Essays on the Analysis of High-Dimensional Dynamic Games and Data Combination by Carlos Andrew Manzanares
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Overview and Trends
9310-01 Chapter 1 10/12/99 14:48 Page 15 1 M Overview and Trends The Transportation Research Board (TRB) study committee that pro- duced Winds of Change held its final meeting in the spring of 1991. The committee had reviewed the general experience of the U.S. airline in- dustry during the more than a dozen years since legislation ended gov- ernment economic regulation of entry, pricing, and ticket distribution in the domestic market.1 The committee examined issues ranging from passenger fares and service in small communities to aviation safety and the federal government’s performance in accommodating the escalating demands on air traffic control. At the time, it was still being debated whether airline deregulation was favorable to consumers. Once viewed as contrary to the public interest,2 the vigorous airline competition 1 The Airline Deregulation Act of 1978 was preceded by market-oriented administra- tive reforms adopted by the Civil Aeronautics Board (CAB) beginning in 1975. 2 Congress adopted the public utility form of regulation for the airline industry when it created CAB, partly out of concern that the small scale of the industry and number of willing entrants would lead to excessive competition and capacity, ultimately having neg- ative effects on service and perhaps leading to monopolies and having adverse effects on consumers in the end (Levine 1965; Meyer et al. 1959). 15 9310-01 Chapter 1 10/12/99 14:48 Page 16 16 ENTRY AND COMPETITION IN THE U.S. AIRLINE INDUSTRY spurred by deregulation now is commonly credited with generating large and lasting public benefits. -

Appendix C Informal Complaints to DOT by New Entrant Airlines About Unfair Exclusionary Practices March 1993 to May 1999
9310-08 App C 10/12/99 13:40 Page 171 Appendix C Informal Complaints to DOT by New Entrant Airlines About Unfair Exclusionary Practices March 1993 to May 1999 UNFAIR PRICING AND CAPACITY RESPONSES 1. Date Raised: May 1999 Complaining Party: AccessAir Complained Against: Northwest Airlines Description: AccessAir, a new airline headquartered in Des Moines, Iowa, began service in the New York–LaGuardia and Los Angeles to Mo- line/Quad Cities/Peoria, Illinois, markets. Northwest offers connecting service in these markets. AccessAir alleged that Northwest was offering fares in these markets that were substantially below Northwest’s costs. 171 9310-08 App C 10/12/99 13:40 Page 172 172 ENTRY AND COMPETITION IN THE U.S. AIRLINE INDUSTRY 2. Date Raised: March 1999 Complaining Party: AccessAir Complained Against: Delta, Northwest, and TWA Description: AccessAir was a new entrant air carrier, headquartered in Des Moines, Iowa. In February 1999, AccessAir began service to New York–LaGuardia and Los Angeles from Des Moines, Iowa, and Moline/ Quad Cities/Peoria, Illinois. AccessAir offered direct service (nonstop or single-plane) between these points, while competitors generally offered connecting service. In the Des Moines/Moline–Los Angeles market, Ac- cessAir offered an introductory roundtrip fare of $198 during the first month of operation and then planned to raise the fare to $298 after March 5, 1999. AccessAir pointed out that its lowest fare of $298 was substantially below the major airlines’ normal 14- to 21-day advance pur- chase fares of $380 to $480 per roundtrip and was less than half of the major airlines’ normal 7-day advance purchase fare of $680. -

