Integrative Analysis Identifies Candidate Tumor
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Malignant Peripheral Nerve Sheath Tumor (MPNST): an Overview with Emphasis on Pathology, Imaging and Management Strategies
Thomas Jefferson University Jefferson Digital Commons Department of Neurosurgery Faculty Papers Department of Neurosurgery 6-2012 Malignant Peripheral Nerve Sheath Tumor (MPNST): An overview with emphasis on pathology, imaging and management strategies Timothy C. Beer 3rd year medical student, Jefferson Medical College Follow this and additional works at: https://jdc.jefferson.edu/neurosurgeryfp Part of the Medical Neurobiology Commons Let us know how access to this document benefits ouy Recommended Citation Beer, Timothy C., "Malignant Peripheral Nerve Sheath Tumor (MPNST): An overview with emphasis on pathology, imaging and management strategies" (2012). Department of Neurosurgery Faculty Papers. Paper 18. https://jdc.jefferson.edu/neurosurgeryfp/18 This Article is brought to you for free and open access by the Jefferson Digital Commons. The Jefferson Digital Commons is a service of Thomas Jefferson University's Center for Teaching and Learning (CTL). The Commons is a showcase for Jefferson books and journals, peer-reviewed scholarly publications, unique historical collections from the University archives, and teaching tools. The Jefferson Digital Commons allows researchers and interested readers anywhere in the world to learn about and keep up to date with Jefferson scholarship. This article has been accepted for inclusion in Department of Neurosurgery Faculty Papers by an authorized administrator of the Jefferson Digital Commons. For more information, please contact: [email protected]. An overview with emphasis -

Central Nervous System Tumors General ~1% of Tumors in Adults, but ~25% of Malignancies in Children (Only 2Nd to Leukemia)
Last updated: 3/4/2021 Prepared by Kurt Schaberg Central Nervous System Tumors General ~1% of tumors in adults, but ~25% of malignancies in children (only 2nd to leukemia). Significant increase in incidence in primary brain tumors in elderly. Metastases to the brain far outnumber primary CNS tumors→ multiple cerebral tumors. One can develop a very good DDX by just location, age, and imaging. Differential Diagnosis by clinical information: Location Pediatric/Young Adult Older Adult Cerebral/ Ganglioglioma, DNET, PXA, Glioblastoma Multiforme (GBM) Supratentorial Ependymoma, AT/RT Infiltrating Astrocytoma (grades II-III), CNS Embryonal Neoplasms Oligodendroglioma, Metastases, Lymphoma, Infection Cerebellar/ PA, Medulloblastoma, Ependymoma, Metastases, Hemangioblastoma, Infratentorial/ Choroid plexus papilloma, AT/RT Choroid plexus papilloma, Subependymoma Fourth ventricle Brainstem PA, DMG Astrocytoma, Glioblastoma, DMG, Metastases Spinal cord Ependymoma, PA, DMG, MPE, Drop Ependymoma, Astrocytoma, DMG, MPE (filum), (intramedullary) metastases Paraganglioma (filum), Spinal cord Meningioma, Schwannoma, Schwannoma, Meningioma, (extramedullary) Metastases, Melanocytoma/melanoma Melanocytoma/melanoma, MPNST Spinal cord Bone tumor, Meningioma, Abscess, Herniated disk, Lymphoma, Abscess, (extradural) Vascular malformation, Metastases, Extra-axial/Dural/ Leukemia/lymphoma, Ewing Sarcoma, Meningioma, SFT, Metastases, Lymphoma, Leptomeningeal Rhabdomyosarcoma, Disseminated medulloblastoma, DLGNT, Sellar/infundibular Pituitary adenoma, Pituitary adenoma, -

UCSD Moores Cancer Center Neuro-Oncology Program
