Jdemetra+ User Guide Version
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Calendar Christs Time for the Church 1St Edition Pdf, Epub, Ebook
CALENDAR CHRISTS TIME FOR THE CHURCH 1ST EDITION PDF, EPUB, EBOOK Laurence Hull Stookey | 9780687011360 | | | | | Calendar Christs Time for the Church 1st edition PDF Book Over all though I think he gave a good feel for not only the meaning of the calendar and its role in the church to day, but also an overview of the history of the way the Church and its calendar has evolved over the centuries. Seller Inventory As in Advent, the deacon and subdeacon of the pre form of the Roman Rite do not wear their habitual dalmatic and tunicle signs of joy in Masses of the season during Lent; instead they wear "folded chasubles", in accordance with the ancient custom. The dates of the festivals vary somewhat between the different churches, though the sequence and logic is largely the same. American Catholic literature Bible fiction Christian drama Christian poetry Christian novel Christian science fiction Spiritual autobiography. Special occasion bulletins are also available for baptisms, ordinations and funerals. The greatest feast is Pascha. The Fathers on the Sunday Gospels. The season begins on January 14 [24] and ends on the Saturday before Septuagesima Sunday. Help Learn to edit Community portal Recent changes Upload file. The letter was his response to a public statement of caution outlined in A Call for Unity that had been issued by seven white Christian ministers and one Jewish rabbi, who agreed that there were injustices, but argued that the battle against segregation should be fought patiently and in the courts, not the streets. Annually recurring fixed sequence of Christian feast days. -

Package 'Bizdays'
Package ‘bizdays’ April 19, 2021 Title Business Days Calculations and Utilities Description Business days calculations based on a list of holidays and nonworking weekdays. Quite useful for fixed income and derivatives pricing. Version 1.0.8 Author Wilson Freitas <[email protected]> Maintainer Wilson Freitas <[email protected]> URL https://github.com/wilsonfreitas/R-bizdays VignetteBuilder knitr Suggests RQuantLib, timeDate, knitr, testthat, covr, rmarkdown Imports methods, utils, jsonlite Collate 'R-bizdays-package.r' 'datasets.R' 'calendar.R' 'adjust.date.R' 'bizdays.options.R' 'bizseq.R' 'is.bizday.R' 'offset.R' 'bizdiff.R' 'bizdays.R' 'create-calendars.R' 'calendar-export.R' 'getdate.R' Depends R (>= 2.15) License MIT + file LICENSE LazyData true RoxygenNote 7.1.1 Encoding UTF-8 NeedsCompilation no Repository CRAN Date/Publication 2021-04-19 05:20:13 UTC R topics documented: bizdays-package . .2 adjust.date . .2 bizdays . .4 bizdays.options . .5 bizdayse . .6 1 2 adjust.date bizdiff . .7 bizseq . .8 calendar-holidays-weekdays . .8 calendar-import-export . .9 calendar-register . 10 create.calendar . 11 getdate . 13 holidaysANBIMA . 14 is.bizday . 14 offset . 15 other-calendars . 16 Index 19 bizdays-package Business Days Calculations and Utilities Description In many countries the standard approach to price derivatives and fixed income instruments involves the use of business days. In Brazil, for example, the great majority of financial instruments are priced on business days counting rules. Given that the use of business days is somehow vital to handle many tasks. That’s the reason why bizdays came up, to make these tasks easier. Excel’s NETWORKDAYS is fairly at hand and once you have a list of holidays it is quite easy to put your data into a spreadsheet and make things happen. -

Brightspace Instructor Calendar
Instructor Guide: Calendar The Calendar tool enables you to create and track two types of events: Availability Events These “events” are reminders of start and end dates for course objects created and edited outside of the Calendar Tool. Once you add a course to your list of Calendars, any objects the course contains are shown in the Calendar. General (content) Events These are events created within the Calendar tool. You can create multiple events for the same course object, and include details of presenters and location for the event. You can create calendar events drawing directly from course content. As you update or edit course content and events, the changes are immediately reflected in Calendar (since content is displayed directly inline). However, you can adjust visibility settings for course objects so that they appear in Calendar on your terms. Accessing the Calendar Click on Calendar from a course homepage. The calendar management area contains tools for customizing how calendar content appears. From this area, you can: -Use the calendar views area to toggle between different display layouts for events in the calendar content area. -Use the Agenda view to group your course events by Date, Course, or Category - events display in chronological order, and all-day events display at the top of each grouped listing. -You can make bulk changes to dates and visibility in the List view. -You can Print, adjust your calendar Settings, or Browse through your calendars. Revised: 4/5/2021 Setting up your Calendar displays I. Setting your active course calendar a. Click on a course name from the calendar menu. -