Customers First Plan, Highlighting Definitions of Terms
RepLayout for final pdf 8/28/2001 9:24 AM Page 1 2001 Annual Report [c u s t o m e r s] AIR TRANSPORT ASSOCIATION RepLayout for final pdf 8/28/2001 9:24 AM Page 2 Officers Carol B. Hallett President and CEO John M. Meenan Senior Vice President, Industry Policy Edward A. Merlis Senior Vice President, Legislative and International Affairs John R. Ryan Acting Senior Vice President, Aviation Safety and Operations Vice President, Air Traffic Management Robert P. Warren mi Thes Air Transports i Associationo n of America, Inc. serves its Senior Vice President, member airlines and their customers by: General Counsel and Secretary 2 • Assisting the airline industry in continuing to prov i d e James L. Casey the world’s safest system of transportation Vice President and • Transmitting technical expertise and operational Deputy General Counsel kn o w l e d g e among member airlines to improve safety, service and efficiency J. Donald Collier Vice President, • Advocating fair airline taxation and regulation world- Engineering, Maintenance and Materiel wide, ensuring a profitable and competitive industry Albert H. Prest Vice President, Operations Nestor N. Pylypec Vice President, Industry Services Michael D. Wascom Vice President, Communications Richard T. Brandenburg Treasurer and Chief Financial Officer David A. Swierenga Chief Economist RepLayout for final pdf 8/28/2001 9:24 AM Page 3 [ c u s t o m e r s ] Table of Contents Officers . .2 The member airlines of the Air Mission . .2 President’s Letter . .5 Transport Association are committed to Goals . .5 providing the highest level of customer Highlights . -

Forward-Thinking Efficient Competitive
EFFICIENT COMPETITIVE FORWARD-THINKING ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ 2013 ANNUAL REPORT 2013 HIGHLIGHTS ADM +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ FINANCIAL RETROSPECTIVE OPERATIONS (IN THOUSANDS OF DOLLARS) 2011-2013 2013 2012 2011 20101 2009 Passenger traffic Cargo volume (metric tons) Aircraft movements 2011 13,668,829 2011 189,318 2011 253,298 Revenues $ 446,584 $ 435,461 $ 426,968 $ 389,314 $ 350,968 2012 13,809,820 2012 185,028 2012 243,436 Excess (deficiency) 2013 14,095,272 2013 177,165 2013 234,638 of revenues over expenses 13,625 6,941 5,423 (9,040) (8,989) ++++++++++++++++++++++++++++++++++++ +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ EBITDA 197,835 189,603 183,978 2 163,974 2 151,466 Investments $ 177,353 $ 194,722 $ 113,685 $ 64,601 $ 186,414 REAL ESTATE AND COMMERCIAL REAL ESTATE DEVELOPMENT DEVELOPMENT 1. The Corporation adopted International Financial Reporting Standards (IFRS) as of its fiscal year beginning January 1, 2010. 2013 2011-2013 2. Excluding the write-down in 2008 (or gain in 2010 and 2011) on investments in floating rate notes (originally ABCP). New leases Investments generated Jobs created (In square metres) (In millions of dollars) Estimates -

The Evolution of U.S. Commercial Domestic Aircraft Operations from 1991 to 2010
THE EVOLUTION OF U.S. COMMERCIAL DOMESTIC AIRCRAFT OPERATIONS FROM 1991 TO 2010 by MASSACHUSETTS INSTME OF TECHNOLOGY ALEXANDER ANDREW WULZ UL02 1 B.S., Aerospace Engineering University of Notre Dame (2008) Submitted to the Department of Aeronautics and Astronautics in PartialFulfillment of the Requirementsfor the Degree of MASTER OF SCIENCE at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY June 2012 0 2012 Alexander Andrew Wulz. All rights reserved. .The author hereby grants to MIT permission to reproduce and to distribute publicly paper and electronic copies of this thesis document in whole or in part in any medium now known or hereafter created. Signature of Author ..................................................................... .. ...................... Department of Aeronautr and Astronautics n n May 11, 2012 Certified by ............................................................................ Peter P. Belobaba Principle Research Scientist of Aeronautics and Astronautics / Thesis Supervisor A ccepted by ................................................................... Eytan H. Modiano Professor of Aeronautics and Astronautics Chair, Graduate Program Committee 1 PAGE INTENTIONALLY LEFT BLANK 2 THE EVOLUTION OF U.S. COMMERCIAL DOMESTIC AIRCRAFT OPERATIONS FROM 1991 TO 2010 by ALEXANDER ANDREW WULZ Submitted to the Department of Aeronautics and Astronautics on May 11, 2012 in PartialFulfillment of the Requirementsfor the Degree of MASTER OF SCIENCE IN AERONAUTICS AND ASTRONAUTICS ABSTRACT The main objective of this thesis is to explore the evolution of U.S. commercial domestic aircraft operations from 1991 to 2010 and describe the implications for future U.S. commercial domestic fleets. Using data collected from the U.S. Bureau of Transportation Statistics, we analyze 110 different aircraft types from 145 airlines operating U.S. commercial domestic service between 1991 and 2010. We classify the aircraft analyzed into four categories: turboprop, regional jet, narrow-body, and wide-body. -

