Percussion Classification in Polyphonic Audio Recordings Using Localized Sound Models
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Percussion Family 1 Table of Contents
THE CLEVELAND ORCHESTRA WHAT IS AN ORCHESTRA? Student Learning Lab for The Percussion Family 1 Table of Contents PART 1: Let’s Meet the Percussion Family ...................... 3 PART 2: Let’s Listen to Nagoya Marimbas ...................... 6 PART 3: Music Learning Lab ................................................ 8 2 PART 1: Let’s Meet the Percussion Family An orchestra consists of musicians organized by instrument “family” groups. The four instrument families are: strings, woodwinds, brass and percussion. Today we are going to explore the percussion family. Get your tapping fingers and toes ready! The percussion family includes all of the instruments that are “struck” in some way. We have no official records of when humans first used percussion instruments, but from ancient times, drums have been used for tribal dances and for communications of all kinds. Today, there are more instruments in the percussion family than in any other. They can be grouped into two types: 1. Percussion instruments that make just one pitch. These include: Snare drum, bass drum, cymbals, tambourine, triangle, wood block, gong, maracas and castanets Triangle Castanets Tambourine Snare Drum Wood Block Gong Maracas Bass Drum Cymbals 3 2. Percussion instruments that play different pitches, even a melody. These include: Kettle drums (also called timpani), the xylophone (and marimba), orchestra bells, the celesta and the piano Piano Celesta Orchestra Bells Xylophone Kettle Drum How percussion instruments work There are several ways to get a percussion instrument to make a sound. You can strike some percussion instruments with a stick or mallet (snare drum, bass drum, kettle drum, triangle, xylophone); or with your hand (tambourine). -

Basic Snare Drum Tuning
Basic Snare Drum Tuning by Tom Freer Please follow these simple and basic instructions for tuning and adjusting your Pearl snare drum. In order for you to get and maintain the best possible sound out of your instrument, it will be important to save this sheet so that you can "tune up" the drum as the heads become broken in, and replace heads when necessary. YOU WILL NEED THE FOLLOWING TOOLS TO PROCEED: 1. DRUM KEY 2. RULER STEP ONE: Loosen the top head completely. Place the drum on a flat surface and unscrew all the tension rods so that there is no tension on the top head. You don't need to take them out, just loosen them all the way. Next, begin to tighten down each rod just until they touch the counter hoop (or rim) WITHOUT PULLING IT DOWN. Just screw the tension rod down until it just touches. Go across the drum and do the same to the opposite tension rod and repeat, always working across the drum head in opposites, this keeps the head very even. When all the tension rods are seated and just touching the counter hoop, take your ruler and beginning with the tension rod directly beside the strainer, measure the distance from underneath the counter hoop to the top of the lug. Repeat this process with the lug directly across the drum and repeat until all measurements are the same. Remember we are not concerned with how tight the head is right now, just how even the tension is. Now that the head is evenly tensioned, bring the top head up to pitch. -

Bluffer's Guide to the Art of Pipe Band Snare Drumming
by Libby O’Brien SNARE DRUM BLUFFER’S GUIDE BLUFFER’S Bluffer’s Guide to the Art of Pipe Band Snare Drumming FOR PIPERS T’S probably safe to say that there are few drummers that have a strong knowl- Crossing noises ya’ wee !X$!%©? I edge of the intricacies of the Great Any more cheek and you’ll Highland Bagpipe, piobaireachd and airtight never eat another meaty flan! seasoning and perhaps the same can be said for some pipers. While most pipers will have some knowledge of the art of snare drumming, there may be a few terms that may need explaining to fully understand exactly what drummers are talking about. After all, radamacues, paradiddles and mummy daddies can be confus- ing things. Of course, there are exceptions in that there are pipers who can play the snare drum, but for those not quite in the know, drummer Libby O’Brien gives her bluffer’s guide to the art of snare drumming. Originally from New Zealand, but now living in Glasgow, Libby has played with The Pipeband Club – Australia and Auckland & District Pipe Band and is now a snare drummer with the Robert Wiseman Dairies Vale of Atholl Pipe Band. Here she shares a few terms to help you to impress your friends with your knowledge of all things drumming. The Drag While some pipers may mistake a drag for what we drummers refer to when pipers spend hours tuning their pipes at band practice, it is a simple rudiment that is regularly found in drumming music. Whilst reasonably simple, this rudiment is often the bane of many drummers’ lives, especially when attempting to play one on the left hand. -

