Analysis of Social Unrest Events Using Spatio-Temporal Data Clustering and Agent-Based Modelling" (2019)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Textiles of the Han Dynasty & Their Relationship with Society
The Textiles of the Han Dynasty & Their Relationship with Society Heather Langford Theses submitted for the degree of Master of Arts Faculty of Humanities and Social Sciences Centre of Asian Studies University of Adelaide May 2009 ii Dissertation submitted in partial fulfilment of the research requirements for the degree of Master of Arts Centre of Asian Studies School of Humanities and Social Sciences Adelaide University 2009 iii Table of Contents 1. Introduction.........................................................................................1 1.1. Literature Review..............................................................................13 1.2. Chapter summary ..............................................................................17 1.3. Conclusion ........................................................................................19 2. Background .......................................................................................20 2.1. Pre Han History.................................................................................20 2.2. Qin Dynasty ......................................................................................24 2.3. The Han Dynasty...............................................................................25 2.3.1. Trade with the West............................................................................. 30 2.4. Conclusion ........................................................................................32 3. Textiles and Technology....................................................................33 -

Archaeological Observation on the Exploration of Chu Capitals
Archaeological Observation on the Exploration of Chu Capitals Wang Hongxing Key words: Chu Capitals Danyang Ying Chenying Shouying According to accurate historical documents, the capi- In view of the recent research on the civilization pro- tals of Chu State include Danyang 丹阳 of the early stage, cess of the middle reach of Yangtze River, we may infer Ying 郢 of the middle stage and Chenying 陈郢 and that Danyang ought to be a central settlement among a Shouying 寿郢 of the late stage. Archaeologically group of settlements not far away from Jingshan 荆山 speaking, Chenying and Shouying are traceable while with rice as the main crop. No matter whether there are the locations of Danyang and Yingdu 郢都 are still any remains of fosses around the central settlement, its oblivious and scholars differ on this issue. Since Chu area must be larger than ordinary sites and be of higher capitals are the political, economical and cultural cen- scale and have public amenities such as large buildings ters of Chu State, the research on Chu capitals directly or altars. The site ought to have definite functional sec- affects further study of Chu culture. tions and the cemetery ought to be divided into that of Based on previous research, I intend to summarize the aristocracy and the plebeians. The relevant docu- the exploration of Danyang, Yingdu and Shouying in ments and the unearthed inscriptions on tortoise shells recent years, review the insufficiency of the former re- from Zhouyuan 周原 saying “the viscount of Chu search and current methods and advance some personal (actually the ruler of Chu) came to inform” indicate that opinion on the locations of Chu capitals and later explo- Zhou had frequent contact and exchange with Chu. -

Shuk Han CHENG (Ne Shuk Han CHUNG) Education 85-90 Phd / RA
1 page cv April 2011 Shuk Han CHENG (neé Shuk Han CHUNG) Education 85-90 PhD / RA (Department of Bacteriology, Royal Postgraduate Medical School, University of London) 80-83 BSc (Department of Zoology, University of Hong Kong) Employment 10-date Professor, Department of Biology & Chemistry, City University of Hong Kong 01-10 Associate Professor, Department of Biology & Chemistry, City University of Hong Kong 00-01 Assistant Professor, Department of Biology & Chemistry, City University of Hong Kong 97-00 Research Assistant Professor, Department of Biology & Chemistry, City University of Hong Kong 93-97 Lecturer/Scientific Officer, Depts of Paediatrics and Orthopaedics, Chinese University of Hong Kong 90-93 Postdoctoral Fellow in Tak Mak’s lab, Ontario cancer Institute, University of Toronto Research Interest: developmental and regenerative biology, nanobiological interface, nanomedicine Publications Records: 75 papers in SCI journals, 2 book chapters & 10 referred conference proceedings (full list available upon request), 1 patent awarded and 8 patents filed Five most representative publications in recent 5 years: * denotes corresponding authorship 1. Cheng J., * Cheng S.H. (2011) Poly(ethylene glycol) conjugated multi-walled carbon nanotubes as an efficient drug carrier for overcoming multi-drug resistance. Toxicology and Applied Pharmacology 250:184-93. 2. Cheng J., Chan CM, Veca LM, Poon W.L., Chan P.K., Qu L, *Sun Y.-P., *Cheng S.H. (2009). Acute and long-term effects after single loading of functionalized multi-walled carbon nanotubes into zebrafish (Danio rerio) Toxicology & Applied Pharmacology 235:216-225. 3. Gu Y.-J., Cheng J., Lin A.C.-C., Lam Y.W., *Cheng S.H., *Wong W.-T. -