Congressional Record United States Th of America PROCEEDINGS and DEBATES of the 106 CONGRESS, FIRST SESSION
E PL UR UM IB N U U S Congressional Record United States th of America PROCEEDINGS AND DEBATES OF THE 106 CONGRESS, FIRST SESSION Vol. 145 WASHINGTON, TUESDAY, OCTOBER 5, 1999 No. 133 Senate The Senate met at 9:30 a.m. and was SCHEDULE If Congress does not reauthorize the called to order by the President pro Mr. MCCAIN. Mr. President, today Airport Improvement Program (AIP), tempore [Mr. THURMOND]. the Senate will resume consideration the Federal Aviation Administration of the pending amendments to the FAA (FAA) will be prohibited from issuing PRAYER bill. Senators should be aware that much needed grants to airports in every state, regardless of whether or The Chaplain, Dr. Lloyd John rollcall votes are possible today prior not funds have been appropriated. We Ogilvie, offered the following prayer: to the 12:30 recess in an attempt to have now entered fiscal year 2000, and Lord of all life, our prayer is like complete action on the bill by the end we cannot put off reauthorization of breathing. We breathe in Your Spirit of the day. As a reminder, first-degree the AIP. The program lapsed as of last and breathe out praise to You. Help us amendments to the bill must be filed to take a deep breath of Your love, Friday. Every day that goes by without by 10 a.m. today. As a further re- an AIP authorization is another day peace, and joy so that we will be re- minder, debate on three judicial nomi- freshed and ready for the day. -

January 2015
THE SOURCE FOR AIRFREIGHT LOGISTICS International Edition • AirCargoWorld.com • Dec. 2014/Jan. 2015 OLIVER EVANS CHIEF CARGO OFFICER SWISS INTERNATIONAL AIR LINES AIR CARGO EXECUTIVE OF THE YEAR p.20 GAME CHANGERS: THREE TOP EXECS SHAPING THE INDUSTRY’S FUTURE p.24 Contents AIR CARGO EXECUTIVE OF THE YEAR Volume 17 • Number 11 • December 2014/January 2015 OLIVER EVANS A LEADER IN ANY LANGUAGE p.20 News Inside: 7 UpFront IATA’s five-year prediction, TNT hits the road and more 8 Asia Cargolux eyes new trans-Pacific venture 12 Africa & Middle East Cargo carriers continue service in hot zones GAME CHANGERS 14 Europe Three top airfreight executives shaping the industry’s future IAG Cargo launches EuroConnector service 17 Americas Could JFK’s freight move upstate? Departments 4 Publisher’s Note 10 Cargo Chat: Martin Drew 40 Bottom Line p.28 WORLD AIRFREIGHT DIRECTORY 42 Classifieds Our annual reference guide for airlines, airports, forwarders 44 People and other airfreight professionals from around the globe 45 Events / Advertiser’s Index 46 Forwarders’ Forum Air Cargo World (ISSN 1933-1614) is published monthly and owned by Royal Media. Air Cargo World is located at 1080 Holcomb Bridge Rd., Suite 255, Roswell, GA 30076. Production office is located at 2033 Sixth Avenue, Suite 830, Seattle WA 98121; telephone 206-587-6537. Air Cargo World is a registered trademark. Periodicals postage paid at Downers Grove, IL and at additional mailing offices. Subscription rates: 1 year, $80; 2 year $128; outside USA surface mail/1 year $120; 2 year $216. Single copies $20. Express Delivery Guide, Carrier Guide, Freight Forwarder Directory and Airport Directory single copies $14.95 domestic; $21.95 overseas. -