Synthesized Drum Sounds
Synthesized Drum Sounds Snare Drum Crack of the drum – a fast glissando of a square wave over multiple octaves. Make it so that you hear the gliss as a quick blip sound rather than hearing the gliss. This means it should be very short. The center frequency of the gliss should be about 600-800hz, so you probably want to gliss from over 1000 to below 400. Metal Snares – WhiteNoise with a longer envelope than the crack sound above Filter – Send both the Crack of the Drum and the WhiteNoise through a Low Pass Filter Resonance of the drum shell – a sound about as long as the snare sound. This should be a sine wave oscillator at about 400hz, that drops about a semitone (25hz at 400) over the duration of the sound. Add the filtered crack and snares to the resonance sound. Bass Drum Crack of the drum – same as the snare, but lower the frequencies of the starting and end points of the gliss. Maybe make a gliss from 400 to 50. I feel like you might want to almost hear the glissing note with the bass drum Resonance of the drum shell –This should be a sine wave oscillator at about 100hz, that drops about a semitone (25hz at 400) over the duration of the sound. Add the two sounds together. Hi-Hat Crack of the drum – an even faster glissando of a square wave over multiple octaves. Make the center freq of the gliss to be about 2000hz, significantly higher than the snare drum, and make the gliss only about 2 octaves, so a quick gliss from 4000 to 1000hz should work. -
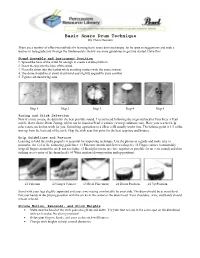
Basic Snare Drum Technique by Thom Hannum
Basic Snare Drum Technique By Thom Hannum There are a number of effective methods for learning basic snare drum technique. So be open to suggestions and seek a teacher to help guide you through the fundamentals. Below are some guidelines to get you started. Have fun! Stand Assembly and Instrument Position 1. Spread the base of the stand far enough to create a stable platform. 2. Insert the top into the base of the stand. 3. Place the drum into the basket while avoiding contact with the snare strainer. 4. The drum should be at about waist level and slightly angled for your comfort. 5. Tighten all stand wing nuts. Step 1 Step 2 Step 3 Step 4 Step 5 Tuning and Stick Selection Now it’s time to tune the drum for the best possible sound. I recommend following the steps outlined in Tom Freer’s Pearl article, Basic Snare Drum Tuning, which can be found at Pearl’s website (www.pearldrum.com). Have your teacher help select snare sticks that work for you. Something equivalent to a 2B or a 5B usually works fine. The balance point is 1/3 of the way up from the butt end of the stick. Grip the stick near this point for the best response and bounce. Grip Guidelines and Posture Learning to hold the sticks properly is essential for improving technique. Use the photos as a guide and make sure to memorize the feel of the following guidelines: #1 Fulcrum (thumb and first two fingers), #2 Finger contact (comfortably wrap all fingers around the stick; not too tight), #3 Bead placement (as close together as possible for an even sound) and then striking area (center of the drum head), #4 Wrist motion (down position and up position). -

ISSN 1661-8211 | 112. Jahrgang | 31. August 2012
2012/16 ISSN 1661-8211 | 112. Jahrgang | 31. August 2012 Redaktion und Herausgeberin: Schweizerische Nationalbibliothek NB, Hallwylstrasse 15, CH-3003 Bern Erscheinungsweise: halbmonatlich, am 15. und 30. jeden Monats ISSN 1661-8211 © Schweizerische Nationalbibliothek NB, CH-3003 Bern. Alle Rechte vorbehalten 782.1 Das Schweizer Buch 2012/16 782.4 Weltliche Vokalformen 782 Vokalmusik Formes de musique profane Forme vocali profane Musique vocale Furmas vocalas profanas Musica vocale Secular vocal forms Musica vocala 12–7 NB 001675399 Vocal music 100 Spielpartituren zum Liederbuch "100 x singen" [Musikdruck] : für alle Arten Instrumente : Streich-, Blas- und Tasteninstrumente, Gitarre, Orff-Instrumente / [Hrsg.:] Hansjörg Brugger. – Zofingen : "Aargauer Spielbuch", H. Brugger, cop. 2005. – 112 S. ; 30 cm Liedtexte in verschiedenen Sprachen 782.1 Dramatische Vokalformen, Opern Formes dramatiques de musique vocale, opéras 12–8 NB 001656607 Forme vocali drammatiche, opere Bächinger, Gabriela. – Chumm i miini Wält [Musikdruck] : 18 Furmas vocalas dramaticas, operas neui Chinderlieder / Gabriela Bächinger. – [Bremgarten AG Dramatic vocal forms, operas (Itenhardstr. 58)] : bmusic, cop. 2011. – 20 S. : Ill. ; 30 cm + 1 Compact Disc (12 cm) 12–1 NB 001654313 Ein- und zweistimmige Lieder mit Bezifferung für Begleitinstrument. – ISBN Furrer, Beat, 1954-. – Fama [Musikdruck] : Hörtheater für grosses 978–303–303–1326 (Liederbuch). ISBN 978–303–303–1319 (CD) Ensemble, acht Stimmen und Schauspielerin : 2004-2005 / Beat Furrer. – Partitur. – Kassel ; Basel [etc.] : Bärenreiter-Verlag, cop. 12–9 NB 001656985 2005. – 1 Partitur (216 S.) ; 42 cm Bächinger, Gabriela. – Sing im Advänt! [Musikdruck] : 19 Kin- derlieder / von Gabriela Bächinger ; Rahmengeschichte von Heinz "Auftragskomposition für die Donaueschinger Musiktage 2005". – "Leihmate- rial". – BA 7770 Bärenreiter-Verlag Lüthi. – [Küsnacht (Krummackerstr. -