Calendar Help
Master Calendar Help Contents View Multiple Calendars .................................................................................................................................................... 2 Filter a Calendar(s) by Event Type and/or Location ............................................................................................................ 2 Keyword Search .................................................................................................................................................................. 3 Calendar Reminders ............................................................................................................................................................ 3 Adding a Calendar to Outlook ............................................................................................................................................. 5 Print a Calendar ................................................................................................................................................................... 8 Calendar Subscriptions ..................................................................................................................................................... 10 Add Individual Events to a Personal Calendar (Google Calendar, Microsoft Outlook) ..................................................... 12 Add Events to the Community Calendar ........................................................................................................................... 13 -
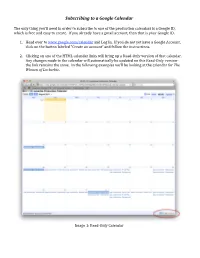
Subscribing to a Google Calendar
Subscribing to a Google Calendar The only thing you’ll need in order to subscribe to one of the production calendars is a Google ID, which is free and easy to create. If you already have a gmail account, then that is your Google ID. 1. Head over to www.google.com/calendar and Log In. If you do not yet have a Google Account, click on the button labeled “Create an account” and follow the instructions. 2. Clicking on one of the HTML calendar links will bring up a Read‐Only version of that calendar. Any changes made to the calendar will automatically be updated on this Read‐Only version‐ the link remains the same. In the following examples we’ll be looking at the calendar for The Women of Lockerbie. Image 1: Read‐Only Calendar 3. To subscribe to a calendar, click on the button in the lower right hand corner labeled “+GoogleCalendar,” circled in red in Image 1. The following window will pop up: Click “Yes, add this calendar” and it will now appear in your list of calendars: Image 2: Single Calendar Turned On 4. Google Calendar allows you to subscribe to and display information from numerous calendars simultaneously. You can choose how much you want to see at any given time; in Image 2, only the Lockerbie calendar is turned on, circled in red on the left hand side of the page, while in Image 3 below, multiple calendars have been turned on: Image 3: Multiple Calendars Turned On You will note that calendars that are active are labeled in bold, while those that are inactive are grayed out. -
Google Calendar for Administrative Assistants What's in This Guide
Google Calendar for Administrative Assistants If you directly manage others’ calendars, this is the Google Calendar guide for you. In this guide, you will learn about setting up delegated Google calendars, common Google Calendar tasks, tips and tricks to improve efficiency, and recommended Google Calendar Labs for administrative assistants. See the Calendar page and the Calendar FAQs in the Google Apps Learning Center for more tips and "how-to’s." What’s in this guide... What’s in this guide... Getting Started Access your manager’s calendar Set up delegated access How events appear to guests Receive notifications for your manager’s calendar Tips on using notifications Work with your manager’s calendar Accept or decline events on behalf of your manager Add a note to the invitation response See meeting status at a glance (invitation, accepted, declined) Create events on behalf of your manager Schedule on your manager's calendar Choose privacy setting Specify the event time zone Invitations and Events Invite guests to events Check availability of guests Invite Google groups to events Select options for your guests in the “Guests can” section Schedule rooms or other resources 1 11/25/2013 DN: GA-GCAA_102.00 Schedule recurring events Notify guests about events Email guests about event Send event invitations only to specific guests Create event reminders only your manager can see Edit event details later Send updates to guests when you edit event details Drag and drop event to change time or day Duplicate events Transfer ownership of an event -