UCSD Moores Cancer Center Neuro-Oncology Program Recent Progress in Brain Tumors 6DQWRVK.HVDUL0'3K' 'LUHFWRU1HXUR2QFRORJ\ 3URIHVVRURI1HXURVFLHQFHV 0RRUHV&DQFHU&HQWHU 8QLYHUVLW\RI&DOLIRUQLD6DQ'LHJR “Brain Cancer for Life” Juvenile Pilocytic Astrocytoma Metastatic Brain Cancer Glioblastoma Multiforme Glioblastoma Multiforme Desmoplastic Infantile Ganglioglioma Desmoplastic Variant Astrocytoma Medulloblastoma Atypical Teratoid Rhabdoid Tumor Diffuse Intrinsic Pontine Glioma -Mutational analysis, microarray expression, epigenetic phenomenology -Age-specific biology of brain cancer -Is there an overlap? ? Neuroimmunology ? Stem cell hypothesis Courtesy of Dr. John Crawford Late Effects Long term effect of chemotherapy and radiation on neurocognition Risks of secondary malignancy secondary to chemotherapy and/or radiation Neurovascular long term effects: stroke, moya moya Courtesy of Dr. John Crawford Importance Increase in aging population with increased incidence of cancer Patients with cancer living longer and developing neurologic disorders due to nervous system relapse or toxicity from treatments Overview Introduction Clinical Presentation Primary Brain Tumors Metastatic Brain Tumors Leptomeningeal Metastases Primary CNS Lymphoma Paraneoplastic Syndromes Classification of Brain Tumors Tumors of Neuroepithelial Tissue Glial tumors (astrocytic, oligodendroglial, mixed) Neuronal and mixed neuronal-glial tumors Neuroblastic tumors Pineal parenchymal tumors Embryonal tumors Tumors of Peripheral Nerves Shwannoma Neurofibroma -

Malignant CNS Solid Tumor Rules
Malignant CNS and Peripheral Nerves Equivalent Terms and Definitions C470-C479, C700, C701, C709, C710-C719, C720-C725, C728, C729, C751-C753 (Excludes lymphoma and leukemia M9590 – M9992 and Kaposi sarcoma M9140) Introduction Note 1: This section includes the following primary sites: Peripheral nerves C470-C479; cerebral meninges C700; spinal meninges C701; meninges NOS C709; brain C710-C719; spinal cord C720; cauda equina C721; olfactory nerve C722; optic nerve C723; acoustic nerve C724; cranial nerve NOS C725; overlapping lesion of brain and central nervous system C728; nervous system NOS C729; pituitary gland C751; craniopharyngeal duct C752; pineal gland C753. Note 2: Non-malignant intracranial and CNS tumors have a separate set of rules. Note 3: 2007 MPH Rules and 2018 Solid Tumor Rules are used based on date of diagnosis. • Tumors diagnosed 01/01/2007 through 12/31/2017: Use 2007 MPH Rules • Tumors diagnosed 01/01/2018 and later: Use 2018 Solid Tumor Rules • The original tumor diagnosed before 1/1/2018 and a subsequent tumor diagnosed 1/1/2018 or later in the same primary site: Use the 2018 Solid Tumor Rules. Note 4: There must be a histologic, cytologic, radiographic, or clinical diagnosis of a malignant neoplasm /3. Note 5: Tumors from a number of primary sites metastasize to the brain. Do not use these rules for tumors described as metastases; report metastatic tumors using the rules for that primary site. Note 6: Pilocytic astrocytoma/juvenile pilocytic astrocytoma is reportable in North America as a malignant neoplasm 9421/3. • See the Non-malignant CNS Rules when the primary site is optic nerve and the diagnosis is either optic glioma or pilocytic astrocytoma. -

Malignant Peripheral Nerve Sheath Tumors with T(X; 18). a Pathologic and Molecular Genetic Study Maureen J