Automatic Classification of Drum Sounds with Indefinite Pitch
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Biblioteca Digital da Produção Intelectual da Universidade de São Paulo (BDPI/USP) Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2015-07 Automatic classification of drum sounds with indefinite pitch International Joint Conference on Neural Network, 2015, Killarney. http://www.producao.usp.br/handle/BDPI/49424 Downloaded from: Biblioteca Digital da Produção Intelectual - BDPI, Universidade de São Paulo Automatic Classification of Drum Sounds with Indefinite Pitch Vinfcius M. A. Souza Nilson E. Souza-Filho Gustavo E. A. P. A. Batista Department of Acoustic Engineering Institute of Mathematics and Computer Science Federal University of Santa Maria, Brazil University of Sao Paulo, Brazil [email protected] {vsouza, gbatista}@icmc.usp.br Abstract-Automatic classification of musical instruments is Many research papers in Machine Learning and Signal an important task for music transcription as well as for pro Processing literature focus in the classification of string or fessionals such as audio designers, engineers and musicians. wind harmonic instruments and only a limited effort has been Unfortunately, only a limited amount of effort has been conducted conducted to classify percussion instruments (an interesting to automatically classify percussion instrument in the last years. review can be found in [1]). The main difference between The studies that deal with percussion sounds are usually restricted percussion and another instruments is the fact that the per to distinguish among the instruments in the drum kit such as cussion produces indefinite pitch or unpitched sounds. -

Triangle & Tambourine
○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○ ○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○ 1 Triangle & 2001 Tambourine Rich Holly NASHVILLE NOVEMBER 14–17 ○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○○ Playing percussion accessories may be some of the most gratifying performance experiences you will have. Why? Because you can be creative! Although there are time-honored traditions on how to play these instru- ments, in the last 30+ years we have seen and heard several variations on playing techniques and available sounds. Percussionists from around the world, in classical, pop, jazz, studio, and world music settings have been discovering and utilizing these other techniques with great success. It is important that you know and understand the basic playing techniques and available sounds first. These will serve you quite well in concert band, wind ensemble, and orchestral settings. Many of you will have the opportunity to play percussion in a jazz ensemble or perhaps in a band of your own. That’s where these performance variations will really come into play. These variations are based on the performance techniques of similar instruments from cultures around the world, and today’s orchestral players are finding many of these quite useful, too. The most important thing is to have fun! Try these only as a starting point – there is no limit to the use of your own creativity. Triangle When holding the triangle in a clip in the standard fashion, it is possible and often desirable to muffle the sound of the triangle with the heel and/or the fingers of the hand that is holding the clip. The following ex- ample is one way to attain a useful pattern using this technique. -

Choosing a Drum Set for Worship
Choosing a Drum Set for Worship We hope this guide will help you find the right drum set and drum hardware that fits your playing style and needs. Whether it is an affordable starter set or a sophisticated, arena-worthy acoustic or electronic kit, this guide will help you identify the right combination of gear to match your budget and percussion skills. You will learn about the elements that go into making drums and cymbals, and what to consider when shopping for drums. Before choosing a drum set, you need to be familiar with the components that go into it, these include: The Snare Drum, the Bass Drum, one or more Mounted Toms and a Floor Tom. The two other essential components that complete a full drum set, Cymbals and Hardware. We have also included a section on how to reduce acoustic drum volume, a microphone alternative, and a section on electronic drums. If you are unfamiliar with any of the terms used here, please see the Glossary of Terms at the end of this document. Enjoy! Parts of the Drum Set ANATOMY OF A DRUM TOP (BATTER) HEAD: The most basic component of a drum, the head is a round membrane made of a synthetic material usually mylar, that is stretched across the shell, with varying degrees of tension. HOOP: The drum hoop is usually made of either cast or stamped metal, although some drummers prefer wood hoops. Hoops are constructed with a flange shaped to hold the head on the shell for tensioning. TENSION ROD: These mount through holes in the hoop and thread into the lug to maintain the desired tension. -