How to Sync the District and School Calendars with Your Devices (Tablets, Smartphones, and Computers)
How to sync the district and school calendars with your devices (tablets, smartphones, and computers) Please note: you will need to subscribe to each calendar that you wish to view within your calendar application. For Elementary School For Middle School families, For High School families, families, subscribe to: subscribe to: subscribe to: School-specific calendar • WMS Calendar WHS Calendar (i.e. BBES, LGES, SCES, or • MS Day Cycle Calendar HS Day Cycle Calendar SGES) • Secondary Events Secondary Events Elementary Encore Calendar Calendar Calendar • MS Athletics WHS Guidance Elementary Calendar • District Calendar District Calendar District Calendar For Apple iOS iPhones and iPads: 1. On the device, go to the webpage with the calendar you want to sync (i.e. District calendar or school calendar). 2. In the upper right-hand corner of the calendar, click the grey feed icon. 3. In the pop-up window, you will see a list of calendars. Click the green iCal icon and a list of options will appear. 4. Click ‘Get Standard iCal URL’. 5. Copy the URL link that appears next to the iCal menu. 6. Go to Settings on your device and click on Mail, Contacts, and Calendars. 7. Within Accounts, click ‘Add Account’ and then click ‘other’. 8. Within Calendars, click ‘Add Subscribed Calendar’. 9. Paste the copied URL into the ‘Server’ field. Then, click ‘Next.’ 10. Finally, click ‘Save.’ At this time, the subscribed calendar will appear in the calendar app of your device. For Android smartphones and tablets: 1. On the device, go to the webpage with the calendar you want to sync (i.e. -

Astronomy Before the Telescope Observing Certificate
Astronomy Before the Telescope Observing Certificate Astronomy Before the Telescope Observing Certificate Coordinator: Steve Boerner 2017 Lake Clay Drive Chesterfield, MO 63017 (636) 537-2495 E-mail: [email protected] Introduction In a 2006 article in the Journal of the Royal Astronomical Society of Canada, Robert A. Egler aptly stated: "In modern astronomy, it is astrophysics that dominates, with its emphasis on analyzing celestial objects for what they are, how they work, what they are made of, and how they evolve. The pre-telescope instruments were all designed to find the position of celestial object in relation to the great celestial sphere and each other, and to determine their motions. In short, these instruments are not for analyzing the heavens, but rather for measuring the heavens." The early instruments were invented to answer important questions like when it would be time to plant crops for best success, when migrating herds might return, when seasonal flooding might occur, when religious days were to be held, what direction to go to get to a specific place, or where things in the sky were likely to appear. The instruments helped develop systems to measure both yearly cycles (calendar) and daily time (clock) as well as determine directions (compass). The ancient people who developed these instruments relied on what they could observe on the ground and in the sky with the Sun, the moon, and bright stars to point the way. The purpose of the Astronomy Before the Telescope Observing Certificate is to provide an opportunity for you to examine some of the early instruments that provide information for both our daily lives and our astronomical observing. -
2. Format for Vehicle Reservations: 4. Format for Room Reservations
The Google Support version: https://support.google.com/calendar/answer/143753 Here are links, to our website, where you can view the current schedules: http://www.rbc.us/resources/room-scheduling http://www.rbc.us/resources/vehicles Please Note: To keep things easy to manage and read for everyone, please follow these rules. 1. Vehicles should be scheduled for All Day use. 2. Format for Vehicle reservations: car# | Employee Name | Department | Destination 3. Rooms should be scheduled only for the times that they will be needed. 4. Format for Room reservations: location - room name | Employee Name | Department - Please continue to check for availability by by using http://www.rbc.us/resources, then email [email protected] with your Exchange/Outlook users reservation needs and we’ll schedule it for yo u. Google Apps (@rbc.us) users - Below are the two easy steps so that you may make reservations yourself. 1. First - Add all reservation calendars into your personal calendar as follows - THIS IS A ONE TIME PROCESS a. Simply click here → http://calendar.rbc.us and log in using your Google email credentials ([email protected] and password). You should see the desired calendar in the list of My calendars (make sure to expand the list using the triangle directly to the left of My calendars). b. To add the calendar for the room you want to use, click on it via the drop-down list next to Other calendars as follows: i. From the drop-down, select Browse interesting calendars. ii. Go to the More tab. iii. Click on the link to Resources for rbc.us. -