Southeast Asia
SOUTHEAST ASIA Shang Dynasty Zhou Dynasty ● Time of emergence: 1766 BC ● Time of emergence: 1046-256 BCE ● Time they were at their peak:1350 BC ● Divided into 2 different periods (Western Zhou: ● Time they were around: 1766-1122 BC 1046-771 BCE)(Eastern Zhou: 770-256 BCE) ● Time of fall: 1122 BC ● They were around for 8 centuries (800+ years) ● Time of fall: 256 BCE GEOGRAPHIC IMPACT ON SOCIETY Shang Dynasty Zhou Dynasty The Shang Dynasty controlled the North China Plain, which ● They were located west of Shang Dynasty however after corresponds to the modern day Chinese provinces of Anhui, Hebei, conquering Shang Dynasty, their borders extended as far Henan, Shandong, and Shanxi. The area that those of the Shang south as chang Jiang river and east to the Yellow sea. Dynasty lived in, under the Yellow River Valley, gave them water as These body of waters provided fertile soil for good farming well as fertile soil which helped their civilization thrive. Natural borders, and their trading increased. ● Present day location: Xi’an in Shaanxi near the Wei river such as mountains, also protected the area, making it easier to protect. and confluence of the Yellow river The Yellow River also made it easy for the people that lived there to ● They were not geographically isolated from other obtain a steady supply of water. civilizations ● They were exposed to large bodies of water POLITICAL SYSTEM AND IMPACT ON SOCIETY government Shang Dynasty Zhou Dynasty The Shang Dynasty was ruled by a ● The Zhou Dynasty ruled with a confucian social hierarchy hereditary monarchy, in which the ● The citizens were expected to follow the rules and values of confucianism government wa controlled by the king Organization: mainly, and the line of rule descended ● Had the “mandate of heaven” through the family. -
![Boya Genuine] the Sweet Kitchen Mu Han(Chinese Edition](https://docslib.b-cdn.net/cover/3962/boya-genuine-the-sweet-kitchen-mu-han-chinese-edition-303962.webp)
Boya Genuine] the Sweet Kitchen Mu Han(Chinese Edition
FANLB1OIFM « Boya Genuine] the sweet kitchen Mu Han(Chinese Edition) < eBook Boya Genuine] th e sweet kitch en Mu Han(Ch inese Edition) By MU HAN ZHU To get Boya Genuine] the sweet kitchen Mu Han(Chinese Edition) eBook, remember to follow the hyperlink listed below and save the ebook or gain access to other information that are related to BOYA GENUINE] THE SWEET KITCHEN MU HAN(CHINESE EDITION) book. Our services was released using a aspire to serve as a comprehensive on the internet digital local library that oers entry to large number of PDF file document selection. You might find many dierent types of e-book as well as other literatures from the files data bank. Certain preferred subject areas that distribute on our catalog are popular books, solution key, exam test question and solution, guideline example, exercise guideline, quiz trial, user manual, consumer guide, services instruction, maintenance guide, and many others. READ ONLINE [ 1.91 MB ] Reviews This book is definitely worth buying. This really is for all who statte there had not been a worthy of studying. You will not sense monotony at at any moment of the time (that's what catalogs are for concerning should you check with me). -- Mr. Martin Baumbach Completely essential study ebook. This is for all those who statte there was not a well worth reading. I realized this book from my dad and i recommended this publication to find out. -- Jarrell Kovacek YMKF4KJGXL < Boya Genuine] the sweet kitchen Mu Han(Chinese Edition) ^ Book Oth er Books Friendfluence: The Surprising Ways Friends Make Us Who We Are [PDF] Access the link under to read "Friendfluence: The Surprising Ways Friends Make Us Who We Are" PDF document. -

Achieving High Coverage for Floating-Point Code Via Unconstrained Programming
Achieving High Coverage for Floating-Point Code via Unconstrained Programming Zhoulai Fu Zhendong Su University of California, Davis, USA [email protected] [email protected] Abstract have driven the research community to develop a spectrum Achieving high code coverage is essential in testing, which of automated testing techniques for achieving high code gives us confidence in code quality. Testing floating-point coverage. code usually requires painstaking efforts in handling floating- A significant challenge in coverage-based testing lies in point constraints, e.g., in symbolic execution. This paper turns the testing of numerical code, e.g., programs with floating- the challenge of testing floating-point code into the oppor- point arithmetic, non-linear variable relations, or external tunity of applying unconstrained programming — the math- function calls, such as logarithmic and trigonometric func- ematical solution for calculating function minimum points tions. Existing solutions include random testing [14, 23], over the entire search space. Our core insight is to derive a symbolic execution [17, 24], and various search-based strate- representing function from the floating-point program, any of gies [12, 25, 28, 31], which have found their way into many whose minimum points is a test input guaranteed to exercise mature implementations [16, 39]. Random testing is easy to a new branch of the tested program. This guarantee allows employ and fast, but ineffective in finding deep semantic is- us to achieve high coverage of the floating-point program by sues and handling large input spaces; symbolic execution and repeatedly minimizing the representing function. its variants can perform systematic path exploration, but suf- We have realized this approach in a tool called CoverMe fer from path explosion and are weak in dealing with complex and conducted an extensive evaluation of it on Sun’s C math program logic involving numerical constraints. -