EXPERT REPORT of MICHAEL E. LEVINE in Re
EXPERT REPORT of MICHAEL E. LEVINE in re: Brady et. al. v. Air Line Pilots Association, et. al Civil Action No. 02-cv-02917-JEI (D.N.J.) 1 Table of Contents I. Introduction ...................................................................................................................... 3 A. Qualifications ............................................................................................................... 3 B. Overview of Assignment ........................................................................................... 5 C. Summary of Opinions ................................................................................................ 5 D. Summary of Plaintiffs’ Expert Opinions ................................................................. 7 II. TWA Was Structurally Unsound and No Longer Viable as a Standalone Airline ................................................................................................................................. 9 A. Historical Overview of TWA’s Competitive Position ........................................ 10 B. TWA’s Inability To Survive with a Single Hub in St. Louis ............................... 12 C. The Impact of Southwest Airlines Competition at St. Louis ............................. 17 D. The American Acquisition Was TWA’s Only Alternative to Liquidation ....... 21 III. The Challenges to Seniority Integration at American Airlines .............................. 26 A. The Unique Importance of Labor Relations in the Airline Industry ................ 26 B. The Impact of -

2002 Annual Report
Kellogg_air 6/18/02 12:00 PM Page 1 2002 ANNUAL REPORT FOR OSPACIOUS beautiful SKIES, Kellogg_air 6/18/02 12:00 PM Page 2 OFFICERS Carol B. Hallett President and CEO Malcolm B.“Mac” Armstrong Senior Vice President, TABLE OF CONTENTS Operations and Safety John M. Meenan Officers . .2 Senior Vice President, Industry Policy Mission . .2 Edward A. Merlis Goals . .4 Senior Vice President, President’s Letter . .5 Legislative and International Affairs Highlights . .6 Robert P. Warren Industry Review . .9 Senior Vice President, Traffic . .9 General Counsel and Secretary Capacity . .10 Fleet . .10 M. Bradley Ballance Revenues . .11 Vice President, E-Business Expenses . .12 James L. Casey Balance Sheet . .13 Vice President and Earnings . .13 Deputy General Counsel Taxes and Fees . .13 J. Donald Collier Environmental Progress . .14 Vice President, Facts and Figures . .15 Engineering, Maintenance Definitions of Terms . .24 and Materiel Index of Charts and Tables . .24 Member Airlines . .27 Albert H. Prest Vice President, Flight Operations CREDITS Pages 1-26: Excerpt from America the Beautiful (1913 version), by Katharine Lee Bates. Nestor N. Pylypec Page 3: Landscape photograph Under the Rainbow, copyright Larry Kanfer, Minneapolis. Vice President, Industry Services REPORT CONTENT John R. Ryan Unless otherwise noted, the data provided in this report reflects the activity of 100 U.S. scheduled airlines (Major, National and Regional passenger and cargo Vice President, Air Traffic Management airlines as defined by the U.S. Department of Transportation under Chapter 411 of Title 49 of the U.S. Code—see page 19 of this report). Michael D.Wascom In some cases numbers in this report may not total, due to rounding. -

Change 3, FAA Order JO 7340.2B, Contractions
U.S. DEPARTMENT OF TRANSPORTATION JO 7340.2B CHANGE FEDERAL AVIATION ADMINISTRATION CHG3 Air Traffic Organization Policy Effective Date: October 20, 2011 SUBJ: Contractions 1. Purpose of This Change. This change transmits revised pages to Federal Aviation Administration Order JO 7340.2B, Contractions. 2. Audience. This change applies to all Air Traffic Organization (ATO) personnel and anyone using ATO directives. 3. Where Can I Find This Change? This change is available on the FAA Web site at http://faa.gov/air_traffic/publications and https://employees.faa.gov/tools_resources/orders_notices/. 4. Distribution. This change is distributed to selected offices in Washington headquarters, regional offices, service area offices, the William J. Hughes Technical Center, and the Mike Monroney Aeronautical Center; to all field offices and field facilities; to all airway facilities field offices; to all international aviation field offices, airport district offices, and flight standards district offices; and to interested aviation public. 5. Disposition of Transmittal. Retain this transmittal until superseded by a new basic order. 6. Page Control Chart. See the page control chart attachment. <QLJ Tizabeth L. Ray Vice President, Mission Support Services Air Traffic Organization Date: 7""^ A// Distribution: ZAT-734, ZAT-464 Initiated By: AJV-0 Vice President, Mission Support Services 10/20/11 JO 7340.2B CHG 3 PAGE CONTROL CHART REMOVE PAGES DATED INSERT PAGES DATED CAM 1−1 through CAM 1−19 . 6/30/11 CAM 1−1 through CAM 1−16 . 10/20/11 TOC−i and TOC−ii . 11/18/10 TOC−i and TOC−ii . 10/20/11 2−1−11 . 11/18/10 2−1−11 . -