The Percussion Family
The Percussion Family The percussion family is the largest family in the orchestra. Percussion instruments include any instrument that makes a sound when it is hit, shaken, or scraped. It's not easy to be a percussionist because it takes a lot of practice to hit an instrument with the right amount of strength, in the right place and at the right time. Some percussion instruments are tuned and can sound different notes, like the xylophone, timpani or piano, and some are untuned with no definite pitch, like the bass drum, cymbals or castanets. Percussion instruments keep the rhythm, make special sounds and add excitement and color. Unlike most of the other players in the orchestra, a percussionist will usually play many different instruments in one piece of music. The most common percussion instruments in the orchestra include the timpani, xylophone, cymbals, triangle, snare drum, bass drum, tambourine, maracas, gongs, chimes, celesta, and piano. The piano is a percussion instrument. You play it by hitting its 88 black and white keys with your fingers, which suggests it belongs in the percussion family. The piano has the largest range of any instrument in the orchestra. It is a tuned instrument, and you can play many notes at once using both your hands. Within the orchestra the piano usually supports the harmony, but it has another role as a solo instrument (an instrument that plays by itself), playing both melody and harmony. Timpani look like big polished bowls or upside-down teakettles, which is why they're also called kettledrums. They are big copper pots with drumheads made of calfskin or plastic stretched over their tops. -

TC 1-19.30 Percussion Techniques
TC 1-19.30 Percussion Techniques JULY 2018 DISTRIBUTION RESTRICTION: Approved for public release: distribution is unlimited. Headquarters, Department of the Army This publication is available at the Army Publishing Directorate site (https://armypubs.army.mil), and the Central Army Registry site (https://atiam.train.army.mil/catalog/dashboard) *TC 1-19.30 (TC 12-43) Training Circular Headquarters No. 1-19.30 Department of the Army Washington, DC, 25 July 2018 Percussion Techniques Contents Page PREFACE................................................................................................................... vii INTRODUCTION ......................................................................................................... xi Chapter 1 BASIC PRINCIPLES OF PERCUSSION PLAYING ................................................. 1-1 History ........................................................................................................................ 1-1 Definitions .................................................................................................................. 1-1 Total Percussionist .................................................................................................... 1-1 General Rules for Percussion Performance .............................................................. 1-2 Chapter 2 SNARE DRUM .......................................................................................................... 2-1 Snare Drum: Physical Composition and Construction ............................................. -

Requirements for Audition Sub-Principal Percussion
Requirements for Audition 1 Requirements for Audition Sub-Principal Percussion March 2019 The NZSO tunes at A440. Auditions must be unaccompanied. Solo 01 | BACH | LUTE SUITE IN E MINOR MVT. 6 – COMPLETE (NO REPEATS) 02 | DELÉCLUSE | ETUDE NO. 9 FROM DOUZE ETUDES - COMPLETE Excerpts BASS DRUM 7 03 | BRITTEN | YOUNG PERSON’S GUIDE TO THE ORCHESTRA .................................. 7 04 | MAHLER | SYMPHONY NO. 3 MVT. 1 ......................................................................... 8 05 | PROKOFIEV | SYMPHONY NO. 3 MVT. 4 .................................................................... 9 06 | SHOSTAKOVICH | SYMPHONY NO. 11 MVT. 1 .........................................................10 07 | STRAVINSKY | RITE OF SPRING ...............................................................................10 08 | TCHAIKOVSKY | SYMPHONY NO. 4 MVT. 4 ..............................................................12 BASS DRUM WITH CYMBAL ATTACHMENT 13 09 | STRAVINSKY | PETRUSHKA (1947) ...........................................................................13 New Zealand Symphony Orchestra | Sub-Principal Percussion | March 2019 2 Requirements for Audition CYMBALS 14 10 | DVOŘÁK | SCHERZO CAPRICCIOSO ........................................................................14 11 | MUSSORGSKY | NIGHT ON BALD MOUNTAIN .........................................................14 12 | RACHMANINOV | PIANO CONCERTO NO. 2 MVT. 3 ................................................15 13 | SIBELIUS | FINLANDIA ................................................................................................15