(And Misreading) the Draft Constitution in China, 1954
Textual Anxiety Reading (and Misreading) the Draft Constitution in China, 1954 ✣ Neil J. Diamant and Feng Xiaocai In 1927, Mao Zedong famously wrote that a revolution is “not the same as inviting people to dinner” and is instead “an act of violence whereby one class overthrows the authority of another.” From the establishment of the People’s Republic of China (PRC) in 1949 until Mao’s death in 1976, his revolutionary vision became woven into the fabric of everyday life, but few years were as violent as the early 1950s.1 Rushing to consolidate power after finally defeating the Nationalist Party (Kuomintang, or KMT) in a decades- long power struggle, the Chinese Communist Party (CCP) threatened the lives and livelihood of millions. During the Land Reform Campaign (1948– 1953), landowners, “local tyrants,” and wealthier villagers were targeted for repression. In the Campaign to Suppress Counterrevolutionaries in 1951, the CCP attacked former KMT activists, secret society and gang members, and various “enemy agents.”2 That same year, university faculty and secondary school teachers were forced into “thought reform” meetings, and businessmen were harshly investigated during the “Five Antis” Campaign in 1952.3 1. See Mao’s “Report of an Investigation into the Peasant Movement in Hunan,” in Stuart Schram, ed., The Political Thought of Mao Tse-tung (New York: Praeger, 1969), pp. 252–253. Although the Cultural Revolution (1966–1976) was extremely violent, the death toll, estimated at roughly 1.5 million, paled in comparison to that of the early 1950s. The nearest competitor is 1958–1959, during the Great Leap Forward. -

The Later Han Empire (25-220CE) & Its Northwestern Frontier
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations 2012 Dynamics of Disintegration: The Later Han Empire (25-220CE) & Its Northwestern Frontier Wai Kit Wicky Tse University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Asian History Commons, Asian Studies Commons, and the Military History Commons Recommended Citation Tse, Wai Kit Wicky, "Dynamics of Disintegration: The Later Han Empire (25-220CE) & Its Northwestern Frontier" (2012). Publicly Accessible Penn Dissertations. 589. https://repository.upenn.edu/edissertations/589 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/589 For more information, please contact [email protected]. Dynamics of Disintegration: The Later Han Empire (25-220CE) & Its Northwestern Frontier Abstract As a frontier region of the Qin-Han (221BCE-220CE) empire, the northwest was a new territory to the Chinese realm. Until the Later Han (25-220CE) times, some portions of the northwestern region had only been part of imperial soil for one hundred years. Its coalescence into the Chinese empire was a product of long-term expansion and conquest, which arguably defined the egionr 's military nature. Furthermore, in the harsh natural environment of the region, only tough people could survive, and unsurprisingly, the region fostered vigorous warriors. Mixed culture and multi-ethnicity featured prominently in this highly militarized frontier society, which contrasted sharply with the imperial center that promoted unified cultural values and stood in the way of a greater degree of transregional integration. As this project shows, it was the northwesterners who went through a process of political peripheralization during the Later Han times played a harbinger role of the disintegration of the empire and eventually led to the breakdown of the early imperial system in Chinese history. -

The Ideology and Significance of the Legalists School and the School Of
Advances in Social Science, Education and Humanities Research, volume 351 4th International Conference on Modern Management, Education Technology and Social Science (MMETSS 2019) The Ideology and Significance of the Legalists School and the School of Diplomacy in the Warring States Period Chen Xirui The Affiliated High School to Hangzhou Normal University [email protected] Keywords: Warring States Period; Legalists; Strategists; Modern Economic and Political Activities Abstract: In the Warring States Period, the legalist theory was popular, and the style of reforming the country was permeated in the land of China. The Seven Warring States known as Qin, Qi, Chu, Yan, Han, Wei and Zhao have successively changed their laws and set the foundation for the country. The national strength hovers between the valley and school’s doctrines have accelerated the historical process of the Great Unification. The legalists laid a political foundation for the big country, constructed a power framework and formulated a complete policy. On the rule of law, the strategist further opened the gap between the powers of the country. In other words, the rule of law has created conditions for the cross-border family to seek the country and the activity of the latter has intensified the pursuit of the former. This has sparked the civilization to have a depth and breadth thinking of that period, where the need of ideology and research are crucial and necessary. This article will specifically address the background of the legalists, the background of these two generations, their historical facts and major achievements as well as the research into the practical theory that was studies during that period. -