The Month God's Holy Calendar Failed
The Month God’s Holy Calendar Failed Abstract This report examines what some Christian groups refer to as ”God’s Sacred Calendar”, ”God’s Holy Calen- dar”, or ”The Calendar of Christ and the Apostles”. Although praised for amazing accuracy, it is demonstrated in this report that for a particularly important month it fails miserably, nullifying the claim of divine origin. Contents 1 Introduction 2 1.1 Outline of this report . ...... 2 1.2 Sourcesforthisreport .............................. ......... 2 2 Background 2 2.1 InPraiseofAccuracy ............................... ........ 2 2.2 General Beliefs about “God’s Holy Calendar” . ............ 3 2.2.1 TheFirstMonth................................... ... 3 2.2.2 TheSeventhMonth ................................. ... 3 2.2.3 A Month in the Judaistic Calendar Begins With A New Moon . .... 4 2.3 Some Information About the Current Calendar of Judaism . .............. 4 2.3.1 Judaism101..................................... ... 4 2.3.2 JewishEncyclopedia ............................... .... 4 3 Nisan in 2014 5 3.1 TheBeginningoftheMonth.............................. ...... 5 3.2 TheBeginningoftheSecondMonth . ....... 6 3.3 TheLengthoftheMonth ................................ ..... 6 3.4 Summaryfor2014.................................. ....... 6 4 Work Out Your Own Salvation 6 4.1 ErrorsNotUncommon ............................... ....... 6 4.2 CheckForYourself ................................. ....... 7 4.3 Jewish Authors on Timing Errors in the Jewish Calendar . ........... 7 5 Conclusion 8 6 About this document 8 7 Further Reading 8 7.1 Scientific Astronomical Sources . ......... 8 7.2 JewishPracticeSources .............................. ........ 9 7.3 Some Non-Jewish Groups Which Try To Observe Biblical New Moons ............. 9 7.4 Further Items on Failures in “God’s Holy Calendar” . ........... 10 Copyright (C) 2014 Selwyn Russell. All rights reserved. Permission is given to copy and distribute in entirety without modification, and with credit to original source. -

Google Calendar for Administrative Assistants DN: GA-GCAA 101.0
Google Calendar for Administrative Assistants DN: GA-GCAA_101.0 Google Calendar for Administrative Assistants If you directly manage others’ calendars, this is the Google Calendar guide for you. In this guide, you will learn about setting up delegated Google calendars, common Google Calendar tasks, tips and tricks to improve efficiency, and recommended Google Calendar Labs for administrative assistants. See the Calendar page and the Calendar FAQs in the Google Apps Learning Center for more tips and "how-to’s." 1 Google Calendar for Administrative Assistants DN: GA-GCAA_101.0 What’s in this guide... Getting Started Access your manager’s calendar How events appear to guests Receive notifications for your manager’s calendar Work with your manager’s calendar Accept or decline events on behalf of your manager Add a note to the invitation response See meeting status at a glance Create events on behalf of your manager Invitations and Events Invite guests to events Schedule rooms or other resources Schedule recurring events Notify guests about events Edit event details later Manage Calendars Print calendars Customize your Calendar view Create new calendars Calendar Tips & Tricks Save time with Calendar keyboard shortcuts Use Tasks in Calendar Add interesting calendars from Google Calendar Add calendars for favorite resources (conference rooms) Include “Add to my calendar” link in emails Calendar Labs Enable Labs Suggested Calendar Labs 2 Google Calendar for Administrative Assistants DN: GA-GCAA_101.0 Getting Started Access your manager’s -

Google Calendar - Parent Directions
Google Calendar - Parent Directions In order to make things more organized and easier to manage, here is a guide explaining how Google Calendar works along with some tips and tricks that will help you to keep student assignments and schedules organized. Google Calendar can be a centralized place to keep all of your events and assignments organized - and you can share Calendars between Google accounts, so you can help to keep your child on task! How to access Google Calendar: 1. When you are signed in to your Google Account, look at the top right of the screen and select the navigation “waffle”/9 square. This is where your Google Apps are located. Select Calendar. Viewing events others (teachers, for example) have shared with you: 1. In the Calendar screen, you have various options for how to view your calendar. In the top right you can change how many days you see, from seeing one day at a time, to seeing an entire year at once. The more days you are looking at, the less specific events you will see. You can scroll through days toward the top left, and you can toggle your different calendars on and off on the bottom left to limit which events you are looking at. This is handy if you only want to see one class’s schedule, or if you set an assignment schedule. 2. On your calendar you will only see a shortened version of the events for the day. Click on the event to find out more details, such as where an event is located, who is invited, and if it is a 3.