IN ACTION Understanding, Analyzing, and Generating Text with Python
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Soft Kites—George Webster
Page 6 The Kiteflier, Issue 102 Soft Kites—George Webster Section 1 years for lifting loads such as timber in isolated The first article I wrote about kites dealt with sites. Jalbert developed it as a response to the Deltas, which were identified as —one of the kites bending of the spars of large kites which affected which have come to us from 1948/63, that their performance. The Kytoon is a snub-nosed amazingly fertile period for kites in America.“ The gas-inflated balloon with two horizontal and two others are sled kites (my second article) and now vertical planes at the rear. The horizontals pro- soft kites (or inflatable kites). I left soft kites un- vide additional lift which helps to reduce a teth- til last largely because I know least about them ered balloon‘s tendency to be blown down in and don‘t fly them all that often. I‘ve never anything above a medium wind. The vertical made one and know far less about the practical fins give directional stability (see Pelham, p87). problems of making and flying large soft kites– It is worth nothing that in 1909 the airship even though I spend several weekends a year —Baby“ which was designed and constructed at near to some of the leading designers, fliers and Farnborough has horizontal fins and a single ver- their kites. tical fin. Overall it was a broadly similar shape although the fins were proportionately smaller. —Soft Kites“ as a kite type are different to deal It used hydrogen to inflate bag and fins–unlike with, compared to say Deltas, as we are consid- the Kytoon‘s single skinned fin. -

Kites in the Classroom
’ American Kitefliers Association KITES IN THE CLASSROOM REVISED EDITION by Wayne Hosking Copyright 0 1992 Wayne E. Hosking 5300 Stony Creek Midland, MI 48640 Editorial assistance from Jon Burkhardt and David Gomberg. Graphics by Wayne Hosking, Alvin Belflower, Jon Burkhardt, and Peter Loop. Production by Peter Loop and Rick Talbott. published by American Kitefliers Association 352 Hungerford Drive Rockville, MD 20850-4117 IN MEMORY OF DOMINA JALBERT (1904-1991) CONTENTS:CONTENTS: PREFACE. ........................................1 CHAPTER 1 INTRODUCTION. .3 HISTORY - KITE TRADITIONS - WHAT IS A KITE - HOW A KITE FLIES - FLIGHT CONTROL - KITE MATERIALS CHAPTER 2PARTS OF A KITE. .13 TAILS -- BRIDLE - TOW POINT - FLYING LINE -- KNOTS - LINE WINDERS CHAPTER 3KITES TO MAKE AND FLY..........................................19 1 BUMBLE BEE............................................................................................................... 19 2 TADPOLE ...................................................................................................................... 20 3CUB.......................................................................................................................21 4DINGBAT ........................................................................................................................ 22 5LADY BUG.................................................................................................................... 23 6PICNIC PLATE KITE.................................................................................................. -

Creative Design Creative Design
Number 50 The newsletter of the South Jersey Kite Flyers Volume #3 - 2004 him; he had two grandchildren, Christopher and Empty Place in the Sky ––– Ed Sarah. Spencer By Betty Hirschmann Each of us who knew Ed will have our own memories of him, and will deal with his passing in our own manner and time. If you get the chance, fly a kite and release it into the wind so On April 9, 2004, five days short of his 73 rd birthday, Ed that Ed can enjoy the experience too. Spencer passed away in his sleep. His son Scott and I were at a Good Friday Kite Fly in Lewes, DE, waiting for Ed to arrive. For those of you who wish to get in touch with Nancy, she is at When we got home that night (about the Manorcare Nursing Home Room #153, 1412 Marlton Pike 10:00 pm) there was a message on our – Rte 70, Cherry Hill, NJ 08034. answering machine asking that Scott call his sister Ellen. When Scott called, he ============================================ learned of the death of his father. Ed touched many people, in many ways. What I remember is that he could be Creative Design found out on the flying field with a smile by Dave Ciotti on his face and a chuckle in his heart. It seemed that he had no problems, at least What you are reading is the second draft of this narrative. This that’s the face he tried to show most of article was originally written at the 2004 the time, but life was not always what it MIKE in Ocean City, Maryland, at the appeared to be. -