Malignant Peripheral Nerve Sheath Tumors with t(X; 18). A Pathologic and Molecular Genetic Study Maureen J. O’Sullivan, Michael Kyriakos, Xiaopei Zhu, Mark R. Wick,1 Paul E. Swanson, Louis P. Dehner, Paul A. Humphrey, John D. Pfeifer L.V. Ackerman Laboratory of Surgical Pathology, Washington University Medical Center, St. Louis, Missouri. KEY WORDS: Chromosomal translocation; malig- Spindle cell sarcomas often present the surgical pa- nant peripheral nerve sheath tumor; specificity; sy- thologist with a considerable diagnostic challenge. novial sarcoma; t(X;18). Malignant peripheral nerve sheath tumor, leiomy- Mod Pathol 2000;13(11):1253–1263 osarcoma, fibrosarcoma, and monophasic synovial sarcoma may all appear similar histologically. The Spindle cell sarcomas include a wide variety of tu- application of ancillary diagnostic modalities, such mors, some of which, such as synovial sarcoma (SS) as immunohistochemistry and electron micros- and malignant peripheral nerve sheath tumor copy, may be helpful in the differentiation of these (MPNST), may have overlapping histologic fea- tumors, but in cases in which these adjunctive tech- tures. Because SS has classically been recognized as niques fail to demonstrate any more definitive evi- a neoplasm arising in the juxta-articular peripheral dence of differentiation, tumor categorization may soft tissue in adolescents or young adults (1–6), and remain difficult. Cytogenetic and molecular genetic MPNST has been associated with peripheral nerves, characterization of tumors have provided the basis especially in persons with neurofibromatosis (NF- for the application of molecular assays as the new- 1), clinical features have often been used as a est components of the diagnostic armamentarium. means to discriminate between the two tumors. -

Adrenal and Paraganglia Tumors Adrenal Cortical Tumors IHC: (+) SF1, Inhibin, Melan-A, Calretinin, Synaptophysin, (-) Chromogranin, Cytokeratin, S100
Last updated: 11/11/2020 Prepared by Kurt Schaberg Adrenal and Paraganglia Tumors Adrenal Cortical Tumors IHC: (+) SF1, Inhibin, Melan-A, Calretinin, Synaptophysin, (-) Chromogranin, Cytokeratin, S100. Often variable!! Adrenal Cortical Adenoma Benign. Very common. Often incidentally identified. Usually unilateral solitary masses with atrophic background adrenal gland. Tumor cells can be lipid-rich (clearer) or lipid-poor (pinker) arranged in nests and cords separated by abundant vasculature. Occasional lipofuscin pigment. Nuclei generally small and round (occasional extreme “endocrine atypia” is common). Low/no mitotic activity. Intact reticulin framework. On a spectrum with and may hard to differentiate from hyperplastic nodules, which is more often multinodular (background hyperplasia) and bilateral. Can be non-functional (85%) or functional (15%). Associated with MEN1, FAP, Carney Complex, among Aldosterone-producing→ “Conn syndrome”→ others… hypertension and hypokalemia If aldosterone-secreting adenoma is treated with Cortisol-producing→ (ACTH-independent) spironolactone→ “spironolactone bodies” (below) “Cushing Syndrome” → central obesity, moon face, hirsutism, poor healing, striae Sex-hormone-producing→ Rare (more common in carcinomas). Symptoms depend on hormone/sex (virilization or feminization) Adrenal Cortical Carcinoma Malignant. Most common in older adults. Can present with an incidental unilateral mass or with an endocrinopathy (see above). Solid, broad trabeculae, or large nested growth (more diffuse, and larger groups than in adenomas) Thick fibrous capsule with occasional fibrous bands. Frequent tumor necrosis. Frequent vascular or capsular invasion. Increased mitotic activity. Variants: Oncocytic, Myxoid, Sarcomatoid Mostly sporadic, but can be associated with Lynch Syndrome and Li-Fraumeni Syndrome Distinguishing between an Adrenal Cortical Adenoma vs Carcinoma Weiss Criteria: Weiss Criteria (≥3 = Malignant) Most widely used system, but doesn’t work as well High nuclear grade (based of Fuhrman criteria) in borderline cases or variants. -

Malignant Intracerebral Nerve Sheath Tumor in a Patient with Noonan Syndrome: Illustrative Case
