Lu, Ph.D., Assistant Professor Dissertation Advisor: Vanathi Gopalakrishnan, Ph.D., Associate Professor ii Copyright © by Rick Matthew Jordan 2016 iii LITERATURE MINING SUSTAINS AND ENHANCES KNOWLEDGE DISCOVERY FROM OMIC STUDIES Rick Matthew Jordan, M.S. University of Pittsburgh, 2016 Genomic, proteomic and other experimentally generated data from studies of biological systems aiming to discover disease biomarkers are currently analyzed without sufficient supporting evidence from the literature due to complexities associated with automated processing. Extracting prior knowledge about markers associated with biological sample types and disease states from the literature is tedious, and little research has been performed to understand how to use this knowledge to inform the generation of classification models from ‘omic’ data. Using pathway analysis methods to better understand the underlying biology of complex diseases such as breast and lung cancers is state-of-the-art. However, the problem of how to combine literature- mining evidence with pathway analysis evidence is an open problem in biomedical informatics research. -

TIAL1 (NM 003252) Human Recombinant Protein Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for TP760477 TIAL1 (NM_003252) Human Recombinant Protein Product data: Product Type: Recombinant Proteins Description: Purified recombinant protein of Human TIA1 cytotoxic granule-associated RNA binding protein-like 1 (TIAL1), transcript variant 1, full length, with N-terminal HIS tag, expressed in E.Coli, 50ug Species: Human Expression Host: E. coli Tag: N-His Predicted MW: 41.4 kDa Concentration: >50 ug/mL as determined by microplate BCA method Purity: > 80% as determined by SDS-PAGE and Coomassie blue staining Buffer: 25mM Tris, pH8.0, 150 mM NaCl, 10% glycerol, 1 % Sarkosyl. Storage: Store at -80°C. Stability: Stable for 12 months from the date of receipt of the product under proper storage and handling conditions. Avoid repeated freeze-thaw cycles. RefSeq: NP_003243 Locus ID: 7073 UniProt ID: Q01085, Q49AS9 RefSeq Size: 1436 Cytogenetics: 10q26.11 RefSeq ORF: 1125 Synonyms: TCBP; TIAR Summary: The protein encoded by this gene is a member of a family of RNA-binding proteins, has three RNA recognition motifs (RRMs), and binds adenine and uridine-rich elements in mRNA and pre-mRNAs of a wide range of genes. It regulates various activities including translational control, splicing and apoptosis. Alternate transcriptional splice variants, encoding different isoforms, have been characterized. The different isoforms have been show to function differently with respect to post-transcriptional silencing. [provided by RefSeq, Jul 2008] This product is to be used for laboratory only. -

The Devil Is in the Domain: Understanding Protein Recognition of Multiple RNA Targets
The devil is in the domain: understanding protein recognition of multiple RNA targets Glen R. Gronland1 and Andres Ramos1 1. Institute of Structural and Molecular Biology, University College London, London WC1E 6XA, UK Correspondence to Andres Ramos: [email protected] Abstract: RNA regulation provides a finely-tuned and highly-coordinated control of gene expression. Regulation is mediated by hundreds to thousands of multi-functional RNA-binding proteins which often interact with large sets of RNAs. In this brief review, we focus on recent work that highlights how the proteins use multiple RNA-binding domains to interact selectively with the different RNA targets. De-convoluting the molecular complexity of the RNA regulatory network is essential to understanding cell differentiation and function, and requires accurate models for protein-RNA recognition and protein target selectivity. We discuss that the structural and molecular understanding of the key determinant of recognition, together with the availability of methods to examine protein-RNA interactions at the transcriptome level, may provide an avenue to establish these models. Abbreviations list: CSD, Cold shock domain dsRBD, Double-stranded RNA-binding domain KH, hnRNP K-homology mRNA, Messenger RNA ncRNA, Non-coding RNA RBD, RNA-binding domain RBP, RNA-binding protein RRM, RNA-recognition motif ZnF, Zinc finger Introduction The combined regulation of the various steps in the metabolism and transport of messenger RNAs (mRNAs) and non-coding RNAs (ncRNAs) multiplies genomic potential, and allows cellular differentiation and the development of complex organisms. In the cell, functional RNAs are associated with a fluctuating assortment of multi-domain RNA-binding proteins (RBPs), forming integrated complexes, whose composition directs the fate of the transcript1,2.