A Decade of Kiting Memories by Peter and Sarah Bindon
THE In this edition Spring 2020 INSIDE: A decade of kiting memories by Peter and Sarah Bindon Also in this edition: ALSO IN THIS EDITION: Thailand and Malaysia Kite Tour Kite Competition – Mike Rourke wins again! KAP made easy with Alan Poxon Sarah Bindon takes the Questionnaire Challenge John’s new kite ...tails Alicja from Poland kite workshop Annual General Meeting NEW Chairman – Keith Proctor NEW Membership Secretary – Ian Duncalf A message from Keith; At the 2020 AGM I gave up the role of Membership Secretary that I Ian had held since 2011/12, and handed it over to Ian Duncalf who I believe is much better qualified to improve and update the system to allow online membership application and Keith with outgoing renewal. I took on the role of chairman but I’m still not sure how this Chairman Len Royles all came about! So this is my first official post in the NKG magazine. This year I think will be described as an “annus horribilis” for the Len stood down as disruption of everyday life as we know it. I fear that for a lot of people, Chairman after six life will never be the same again. We have never experienced this years but will continue before. But if we all follow the guidelines about staying at home, to play an active part washing hands, keeping your distance from others we can pick up in the Group by taking our kite-flying again, possibly later this year and if not then next year. the childrens’ rainbow Good luck and good health to you all and your loved ones in the delta kites to festivals. -

Meteorological Equipment Data Sheets
TM 750-5-3 TECHNICAL MANUAL METEOROLOGICAL EQUIPMENT DATA SHEETS HEADQUARTERS, DEPARTMENT OF THE ARMY 30 APRIL 1973 *TM 750–5–3 TECHNICAL MANUAL HEADQUARTERS DEPARTMENT OF THE ARMY No. 750–5–3 WASHINGTON, D.C., 30 April 1973 METEOROLOGICAL EQUIPMENT DATA SHEETS Paragraph Page SECTION I. INTRODUCTION Scope _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ 1 3 Purpose _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ 2 3 Organization of content _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ __ 3 3 US Army type classifications _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ 4 3 Currency of information _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ 5 4 Omitted data_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ 6 4 II. -

The Kiteflier
THE KITEFLIER ISSUE 66 JANUARY 1 996 PRICE£1.75 MAKE YOURSELF A WINNER WITH T~E C~.A.IN" "WVIT~ N"O N"A.1VIE A.IR"'QDRN WE'RE SECOND TO NONE RRISTOL KTT'£S ICIT'E 97 Trafalgar Street STaR£ BRIGHTON l b P itville P lace BN14ER Cot ham HiJJ T e i/Fu 1ST FOR CHOICE BRISTOL 01273 676740 BS66JY 1ST FOR SERVICE Tel: 0117 974 5010 1ST FOR QUALITY Fax: 0 117 973 7202 THE CHAIN WITH A COMPETITIVE EDGE Chain With No Name Members Roll of Honour includes: Team Member of Airkraft, 1995 World Cup Wmners KOSMIC Team Member of:XS, UK Masters Class Team KTT'£S 153 Stoke Team Member of Airheads 16 1 Ewell Road Ne win gt.on C h u rc h SURBITON Stree t Leader of Phoenix, 1995 UK National Pairs Winners KT66AW LONDON Top Placed UK Flyer at Tei/Fax: N16 OUH 0 181 390 2221 Tei/Fu:: London Arena Indoor Competition 0 171 275 8799 Power Kite Specialists Individual Masters Class Flyers Kite Festival Organisers Winter Sport Kite League Organisers WHO ELSE CAN OFFER TIDS MUCH EXPERTISE? WA.YON UIGU 6 Harris Arcade KTT'£S READING 3 Capuc hin Yard RGJ IDN WE FLY THEM AND FLOG THEM Churc h Street Tei/Fu:: HEREFORD 01734 568848 Te l: 01432 264206 Dear Reader Welcome to the first issue of 1996. With this issue members will find a copy of the 1996 Kite Society Handbook, with a comprehensive list of Kite Retailers and Kite Groups. TABLE OF CONTENTS It is at this time of year that we review the cost of producing The Kiteflier as well as the general costs of Letters 4 running the Kite Society. -