J Neurosurg Case Lessons 1(26):CASE21146, 2021 DOI: 10.3171/CASE21146 Malignant intracerebral nerve sheath tumor in a patient with Noonan syndrome: illustrative case *Callum M. Allison, MClinRes,1,2 Syed Shumon, MBBS, MRCS,1 Abhijit Joshi, MBBS, FRCPath,5 Annelies Quaegebeur, MD, PhD, FRCPath,6 Georges Sinclair, MRCR, MD,3,4 and Surash Surash, MBChB, FRCS(Neurosurg), MD, LLM1 Departments of 1Neurosurgery and 5Pathology, Royal Victoria Infirmary, Newcastle Upon Tyne, United Kingdom; 2Newcastle University Medical School, Newcastle Upon Tyne, United Kingdom; 3Department of Oncology, James Cook University Hospital, Middlesbrough, United Kingdom; 4Department of Neurosurgery, Bezmialem Vakif University Hospital, Istanbul, Turkey; and 6Division of Neuropathology, National Hospital for Neurology and Neurosurgery, University College London Hospitals NHS Foundation Trust, London, United Kingdom BACKGROUND Malignant peripheral nerve sheath tumors (MPNSTs) within the neuroaxis are rare, usually arising from peripheral and cranial nerves. Even more scarce are cranial subclassifications of MPNSTs termed “malignant intracerebral nerve sheath tumors” (MINSTs). These tumors are aggressive, with a strong tendency for metastasis. With this presentation, alongside resistance to adjunctive therapy, complete excision is the mainstay of treatment, although it is often insufficient, resulting in a high rate of mortality. OBSERVATIONS The authors report the case of an adult patient with a history of Noonan syndrome (NS) presenting with slowly progressive right- sided hemiparesis and right-sided focal motor seizures. Despite initial imaging and histology suggesting a left frontal lobe high-grade intrinsic tumor typical of a glioblastoma, subsequent molecular analysis confirmed a diagnosis of MINST. The patient’s neurological condition improved after gross- total resection and adjuvant chemo-radiation; he remains on follow-up. -

Malignant Peripheral Nerve Sheath Tumor
Malignant Peripheral Nerve Sheath Tumor a b c Aaron W. James, MD , Elizabeth Shurell, MD , Arun Singh, MD , d e, Sarah M. Dry, MD , Fritz C. Eilber, MD * KEYWORDS Neurofibroma Atypical neurofibroma Malignant peripheral nerve sheath tumor Neurofibromatosis NF1 KEY POINTS Malignant peripheral nerve sheath tumor (MPNST) is the sixth most common soft tissue sarcoma, often arises from a neurofibroma, and in half of cases occurs in a patient with neurofibromatosis type I. The most accurate radiographic evaluation of MPNST uses a combination of PET along with CT or MRI. The pathologic diagnoses of peripheral nerve sheath tumors with atypia represent a his- tologic continuum, and include neurofibroma with atypical features, low-grade MPNST, and high-grade MPNST. Management and prognosis significantly differ between low-grade MPNST and high- grade MPNST. INTRODUCTION TO MALIGNANT PERIPHERAL NERVE SHEATH TUMOR MPNST is the sixth most common type of soft-tissue sarcoma, accounting for approx- imately 5% to 10% of cases.1–3 Although its exact cellular origins remain unclear, most MPNSTs arise in association with a peripheral nerve and are hypothesized to be of neural crest origin.4 Approximately 50% of all MPNST cases arise sporadically, whereas the other 50% of cases are observed in patients with neurofibromatosis Disclosure Statement: The authors have nothing to disclose. a Department of Pathology, Johns Hopkins University, 600 North Wolfe Street, Baltimore, MD 21287-6417, USA; b Memorial Sloan Kettering Cancer Center, 1275 York Avenue, New York, NY 10065, USA; c Sarcoma Service, Division of Hematology/Oncology, University of California, Los Angeles, 2825 Santa Monica Boulevard, Suite 213 TORL, Santa Monica, CA 90404, USA; d Department of Pathology & Laboratory Medicine, University of California, Los Angeles, Box 951732, 13-145D CHS, Los Angeles, CA 90095-1732, USA; e Division of Surgical Oncology, University of California, Los Angeles, 10833 LeConte Avenue, Room 54-140 CHS, Los Angeles, CA 90095-1782, USA * Corresponding author. -