November 1999
Aviation Strategy Issue No: 25 November 1999 The unpredictable dynamics of alliance competition CONTENTS Analysis “ n the future airline competition will be competition between alliances" - Ithis vision of the evolution of the airline industry from Jurgen Weber Potential Star attack CEO of Lufthansa is now widely accepted. But its implication of rational on UK premium traffic 2 global competition between integrated networks is far from today's reality. Recent proxy battles between the alliances - see pages 2 and 3 - Canada: restructuring plan reveal the unpredictable dynamics of alliances and the tensions between lost in financial battle 3 the members. The concept of cross-equity links had been abandoned in forming the What does EADS mean mew global alliances (except where it was considered necessary to sup- for Airbus and the A3XX? 4-5 port a privatisation as with Thai next year). Now in the case of Air Canada, the senior members of Star find themselves having to invest funds to stave United: what’s the off a hostile bid from American and others. optimal growth rate? 5-6 Star is expanding well beyond its original plan of 10 members, with Austrian, ANA, SIA, Mexicana, BMA and a Chinese airline all in the Schiphol: what’s the process of joining. Oneworld is adding Iberia, Aer Lingus and Lan Chile in optimal level of pollution? 7-8 quick succession. As such it is very difficult to maintain any semblance of equality between the participants. Briefing This table summarises the recent profitability of the alliance members and gives a clear indication of their relative power. -
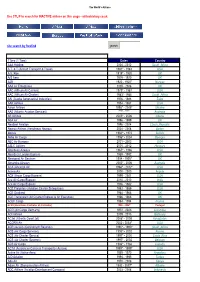
Use CTL/F to Search for INACTIVE Airlines on This Page - Airlinehistory.Co.Uk
The World's Airlines Use CTL/F to search for INACTIVE airlines on this page - airlinehistory.co.uk site search by freefind search Airline 1Time (1 Time) Dates Country A&A Holding 2004 - 2012 South_Africa A.T. & T (Aircraft Transport & Travel) 1981* - 1983 USA A.V. Roe 1919* - 1920 UK A/S Aero 1919 - 1920 UK A2B 1920 - 1920* Norway AAA Air Enterprises 2005 - 2006 UK AAC (African Air Carriers) 1979* - 1987 USA AAC (African Air Charter) 1983*- 1984 South_Africa AAI (Alaska Aeronautical Industries) 1976 - 1988 Zaire AAR Airlines 1954 - 1987 USA Aaron Airlines 1998* - 2005* Ukraine AAS (Atlantic Aviation Services) **** - **** Australia AB Airlines 2005* - 2006 Liberia ABA Air 1996 - 1999 UK AbaBeel Aviation 1996 - 2004 Czech_Republic Abaroa Airlines (Aerolineas Abaroa) 2004 - 2008 Sudan Abavia 1960^ - 1972 Bolivia Abbe Air Cargo 1996* - 2004 Georgia ABC Air Hungary 2001 - 2003 USA A-B-C Airlines 2005 - 2012 Hungary Aberdeen Airways 1965* - 1966 USA Aberdeen London Express 1989 - 1992 UK Aboriginal Air Services 1994 - 1995* UK Absaroka Airways 2000* - 2006 Australia ACA (Ancargo Air) 1994^ - 2012* USA AccessAir 2000 - 2000 Angola ACE (Aryan Cargo Express) 1999 - 2001 USA Ace Air Cargo Express 2010 - 2010 India Ace Air Cargo Express 1976 - 1982 USA ACE Freighters (Aviation Charter Enterprises) 1982 - 1989 USA ACE Scotland 1964 - 1966 UK ACE Transvalair (Air Charter Express & Air Executive) 1966 - 1966 UK ACEF Cargo 1984 - 1994 France ACES (Aerolineas Centrales de Colombia) 1998 - 2004* Portugal ACG (Air Cargo Germany) 1972 - 2003 Colombia ACI