Kiting Summer 2007 Volume 29 Issue 2
Modegi & Co. In Waasshhiinnggttoonnashington Sleepover at Tookkiioki CCaammppCamp TTTuurrurnniinnggning JJaappaanneessee!!Japanese! National Kite Month NNAABBXX::NABX: VVVegas Buggying Ocean Shores Convention John Freeman’s Rockaway Bikini Festivals: Guam, France, China, IIttaallyyItaly,,, TTTexas, DC, Maryyllaanndd,,yland, OOrrOreeggoonnegon CONTENTS National Kite Kite Plan Cervia 33 Month 22 John Freeman 32 Everything’s Whole lotta fly- wants you to molto bene in ing going on have his bikini the Italian skies North KAPtions Berck-sur-mer What happens in American 5 Carl Bigras looks 24 34 Buggy Expo down on Canada France, doesn’t stay in France! Hi-jinx in the low desert Lincoln City Zilker Park Weifang Today a kite fes- 8 Indoors 25 Still flying in 36 tival, next year On stage and Austin after all the Olympics indoors in these years Oregon Sporting Life Guam’s Convention Throw your own Kites & Wishes 10 26 Preview 38 regional party Ray Bethell has It’s a XXX get- his shirt off on a together in beach again Ocean Shores K-Files MIKE/MASKC Smithsonian Amidst the 12 Glen and Tanna 27 Things are ducky 40 52 Haynes are on the beach in cherry blossoms, wrapped up in Ocean City, MD the Japanese kitemaking triumph Voices From Ft. Worden The Vault 14 Fancy sewing in 28 Wayne Hosking the Northwest is swarmed by 2 AKA Directory children 4 President’s Page 6 In Balance 7 Empty Spaces In The Sky MAKR 11 AKA News Fightin’ Words 20 29 Fancy sewing in 16 Event Calendar 20 Building an the Midwest 17 AI: Aerial Inquiry American 17 FlySpots tradition 18 Member Merchants 41 Regional Reports 52 People + Places + Things Toki Camp History Lesson 21 Greg Kono 30 On the cover: The Roby Pa- The journals of moves in with goda, built by Bermuda’s Philip Philippe one of Japan’s Jones, shadows the Washington Cottenceau greats Monument. -
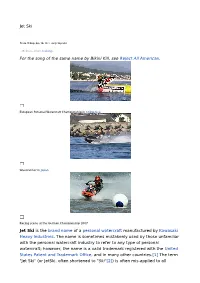
Jet Ski for the Song of the Same Name by Bikini Kill, See Reject All American. Jet Ski Is the Brand Name of a Personal Watercraf
Jet Ski From Wikipedia, the free encyclopedia (Redirected from Jet skiing) For the song of the same name by Bikini Kill, see Reject All American. European Personal Watercraft Championship in Crikvenica Waverunner in Japan Racing scene at the German Championship 2007 Jet Ski is the brand name of a personal watercraft manufactured by Kawasaki Heavy Industries. The name is sometimes mistakenly used by those unfamiliar with the personal watercraft industry to refer to any type of personal watercraft; however, the name is a valid trademark registered with the United States Patent and Trademark Office, and in many other countries.[1] The term "Jet Ski" (or JetSki, often shortened to "Ski"[2]) is often mis-applied to all personal watercraft with pivoting handlepoles manipulated by a standing rider; these are properly known as "stand-up PWCs." The term is often mistakenly used when referring to WaveRunners, but WaveRunner is actually the name of the Yamaha line of sit-down PWCs, whereas "Jet Ski" refers to the Kawasaki line. [3] [4] Recently, a third type has also appeared, where the driver sits in the seiza position. This type has been pioneered by Silveira Customswith their "Samba". Contents [hide] • 1 Histor y • 2 Freest yle • 3 Freeri de • 4 Close d Course Racing • 5 Safety • 6 Use in Popular Culture • 7 See also • 8 Refer ences • 9 Exter nal links [edit]History In 1929 a one-man standing unit called the "Skiboard" was developed, guided by the operator standing and shifting his weight while holding on to a rope on the front, similar to a powered surfboard.[5] While somewhat popular when it was first introduced in the late 1920s, the 1930s sent it into oblivion.[citation needed] Clayton Jacobson II is credited with inventing the personal water craft, including both the sit-down and stand-up models. -

Kap Guide BBHD
Notes on K I T E A E R I A L P H O T O G R A P H Y I N T R O D U C T I O N This guide is prepared as an introduction to the acquisition of photography using a kite to raise the camera. It is in 3 parts: Application Equipment Procedure It is prepared with the help and guidance from the world wide KAP community who have been generous with their expertise and support. Blending a love of landscape and joy in the flight of a kite, KAP reveals rich detail and captures the human scale missed by other (higher) aerial platforms. It requires patience, ingenuity and determination in equal measure but above all a desire to capture the unique viewpoint achieved by the intersection of wind, light and time. Every flight has the potential to surprise us with views of a familiar world seen anew. Mostly this is something that is done for the love of kite flying: camera positioning is difficult and flight conditions are unpredictable. If predictable aerial imagery is required and kite flying is not your thing then other UAV methods are recommended: if you are not happy flying a kite this is not for you. If you have not flown a kite then give it a go without a camera and see how you feel about it: kite flying at its best is a curious mix of exhilaration, spiritual empathy with the environment and relaxation of mind and body brought about by concentration of the mind on a single object in the landscape. -