Successful Treatment of Primary Intracranial Malignant Peripheral
Case Report iMedPub Journals JOURNAL OF NEUROLOGY AND NEUROSCIENCE 2016 http://www.imedpub.com/ Vol.7 No.4:136 ISSN 2171-6625 DOI: 10.21767/2171-6625.1000136 Successful Treatment of Primary Intracranial Malignant Peripheral Nerve Sheath Tumor in Iranian Child: Case Report Babak Abdolkarimi1, Soheila Zareifar2 and Mansureh Shokripoor3 1Department of Pediatric Oncology/Hematology, Lorestan University of Medical Sciences, Khoramabad, Iran 2Hematology/Oncology Department, Amir Oncology Hospital, Shiraz University of Medical Sciences, Shiraz, Iran 3Pathology Department, Shiraz University of Medical Sciences, Shiraz, Iran Corresponding author: Babak Abdolkarimi, Assistant professor, Department of Pediatric Oncology/Hematology, Lorestan University of Medical Sciences, Khoramabad, Iran, Tel: +989183605274; E-mail: [email protected] Received: Jul 16, 2016; Accepted: Jul 29, 2016; Published: Aug 02, 2016 Citation: Abdolkarimi B, Zareifar S, Shokripoor M. Successful Treatment of Primary Intracranial Malignant Peripheral Nerve Sheath Tumor in Iranian Child: Case Report. J Neurol Neurosci. 2016, 7:4. On examination the patient was conscious and coherent. She had not cranial nerve palsy but, muscle force in the right- sided Abstract limb was 3/5. Right plantar showed an extensor response. There wasn’t any constitutional symptom such as fever Intracerebral malignant peripheral nerve sheath tumor is detected in patient. an unusual and a highly malignant tumor. The prognosis of the tumor is extremely poor. Radical surgery is main Trigeminal Nerve -

Schwannoma of the Median Nerve at the Wrist- a Case Report and Review of Literature
Orthopedics and Rheumatology Open Access Journal ISSN: 2471-6804 Case Report Ortho & Rheum Open Access Volume 4 Issue 5 - February 2017 Copyright © All rights are reserved by Damián Gómez Hernández DOI: 10.19080/OROAJ.2017.04.555648 Schwannoma of the Median Nerve at the Wrist- A Case Report and Review of Literature Damián Gómez Hernández¹*, Ricardo Monreal González², Javier Martínez Mesa¹, Eva Tejerina González¹ and Elizabeth Rivero Rabilero¹ 1Hospital Universitario Madrid Torrelodones, España 2Centro Médico MEDEX, Perú Submission: February 06, 2017; Published: February 15, 2017 *Corresponding author: SDamián Gómez Hernández, Hospital Universitario Madrid Torrelodones, Torrelodones, Madrid, España, Email: Abstract Benign tumours involving peripheral nerves of the upper extremity are uncommon. Schwannomas also known as neurolemmas are usually originated from Schwann cells located in the peripheral nerve sheaths. It is generally presented as an asymptomatic mass and its slow evolution remain an essential factor in diagnosis delays. Tumors with a long evolution and relatively large dimensions can undergo degenerative changes such as cyst formation, calcification, hemorrhage and fibrosis and are described as ancient schwannomas which can be misdiagnosed as sarcomas due to specific imaging and histologic findings. for malignantWe report transformation. a rare case diagnosed Surgical as removalancient schwannoma is usually curative. of the median nerve in a 70-year-old male. We describe the clinical presentation, the specific imaging, histology, surgical findings and functional outcome. This tumor has a good prognosis with a low recurrence rate and potential Keywords: Ancient schwannoma; Median nerve; peripheral nerve sheath tumors; Neurilimoma Introduction Peripheral nerve tumors are uncommon lesions categorized Case Report into primary neuronal, nerve sheath, and non-neuronal neoplasm. -