Dynasty Report Cards
Shang Dynasty Years: 1600-1046 BC Founder: Tang Religions/philosophies: oracle bones, ancestor worship, sacrifice Capital City: Anyang Inventions, Technology, and Achievements People of the Shang Dynasty are believed to have used calendars and developed knowledge of astronomy and math, thanks to inscriptions on tortoise shell that have been unearthed by archaeologists. The Shang calendar was at first lunar-based, but a solar-based one was developed by a man named Wan-Nien, who established a 365-day year through his observations and pinpointed the two solstices. The Shang Dynasty signified the start of the in China and was an advanced civilization for its time with sophisticated bronze works, ceramics and trinkets made from jade. Unlike their Bronze Age counterparts, Shang Dynasty artisans used piece-mold casting as opposed to the lost-wax method. This meant that they first made a model of the object they wanted to create before covering it in a clay mold. The clay mold would then be cut into sections, removed, and re-fired to create a new, unified one. By 1200 B.C., Shang armies were equipped with horse-drawn chariots. Before that, there is evidence of bronze-tipped spears, halberds (pointed axes) and bows. The language of the Shang Dynasty is an early form of modern Chinese. Chinese characters first appeared during the Shang Dynasty inscribed on cattle bone and tortoise shells. There is evidence of two numerological systems, one based on numbers from one to 10 and the other from one to 12. Other Information In the first half of Shang rule, royal burials included the burial of subordinates in the chambers alongside their ruler. -

To Strike the Strongest Blow
To Strike The Strongest Blow: Questions Remain Over Crackdown On 2009 Unrest In Urumchi A Report by the Uyghur Human Rights Project Washington, D.C. TABLE OF CONTENTS Introduction .......................................................................................................................3 Unclear Detention Numbers .............................................................................................4 Lack of Due Process in Detentions.................................................................................11 Misuse of Video Surveillance..........................................................................................15 Torture in Detention........................................................................................................18 Unfair Trials.....................................................................................................................19 Enforced Disappearances................................................................................................24 Letter to the Ambassador of China to the United States .............................................34 Appendix: Urumchi Evening News Article Translations ............................................36 Cover image: Montage of photos of 28 Uyghurs who have disappeared after July 5, 2009, from UighurBiz. Retrieved from: http://www.Uighurbiz.net/archives/15061 2 INTRODUCTION On July 5, 2009, in the city of Urumchi, Uyghur men, women and children peacefully assembled in People’s Square to protest government inaction -
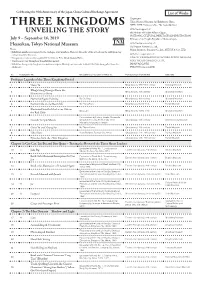
Three Kingdoms Unveiling the Story: List of Works
Celebrating the 40th Anniversary of the Japan-China Cultural Exchange Agreement List of Works Organizers: Tokyo National Museum, Art Exhibitions China, NHK, NHK Promotions Inc., The Asahi Shimbun With the Support of: the Ministry of Foreign Affairs of Japan, NATIONAL CULTURAL HERITAGE ADMINISTRATION, July 9 – September 16, 2019 Embassy of the People’s Republic of China in Japan With the Sponsorship of: Heiseikan, Tokyo National Museum Dai Nippon Printing Co., Ltd., Notes Mitsui Sumitomo Insurance Co.,Ltd., MITSUI & CO., LTD. ・Exhibition numbers correspond to the catalogue entry numbers. However, the order of the artworks in the exhibition may not necessarily be the same. With the cooperation of: ・Designation is indicated by a symbol ☆ for Chinese First Grade Cultural Relic. IIDA CITY KAWAMOTO KIHACHIRO PUPPET MUSEUM, ・Works are on view throughout the exhibition period. KOEI TECMO GAMES CO., LTD., ・ Exhibition lineup may change as circumstances require. Missing numbers refer to works that have been pulled from the JAPAN AIRLINES, exhibition. HIKARI Production LTD. No. Designation Title Excavation year / Location or Artist, etc. Period and date of production Ownership Prologue: Legends of the Three Kingdoms Period 1 Guan Yu Ming dynasty, 15th–16th century Xinxiang Museum Zhuge Liang Emerges From the 2 Ming dynasty, 15th century Shanghai Museum Mountains to Serve 3 Narrative Figure Painting By Qiu Ying Ming dynasty, 16th century Shanghai Museum 4 Former Ode on the Red Cliffs By Zhang Ruitu Ming dynasty, dated 1626 Tianjin Museum Illustrated