January 2005 Issue 102 Price £2.00
Issue 102 January 2005 Price £2.00 We have moved to Tel: +44 (01525) 229 773 The Kite Centre Fax: +44 (01525) 229 774 Unit 1 Barleyfields [email protected] Sparrow Hall Farm Edlesborough Beds LU6 2ES The Airbow is a revolutionary hybrid which combines the carving turns and trick capabilities ~ I~ 11-~ 1 • 1 of dual line kites with the precise handling and '""-' • '-=' "-"' ~ total control of quad line flying. The unique 3D shape is symmetrical both left-to-right Airbow Kite and top-to-bottom, giving the kite equal stability £190 in powered flight in all directions and unprecedented recoverability from slack line trick and freestyle flying. Switchgrip handles Switchgrips are also available (Airbow dedicated handles) £24 Flying Techniques is an instructional DVD presented by three of the UK's most respected sport kite flyers; Andy Wardley, earl Robertshaw & James Robertshaw Flying The DVD is aimed at the kite flyer who wants to take their skills to the next level and is presented in a way that even Techniques a complete novice can follow. lt also details the methods for creating flying routines and concentrates DVD on the skills required to master four line and two line sports kites £20 including the Airbow, Revolution, Gemini, Matrix and Dot Matrix. Flying Techniques lasts 93 minutes and there are 20 minutes of extras. The Peak is a new entry level trick kite from DIDAK With its high aspect ratio and its anti tangle trick line arrangement PEAK makes it an ideal kite for the intermediate flier wishing to learn some of the more radical tricks, packaged complete with £48.90 Dyneema lines and Wriststraps. -

The Fighter Kites of Korea
The Fighter Kites of Korea In many countries throughout Asia, flying a kite usually means fighting with a kite. In India, Japan, Thailand, Pakistan, Afghanistan, Malaysia, and Korea, kite battles fill the skies at seasonal tournaments and festivals—and even in the streets after school. Fighters compete to cut each other’s kites out of the sky. Kites climb, swerve, and dive, trying to avoid the deadly friction from a competitor’s line coated with finely crushed glass or diamond dust. Just how popular is this sport? Perhaps seven of every ten of the billions of kites in Asia are fighter kites. And which do international competitors think are the toughest and fastest fighter kites in the world? The fighter kites of Korea. The Korean fighter kite is the country’s signature kite, the bang-pae yeon, a rectangular, bowed “shield” kite with a hole in the middle of the sail. Master kite makers cut the hanji (paper) sail a centimeter or two wider at the top than the bottom so that the kite will be rectangular after it is bowed. The frame uses five bamboo spars—one each across the top and the “waist” of the kite, a “spine,” and two diagonals. The spine and diagonals are carefully tapered toward the bottom, and the spar at the waist is very thin so that it will bend easily in the wind. The kites are made in different sizes, with larger kites flown in heavier winds. The width is usually two-thirds of the length, but some fighters prefer the speed and maneuverability of a width four-fifths of the length. -

A Brief Introduction to North American Fighter Kites and the Line Touch Game
A Brief Introduction to North American Fighter Kites and the Line Touch Game “North American style” fighter kites are small (~ 20” x 18”) single-line kites that you can maneuver by controlling the line tension. They are a smaller, faster, high-tech version of the traditional fighter kite flown in India, Pakistan, Afghanistan, and many other places. Traditional Indian fighter kite (back side). Bamboo North American fighter kite (front side). Carbon spine and bow, tissue paper sail. fiber spine, bow and stays; polyfilm sail. Flying a fighter kite is simple, but it takes practice to get good at it. When you pull on the line, the kite flies forward in a straight line. The harder you pull, the faster the kite goes. When releasing line, the kite spins. So, to make the kite go to the right, you wait while releasing line until the nose is pointing right. Then, start pulling. It’s all about the timing and knowing how your kite behaves when given slack. Pulling line into a pile at the flier’s Slipping line. The kite will be Kite in a low, horizontal pass. feet. The kite will be moving, spinning, perhaps hovering Attacking a kite to the left? perhaps to a high position. low over the sand. Escaping from one to the right? North American fighters have evolved to perform well in the line touch game. Fliers start ~10’ apart with kites in the air, away from each other in a neutral position, with about 100’ of line out. The starter (who may well be one of the two fliers) starts the point by yelling “Top” or “Bottom”.