Vaginal Malignant Peripheral Nerve Sheath Tumor (MPNST) with Unusual Liposarcomatous Differentiation - a Case Report F Gougeon1*, J
Gougeon et al. Int J Cancer Clin Res 2015, 2:4 ISSN: 2378-3419 International Journal of Cancer and Clinical Research Case Report: Open Access Vaginal Malignant Peripheral Nerve Sheath Tumor (MPNST) With Unusual Liposarcomatous Differentiation - A Case Report F Gougeon1*, J. Doyon2, P. Sauthier3 and K. Rahimi1 1Centre universitaire de l’université de Montréal, département de pathologie, Montréal, Canada 2Centre de santé Maisonneuve-Rosemont, département de pathologie, Montréal, Canada 3Centre universitaire de l’université de Montréal, département de gynéco-oncologie, Canada *Corresponding author: Francois Gougeon, Centre universitaire de l’université de Montréal, département de pathologie, Montréal, Canada, Tel: 4388830570, E-mail: [email protected] She was referred to the gynecological-oncology clinic for spotting Abstract which had started a year before. Two months prior to presentation, Malignant peripheral nerve sheath tumors (MPNSTs) are rare she noticed an enlarging vaginal mass, as well as urinary symptoms sarcomas usually arising in peripheral nerve bundles or from and loss of around 10 pounds. pre-existing neurofibromas. They have frequent divergent differentiation. Here we present a case of MPNST arising in the A PET-SCAN showed two vaginal masses measuring 8.6 cm and vagina of a 70 y.o women. Beside the unusual location, this tumor 6.0 cm. One of them showed cavitation. Two lymph nodes adjacent presented liposarcomatous differentiation, a finding which has only to the left iliac vessels were suspicious for metastasis. There was no been reported three times in the past and never in a MPNST of the evidence of extra-nodal metastasic disease. female genital tract. The patient underwent a surgical biopsy of one of the vaginal Keywords masses. -
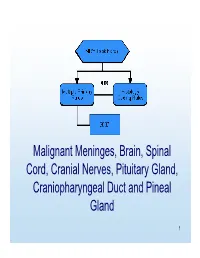
MP/H Rules Presentation
Malignant Meninges, Brain, Spinal Cord, Cranial Nerves, Pituitary Gland, Craniopharyngeal Duct and Pineal Gland 1 Equivalent Terms, Definitions, Charts and Illustrations • Benign and borderline intracranial and CNS tumors have a separate set of rules. 2 Equivalent Terms, Definitions, Charts and Illustrations • PNET (Primitive neuroectodermal tumor) – Central PNET – Supratentorial PNET • pPNET –not brain primary 3 Chart 1 Neuroepithelial Brain CNS • WHO Classification of Tumors of the brain and central nervous system • Not complete listing 4 Chart Instructions: Use this chart to code histology. The tree is arranged Neuroepithelial in descending order. Each branch is a histology group, starting at the top (9503) with the least specific terms and descending into more specific terms. Embryonal Ependymal Pineal Choroid plexus Neuronal and mixed Neuroblastic Glial Oligodendroglial tumors tumors tumors tumors neuronal-glial tumors tumors tumors tumors Ependymoma, Pineoblastoma Choroid plexus Olfactory neuroblastoma Oligodendroglioma NOS (9391) (9362) carcinoma Ganglioglioma, anaplastic (9522) NOS (9450) (9390) (9505 Olfactory neurocytoma Oligodendroglioma Ganglioglioma, malignant (9521) anaplastic (9451) Anasplastic ependymoma (9505) Olfactory neuroepithlioma Oligodendroblastoma (9392) (9523) (9460) Papillary ependymoma (9393) Glioma, NOS (9380) Atypical Ependymoblastoma Medulloepithelioma Medulloblastoma Supratentorial primitive tetratoid/rhabdoid (9392) (9501) (9470) neuroectodermal tumor tumor (9508) (PNET) (9473) Teratoid Demoplastic (9471)